Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Progettazione dello schema di social network in DynamoDB
Caso d'uso aziendale di social network
In questo caso d'uso viene descritto l'utilizzo di DynamoDB come un social network. Un social network è un servizio online che consente a diversi utenti di interagire tra loro. Il social network che verrà progettato consentirà all'utente di visualizzare una sequenza temporale composta da post, follower, utenti seguiti e post scritti dagli utenti seguiti. I modelli di accesso per questo schema sono:
-
Ottenere informazioni utente per un userID specifico
-
Ottenere l'elenco di follower per un userID specifico
-
Ottenere l'elenco di follower per un userID specifico
-
Ottenere l'elenco di post per un userID specifico
-
Ottenere l'elenco di utenti a cui piace il post per un postID specifico
-
Ottenere il numero di like per un postID specifico
-
Ottenere la sequenza temporale per un userID specifico
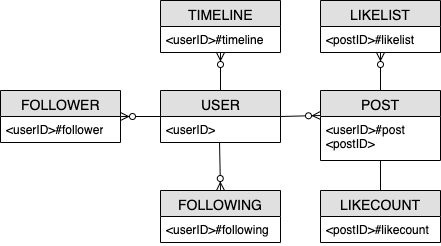
Diagramma delle relazioni tra entità del social network
Questo è il diagramma delle relazioni tra entità (ERD) che useremo per la progettazione dello schema di social network.
Modelli di accesso di social network
Questi sono i modelli di accesso che creeremo per la progettazione dello schema di social network.
-
getUserInfoByUserID -
getFollowerListByUserID -
getFollowingListByUserID -
getPostListByUserID -
getUserLikesByPostID -
getLikeCountByPostID -
getTimelineByUserID
Evoluzione della progettazione dello schema di social network
DynamoDB è un database NoSQL, quindi non consente di eseguire un join, ovvero un'operazione che combina dati di più database. I clienti che non hanno familiarità con DynamoDB potrebbero applicare filosofie di progettazione del sistema di gestione dei database relazionali (RDBMS) (come la creazione di una tabella per ogni entità) a DynamoDB quando non è necessario. Lo scopo della progettazione tabella singola di DynamoDB è scrivere dati in un formato pre-unito in base al modello di accesso dell'applicazione e quindi utilizzare immediatamente i dati senza calcoli aggiuntivi. Per ulteriori informazioni, consulta la comparazione tra progettazione Single-table multitavola in DynamoDB
Ora illustreremo come intendiamo sviluppare la progettazione dello schema per gestire tutti i modelli di accesso.
Fase 1: Gestire il modello di accesso 1 (getUserInfoByUserID)
Per ottenere le informazioni di un determinato utente, devi eseguire una Query della tabella di base con una condizione chiave di PK=<userID>. L'operazione di interrogazione consente di impaginare i risultati, il che può essere utile quando un utente ha molti follower. Per ulteriori informazioni su Query, consulta Esecuzione di query in DynamoDB.
In questo esempio, vengono monitorati due tipi di dati per gli utenti: il "conteggio" e le "informazioni". Il "conteggio" di un utente indica quanti follower ha, quanti utenti sta seguendo e quanti post ha creato. Le "informazioni" di un utente indicano le informazioni personali, come il nome.
Questi due tipi di dati sono rappresentati dai due elementi sottostanti. L'elemento che contiene "conteggio" nella sua chiave di ordinamento (SK) è più probabile che cambi rispetto all'elemento con "informazioni". DynamoDB considera le dimensioni elemento così come appaiono prima e dopo l'aggiornamento e la velocità di trasmissione effettiva assegnata consumata rifletterà il più grande di questi valori. Anche se aggiorni solo un sottoinsieme di attributi dell'elemento, UpdateItem utilizza comunque la quantità completa della velocità di trasmissione effettiva assegnata (il valore maggiore tra le dimensioni "prima" e "dopo"). Puoi ottenere gli elementi tramite una singola operazione Query e utilizzare UpdateItem per aggiungere o sottrarre attributi numerici esistenti.

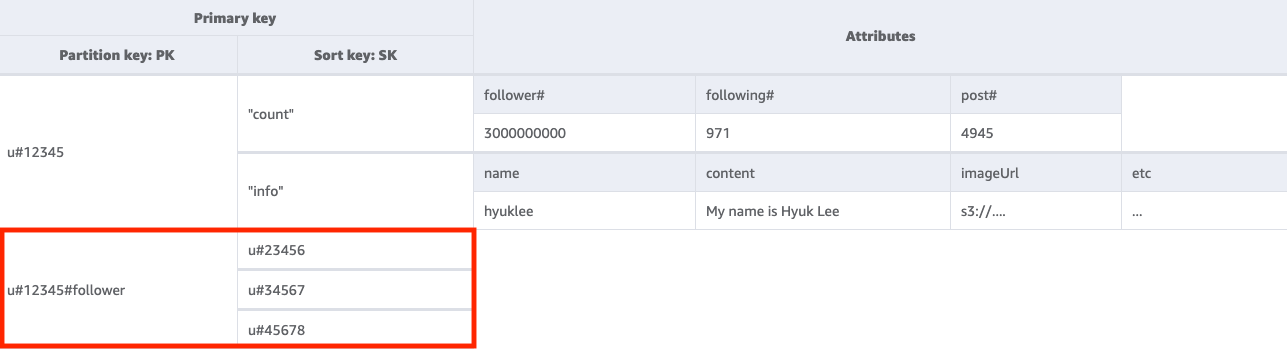
Fase 2: Gestire il modello di accesso 2 (getFollowerListByUserID)
Per ottenere un elenco di utenti che seguono un determinato utente, occorre eseguire una Query della tabella di base con una condizione chiave di PK=<userID>#follower.
Fase 3: Gestire il modello di accesso 3 (getFollowingListByUserID)
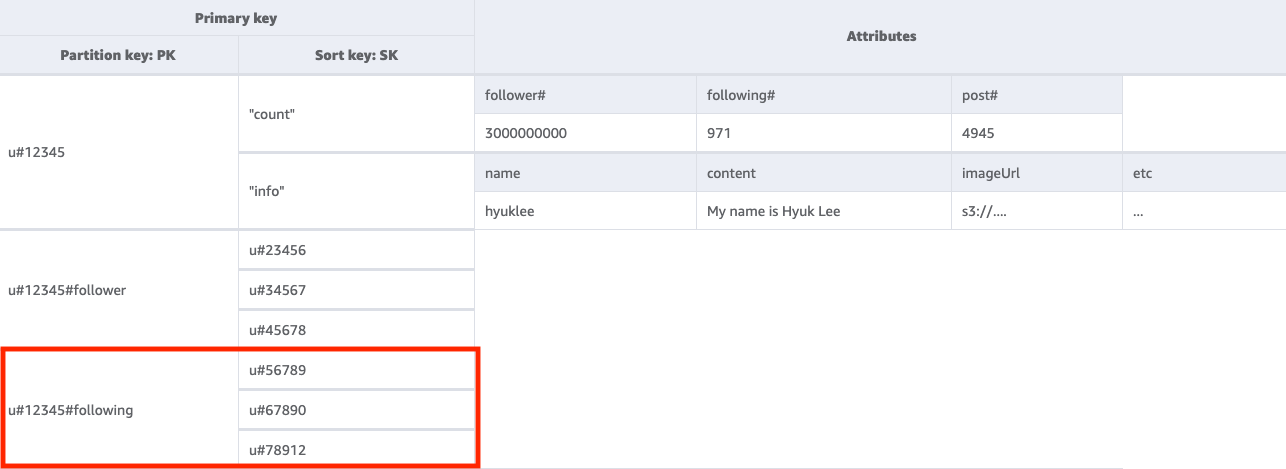
Per ottenere un elenco di utenti seguiti da un determinato utente, occorre eseguire una Query della tabella di base con una condizione chiave di PK=<userID>#following. Quindi è possibile utilizzare un’operazione TransactWriteItems per raggruppare più richieste e procedere come segue:
-
Aggiungi l’Utente A all’elenco di follower dell’Utente B, quindi incrementa il conteggio di follower dell’Utente B di uno.
-
Aggiungi l’Utente B all’elenco di follower dell’Utente A, quindi incrementa il conteggio di follower dell’Utente A di uno.
Fase 4: Gestire il modello di accesso 4 (getPostListByUserID)
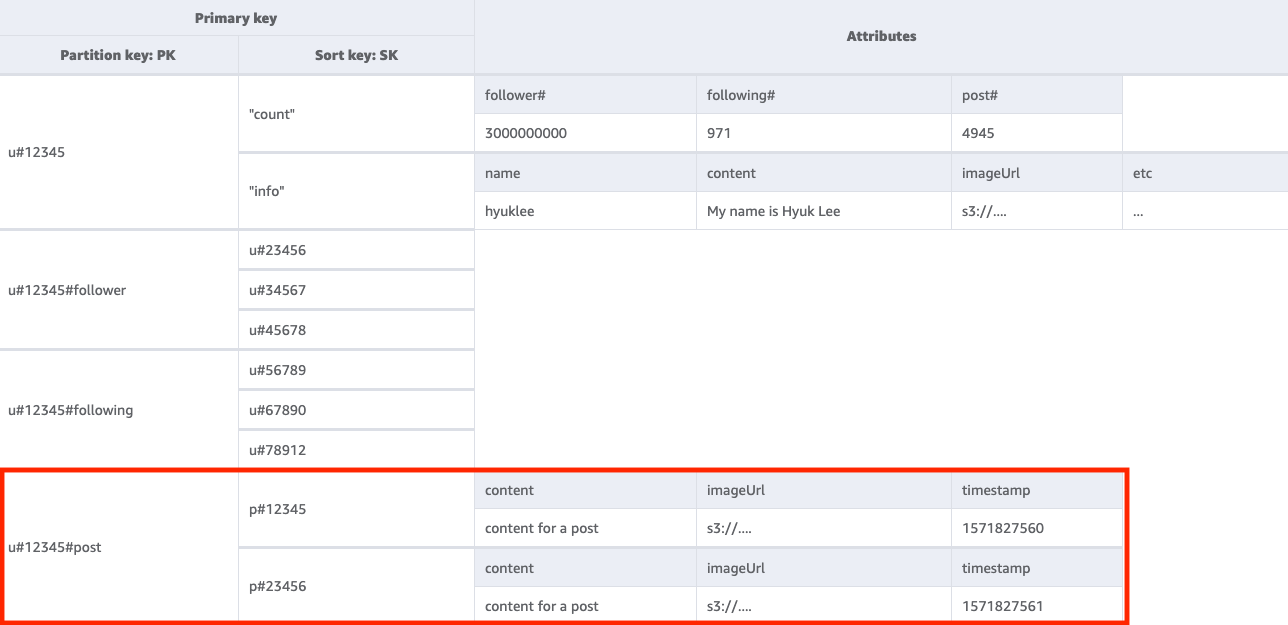
Per ottenere un elenco di post creati da un determinato utente, devi eseguire una Query della tabella di base con una condizione chiave di PK=<userID>#post. Una cosa importante che occorre notare qui è che i postID di un utente devono essere incrementali: il secondo valore postID deve essere maggiore del primo valore postID (poiché gli utenti desiderano vedere i post in modo ordinato). A questo scopo, genera i postID in base a un valore temporale come un ULID (Universally Unique Lexicographically Sortable Identifier).
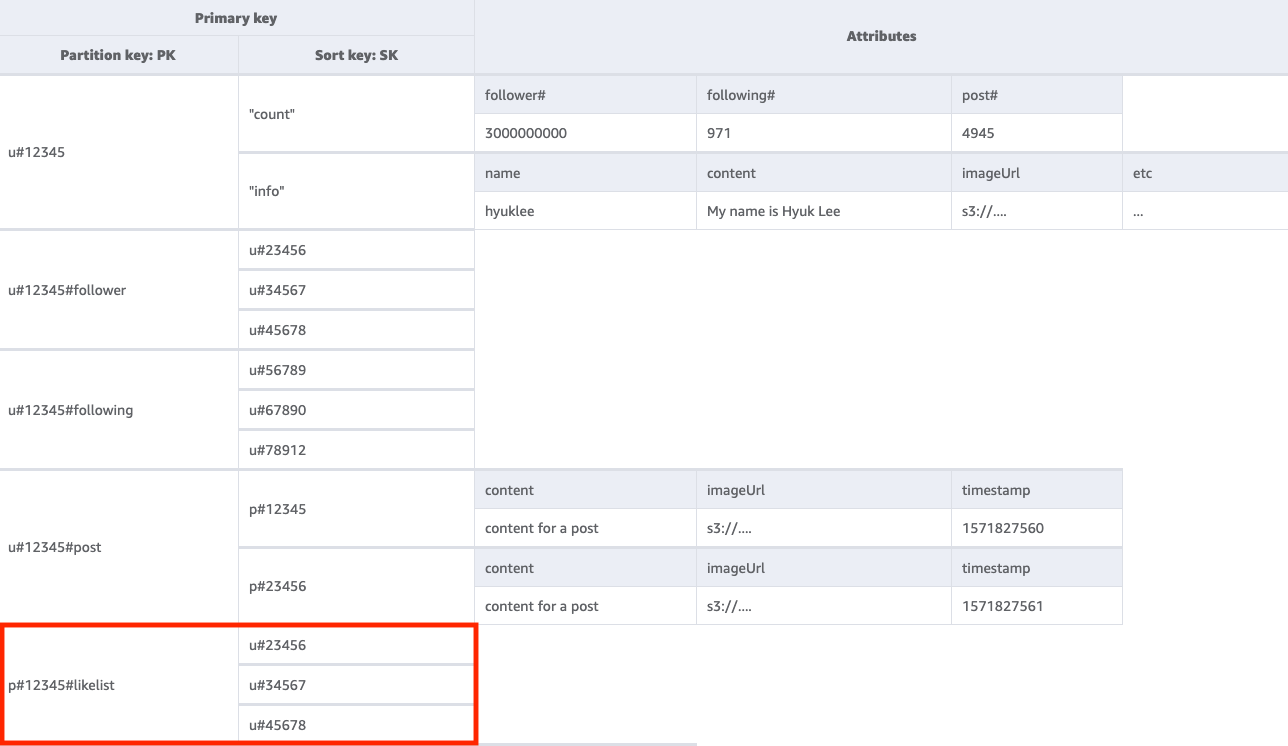
Fase 5: Gestire il modello di accesso 5 (getUserLikesByPostID)
Per ottenere un elenco di utenti che hanno messo like al post di un determinato utente, devi eseguire una Query della tabella di base con una condizione chiave di PK=<postID>#likelist. Questo approccio è lo stesso modello utilizzato per recuperare gli elenchi di follower e di utenti seguiti nel modello di accesso 2 (getFollowerListByUserID) e nel modello di accesso 3 (). getFollowingListByUserID
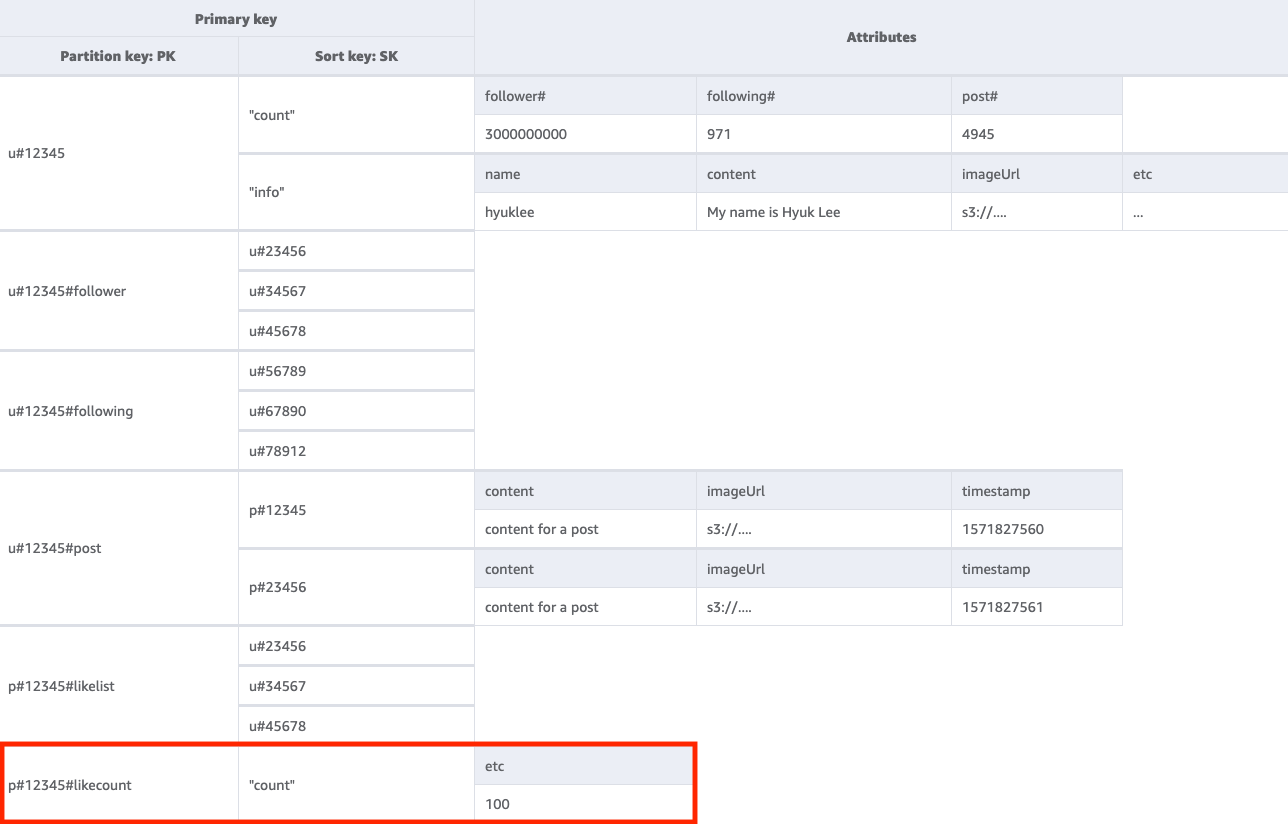
Fase 6: Gestire il modello di accesso 6 (getLikeCountByPostID)
Per ottenere un conteggio di like per un determinato post, occorre eseguire un'operazione GetItem sulla tabella di base con una condizione chiave di PK=<postID>#likecount. Questo modello di accesso può causare problemi di limitazione (della larghezza di banda della rete) ogni volta che un utente con molti follower (ad esempio, una celebrità) crea un post poiché la limitazione (della larghezza di banda della rete) si verifica quando la velocità di trasmissione effettiva di una partizione supera i 1000 WCU al secondo. Questo problema non è una conseguenza di DynamoDB, ma appare solo in DynamoDB poiché si trova alla fine dello stack software.
Occorre valutare se è davvero essenziale che tutti gli utenti visualizzino il conteggio dei like contemporaneamente o se questo può avvenire gradualmente nel tempo. In generale, il conteggio dei like di un post non deve essere immediatamente accurato al 100%. È possibile implementare questa strategia inserendo una coda tra l'applicazione e DynamoDB in modo che gli aggiornamenti avvengano periodicamente.
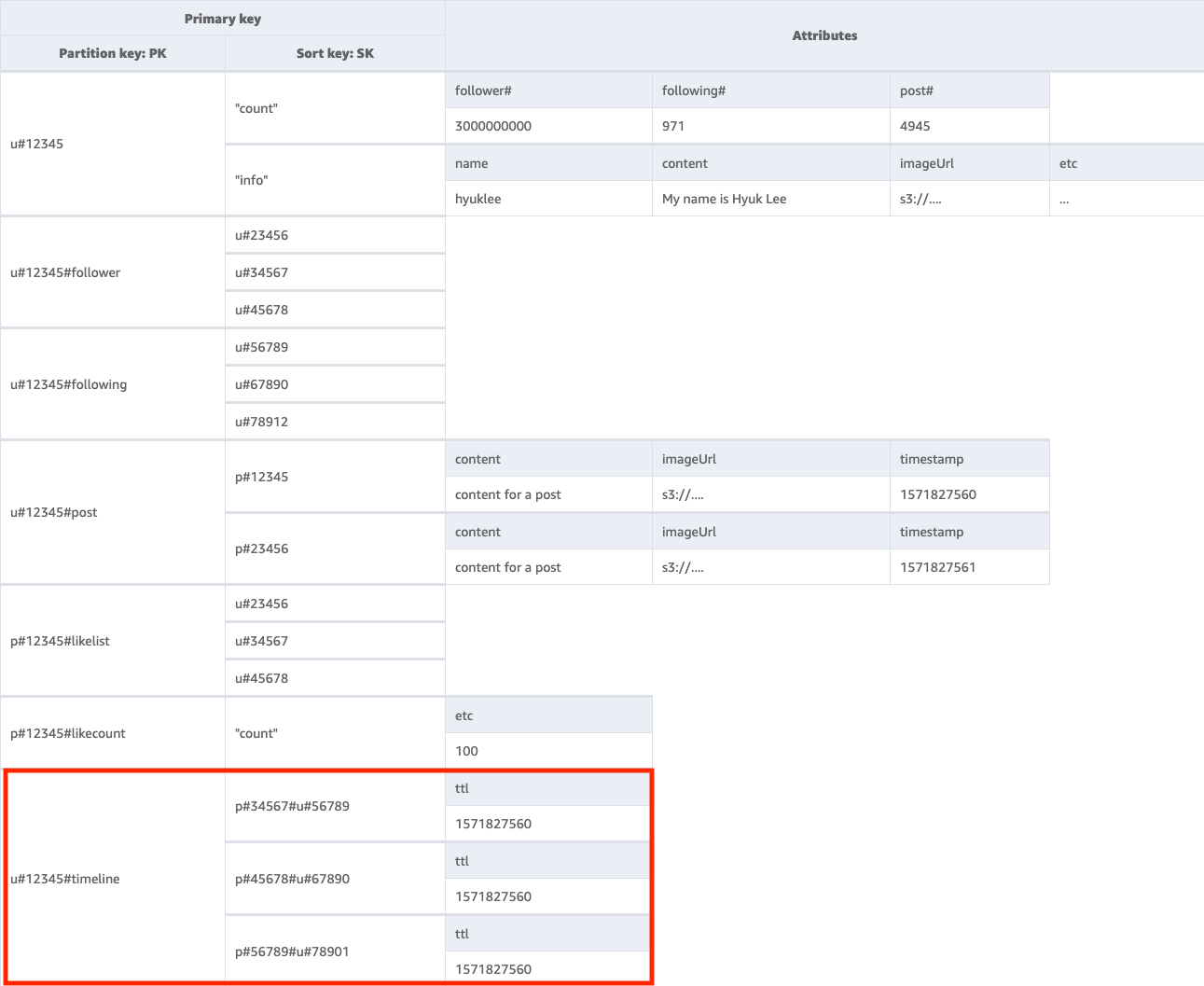
Fase 7: Gestire il modello di accesso 7 (getTimelineByUserID)
Per ottenere la sequenza temporale per un determinato post, occorre eseguire un'operazione Query sulla tabella di base con una condizione chiave di PK=<userID>#timeline. Consideriamo uno scenario in cui i follower di un utente devono visualizzare i loro post in modo sincrono. Ogni volta che un utente scrive un post, il relativo elenco di follower viene letto e i valori userID e postID vengono inseriti lentamente nella chiave della sequenza temporale di tutti i suoi follower. Quindi, all'avvio dell'applicazione, puoi leggere la chiave della sequenza temporale con l'operazione Query e riempire la schermata della sequenza temporale con una combinazione di userID e postID utilizzando l'operazione BatchGetItem per tutti i nuovi elementi. Non è possibile leggere la sequenza temporale con una chiamata API, ma questa è una soluzione più conveniente se i post possono essere modificati frequentemente.
Poiché la sequenza temporale visualizza i post recenti, occorre un modo per cancellare quelli vecchi. Anziché usare WCU per eliminarli, puoi utilizzare la funzionalità TTL di DynamoDB per eseguire questa operazione gratuitamente.
Tutti i modelli di accesso e il modo in cui la progettazione dello schema li affronta sono riassunti nella tabella seguente:
| Modello di accesso | Base table/GSI /LSI | Operation | Valore della chiave di partizione | Valore della chiave di ordinamento | Altro conditions/filters |
|---|---|---|---|---|---|
| ottenere UserInfoByUserID | Tabella di base | Query | PK=<userID> | ||
| ottenere FollowerListByUserID | Tabella di base | Query | PK=<userID>#follower | ||
| ottenere FollowingListByUserID | Tabella di base | Query | PK=<userID>#following | ||
| ottenere PostListByUserID | Tabella di base | Query | PK=<userID>#post | ||
| ottenere UserLikesByPostID | Tabella di base | Query | PK=<postID>#likelist | ||
| ottenere LikeCountByPostID | Tabella di base | GetItem | PK=<postID>#likecount | ||
| ottenere TimelineByUserID | Tabella di base | Query | PK=<userID>#timeline |
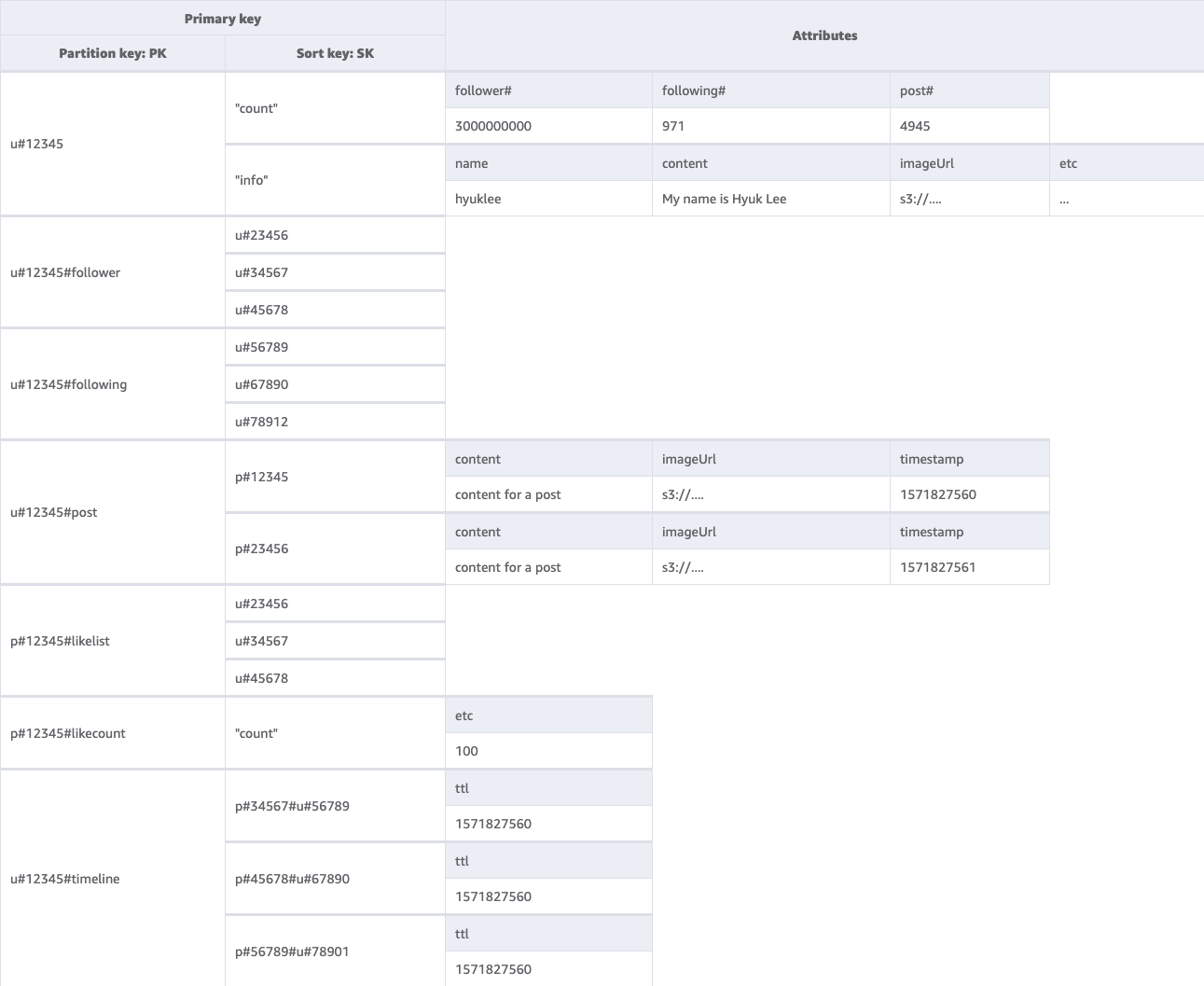
Schema finale del social network
Di seguito è riportata la progettazione dello schema finale. Per scaricare questo schema come file JSON, consulta Esempi di DynamoDB
Tabella di base:
Utilizzo di NoSQL Workbench con questa progettazione dello schema
Puoi importare questo schema finale in NoSQL Workbench, uno strumento visivo che fornisce funzionalità di modellazione dei dati, visualizzazione dei dati e sviluppo di query per DynamoDB, per esplorare e modificare ulteriormente il tuo nuovo progetto. Per iniziare, segui queste fasi:
-
Scarica NoSQL Workbench. Per ulteriori informazioni, consulta Download di NoSQL Workbench per DynamoDB.
-
Scarica il file dello schema JSON elencato in precedenza, che si trova già nel formato del modello NoSQL Workbench.
-
Importa il file dello schema JSON in NoSQL Workbench. Per ulteriori informazioni, consulta Importazione di un modello di dati esistente.
-
Dopo che è stato importato in NOSQL Workbench, puoi modificare il modello di dati. Per ulteriori informazioni, consulta Modifica di un modello di dati esistente.
