Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per qualsiasi elemento in una tabella, DynamoDB scrive una voce di indice corrispondente solo se nell'elemento è presente il valore della chiave di ordinamento dell'indice. Se la chiave di ordinamento non appare in tutti gli elementi della tabella o se la chiave di partizione dell'indice non è presente nell'elemento, si dice che l'indice sia sparso.
Gli indici sparse sono utili per query su una sottosezione piccola della tabella. Ad esempio immagina di avere una tabella dove archivi tutti gli ordini dei clienti, con i seguenti attributi di chiave:
-
Chiave di partizione:
CustomerId -
Chiave di ordinamento:
OrderId
Per tracciare gli ordini aperti, è possibile inserire un attributo denominato isOpen negli articoli degli ordini che non sono ancora stati spediti. Poi quando viene spedito l'ordine, puoi eliminare l'attributo. Se poi crei un indice su CustomerId (chiave di partizione) e isOpen (chiave di ordinamento), solo quegli ordini con isOpen definito vi appaiono. Quando hai migliaia di ordini dei quali solo un numero piccolo sono aperti, è più facile e meno costoso eseguire query sull'indice sugli ordini aperti che scannerizzare la tabella intera.
Invece di utilizzare un tipo di attributo come isOpen, è possibile utilizzare un attributo con un valore che risulta in un ordine di ordinamento utile nell'indice. Ad esempio, puoi utilizzare un set di attributi OrderOpenDate per la data in cui è stato effettuato l'ordine e poi eliminarlo dopo che l'ordine è stato consegnato. In quel modo, quando esegui una query sull'indice sparso, le voci vengono restituite ordinate per la data in cui l'ordine è stato effettuato.
Esempi di indici di tipo sparse in DynamoDB
Gli indici secondari globali sono sparse come impostazione predefinita. Quando crei un indice secondario globale, specifica una chiave di partizione e opzionalmente una chiave di ordinamento. Solo voci nella tabella base che contengono quegli attributi appaiono nell'indice.
Progettando che un indice secondario globale sia sparse, puoi assegnargli throughput di scrittura più basso rispetto a quello della tabella base, ottenendo comunque prestazioni eccellenti.
Ad esempio, un'applicazione di gaming può registrare tutti i punteggi di ogni utente, ma in genere deve eseguire delle query solo su alcuni punteggi bassi. La seguente progettazione gestisce questo scenario in modo efficiente:
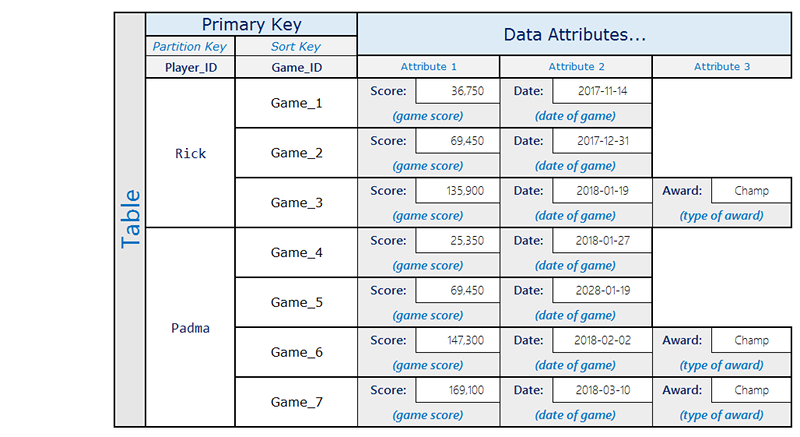
Rick ha giocato tre partite e ottenuto lo stato Champ in una. Padma ha giocato quattro partite e ottenuto lo stato Champ in due. Nota che l'attributo Award è presente solo nelle voci dove l'utente ha ottenuto un premio. L'indice secondario globale associato ha il seguente aspetto:
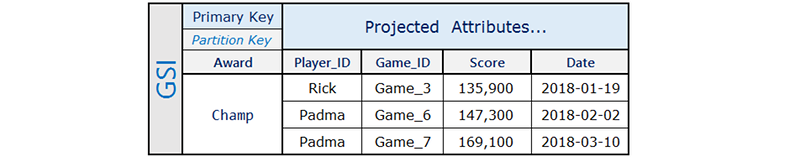
L'indice secondario globale contiene solo i punteggi alti sui quali vengono spesso eseguite delle query, che sono un sottoinsieme piccolo delle voci nella tabella base.
