Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per la gestione di relazioni molti a molti nelle tabelle DynamoDB
Gli elenchi di adiacenza sono un pattern di progettazione utile per la modellazione di relazioni molti-a-molti in Amazon DynamoDB. Più in generale, forniscono un modo per rappresentare i dati grafici (nodi ed edge) in DynamoDB.
Modello di progettazione elenchi di adiacenza
Quando diverse entità di un'applicazione hanno una relazione molti-a-molti tra di loro, la relazione può essere modellata come un elenco di adiacenza. In questo modello, tutte le entità di primo livello (sinonimi di nodi nel modello grafico) vengono rappresentate utilizzando la chiave di partizione. Qualsiasi relazione con altre entità (edge in un grafico) viene rappresentata come voce in una partizione impostando il valore della chiave di ordinamento sull'ID dell'entità target (nodo target).
I vantaggi di questo modello comprendono una duplicazione minima dei dati e modelli di query semplificati per trovare tutte le entità (nodi) legate a un'entità target (avendo un edge in un nodo target).
Un esempio reale dove questo modello è stato utile è un sistema di fatturazione dove le fatture contengono ricevute multiple. Una ricevuta può appartenere a fatture multiple. La chiave di partizione in questo esempio è un InvoiceID o un BillID. Le partizioni BillID hanno tutti gli attributi specifici delle fatture. Le partizioni InvoiceID hanno una voce che contiene attributi specifici delle fatture e una voce per ogni BillID che si trova nella fattura.
Lo schema ha il seguente aspetto.
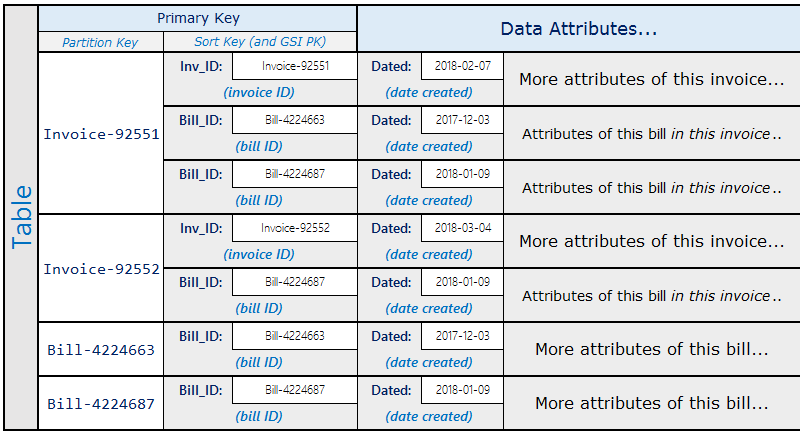
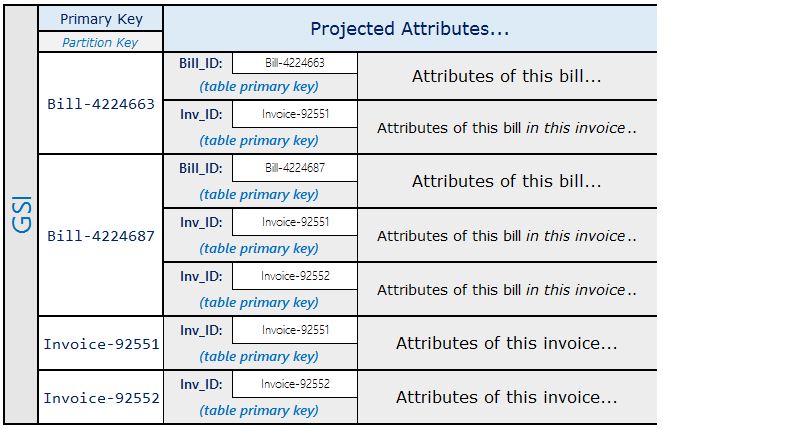
Utilizzando lo schema precedente, puoi vedere che per tutte le ricevute per una fattura può essere eseguita una query utilizzando la chiave primaria nella tabella. Per controllare tutte le fatture che contengono una parte di ricevuta, crea un indice secondario globale nella chiave di ordinamento della tabella.
Le previsioni per l'indice secondario globale hanno il seguente aspetto.
Modello grafico materializzato
Tante applicazioni sono costruite sulla base della comprensione delle classificazioni tra peer, relazioni comuni tra entità, stato entità vicina e altri tipi di flussi di lavoro in stile grafico. Per questi tipi di applicazioni, considera il seguente modello di progettazione dello schema.
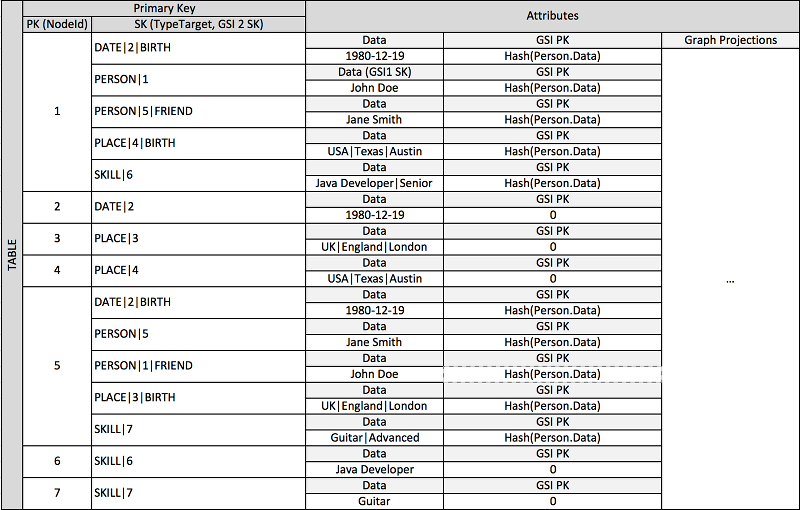
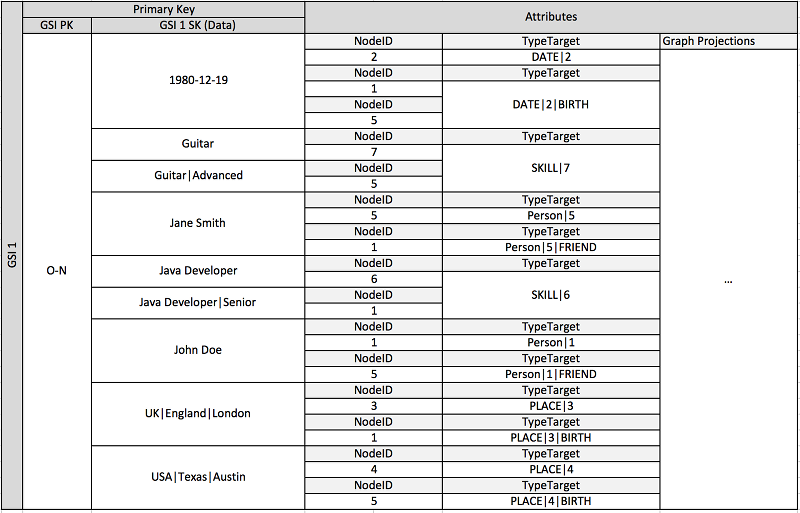
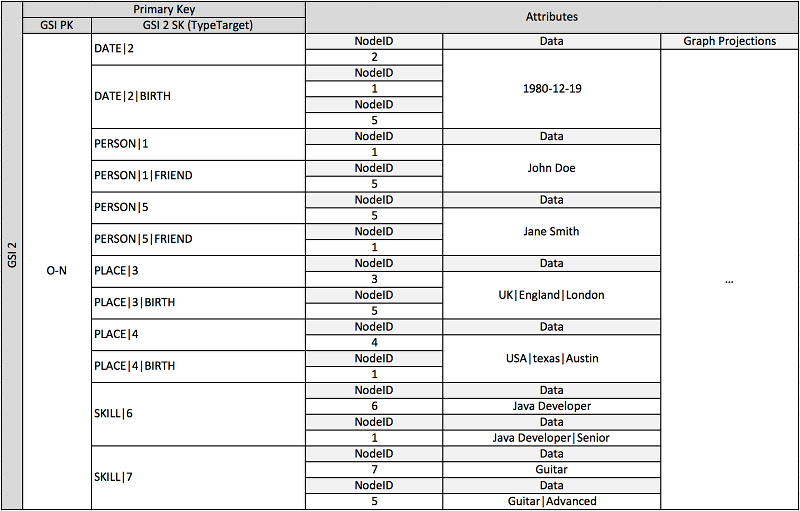
Lo schema precedente mostra una struttura grafica di dati definita da un set di partizioni di dati contenenti le voci che definiscono gli edge e i nodi del grafico. Le voci edge contengono un attributo Target e Type. Questi attributi vengono utilizzati come parte di un nome di chiave composito TypeTarget "" per identificare l'elemento in una partizione della tabella primaria o in un secondo indice secondario globale.
Il primo indice secondario globale è costruito sull'attributo Data. Questo attributo utilizza l'overloading dell'indice secondario globale come descritto in precedenza per indicizzare diversi tipi di attributo, ovvero Dates, Names, Places e Skills. Qui, un indice secondario globale indicizza quattro diversi attributi in modo efficace.
Quando si inseriscono gli elementi nella tabella, è possibile utilizzare una strategia di suddivisione intelligente per distribuire set di elementi con grandi aggregazioni (data di nascita, abilità) su tutte le partizioni logiche degli indici secondari globali necessarie per evitare problemi complessi. read/write
Il risultato di questa combinazione di modelli di design è un datastore solido per flussi di lavoro grafici in tempo reale altamente efficaci. Questi flussi di lavoro possono fornire query di prestazioni alte sullo stato dell'entità vicina e sull'aggregazione degli edge per i motori delle raccomandazioni, le applicazioni di social network, le classifiche dei nodi, le aggregazioni di sottostruttura e altri casi d'uso comuni dei grafici.
Se il tuo caso d'uso non è sensibile alla coerenza dei dati in tempo reale, è possibile utilizzare un processo Amazon EMR programmato per popolare gli edge con aggregazioni di riepilogo grafico rilevanti per i flussi di lavoro. Se la tua applicazione non deve sapere immediatamente quando un edge è aggiunto al grafico, puoi utilizzare un processo programmato per aggregare i risultati.
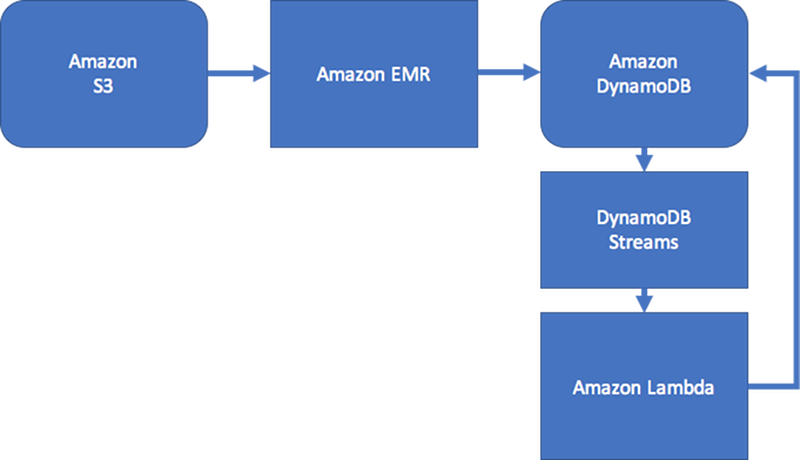
Per mantenere un certo divello di coerenza, la progettazione può includere Amazon DynamoDB Streams e AWS Lambda per elaborare gli aggiornamenti edge. Può anche utilizzare un processo Amazon EMR per convalidare i risultati a un intervallo regolare. Questo approccio viene illustrato nel seguente diagramma. Viene comunemente utilizzato nelle applicazioni di social network dove il costo di una query in tempo reale è alta e la necessità di ottenere aggiornamenti all'utente individuale è bassa.
Le applicazioni di gestione dei servizi IT (ITSM) e di sicurezza in genere devono rispondere in tempo reale alle modifiche all'entità stato composte da aggregazioni degli edge complesse. Tali applicazioni necessitano di un sistema che può supportare aggregazioni dei nodi multiple in tempo reale di relazioni di secondo e terzo livello o elementi trasversali di edge complessi. Se il tuo caso d'uso richiede questi tipi di flusso di lavoro grafici di query in tempo reale, consigliamo l'utilizzo di Amazon Neptune per gestire questi flussi di lavoro.
Nota
Se devi eseguire query sui set di dati altamente connessi o eseguire query che devono attraversare più nodi (note anche come query multi-hop) con una latenza di millisecondi, è opportuno prendere in considerazione l'utilizzo di Amazon Neptune. Amazon Neptune è un motore di database a grafo dedicato e a prestazioni elevate, ottimizzato per conservare miliardi di relazioni e inviare query al grafo con una latenza di millisecondi.
