Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per la gestione dei dati di serie temporali in DynamoDB
I principi di progettazione generali di Amazon DynamoDB consigliano di mantenere al minimo il numero di tabelle utilizzate. Per la maggior parte delle applicazioni, una singola tabella è sufficiente. Tuttavia, spesso è meglio gestire i dati delle serie temporali usando una tabella per applicazione per periodo.
Modello di progetto per i dati di serie temporali
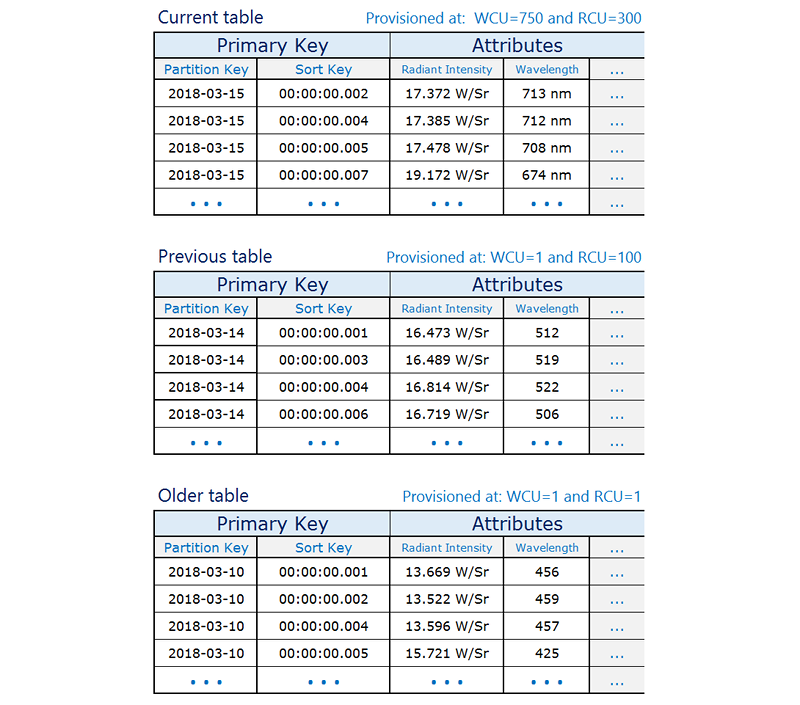
Prendi in considerazione uno scenario tipico relativo alle serie temporali, in cui vuoi tenere traccia di un elevato volume di eventi. Il tuo modello di accesso in scrittura equivale a quello di tutti gli eventi registrati con la data odierna. Il tuo modello di accesso in lettura potrebbe prevedere la lettura degli eventi odierni con più frequenza, degli eventi di ieri con meno frequenza e quindi degli eventi più vecchi con una frequenza ridotta. Una soluzione di gestione prevede l'aggiunta della data e dell'ora correnti alla chiave primaria.
Il seguente modello di progetto spesso è in grado di gestire questo tipo di scenario in modo efficace:
-
Crea una tabella per periodo che abbia la capacità in lettura e scrittura e gli indici richiesti.
-
Prima della fine di ogni periodo, prepara la tabella per il periodo successivo. Non appena termina il periodo corrente, dirigi il traffico degli eventi alla nuova tabella. A queste tabelle puoi assegnare dei nomi che specifichino i periodi registrati.
-
Non appena si interrompe la scrittura su una tabella, imposta la capacità in scrittura assegnata su un valore inferiore, ad esempio 1 WCU, e assegna la capacità in lettura appropriata. Riduci la capacità in lettura assegnata delle tabelle precedenti man mano che passa il tempo. Puoi scegliere di archiviare o eliminare le tabelle di cui utilizzi raramente o mai i contenuti.
L'idea è allocare le risorse necessarie per il periodo corrente con il volume di traffico più alto e di ridurre il provisioning per le tabelle precedenti che non vengono utilizzate attivamente, riducendo così i costi. A seconda delle esigenze aziendali, può essere utile partizionare la scrittura per distribuire equamente il traffico alla chiave di partizione logica. Per ulteriori informazioni, consulta Utilizzo dello sharding di scrittura per distribuire i carichi di lavoro in modo uniforme in una tabella DynamoDB.
Ottimizza i costi di storage con la classe table Standard-IA
DynamoDB offre due classi di tabelle: DynamoDB Standard e DynamoDB Access (DynamoDB). Standard-Infrequent Standard-IA La classe Standard-IA table riduce i costi di archiviazione aumentando al contempo il costo del throughput di lettura e scrittura. È una soluzione ideale quando l'archiviazione è la parte principale del costo di una tabella e vi si accede raramente.
Questo compromesso si ricollega naturalmente al modello delle serie temporali. La tabella del periodo corrente riceve la maggior parte del traffico di lettura e scrittura, quindi tienila nella classe di tabelle DynamoDB Standard, dove la velocità effettiva è meno costosa. Man mano che una tabella non viene più utilizzata, viene scritta raramente (o non viene letta affatto) e letta raramente, mentre si continuano a conservarne i dati. Per queste tabelle meno recenti, lo storage rappresenta in genere il costo maggiore, quindi passare alla classe delle Standard-IA tabelle può ridurre i costi complessivi.
Considerate quanto segue quando applicate le classi di tabella alle tabelle delle serie temporali:
-
Mantieni il periodo corrente (attivo) nella classe di tabella DynamoDB Standard. Il costo di throughput più elevato di Standard-IA supererebbe i risparmi di archiviazione per una tabella che serve un volume elevato di letture e scritture.
-
Passa alla tabella di un Standard-IA periodo a quella in cui non viene più scritta attivamente e vi si accede raramente, ma è comunque necessario conservarne i dati (ad esempio, per motivi di conformità o per richieste cronologiche occasionali).
-
È possibile impostare la classe table quando si crea una tabella o la si modifica in un secondo momento. Valuta il rapporto tra costi di storage e throughput di ogni tabella prima di passare alla tabella e monitora i costi dopo la modifica.
Per ulteriori informazioni sulle classi di tabelle e su come scegliere tra di esse, consulta e. Classi di tabella DynamoDB Valutazione della selezione della classe di tabella DynamoDB
Esempi di tabella di serie temporali
Di seguito è riportato un esempio di dati di serie temporali in cui la tabella corrente viene fornita con una read/write capacità maggiore e le tabelle precedenti vengono ridimensionate perché vi si accede di rado.