Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Quando è necessario interrogare dati recenti entro una finestra temporale specifica, il requisito di DynamoDB di fornire una chiave di partizione per la maggior parte delle operazioni di lettura può rappresentare una sfida. Per risolvere questo scenario, è possibile implementare un modello di query efficace utilizzando una combinazione di write sharding e un Global Secondary Index (GSI).
Questo approccio consente di recuperare e analizzare in modo efficiente i dati sensibili al fattore tempo senza eseguire scansioni complete delle tabelle, che possono richiedere molte risorse e costi. Progettando strategicamente la struttura e l'indicizzazione delle tabelle, è possibile creare una soluzione flessibile che supporti il recupero dei dati basato sul tempo, mantenendo al contempo prestazioni ottimali.
Argomenti
Progettazione del modello
Quando lavori con DynamoDB, puoi superare le sfide del recupero dei dati basato sul tempo implementando un modello sofisticato che combina lo sharding di scrittura e gli indici secondari globali per consentire l'interrogazione flessibile ed efficiente su finestre di dati recenti.
Struttura della tabella
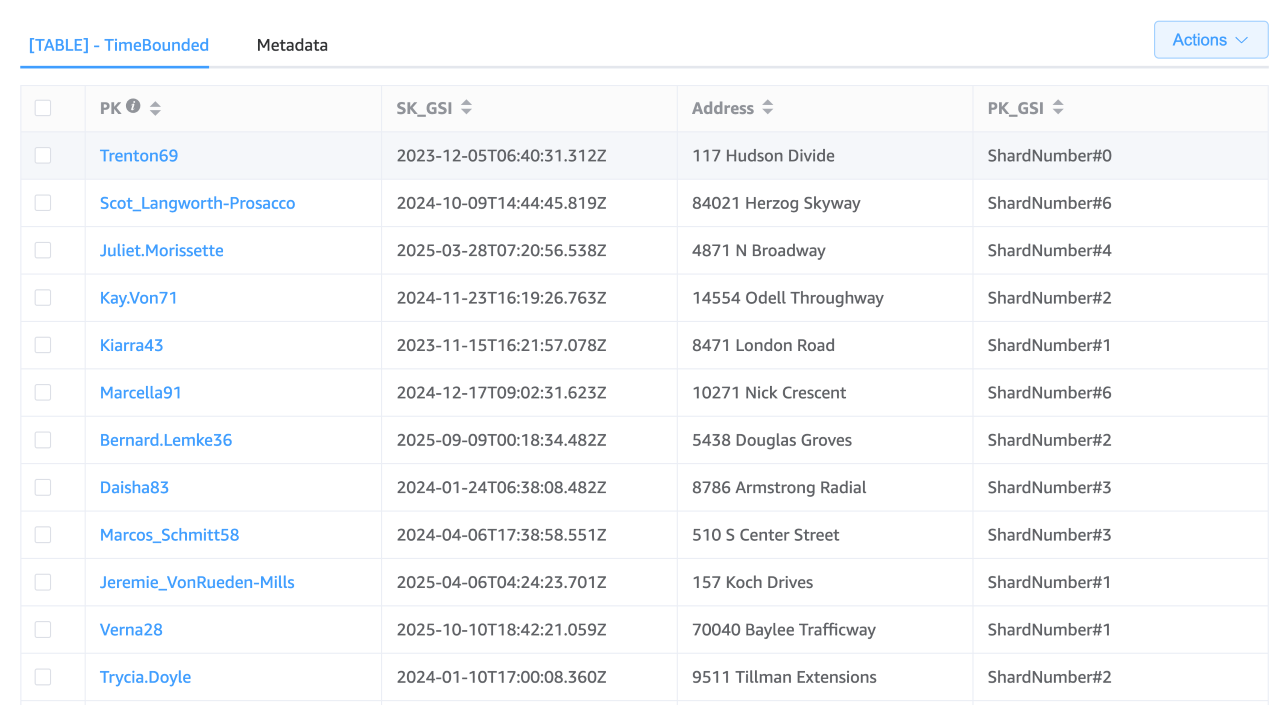
Chiave di partizione (PK): «Nome utente»
Struttura del GSI
Chiave di partizione GSI (PK_GSI): "#» ShardNumber
Chiave di ordinamento GSI (SK_GSI): timestamp ISO 8601 (ad esempio, «2030-04-01T 12:00:00 Z»)
Strategia di condivisione
Supponendo che tu decida di utilizzare 10 frammenti, i numeri dei frammenti potrebbero variare da 0 a 9. Quando si registra un'attività, è necessario calcolare il numero di shard (ad esempio, utilizzando una funzione hash sull'ID utente e quindi prendendo il modulo del numero di shard) e anteponendolo alla chiave di partizione GSI. Questo metodo distribuisce le voci su diversi shard, mitigando il rischio di partizioni calde.
Interrogazione del GSI frammentato
L'interrogazione su tutti gli shard per gli elementi all'interno di un determinato intervallo di tempo in una tabella DynamoDB, in cui i dati sono condivisi su più chiavi di partizione, richiede un approccio diverso rispetto all'interrogazione di una singola partizione. Poiché le query DynamoDB sono limitate a una singola chiave di partizione alla volta, non è possibile eseguire query direttamente su più shard con una singola operazione di query. Tuttavia, è possibile ottenere il risultato desiderato tramite la logica a livello di applicazione eseguendo più query, ciascuna mirata a uno shard specifico, e quindi aggregando i risultati. La procedura riportata di seguito spiega come eseguire questa operazione.
Per interrogare e aggregare frammenti
Identifica la gamma di numeri di frammenti utilizzati nella tua strategia di sharding. Ad esempio, se hai 10 frammenti, i numeri dei frammenti andrebbero da 0 a 9.
Per ogni shard, costruisci ed esegui una query per recuperare gli elementi entro l'intervallo di tempo desiderato. Queste interrogazioni possono essere eseguite in parallelo per migliorare l'efficienza. Usa la chiave di partizione con il numero dello shard e la chiave di ordinamento con l'intervallo di tempo per queste query. Ecco un esempio di query per un singolo shard:
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'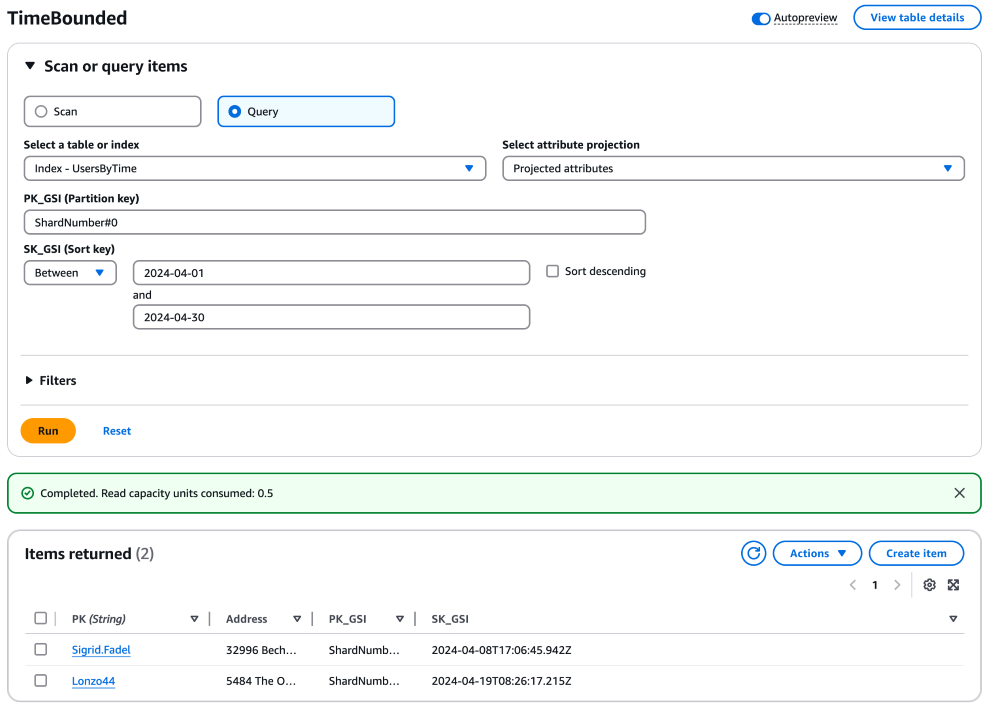
Dovresti replicare questa query per ogni shard, regolando la chiave di partizione di conseguenza (ad esempio, "ShardNumber#1 «," ShardNumber #2 «,...," #9 «). ShardNumber
Aggrega i risultati di ogni query dopo che tutte le query sono state completate. Eseguite questa aggregazione nel codice dell'applicazione, combinando i risultati in un unico set di dati che rappresenta gli elementi di tutti gli shard entro l'intervallo di tempo specificato.
Considerazioni sull'esecuzione parallela delle query
Ogni query consuma la capacità di lettura della tabella o dell'indice. Se utilizzi un throughput assegnato, assicurati che la tabella disponga di una capacità sufficiente per gestire la raffica di query parallele. Se utilizzi la capacità on-demand, tieni presente le potenziali implicazioni in termini di costi.
esempio di codice
Per eseguire query parallele su shard in DynamoDB usando Python, puoi usare la libreria boto3, che è l'Amazon Web Services SDK per Python. Questo esempio presuppone che boto3 sia installato e configurato con le credenziali appropriate. AWS
Il seguente codice Python dimostra come eseguire query parallele su più shard per un determinato intervallo di tempo. Utilizza futures simultanei per eseguire query in parallelo, riducendo il tempo di esecuzione complessivo rispetto all'esecuzione sequenziale.
import boto3
from concurrent.futures import ThreadPoolExecutor, as_completed
# Initialize a DynamoDB client
dynamodb = boto3.client('dynamodb')
# Define your table name and the total number of shards
table_name = 'YourTableName'
total_shards = 10 # Example: 10 shards numbered 0 to 9
time_start = "2030-03-15T09:00:00Z"
time_end = "2030-03-15T10:00:00Z"
def query_shard(shard_number):
"""
Query items in a specific shard for the given time range.
"""
response = dynamodb.query(
TableName=table_name,
IndexName='YourGSIName', # Replace with your GSI name
KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end",
ExpressionAttributeValues={
":pk_val": {"S": f"ShardNumber#{shard_number}"},
":date_start": {"S": time_start},
":date_end": {"S": time_end},
}
)
return response['Items']
# Use ThreadPoolExecutor to query across shards in parallel
with ThreadPoolExecutor(max_workers=total_shards) as executor:
# Submit a future for each shard query
futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)}
# Collect and aggregate results from all shards
all_items = []
for future in as_completed(futures):
shard_number = futures[future]
try:
shard_items = future.result()
all_items.extend(shard_items)
print(f"Shard {shard_number} returned {len(shard_items)} items")
except Exception as exc:
print(f"Shard {shard_number} generated an exception: {exc}")
# Process the aggregated results (e.g., sorting, filtering) as needed
# For example, simply printing the count of all retrieved items
print(f"Total items retrieved from all shards: {len(all_items)}")Prima di eseguire questo codice, assicurati di sostituire YourTableName e YourGSIName con la tabella e i nomi GSI effettivi della configurazione di DynamoDB. Inoltre total_shardstime_start, regolate time_end le variabili in base alle vostre esigenze specifiche.
Questo script interroga ogni frammento alla ricerca di elementi entro l'intervallo di tempo specificato e aggrega i risultati.
