Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Indici secondari locali
Alcune applicazioni devono eseguire query sui dati soltanto utilizzando la chiave primaria della tabella di base. Tuttavia, potrebbero esserci situazioni in cui una chiave di ordinamento alternativa sarebbe utile. Per dare all'applicazione una scelta di chiavi di ordinamento, è possibile creare uno o più indici secondari locali su una tabella Amazon DynamoDB ed emettere le richieste Query o Scan rispetto a questi indici.
Argomenti
Scenario: Utilizzo di un indice secondario locale
Ad esempio, si consideri la tabella Thread. Questa tabella è utile per un'applicazione come Forum di discussione AWS
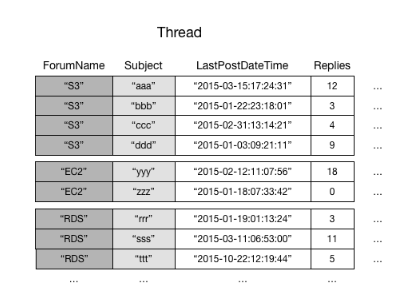
DynamoDB archivia tutti gli elementi con lo stesso valore della chiave di partizione in modo continuo. In questo esempio, dato un particolare ForumName, un'operazione Query potrebbe individuare immediatamente tutti i thread per quel forum. All'interno di un gruppo di elementi con lo stesso valore della chiave di partizione, gli elementi vengono ordinati in base al valore della chiave di ordinamento. Se la chiave di ordinamento (Subject) viene fornita anche nella query, DynamoDB può restringere i risultati restituiti, ad esempio restituendo tutti i thread nel forum "S3" che hanno un Subject che inizia con la lettera "a".
Alcune richieste potrebbero richiedere modelli di accesso ai dati più complessi. Ad esempio:
-
Quali thread del forum ottengono il maggior numero di visualizzazioni e risposte?
-
Quale thread in un particolare forum ha il maggior numero di messaggi?
-
Quanti thread sono stati pubblicati in un particolare forum in un determinato periodo di tempo?
Per rispondere a queste domande, l'operazione Query non sarebbe sufficiente. Con questa procedura, sarà necessario eseguire una Scan di tutta la tabella. Per una tabella con milioni di elementi, questa operazione consumerebbe una grande quantità di velocità effettiva di lettura assegnata e richiederebbe molto tempo per il completamento.
Tuttavia, è possibile specificare uno o più indici secondari locali su attributi non chiave, ad esempio Replies o LastPostDateTime.
Un indice secondario locale gestisce una chiave di ordinamento alternativa per un determinato valore della chiave di partizione. Un indice secondario locale contiene anche una copia di alcuni o tutti gli attributi della relativa tabella di base. È possibile specificare gli attributi proiettati nell'indice secondario locale quando si crea la tabella. I dati in un indice secondario locale sono organizzati in base alla stessa chiave di partizione della tabella di base ma con una chiave di ordinamento diversa. Ciò consente di accedere in modo efficiente agli elementi di dati in questa diversa dimensione. Per una maggiore flessibilità di query o scansione, è possibile creare un massimo di cinque indici secondari locali per tabella.
Supponiamo che un'applicazione debba trovare tutti i thread che sono stati pubblicati negli ultimi tre mesi in un particolare forum. Senza un indice secondario locale, l'applicazione dovrebbe eseguire la Scan dell'intera tabella Thread ed eliminare tutti i post che non erano nel periodo di tempo specificato. Con un indice secondario locale, un'operazione Querypotrebbe usare LastPostDateTime come chiave di ordinamento e trovare rapidamente i dati.
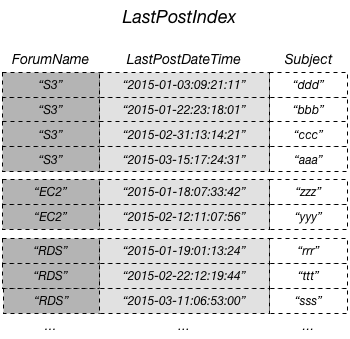
Il seguente diagramma mostra un indice secondario locale denominato LastPostIndex. Si noti che la chiave di partizione è la stessa di quella della tabella Thread, ma la chiave di ordinamento èLastPostDateTime.
Ciascun indice secondario locale deve soddisfare le seguenti condizioni:
-
La chiave di partizione deve essere la stessa della tabella di base.
-
La chiave di ordinamento deve essere costituita esattamente da un attributo scalare.
-
La chiave di ordinamento della tabella di base deve essere proiettata nell'indice, dove funzionerà da attributo non chiave.
In questo esempio, la chiave di partizione è ForumName e la chiave di ordinamento dell'indice secondario locale è LastPostDateTime. Inoltre, il valore della chiave di ordinamento dalla tabella di base (in questo esempio, Subject) viene proiettato nell'indice ma non fa parte della chiave di indice. Se un'applicazione ha bisogno di un elenco basato su ForumName e LastPostDateTime, può emettere una richiesta Query rispetto a LastPostIndex. I risultati della query sono ordinati per LastPostDateTime e possono essere restituiti in ordine crescente o decrescente. La query può applicare anche condizioni chiave, ad esempio restituendo solo gli elementi che dispongono di un LastPostDateTime entro un determinato lasso di tempo.
Ogni indice secondario locale contiene automaticamente le chiavi di partizione e ordinamento dalla relativa tabella di base; facoltativamente, è possibile proiettare gli attributi non chiave nell'indice. Quando si esegue una query sull'indice, DynamoDB può recuperare questi attributi proiettati in modo efficiente. Se si esegue una query sull'indice secondario locale, è possibile richiamare gli attributi che non sono proiettati sull'indice. DynamoDB recupera automaticamente questi attributi dalla tabella di base, ma a una latenza maggiore e con costi di velocità effettiva assegnata più elevati.
Per qualsiasi indice secondario locale, è possibile memorizzare fino a 10 GB di dati per ogni valore di chiave di partizione distinto. Questa figura include tutti gli elementi della tabella di base più tutti gli elementi degli indici, che hanno lo stesso valore della chiave di partizione. Per ulteriori informazioni, consulta Raccolte di elementi negli indici secondari locali.
Proiezioni di attributi
Con LastPostIndex, un'applicazione potrebbe usare ForumName e LastPostDateTime come criteri di query. Tuttavia, per richiamare eventuali altri attributi, DynamoDB deve eseguire ulteriori operazioni di lettura rispetto alla tabella Thread. Queste letture extra sono conosciute come recuperi e possono aumentare la quantità totale di velocità effettiva assegnata necessaria per una query.
Supponiamo di voler compilare una pagina web con un elenco di tutte le discussioni in «S3" e il numero di risposte per ogni thread, ordinate in base all'ultima risposta che inizia con la risposta più recente. date/time Per popolare questo elenco, sono necessari i seguenti attributi:
-
Subject -
Replies -
LastPostDateTime
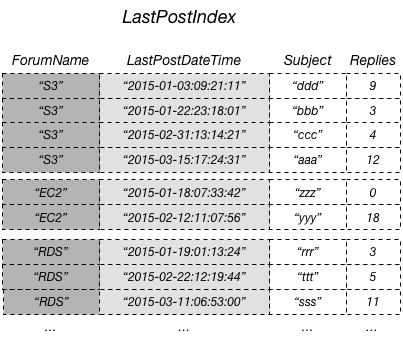
Il modo più efficiente per interrogare questi dati e per evitare operazioni di recupero sarebbe quello di proiettare l'attributo Replies dalla tabella nell'indice secondario locale, come mostrato in questo diagramma.
Una proiezione è l'insieme di attributi copiato da una tabella in un indice secondario. La chiave di partizione e la chiave di ordinamento della tabella vengono sempre proiettati nell'indice; è possibile proiettare altri attributi per supportare i requisiti di query dell'applicazione. Quando si esegue una query su un indice, Amazon DynamoDB può accedere a qualsiasi attributo nella proiezione come se tali attributi fossero in una propria tabella.
Quando si crea un indice secondario, è necessario specificare gli attributi che saranno proiettati nell'indice. DynamoDB fornisce tre diverse opzioni per questo:
-
KEYS_ONLY: ogni elemento dell'indice è costituito solo dalla chiave di partizione della tabella e dai valori della chiave di ordinamento, oltre ai valori della chiave di indice. L'opzione
KEYS_ONLYsi traduce nell'indice secondario più piccolo possibile. -
INCLUDE: oltre agli attributi descritti in
KEYS_ONLY, l'indice secondario includerà gli altri attributi non chiave che sono stati specificati. -
ALL: l'indice secondario include tutti gli attributi della tabella di origine. Poiché tutti i dati della tabella sono duplicati nell'indice, una proiezione
ALLrestituisce il più grande indice secondario possibile.
Nel diagramma precedente, l'attributo non chiave Replies è proiettato in LastPostIndex. Un'applicazione può interrogare LastPostIndex al posto della tabella Thread completa per popolare una pagina Web conSubject, Replies e LastPostDateTime. Se vengono richiesti altri attributi non chiave, DynamoDB dovrebbe recuperare tali attributi dalla tabella Thread.
Dal punto di vista di un'applicazione, il recupero di attributi aggiuntivi dalla tabella di base è automatico e trasparente, quindi non è necessario riscrivere alcuna logica dell'applicazione. Tuttavia, tale recupero può ridurre notevolmente il vantaggio in termini di prestazioni dell'utilizzo di un indice secondario locale.
Quando si scelgono gli attributi da proiettare in un indice secondario locale, è necessario considerare il compromesso tra i costi correlati alla velocità effettiva assegnata e costi di archiviazione:
-
Se è necessario accedere a pochi attributi con la latenza più bassa possibile, considerare la possibilità di proiettare solo quegli attributi in un indice secondario locale. Più piccolo è l'indice, minore è il costo per memorizzarlo e minori sono i costi di scrittura. Se sono presenti attributi che occasionalmente è necessario recuperare, il costo per la velocità effettiva assegnata potrebbe superare il costo a lungo termine della memorizzazione di tali attributi.
-
Se l'applicazione accede frequentemente ad alcuni attributi non chiave, è necessario considerare di proiettare quegli attributi in un indice secondario locale. I costi di archiviazione aggiuntivi per l'indice secondario locale compensano il costo di esecuzione di scansioni frequenti delle tabelle.
-
Se è necessario accedere alla maggior parte degli attributi non chiave su base frequente, è possibile proiettare questi attributi, o anche l'intera tabella di base, in un indice secondario locale. Ciò offre la massima flessibilità e il minor consumo di velocità effettiva assegnata, in quanto non sarebbe necessario eseguire alcun recupero. Tuttavia, i costi di archiviazione aumenteranno o addirittura raddoppieranno se verranno proiettati tutti gli attributi.
-
Se l'applicazione esegue di rado le query sulla tabella ma esegue molte scritture o aggiornamenti dei dati, considerare la possibilità di proiettare KEYS_ONLY. L'indice secondario locale avrebbe dimensioni minime e sarebbe comunque disponibile, se necessario, per l'attività di query.
Creazione di un indice secondario locale
Per creare una tabella con uno o più indici secondari locali su una tabella, utilizza il parametro LocalSecondaryIndexes con l'operazione CreateTable. Gli indici secondari locali in una tabella vengono creati al momento della creazione della tabella. Quando si elimina una tabella, vengono eliminati anche tutti gli indici secondari locali della tabella.
È necessario specificare un attributo non chiave che funzioni da chiave di ordinamento dell'indice secondario locale. L'attributo scelto deve essere uno String, Number oppure Binary scalare. Altri tipi scalari, documento e set non sono consentiti. Per l'elenco completo dei tipi di dati, consulta Tipi di dati.
Importante
Per le tabelle con gli indici secondari locali, esiste un limite di 10 GB per valore di chiave di partizione. Una tabella con indici secondari locali può memorizzare qualsiasi numero di elementi, a condizione che la dimensione totale per qualsiasi valore di una chiave di partizione non superi 10 GB. Per ulteriori informazioni, consulta Limite delle dimensioni delle raccolte di elementi.
È possibile proiettare gli attributi di qualsiasi tipo di dati in un indice secondario locale. Questo include scalari, documenti e set. Per l'elenco completo dei tipi di dati, consulta Tipi di dati.
Lettura di dati da un indice secondario locale
È possibile richiamare gli elementi da un indice secondario locale utilizzando le operazioni Query e Scan. Le operazioni GetItem e BatchGetItem non possono essere utilizzate su un indice secondario locale.
Esecuzione di una query su un indice secondario locale
In una tabella DynamoDB, il valore combinato della chiave di partizione e della chiave di ordinamento per ogni elemento deve essere univoco. Tuttavia, in un indice secondario locale, il valore della chiave di ordinamento non deve essere univoco per un determinato valore di chiave di partizione. Se nell'indice secondario locale sono presenti più elementi con lo stesso valore della chiave di ordinamento, un'operazione Query restituisce tutti gli elementi che hanno lo stesso valore della chiave di partizione. Nella risposta, gli articoli corrispondenti non vengono restituiti in un ordine particolare.
È possibile eseguire una query su un indice secondario locale utilizzando letture a consistenza finale o fortemente coerenti. Per specificare il tipo di coerenza desiderato, utilizza il parametro ConsistentRead dell'operazione Query. Una lettura fortemente consistente da un indice secondario locale restituisce sempre gli ultimi valori aggiornati. Se la query deve recuperare attributi aggiuntivi dalla tabella di base, tali attributi saranno coerenti rispetto all'indice.
Esempio
Valuta i seguenti dati restituiti da una Query che richiede dati dai thread di discussione in un particolare forum.
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
In questa query:
-
DynamoDB accede a
LastPostIndexutilizzando la chiave di partizioneForumNameper individuare gli elementi dell'indice per "EC2". Tutti gli elementi dell'indice con questa chiave sono memorizzati l'uno accanto all'altro per il recupero rapido. -
All'interno di questo forum, DynamoDB utilizza l'indice per cercare le chiavi che corrispondono alla condizione
LastPostDateTimespecificata. -
Poiché l'attributo
Repliesviene proiettato nell'indice, DynamoDB è in grado di recuperare questo attributo senza utilizzare alcuna velocità effettiva assegnata aggiuntiva. -
L'attributo
Tagsnon viene proiettato nell'indice, quindi DynamoDB deve accedere alla tabellaThreade recuperare questo attributo. -
I risultati vengono restituiti, ordinati per
LastPostDateTime. Le voci dell'indice vengono ordinate in base al valore della chiave di partizione e quindi in base al valore della chiave di ordinamento eQueryli restituisce nell'ordine in cui sono memorizzati. È possibile utilizzare il parametroScanIndexForwardper restituire i risultati in ordine decrescente.
Poiché l'attributo Tags non viene proiettato nell'indice secondario locale, DynamoDB deve consumare unità di capacità di lettura aggiuntive per recuperare questo attributo dalla tabella di base. Se è necessario eseguire spesso questa query, è necessario proiettare Tags in LastPostIndex per evitare il recupero dalla tabella di base. Tuttavia, se è necessario accedere a Tags solo occasionalmente, il costo di archiviazione aggiuntivo per la proiezione Tags nell'indice potrebbe non valere la pena.
Scansione di un indice secondario locale
È possibile utilizzare l'operazione Scan per recuperare tutti i dati da un indice secondario globale. Devi fornire il nome della tabella di base e il nome dell'indice nella richiesta. Con un'operazione Scan, DynamoDB legge tutti i dati nell'indice e li restituisce all'applicazione. Inoltre puoi richiedere che vengano restituiti solo alcuni dati e che quelli rimanenti vengano eliminati. A questo scopo, utilizza il parametro FilterExpression dell'API Scan. Per ulteriori informazioni, consulta Espressioni di filtro per la scansione.
Scritture di elementi e indici secondari locali
DynamoDB conserva automaticamente tutti gli indici secondari locali sincronizzati con le rispettive tabelle di base. Le applicazioni non scrivono mai direttamente in un indice. Tuttavia, è importante comprendere le implicazioni di come DynamoDB mantiene questi indici.
Quando si crea un indice secondario locale, viene specificato un attributo da utilizzare come chiave di ordinamento per l'indice. È inoltre possibile specificare un tipo di dati per tale attributo. Questo significa che ogni volta che si scrive un elemento nella tabella di base, se l'elemento definisce un attributo della chiave di indice, il relativo tipo deve corrispondere al tipo di dati dello schema della chiave di indice. Nel caso di LastPostIndex, la chiave di ordinamento LastPostDateTime nell'indice è definita come un tipo di dati String. Se si prova ad aggiungere un elemento alla tabella Thread e si specifica un tipo di dati diverso per LastPostDateTime (come Number), DynamoDB restituisce un ValidationException perché il tipo di dati non corrisponde.
Non è necessaria una relazione uno-a-uno tra gli elementi di una tabella di base e gli elementi di un indice secondario locale. In effetti, questo comportamento può essere vantaggioso per molte applicazioni.
Una tabella con molti indici secondari globali comporta costi maggiori per l'attività di scrittura rispetto alle tabelle con meno indici. Per ulteriori informazioni, consulta Considerazioni sulla velocità di trasmissione effettiva assegnata per indici secondari locali.
Importante
Per le tabelle con gli indici secondari locali, esiste un limite di 10 GB per valore di chiave di partizione. Una tabella con indici secondari locali può memorizzare qualsiasi numero di elementi, a condizione che la dimensione totale per qualsiasi valore di una chiave di partizione non superi 10 GB. Per ulteriori informazioni, consulta Limite delle dimensioni delle raccolte di elementi.
Considerazioni sulla velocità di trasmissione effettiva assegnata per indici secondari locali
Quando si crea una tabella in DynamoDB, vengono assegnate le unità di capacità di lettura e scrittura per il carico di lavoro previsto della tabella. Tale carico di lavoro include attività di lettura e scrittura sugli indici secondari locali della tabella.
Per visualizzare le tariffe correnti per la capacità di throughput assegnata, consulta Prezzi di Amazon DynamoDB
Unità di capacità in lettura
Quando si esegue una query su un indice secondario locale, il numero di unità di capacità di lettura utilizzate dipende dal modo in cui si accede ai dati.
Come per le query su una tabella, una query su un indice può utilizzare letture a consistenza finale o fortemente consistenti a seconda del valore di ConsistentRead. Una lettura fortemente consistente utilizza una unità di capacità di lettura mentre una lettura a consistenza finale ne consuma solo la metà. Pertanto, scegliendo letture a consistenza finale, è possibile ridurre i costi delle unità di capacità di lettura.
Per le query su un indice che richiedono solo chiavi di indice e attributi proiettati, DynamoDB calcola l'attività di lettura assegnata come avviene per le query sulle tabelle. L'unica differenza è che il calcolo si basa sulle dimensioni delle voci dell'indice, piuttosto che sulla dimensione dell'item nella tabella di base. Il numero di unità di capacità in lettura è la somma di tutte le dimensioni degli attributi proiettati di tutti gli elementi restituiti; il risultato viene quindi arrotondato al successivo limite di 4 KB. Per ulteriori informazioni sul modo in cui DynamoDB calcola l'uso della velocità effettiva assegnata, consulta Modalità con capacità allocata di DynamoDB.
Per le query sugli indici che leggono gli attributi non proiettati sull'indice secondario locale, oltre a leggere gli attributi proiettati dall'indice DynamoDB deve recuperare tali attributi dalla tabella di base. Questi recuperi si verificano quando si includono attributi non proiettati nei parametri Select o ProjectionExpression dell'operazione Query. Il recupero causa una latenza aggiuntiva nelle risposte alle query e comporta anche un costo della velocità effettiva assegnata più elevato: oltre alle letture dall'indice secondario locale descritto in precedenza, vengono addebitate le unità di capacità di lettura per ogni elemento della tabella di base recuperato. Questo addebito è per la lettura di ogni elemento intero dalla tabella, non solo degli attributi richiesti.
La dimensione massima dei risultati restituiti da un'operazione Query è 1 MB. Sono incluse le dimensioni di tutti i nomi e i valori degli attributi in tutti gli elementi restituiti. Tuttavia, se una query su un indice secondario locale fa sì che DynamoDB recuperi gli attributi dell'elemento dalla tabella di base, la dimensione massima dei dati nei risultati potrebbe essere inferiore. In questo caso, la dimensione del risultato è la somma di:
-
La dimensione degli elementi corrispondenti nell'indice, arrotondata per eccesso ai 4 KB successivi.
-
La dimensione di ogni elemento corrispondente nella tabella di base, con ogni elemento arrotondato singolarmente ai 4 KB successivi.
Utilizzando questa formula, la dimensione massima dei risultati restituiti da un'operazione Query è comunque 1 MB.
Ad esempio, si consideri una tabella in cui la dimensione di ogni elemento è 300 byte. Su quella tabella è presente un indice secondario locale, ma solo 200 byte di ogni elemento vengono proiettati sull'indice. Si supponga adesso che venga eseguita una Query su questo indice, che la query richieda recuperi di tabella per ogni elemento e che la query restituisca 4 elementi. DynamoDB riassume quanto segue:
-
Dimensione degli elementi corrispondenti nell'indice: 200 byte × 4 elementi = 800 byte; questo valore viene quindi arrotondato a 4 KB.
-
Dimensione di ogni elemento corrispondente nella tabella di base: (300 byte, arrotondato a 4 KB) × 4 elementi = 16 KB.
La dimensione totale dei dati nel risultato è pertanto 20 KB.
Unità di capacità in scrittura
Quando un elemento viene aggiunto, aggiornato o eliminato in una tabella, l'aggiornamento degli indici secondari locali utilizza le unità di capacità di scrittura assegnate per la tabella. Il costo totale della velocità effettiva assegnata per una scrittura è la somma delle unità di capacità di scrittura utilizzate scrivendo sulla tabella e di quelle utilizzate dall'aggiornamento degli indici secondari locali.
Il costo della scrittura di un elemento in un indice secondario locale dipende da diversi fattori:
-
Se scrivi un nuovo item nella tabella che definisce un attributo indicizzato o aggiorni un item esistente per definire un attributo indicizzato in precedenza non definito, è necessario eseguire un'operazione di scrittura per inserire l'item nell'indice.
-
Se un aggiornamento alla tabella modifica il valore di un attributo chiave indicizzato (da A a B), sono necessarie due scritture, una per eliminare l'elemento precedente dall'indice e un'altra per inserire il nuovo elemento nell'indice.
-
Se un item era presente nell'indice, ma una scrittura nella tabella ha causato la cancellazione dell'attributo indicizzato, è necessaria una scrittura per eliminare la proiezione dell'item precedente dall'indice.
-
Se un item non è presente nell'indice prima o dopo l'aggiornamento dell'item, non vi è alcun costo di scrittura aggiuntivo per l'indice.
Tutti questi fattori presuppongono che la dimensione di ciascun elemento nell'indice sia minore o uguale alla dimensione dell'elemento di 1 KB per il calcolo delle unità di capacità di scrittura. Le voci di indice più grandi richiedono unità di capacità in scrittura aggiuntive. È possibile ridurre al minimo i costi di scrittura considerando gli attributi che le query devono restituire e proiettando solo tali attributi nell'indice.
Considerazioni sull'archiviazione per indici secondari locali
Quando un'applicazione scrive un elemento in una tabella, DynamoDB copia automaticamente il sottoinsieme di attributi corretto in qualsiasi indice secondario locale in cui devono essere presenti gli attributi. All' AWS account vengono addebitati i costi per la memorizzazione dell'elemento nella tabella di base e anche per l'archiviazione degli attributi in qualsiasi indice secondario locale di tale tabella.
La quantità di spazio utilizzata da un item dell'indice è la somma di quanto segue:
-
La dimensione in byte della chiave primaria della tabella di base (chiave di partizione e chiave di ordinamento)
-
La dimensione in byte dell'attributo della chiave di indicizzazione
-
La dimensione in byte degli attributi proiettati (se presenti)
-
100 byte di sovraccarico per elemento dell'indice
Per stimare i requisiti di archiviazione per un indice secondario locale, è possibile stimare la dimensione media di un elemento nell'indice e quindi moltiplicarla per il numero di elementi nella tabella di base.
Se una tabella contiene un elemento in cui non è definito un attributo specifico, ma l'attributo è definito come una chiave di ordinamento dell'indice, DynamoDB non scrive alcun dato per tale elemento nell'indice.
Raccolte di elementi negli indici secondari locali
Nota
In questa sezione vengono trattate solo le tabelle con indici secondari locali.
In DynamoDB, una raccolta di elementi è un gruppo di elementi in che hanno lo stesso valore della chiave di partizione in una tabella e in tutti gli indici secondari locali. Negli esempi utilizzati in tutta questa sezione, la chiave di partizione per la tabella Thread è ForumName e la chiave di partizione per LastPostIndex è anch'essa ForumName. Tutti gli elementi della tabella e dell'indice con lo stesso ForumName fanno parte della stessa raccolta di elementi. Ad esempio, nella tabella Thread e nell'indice secondario locale LastPostIndex esiste una raccolta di elementi per il forum EC2 e una raccolta di elementi diversa per il forum RDS.
Il seguente diagramma mostra la raccolta di elementi per il forum S3.
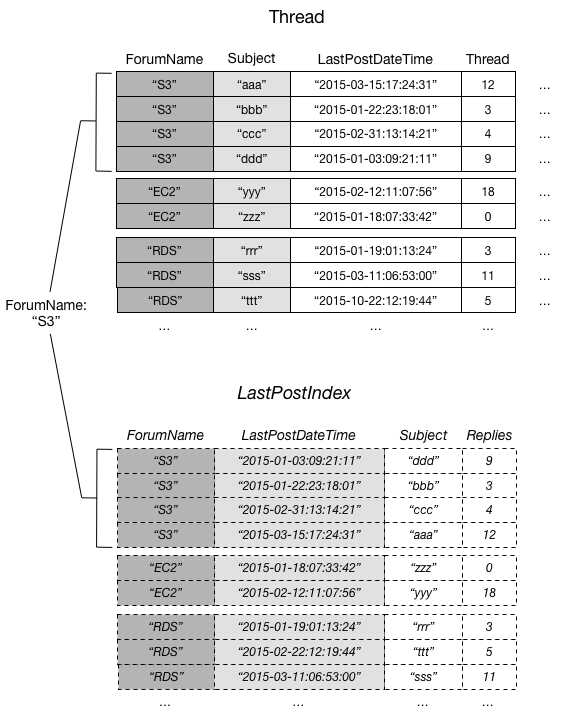
In questo diagramma, la raccolta di elementi è costituita da tutti gli elementi in Thread e LastPostIndex dove il valore della chiave di partizione ForumName è "S3". Se nella tabella sono presenti altri indici secondari locali, tutti gli elementi in tali indici con ForumName uguale a "S3" fanno parte della raccolta di elementi.
È possibile utilizzare una delle seguenti operazioni in DynamoDB per restituire informazioni sulle raccolte di elementi:
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
Ognuna di queste operazioni supporta il parametro ReturnItemCollectionMetrics. Quando si .imposta questo parametro su SIZE, è possibile visualizzare informazioni sulle dimensioni di ogni raccolta di elementi nell'indice.
Esempio
Di seguito è riportato un esempio dall'output di una operazione UpdateItem sulla tabella Thread, con ReturnItemCollectionMetrics impostato su SIZE. L'elemento che è stato aggiornato aveva un valore di ForumName pari a "EC2", quindi l'output include informazioni su tale raccolta di elementi.
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
L'oggetto SizeEstimateRangeGB indica che la dimensione di questa raccolta di elementi è compresa tra 0 e 1 GB. DynamoDB aggiorna periodicamente questa stima delle dimensioni, quindi i numeri potrebbero essere diversi la volta successiva che l'elemento viene modificato.
Limite delle dimensioni delle raccolte di elementi
La dimensione massima di qualsiasi raccolta di elementi per una tabella con uno o più indici secondari locali è di 10 GB. Ciò non si applica alle raccolte di elementi nelle tabelle senza indici secondari locali e non si applica alle raccolte di elementi negli indici secondari globali. Sono interessate solo le tabelle con uno o più indici secondari locali.
Se una raccolta di elementi supera il limite di 10 GB, DynamoDB potrebbe restituire ItemCollectionSizeLimitExceededException un elemento e l'utente potrebbe non essere in grado di aggiungere altri elementi alla raccolta di elementi o aumentare le dimensioni degli elementi presenti nella raccolta di elementi. Le operazioni di lettura e scrittura che riducono le dimensioni della raccolta di elementi sono ancora consentite. Gli elementi possono comunque essere aggiunti ad altre raccolte di elementi.
Per ridurre le dimensioni di una raccolta di elementi, è possibile procedere in uno dei seguenti modi:
-
Eliminare eventuali elementi non necessari con il valore della chiave di partizione in questione. Quando si eliminano questi elementi dalla tabella di base, DynamoDB rimuove anche tutte le voci di indice che hanno lo stesso valore della chiave di partizione.
-
Aggiorna gli elementi rimuovendo gli attributi o riducendo le dimensioni degli attributi. Se questi attributi sono proiettati su qualsiasi indice secondario locale, DynamoDB riduce anche la dimensione delle voci di indice corrispondenti.
-
Crea una nuova tabella con la stessa chiave di partizione e la stessa chiave di ordinamento, quindi sposta gli elementi dalla tabella precedente alla nuova tabella. Questo potrebbe essere un buon approccio se una tabella dispone di dati cronologici a cui si accede raramente. È possibile anche considerare l'archiviazione di questi dati della cronologia in Amazon Simple Storage Service (Amazon S3).
Quando la dimensione totale della raccolta di elementi scende al di sotto di 10 GB, è possibile aggiungere nuovamente elementi con lo stesso valore della chiave di partizione.
Come best practice, consigliamo di strumentalizzare l'applicazione in modo da monitorare le dimensioni delle raccolte di elementi. Un modo per farlo è impostare il parametro ReturnItemCollectionMetrics su SIZEogni volta che si utilizza BatchWriteItem, DeleteItem, PutItem o UpdateItem. L'applicazione dovrebbe esaminare l'oggetto ReturnItemCollectionMetrics nell'output e registrare un messaggio di errore ogni volta che una raccolta di elementi supera un limite definito dall'utente (ad esempio, 8 GB). L'impostazione di un limite inferiore a 10 GB fornirebbe un sistema di avviso anticipato in modo da sapere che una raccolta di elementi si sta avvicinando al limite in tempo per intervenire.
Raccolte di elementi e partizioni
In una tabella con uno o più indici secondari locali, ogni raccolta di elementi viene archiviata in una partizione. La dimensione totale di tale raccolta di elementi è limitata alla capacità di quella partizione: 10 GB. Per un'applicazione in cui il modello di dati include raccolte di elementi con dimensioni illimitate o in cui si potrebbe ragionevolmente aspettarsi che alcune raccolte di elementi crescano oltre i 10 GB in futuro, è consigliabile prendere in considerazione l'utilizzo di un indice secondario globale.
Progettare le applicazioni in modo che i dati della tabella siano distribuiti uniformemente tra valori distinti della chiave di partizione. Per le tabelle con indici secondari locali, le applicazioni non devono creare "hot spot" di attività di lettura e scrittura all'interno di una singola raccolta di elementi su una singola partizione.
