Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo degli indici secondari globali in DynamoDB
Alcune applicazioni devono poter eseguire molti tipi di query, usando un'ampia gamma di attributi diversi come criteri di query. Per supportare questi requisiti, è possibile creare uno o più indici secondari globali ed emettere richieste Query rispetto a questi indici in Amazon DynamoDB.
Argomenti
Scenario: Utilizzo di un indice secondario globale
A titolo illustrativo, considera una tabella denominata GameScores che tiene traccia di utenti e punteggi per un'applicazione di gioco per dispositivi mobili. Ogni item in GameScores è identificato da una chiave di partizione (UserId) e una chiave di ordinamento (GameTitle). Il seguente diagramma mostra in che modo verrebbero organizzarti gli elementi nella tabella. Non tutti gli attributi vengono visualizzati.
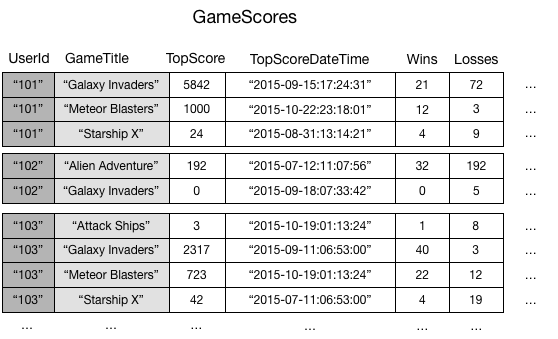
Supponi ora di voler scrivere un'applicazione di tipo classifica per visualizzare i punteggi più alti per ogni gioco. Una query che specifica gli attributi chiave (UserId e GameTitle) sarebbe molto efficiente. Tuttavia, se l'applicazione deve recuperare i dati da GameScores solo in base a GameTitle, occorre utilizzare un'operazione Scan. Con l'aggiunta di altri item alla tabella, le scansioni di tutti i dati rallenterebbero e diventerebbero meno pratiche, rendendo difficile rispondere a domande come le seguenti:
-
Qual è il punteggio più alto mai registrato per il gioco Meteor Blasters?
-
Quale utente ha il punteggio più alto per Galaxy Invaders?
-
Qual è il rapporto più elevato tra vittorie e sconfitte?
Per accelerare le query su attributi non chiave, è possibile creare un indice secondario globale. Un indice secondario globale contiene una selezione di attributi dalla tabella di base organizzati tramite una chiave primaria diversa da quella della tabella. La chiave dell'indice non deve avere alcuno degli attributi di chiave della tabella, né lo stesso schema della chiave di una tabella.
Ad esempio, è possibile creare un indice secondario globale denominato GameTitleIndex con una chiave di partizione GameTitle e una chiave di ordinamento TopScore. Gli attributi della chiave primaria della tabella di base vengono sempre proiettati in un indice, pertanto è presente anche l'attributo UserId. Il diagramma seguente mostra l'aspetto di un indice GameTitleIndex.
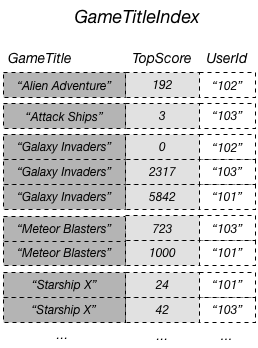
A questo punto, puoi eseguire una query su GameTitleIndex e ottenere facilmente i punteggi per Meteor Blasters. I risultati sono ordinati in base ai valori della chiave di ordinamento, ovvero TopScore. Se imposti il parametro ScanIndexForward su false, i risultati vengono restituiti in ordine decrescente e di conseguenza il punteggio più alto viene restituito per primo.
Ogni indice secondario globale deve avere una chiave di partizione e può avere anche una chiave di ordinamento facoltativa. Lo schema della chiave di indicizzazione può essere diverso dallo schema della tabella di base. È possibile avere una tabella con una chiave primaria semplice (chiave di partizione) e creare un indice secondario globale con una chiave primaria composita (chiave di partizione e chiave di ordinamento) o viceversa. Gli attributi della chiave dell'indice possono essere costituiti da qualsiasi attributo String, Number o Binary di primo livello della tabella di base. Altri tipi scalari, documento e set non sono consentiti.
Se vuoi, puoi proiettare altri attributi della tabella di base nell'indice. Quando si esegue una query sull'indice, DynamoDB può recuperare questi attributi proiettati in modo efficiente. Tuttavia, le query su un indice secondario globale non possono recuperare gli attributi dalla tabella di base. Ad esempio, se esegui una query GameTitleIndex come mostrato nel diagramma precedente, la query non è in grado di accedere ad alcun attributo non di chiave diverso da TopScore (se vengono automaticamente proiettati gli attributi della chiave GameTitle e UserId).
In una tabella DynamoDB ogni valore di chiave deve essere univoco. Tuttavia, i valori delle chiavi in un indice secondario globale non devono essere univoci. A titolo illustrativo, supponi che un gioco denominato Comet Quest sia particolarmente difficile, con molti nuovi utenti che provano ma non riescono a ottenere un punteggio maggiore di zero. Di seguito sono illustrati alcuni dati che possono rappresentare questa situazione.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
Quando questi dati vengono aggiunti alla tabella GameScores, vengono propagati da DynamoDB a GameTitleIndex. Se quindi eseguiamo una query sull'indice utilizzando Comet Quest per GameTitle e 0 per TopScore, vengono restituiti i dati seguenti.
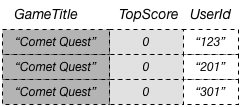
Nella risposta vengono visualizzati solo gli elementi con i valori di chiave specificati. All'interno di questo set di dati, gli elementi non hanno un ordine specifico.
Un indice secondario globale tiene traccia solo degli elementi di dati in cui esistono effettivamente i suoi attributi di chiave. Ad esempio, supponi di aver aggiunto un nuovo item alla tabella GameScores, ma di aver fornito solo gli attributi della chiave primaria obbligatori.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Poiché non è stato specificato l'attributo TopScore, DynamoDB non propaga questo elemento a GameTitleIndex. Di conseguenza, se ha eseguito una query su GameScores per tutti gli elementi di Comet Quest, ottieni i quattro item seguenti:
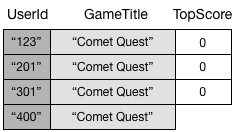
Una query simile su GameTitleIndex continua a restituire tre item anziché quattro. Il motivo è che l'item con TopScore inesistente non viene propagato nell'indice.
Proiezioni di attributi
Una proiezione è l'insieme di attributi copiato da una tabella in un indice secondario. La chiave di partizione e la chiave di ordinamento della tabella vengono sempre proiettati nell'indice; è possibile proiettare altri attributi per supportare i requisiti di query dell'applicazione. Quando si esegue una query su un indice, Amazon DynamoDB può accedere a qualsiasi attributo nella proiezione come se tali attributi fossero in una propria tabella.
Quando si crea un indice secondario, è necessario specificare gli attributi che saranno proiettati nell'indice. DynamoDB fornisce tre diverse opzioni per questo:
-
KEYS_ONLY: ogni elemento dell'indice è costituito solo dalla chiave di partizione della tabella e dai valori della chiave di ordinamento, oltre ai valori della chiave di indice. L'opzione
KEYS_ONLYsi traduce nell'indice secondario più piccolo possibile. -
INCLUDE: oltre agli attributi descritti in
KEYS_ONLY, l'indice secondario includerà gli altri attributi non chiave che sono stati specificati. -
ALL: l'indice secondario include tutti gli attributi della tabella di origine. Poiché tutti i dati della tabella sono duplicati nell'indice, una proiezione
ALLrestituisce il più grande indice secondario possibile.
Nel diagramma precedente, GameTitleIndex dispone di un solo attributo proiettato: UserId. Pertanto, sebbene un'applicazione possa determinare in maniera efficiente il valore UserId dei punteggi più alti per ogni partita utilizzando GameTitle e TopScore nelle query, non può determinare in maniera efficiente il rapporto più elevato tra vittorie e sconfitte per i punteggi più alti. A tale scopo, l'applicazione dovrebbe eseguire un'interrogazione aggiuntiva sulla tabella di base per recuperare le vittorie e le sconfitte di ciascuno dei migliori marcatori. Un modo più efficiente per supportare le query su questi dati consiste nel proiettare gli attributi dalla tabella di base nell'indice secondario globale, come mostrato in questo diagramma.
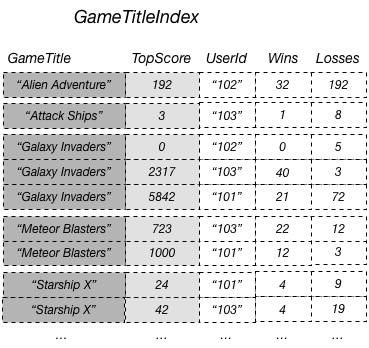
Poiché gli attributi non di chiave Wins e Losses vengono proiettati nell'indice, un'applicazione può determinare il rapporto tra vittorie e sconfitte per qualsiasi gioco o per qualsiasi combinazione di gioco e ID utente.
Quando si scelgono gli attributi da proiettare in un indice secondario globale, è necessario considerare il compromesso tra i costi correlati alla velocità effettiva assegnata e i costi di archiviazione:
-
Se è necessario accedere a pochi attributi con la latenza più bassa possibile, considerare la possibilità di proiettare solo quegli attributi in un indice secondario globale. Più piccolo è l'indice, minore è il costo per memorizzarlo e minori sono i costi di scrittura.
-
Se l'applicazione accede frequentemente ad alcuni attributi non chiave, è necessario considerare di proiettare quegli attributi in un indice secondario globale. I costi di archiviazione aggiuntivi per l'indice secondario globale compensano il costo di esecuzione di scansioni frequenti delle tabelle.
-
Se è necessario accedere alla maggior parte degli attributi non chiave su base frequente, è possibile proiettare questi attributi, o anche l'intera tabella di base, in un indice secondario globale. Questo offre massima flessibilità. Tuttavia, i costi di storage aumenteranno o addirittura raddoppieranno.
-
Se l'applicazione esegue di rado le query sulla tabella, ma esegue molte scritture o aggiornamenti dei dati nella tabella, considera di proiettare
KEYS_ONLY. L'indice secondario globale avrebbe dimensioni minime e sarebbe comunque disponibile se necessario per l'attività di query.
Schema chiave con più attributi
Gli indici secondari globali supportano chiavi con più attributi, che consentono di comporre chiavi di partizione e ordinare le chiavi a partire da più attributi. Con le chiavi multiattributo, è possibile creare una chiave di partizione da un massimo di quattro attributi e una chiave di ordinamento da un massimo di quattro attributi, per un totale di un massimo di otto attributi per schema di chiavi.
Le chiavi multiattributo semplificano il modello di dati eliminando la necessità di concatenare manualmente gli attributi in chiavi sintetiche. Invece di creare stringhe composite, ad esempioTOURNAMENT#WINTER2024#REGION#NA-EAST, puoi utilizzare direttamente gli attributi naturali del tuo modello di dominio. DynamoDB gestisce automaticamente la logica delle chiavi composite, eseguendo l'hashing di più attributi chiave di partizione per la distribuzione dei dati e mantenendo l'ordinamento gerarchico tra più attributi delle chiavi di ordinamento.
Ad esempio, prendi in considerazione un sistema di tornei di gioco in cui desideri organizzare le partite per torneo e regione. Con le chiavi multiattributo, è possibile definire la chiave di partizione come due attributi separati: tournamentId e. region Allo stesso modo, è possibile definire la chiave di ordinamento utilizzando più attributi come roundbracket, e matchId creare una gerarchia naturale. Questo approccio mantiene i dati digitati e il codice pulito, senza manipolazione o analisi delle stringhe.
Quando si esegue una query su un indice secondario globale con chiavi multiattributo, è necessario specificare tutti gli attributi delle chiavi di partizione utilizzando condizioni di uguaglianza. Per gli attributi chiave di ordinamento, è possibile interrogarli left-to-right nell'ordine in cui sono definiti nello schema chiave. Ciò significa che è possibile interrogare solo il primo attributo chiave di ordinamento, i primi due attributi insieme o tutti gli attributi insieme, ma non è possibile saltare gli attributi intermedi. Condizioni di disuguaglianza come>, <BETWEEN, o begins_with() devono essere l'ultima condizione della query.
Le chiavi con più attributi funzionano particolarmente bene quando si creano indici secondari globali su tabelle esistenti. È possibile utilizzare gli attributi già presenti nella tabella senza inserire le chiavi sintetiche tra i dati. Ciò semplifica l'aggiunta di nuovi modelli di query all'applicazione creando indici che riorganizzano i dati utilizzando diverse combinazioni di attributi.
Ogni attributo in una chiave con più attributi può avere il proprio tipo di dati: String (S), (N) o Number (B). Binary Quando scegliete i tipi di dati, tenete presente che Number gli attributi vengono ordinati numericamente senza richiedere il riempimento zero, mentre gli attributi vengono ordinati lessicograficamente. String Ad esempio, se utilizzi un Number tipo per un attributo score, i valori 5, 50, 500 e 1000 vengono ordinati in ordine numerico naturale. Gli stessi valori String di type verrebbero ordinati come «1000", «5", «50", «500" a meno che non vengano riempiti con zeri iniziali.
Quando progettate chiavi con più attributi, ordinate gli attributi dal più generale al più specifico. Per le chiavi di partizione, combinate gli attributi che vengono sempre interrogati insieme e che garantiscono una buona distribuzione dei dati. Per le chiavi di ordinamento, posiziona gli attributi più richiesti al primo posto nella gerarchia per massimizzare la flessibilità delle query. Questo ordinamento consente di eseguire query a qualsiasi livello di granularità che corrisponda ai modelli di accesso.
Vedi gli esempi di Chiavi con più attributi implementazione.
Lettura di dati da un indice secondario globale
È possibile recuperare gli elementi da un indice secondario globale utilizzando le operazioni Query e Scan. Le operazioni GetItem e BatchGetItem non possono essere utilizzate su un indice secondario globale.
Esecuzione di query su un indice secondario globale
È possibile utilizzare l'operazione Query per accedere a uno o più elementi in un indice secondario globale. La query deve specificare il nome della tabella di base e il nome dell'indice che si desidera utilizzare, gli attributi da restituire nei risultati della query e qualsiasi condizione di query da applicare. DynamoDB può restituire i risultati in ordine crescente o decrescente.
Considera i dati seguenti restituiti da un'operazione Query che richiede dati di gioco per un'applicazione di tipo classifica.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
In questa query:
-
DynamoDB GameTitleIndexaccede, utilizzando la chiave di partizione per individuare gli elementi GameTitledell'indice per Meteor Blasters. Tutti gli elementi dell'indice con questa chiave sono memorizzati l'uno accanto all'altro per il recupero rapido.
-
All'interno di questo gioco, DynamoDB utilizza l'indice per accedere a tutti gli IDs utenti e ai punteggi più alti di questo gioco.
-
Vengono restituiti i risultati in base all'ordine decrescente, perché il parametro
ScanIndexForwardè impostato su false.
Scansione di un indice secondario globale
È possibile utilizzare l'operazione Scan per recuperare tutti i dati da un indice secondario globale. Devi fornire il nome della tabella di base e il nome dell'indice nella richiesta. Con un'operazione Scan, DynamoDB legge tutti i dati nell'indice e li restituisce all'applicazione. Inoltre puoi richiedere che vengano restituiti solo alcuni dati e che quelli rimanenti vengano eliminati. A questo scopo, usa il parametro FilterExpression dell'operazione Scan. Per ulteriori informazioni, consulta Espressioni di filtro per la scansione.
Sincronizzazione dei dati tra tabelle e indici secondari globali
DynamoDB sincronizza automaticamente ogni indice secondario globale con la relativa tabella di base. Quando un'applicazione scrive o elimina elementi in una tabella, ogni indice secondario globale nella tabella viene aggiornato in modo asincrono, usando un modello a consistenza finale. Le applicazioni non scrivono mai direttamente in un indice. Tuttavia, è importante comprendere le implicazioni di come DynamoDB mantiene questi indici.
Gli indici secondari globali ereditano la modalità di read/write capacità dalla tabella base. Per ulteriori informazioni, consulta Considerazioni sul passaggio tra modalità di capacità in DynamoDB.
Quando si crea un indice secondario globale, viene specificato uno o più attributi della chiave di indice e i rispettivi tipi di dati. Questo significa che ogni volta che scrivi un item nella tabella di base, i tipi di dati per questi attributi devono corrispondere ai tipi di dati dello schema della chiave dell'indice. Nel caso di GameTitleIndex, la chiave di partizione GameTitle nell'indice è definita come un tipo di dati String. La chiave di ordinamento TopScore nell'indice è di tipo Number. Se si prova ad aggiungere un elemento alla tabella GameScores e si specifica un tipo di dati diverso per GameTitle o TopScore, DynamoDB restituisce un ValidationException perché il tipo di dati non corrisponde.
Quando inserisci o elimini item in una tabella, ogni indice secondario globale nella tabella viene aggiornato in base a un modello eventualmente consistente. Le modifiche apportate ai dati della tabella vengono propagate in ogni indice secondario globale entro una frazione di secondo in condizioni normali. Tuttavia, in alcuni improbabili scenari di errore, possono verificarsi ritardi di propagazione prolungati. Per questo motivo, le applicazioni devono poter prevedere e gestire le situazioni in cui una query su un indice secondario globale restituisce risultati non aggiornati.
Se si scrive un elemento in una tabella, non è necessario specificare gli attributi per la chiave di ordinamento di alcun indice secondario globale. Utilizzando GameTitleIndex come un esempio, non devi specificare un valore per l'attributo TopScore per scrivere un nuovo item nella tabella GameScores. In questo caso, DynamoDB non scrive alcun dato nell'indice per questo particolare elemento.
Una tabella con molti indici secondari globali comporta costi maggiori per l'attività di scrittura rispetto alle tabelle con meno indici. Per ulteriori informazioni, consulta Considerazioni sulla velocità di trasmissione effettiva assegnata per indici secondari globali.
Classi di tabella con indici secondari globali
Un indice secondario globale utilizzerà sempre la stessa classe di tabella della tabella di base. Ogni volta che viene aggiunto un nuovo indice secondario globale per una tabella, il nuovo indice utilizzerà la stessa classe di tabella della tabella di base. Quando la classe di tabella di una tabella viene aggiornata, vengono aggiornati anche tutti gli indici secondari globali associati.
Considerazioni sulla velocità di trasmissione effettiva assegnata per indici secondari globali
Quando si crea un indice secondario globale su una tabella con modalità assegnata, è necessario specificare le unità di capacità di lettura e scrittura per il carico di lavoro previsto sull'indice. Le impostazioni correlate alla velocità effettiva assegnata di un indice secondario globale sono separate da quelle della relativa tabella di base. Un'operazione Query su un indice secondario globale utilizza unità di capacità di lettura dell'indice e non della tabella di base. Quando inserisci, aggiorni o elimini item in una tabella, anche gli indici secondari globali nella tabella vengono aggiornati. Questi aggiornamenti dell'indice utilizzano unità di capacità in scrittura dell'indice, non della tabella.
Ad esempio, se si esegui un'operazione Query su un indice secondario globale e se ne supera la capacità di lettura assegnata, la richiesta sarà sottoposta a limitazione. Se si esegue un'attività di scrittura pesante sulla tabella, ma un indice secondario globale su quella tabella ha una capacità di scrittura insufficiente, l'attività di scrittura sulla tabella verrà limitata.
Importante
Per evitare il possibile throttling, la capacità in scrittura assegnata per un indice secondario globale deve essere maggiore o uguale alla capacità in scrittura della tabella di base poiché nuovi aggiornamenti scrivono nella tabella di base e nell'indice secondario globale.
Per visualizzare le impostazioni di velocità effettiva assegnata per un indice secondario globale, utilizza l'operazione DescribeTable. Vengono restituite informazioni dettagliare relative a tutti gli indici secondari della tabella.
Unità di capacità in lettura
Gli indici secondari globali supportano letture consistenti finali, ognuna delle quali utilizza metà di un'unità di capacità in lettura. Questo significa che una singola query su un indice secondario globale può recuperare fino a 2 × 4 KB = 8 KB per ogni unità di capacità di lettura.
Per le query su un indice secondario globale, DynamoDB calcola l'attività di lettura assegnata come avviene per le query sulle tabelle. L'unica differenza è che il calcolo si basa sulle dimensioni delle voci dell'indice, piuttosto che sulla dimensione dell'item nella tabella di base. Il numero di unità di capacità in lettura è la somma di tutte le dimensioni degli attributi proiettati di tutti gli elementi restituiti. Il risultato viene arrotondato al limite di 4 KB successivo. Per ulteriori informazioni sul modo in cui DynamoDB calcola l'uso della velocità effettiva assegnata, consulta Modalità con capacità allocata di DynamoDB.
La dimensione massima dei risultati restituiti da un'operazione Query è 1 MB. Sono incluse le dimensioni di tutti i nomi e i valori degli attributi in tutti gli elementi restituiti.
Ad esempio, si consideri un indice secondario globale in cui ogni elemento contiene 2.000 byte di dati. Si supponga ora di eseguire un'operazione Query su questo indice e che KeyConditionExpression della query restituisca otto elementi. La dimensione totale degli elementi corrispondenti è 2.000 byte 8 elementi = 16.000 byte. Questo risultato viene quindi arrotondato al limite da 4 KB più vicino. Poiché le query su un indice secondario globale sono a consistenza finale, il costo totale equivale a 0,5 × (16 KB / 4 KB) o 2 unità di capacità di lettura.
Unità di capacità in scrittura
Quando un elemento in una tabella viene aggiunto, aggiornato o eliminato e questa operazione interessa un indice secondario globale, l'indice utilizzerà le unità di capacità di scrittura assegnate per l'operazione. Il costo totale del throughput assegnato per una scrittura è la somma delle unità di capacità in scrittura utilizzate dalla scrittura nella tabella di base e quelle utilizzate dall'aggiornamento degli indici secondari globali. Se una scrittura in una tabella non richiede l'aggiornamento di un indice secondario globale, non viene utilizzata capacità di scrittura dell'indice.
Perché la scrittura in una tabella riesca, le impostazioni correlate al throughput assegnato per la tabella e tutti i suoi indici secondari globali devono avere capacità in scrittura sufficiente per la scrittura. In caso contrario, la scrittura nella tabella viene limitata.
Importante
Quando si crea un indice secondario globale (GSI), le operazioni di scrittura sulla tabella di base possono essere sottoposte a limitazione (della larghezza di banda della rete) se l’attività dei GSI risultante dalle scritture sulla tabella di base supera la capacità di scrittura allocata del GSI. Questa limitazione (della larghezza di banda della rete) influisce su tutte le operazioni di scrittura, dal processo di indicizzazione alla potenziale interruzione dei carichi di lavoro di produzione. Per ulteriori informazioni, consulta Risoluzione dei problemi di limitazione (della larghezza di banda della rete) in Amazon DynamoDB.
Il costo della scrittura di un elemento in un indice secondario globale dipende da diversi fattori:
-
Se scrivi un nuovo item nella tabella che definisce un attributo indicizzato o aggiorni un item esistente per definire un attributo indicizzato in precedenza non definito, è necessario eseguire un'operazione di scrittura per inserire l'item nell'indice.
-
Se un aggiornamento della tabella modifica il valore di un attributo chiave indicizzato (da A a B), sono necessarie due scritture, una per eliminare l'item precedente dall'indice e un'altra per inserire il nuovo item nell'indice.
-
Se un item era presente nell'indice, ma una scrittura nella tabella ha causato la cancellazione dell'attributo indicizzato, è necessaria una scrittura per eliminare la proiezione dell'item precedente dall'indice.
-
Se un item non è presente nell'indice prima o dopo l'aggiornamento dell'item, non vi è alcun costo di scrittura aggiuntivo per l'indice.
-
Se un aggiornamento della tabella modifica solo il valore degli attributi proiettati nello schema della chiave dell'indice, ma non modifica il valore di alcun attributo di chiave indicizzato, è necessaria una scrittura per aggiornare i valori degli attributi proiettati nell'indice.
Tutti questi fattori presuppongono che la dimensione di ciascun elemento nell'indice sia minore o uguale alla dimensione dell'elemento di 1 KB per il calcolo delle unità di capacità di scrittura. Le voci di indice più grandi richiedono unità di capacità in scrittura aggiuntive. Puoi contenere al minimo i costi di scrittura considerando gli attributi che le query devono restituire e proiettando solo tali attributi nell'indice.
Considerazioni sullo storage per indici secondari globali
Quando un'applicazione scrive un elemento in una tabella, DynamoDB copia automaticamente il sottoinsieme di attributi corretto in qualsiasi indice secondario globale in cui devono essere presenti gli attributi. All' AWS account vengono addebitati i costi per la memorizzazione dell'articolo nella tabella di base e anche per la memorizzazione degli attributi in tutti gli indici secondari globali di tale tabella.
La quantità di spazio utilizzata da un item dell'indice è la somma di quanto segue:
-
La dimensione in byte della chiave primaria della tabella di base (chiave di partizione e chiave di ordinamento)
-
La dimensione in byte dell'attributo della chiave di indicizzazione
-
La dimensione in byte degli attributi proiettati (se presenti)
-
100 byte di sovraccarico per elemento dell'indice
Per stimare i requisiti di archiviazione per un indice secondario globale, è possibile stimare la dimensione media di un elemento nell'indice e quindi moltiplicarla per il numero di elementi nella tabella di base che hanno attributi di chiave dell'indice secondario globale.
Se una tabella contiene un elemento in cui uno o più attributi particolari non sono definiti, ma tale attributo è definito come chiave di partizione dell'indice o chiave di ordinamento, DynamoDB non scrive alcun dato per quell'elemento nell'indice.
