Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio degli aggiornamenti dello stato dei dispositivi in DynamoDB
In questo caso d'uso viene descritto l'utilizzo di DynamoDB per monitorare gli aggiornamenti dello stato del dispositivo (o le modifiche allo stato del dispositivo) in DynamoDB.
Caso d’uso
Nei casi d'uso dell'IoT (ad esempio una fabbrica intelligente) molti dispositivi devono essere monitorati dagli operatori e inviano periodicamente il proprio stato o i log a un sistema di monitoraggio. Quando si verifica un problema con un dispositivo, lo stato del dispositivo cambia da normale ad avviso. Esistono diversi livelli o stati di log a seconda della gravità e del tipo di comportamento anomalo nel dispositivo. Il sistema incarica quindi un operatore di controllare il dispositivo e, se necessario, può segnalare il problema al proprio supervisore.
Alcuni modelli di accesso tipici per questo sistema includono:
-
Crea una voce di log per un dispositivo
-
Ottieni tutti i log per uno stato specifico del dispositivo, mostrando per primi i log più recenti
-
Ottieni tutti i log di un determinato operatore tra due date
-
Ottieni tutti i log inoltrati per un determinato supervisore
-
Ottieni tutti i log inoltrati con uno stato specifico del dispositivo per un determinato supervisore
-
Ottieni tutti i log inoltrati con uno stato specifico del dispositivo per un determinato supervisore e per una data specifica
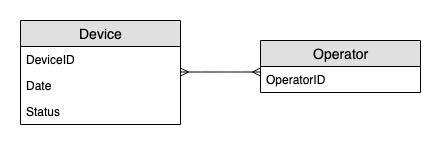
Diagramma delle relazioni tra entità
Questo è il diagramma di relazione delle entità (ERD) ch useremo per monitorare gli aggiornamenti dello stato dei dispositivi.
Modelli di accesso
Questi sono i modelli di accesso che prenderemo in considerazione per monitorare gli aggiornamenti dello stato dei dispositivi.
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
Evoluzione della progettazione dello schema
Fase 1: Gestire i modelli di accesso 1 (createLogEntryForSpecificDevice) e 2 (getLogsForSpecificDevice)
L'unità di dimensionamento per un sistema di tracciamento dei dispositivi sarebbe costituita dai singoli dispositivi. In questo sistema, deviceID identifica in modo univoco un dispositivo. Questo rende deviceID un buon candidato per la chiave di partizione. Ogni dispositivo invia informazioni al sistema di tracciamento periodicamente (ad esempio ogni cinque minuti circa). Questo ordinamento rende la data un criterio di ordinamento logico e quindi la chiave di ordinamento. I dati di esempio in questo caso apparirebbero simili a:
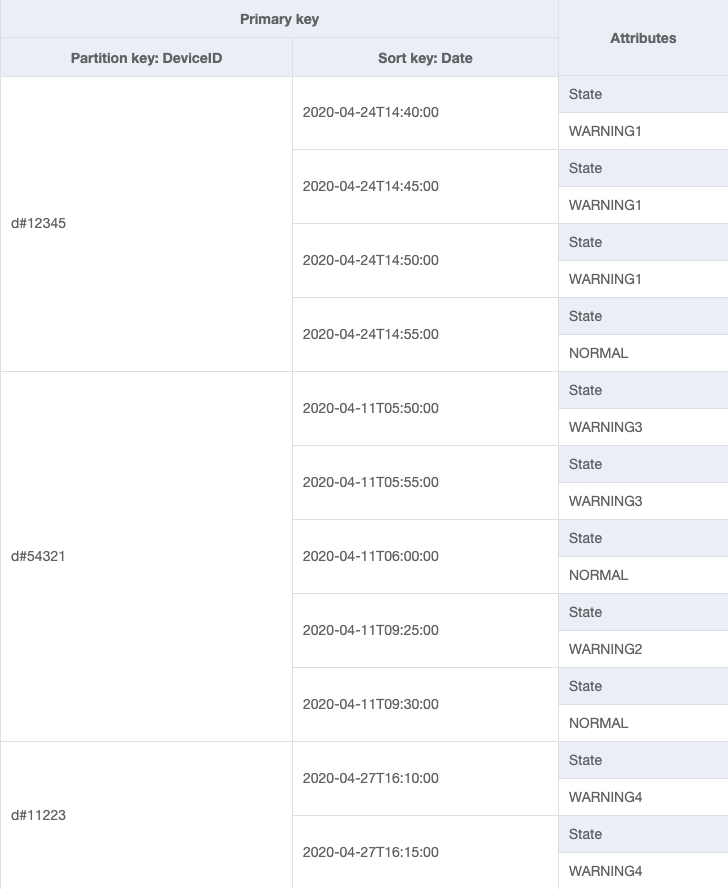
Per recuperare le voci di log per un dispositivo specifico, possiamo eseguire un’operazione di query con la chiave di partizione DeviceID="d#12345".
Fase 2: Gestire il modello di accesso 3 (getWarningLogsForSpecificDevice)
Poiché State è un attributo non chiave, affrontare il pattern di accesso 3 con lo schema corrente richiederebbe un’espressione di filtro. In DynamoDB, le espressioni di filtro vengono applicate dopo la lettura dei dati utilizzando le espressioni delle condizioni chiave. Ad esempio, se si dovessero recuperare i registri dei log per d#12345, l’operazione di query con chiave di partizione DeviceID="d#12345" leggerà quattro elementi dalla tabella precedente e poi filtrerà l’unico elemento senza lo stato di avviso. Questo approccio non è efficiente su larga scala. Un'espressione di filtro può essere un buon modo per escludere gli elementi interrogati se il rapporto tra gli elementi esclusi è basso o la query viene eseguita di rado. Tuttavia, nei casi in cui molti elementi vengono recuperati da una tabella e la maggior parte degli elementi viene filtrata, possiamo continuare a sviluppare il design della tabella in modo che funzioni in modo più efficiente.
Cambiamo come gestire questo modello di accesso utilizzando chiavi di ordinamento composte. È possibile importare dati di esempio da DeviceStateLog_3.json in cui è stataState#Date Questa chiave di ordinamento è la composizione degli attributi State, # e Date. In questo caso, # viene usato come un delimitatore. L'aspetto dei dati è ora il seguente:
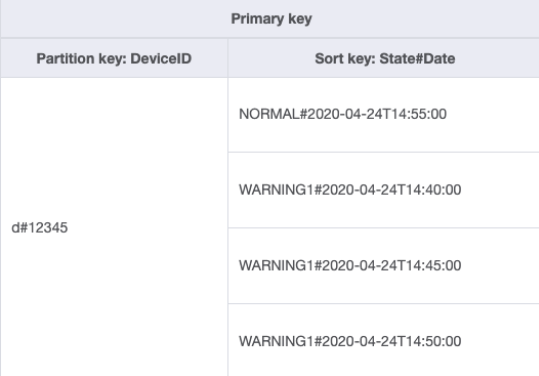
Per recuperare solo i log degli avvisi per un dispositivo, la query diventa più mirata con questo schema. La condizione chiave per la query utilizza la chiave di partizione DeviceID="d#12345" e la chiave di ordinamento State#Date begins_with
“WARNING”. Questa interrogazione leggerà solo i tre elementi pertinenti con lo stato di avviso.
Fase 3: Gestire il modello di accesso 4 (getLogsForOperatorBetweenTwoDates)
È possibile importare DeviceStateLog_4.jsonOperatorattributo è stato aggiunto alla tabella con dati di esempio. DeviceStateLog
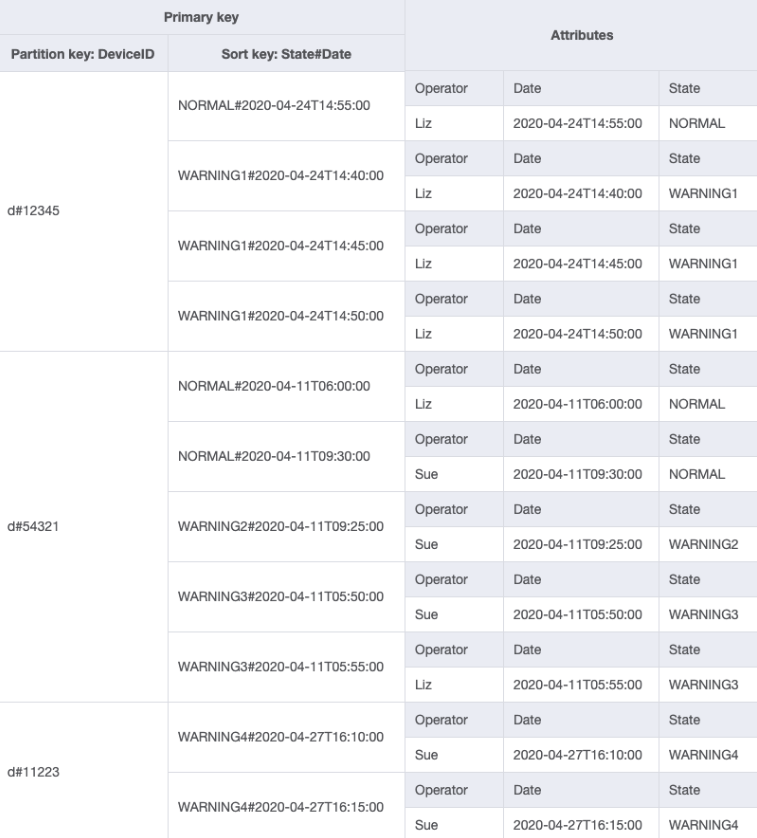
Poiché Operator attualmente non è una chiave di partizione, non è possibile eseguire una ricerca diretta chiave-valore su questa tabella basata su OperatorID. Dovremo creare una nuova collezione di articoli con un indice secondario globale su OperatorID. Il modello di accesso richiede una ricerca basata sulle date, quindi Data è l'attributo chiave di ordinamento per indice secondario globale (GSI). Ecco come appare ora il GSI:
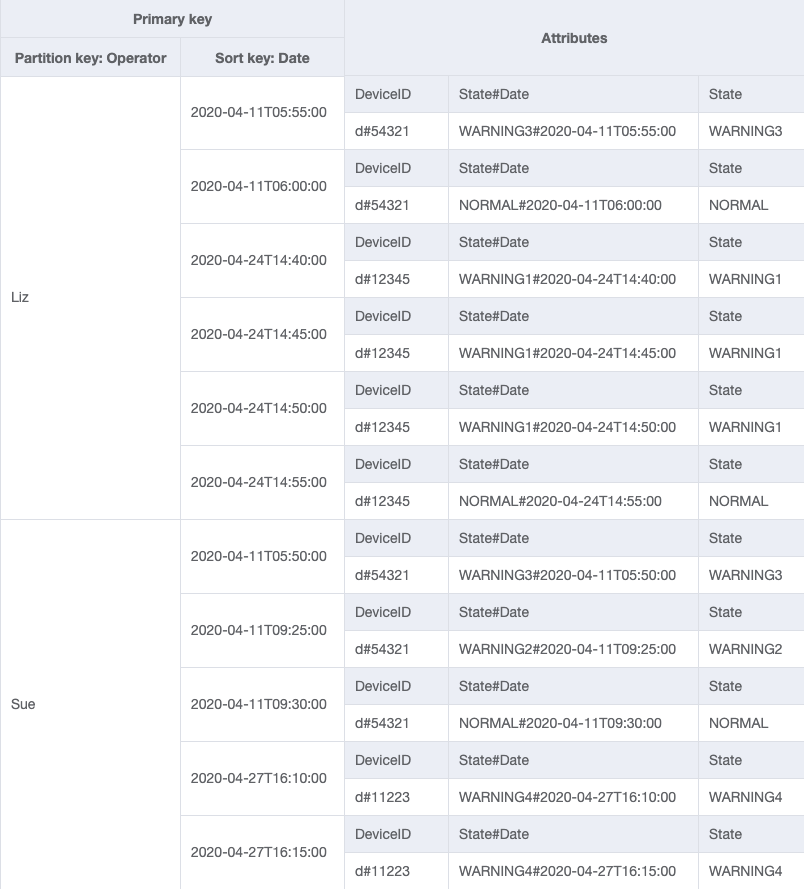
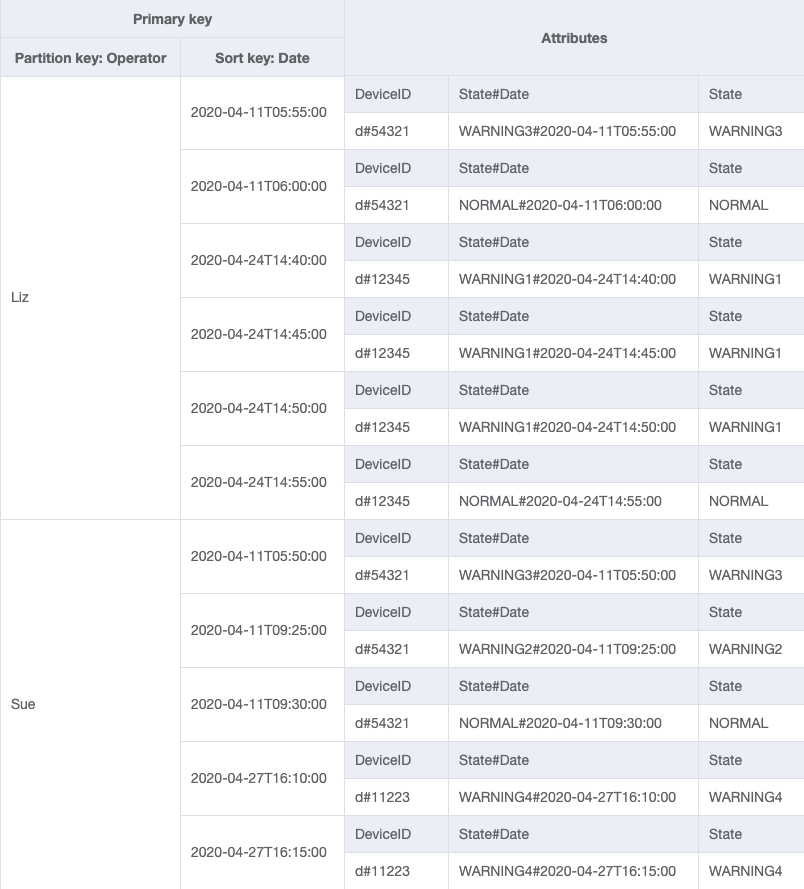
Per il modello di accesso 4 (getLogsForOperatorBetweenTwoDates), puoi interrogare questo GSI con la chiave di partizione OperatorID=Liz e la chiave di ordinamento Date fra 2020-04-11T05:58:00 e 2020-04-24T14:50:00.
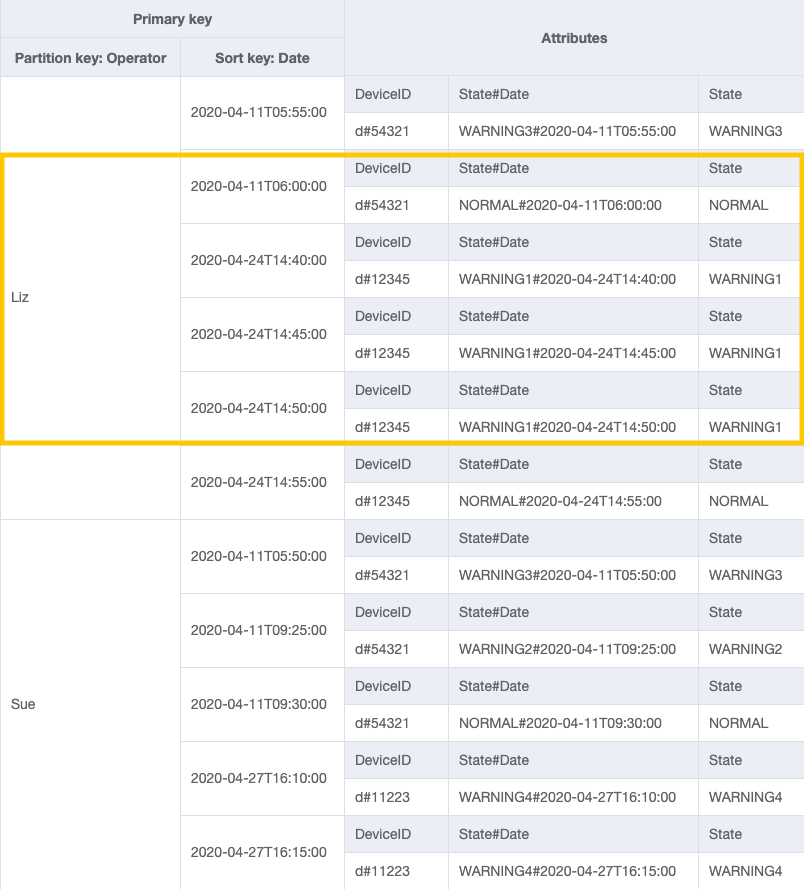
Fase 4: Gestire i modelli di accesso 5 (getEscalatedLogsForSupervisor), 6 (getEscalatedLogsWithSpecificStatusForSupervisor) e 7 (getEscalatedLogsWithSpecificStatusForSupervisorForDate)
Useremo un indice sparso per affrontare questi modelli di accesso.
Per impostazione predefinita, gli indici secondari globali sono sparsi, quindi solo gli elementi della tabella di base che contengono gli attributi della chiave primaria dell'indice verranno effettivamente visualizzati nell'indice. Questo è un altro modo per escludere gli elementi che non sono rilevanti per il modello di accesso da modellare.
Puoi importare DeviceStateLog_6.jsonEscalatedToattributo è stato aggiunto alla DeviceStateLog tabella con dati di esempio. Come accennato in precedenza, non tutti i log vengono inoltrati a un supervisore.
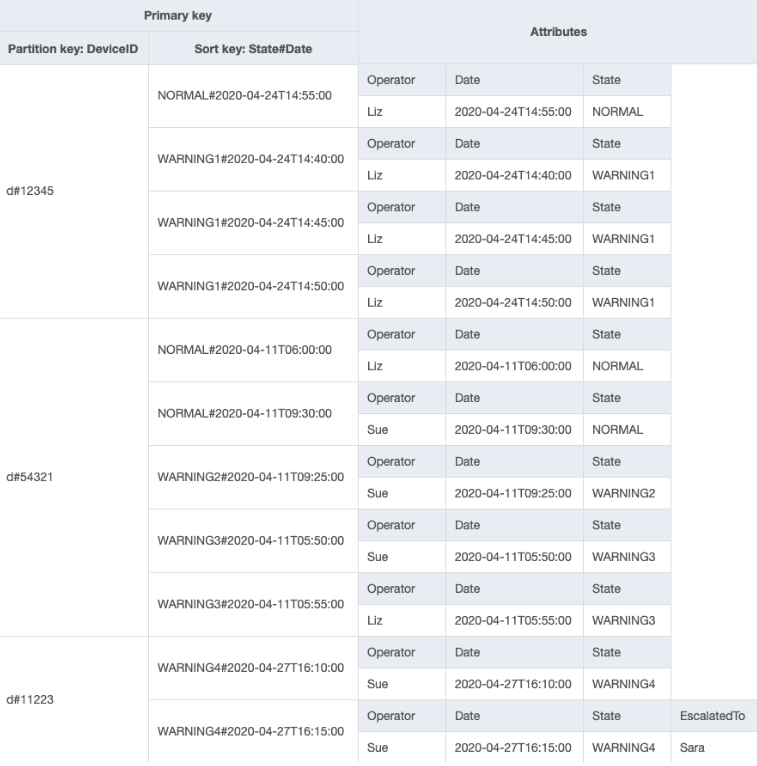
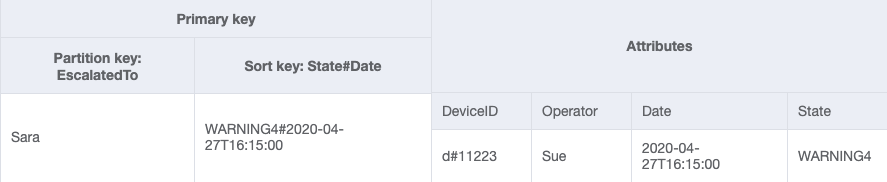
È ora possibile creare un nuovo GSI in cui EscalatedTo è la chiave di partizione e State#Date è la chiave di ordinamento. Nota che solo gli elementi che hanno entrambi gli attributi EscalatedTo e State#Date vengono visualizzati nell'indice.

Gli altri modelli di accesso sono riassunti come segue:
Tutti i modelli di accesso e il modo in cui la progettazione dello schema li affronta sono riassunti nella tabella seguente:
| Modello di accesso | table/GSIBase /LSI | Operation | Valore della chiave di partizione | Valore della chiave di ordinamento | Altro conditions/filters |
|---|---|---|---|---|---|
| creare LogEntryForSpecificDevice | Tabella di base | PutItem | DeviceID=deviceId | State#Date=state#date | |
| ottenere LogsForSpecificDevice | Tabella di base | Query | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = Falso |
| ottenere WarningLogsForSpecificDevice | Tabella di base | Query | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| ottenere LogsForOperatorBetweenTwoDates | GSI-1 | Query | Operator=operatorName | Data compresa tra data1 e data2 | |
| ottenere EscalatedLogsForSupervisor | GSI-2 | Query | EscalatedTo= Nome del supervisore | ||
| ottenere EscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | Query | EscalatedTo= Nome del supervisore | State#Date begins_with "state1#" | |
| ottenere EscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | Query | EscalatedTo= Nome del supervisore | State#Date begins_with "state1#date1" |
Schema finale
Di seguito sono riportate le progettazioni dello schema finale. Per scaricare questo schema come file JSON, consulta Esempi di DynamoDB
Tabella di base
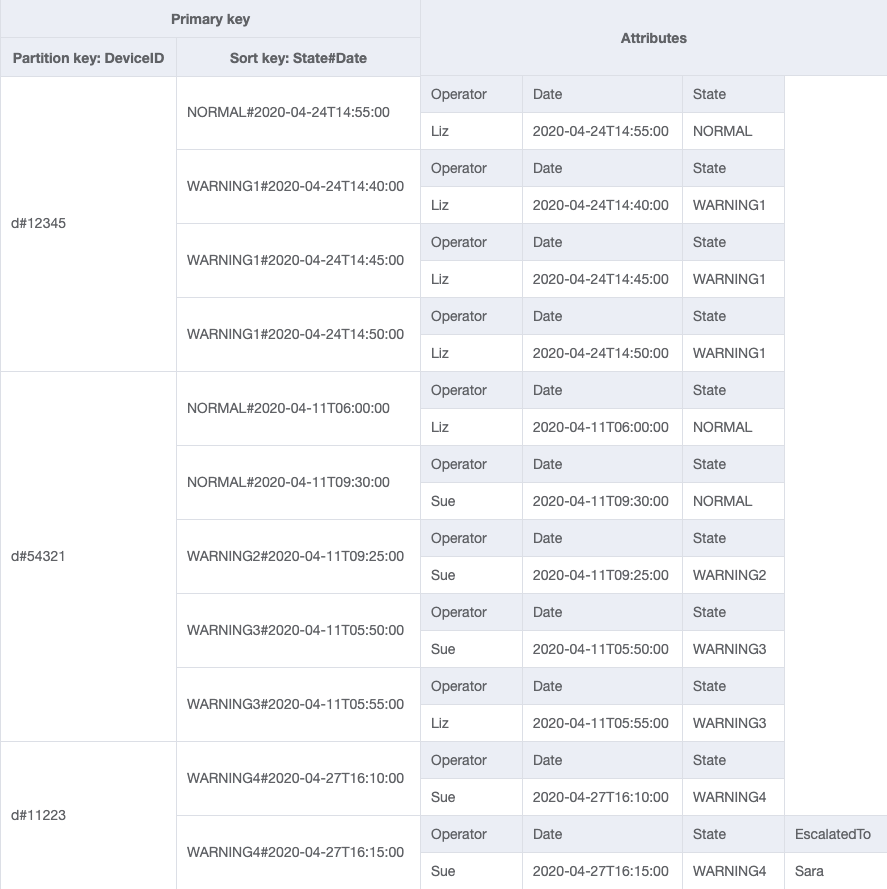
GSI-1
GSI-2
Utilizzo di NoSQL Workbench con questa progettazione dello schema
Puoi importare questo schema finale in NoSQL Workbench, uno strumento visivo che fornisce funzionalità di modellazione dei dati, visualizzazione dei dati e sviluppo di query per DynamoDB, per esplorare e modificare ulteriormente il tuo nuovo progetto. Per iniziare, segui queste fasi:
-
Scarica NoSQL Workbench. Per ulteriori informazioni, consulta Download di NoSQL Workbench per DynamoDB.
-
Scarica il file dello schema JSON elencato in precedenza, che si trova già nel formato del modello NoSQL Workbench.
-
Importa il file dello schema JSON in NoSQL Workbench. Per ulteriori informazioni, consulta Importazione di un modello di dati esistente.
-
Dopo che è stato importato in NOSQL Workbench, puoi modificare il modello di dati. Per ulteriori informazioni, consulta Modifica di un modello di dati esistente.
