Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fondamenti della modellazione dei dati in DynamoDB
Questa sezione inizia dal livello base esaminando i due tipi di progettazione tabella: tabella singola e tabelle multiple.
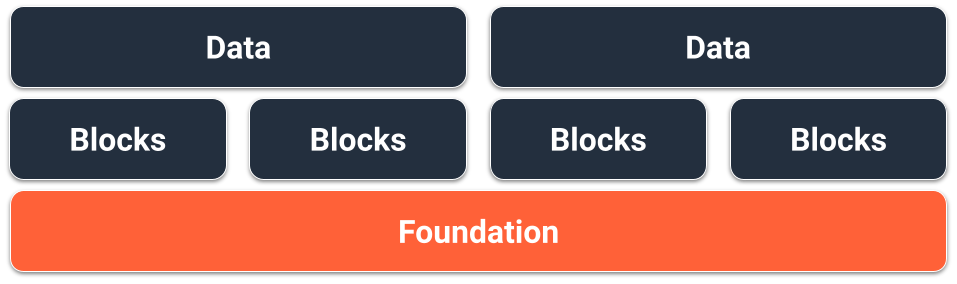
Base della progettazione tabella singola
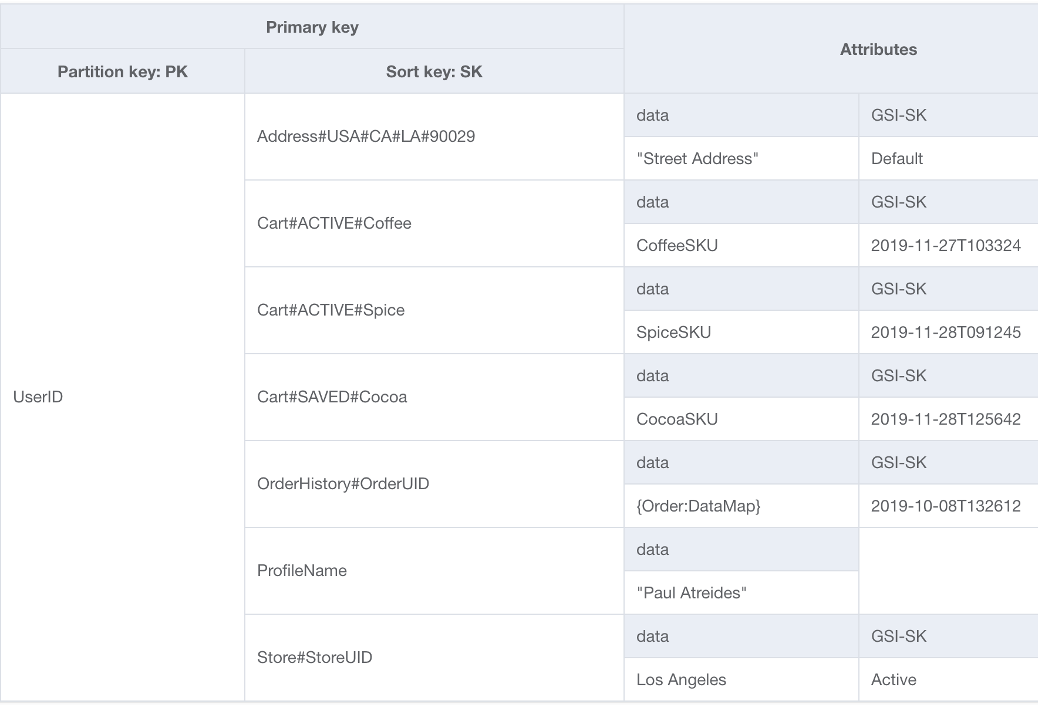
Una scelta per la base dello schema DynamoDB è la progettazione tabella singola. La progettazione tabella singola è un modello che consente di archiviare più tipi (entità) di dati in una singola tabella DynamoDB. Ha lo scopo di ottimizzare i modelli di accesso ai dati, migliorare le prestazioni e ridurre i costi eliminando la necessità di mantenere più tabelle e relazioni complesse tra di esse. Ciò è possibile perché DynamoDB archivia gli elementi con la stessa chiave di partizione (nota come raccolta di elementi) sulle stesse partizioni dell'altra. In questa progettazione, tipi di dati differenti vengono archiviati come elementi nella stessa tabella e ciascun elemento è identificato da una chiave di ordinamento univoca.
Vantaggi
-
Ubicazione dei dati per supportare query per più tipi di entità in una singola chiamata al database
-
Riduce i costi finanziari e di latenza complessivi delle letture:
-
Una singola query per due elementi che totalizzano meno di 4 KB è caratterizzata da consistenza finale di 0,5 RCU
-
Due query per due elementi che totalizzano meno di 4 KB è caratterizzata da consistenza finale di 1 RCU (0,5 RCU ciascuna)
-
Il tempo richiesto per restituire due chiamate al database separate sarà in media superiore a quello di una singola chiamata
-
-
Riduce il numero di tabelle da gestire:
-
Non è necessario mantenere le autorizzazioni per più ruoli o policy IAM
-
La gestione della capacità per la tabella viene calcolata come media tra tutte le entità, di solito risultando in un modello di consumo più prevedibile
-
Il monitoraggio richiede un numero inferiore di allarmi
-
Le chiavi di crittografia gestite dal cliente devono essere ruotate solo su una tabella
-
-
Uniforma il traffico verso la tabella:
-
Aggregando più modelli di utilizzo nella stessa tabella, l'utilizzo complessivo tende a essere più uniforme (così come la performance di un indice azionario tende a essere più uniforme di qualsiasi titolo singolo), consentendo di raggiungere un maggiore utilizzo con tabelle con modalità assegnata
-
Svantaggi
-
La curva di apprendimento può essere ripida a causa della progettazione paradossale rispetto ai database relazionali
-
I requisiti di dati devono essere coerenti tra tutti i tipi di entità
-
I backup sono in modalità “tutto o niente”, pertanto se alcuni dati non sono mission-critical, occorre valutare la possibilità di conservarli in una tabella separata
-
La crittografia delle tabelle è condivisa tra tutti gli elementi. Per applicazioni multi-tenant con requisiti di crittografia del singolo tenant, è richiesta la crittografia lato client
-
Le tabelle con una combinazione di dati storici e dati operativi non traggono vantaggio dall'attivazione della classe di storage ad accesso infrequente. Per ulteriori informazioni, consulta Classi di tabella DynamoDB
-
-
Tutti i dati modificati verranno propagati ai flussi DynamoDB anche se deve essere elaborato solo un sottoinsieme di entità.
-
Grazie ai filtri degli eventi Lambda, ciò non influirà sulla fatturazione quando si utilizza Lambda, ma comporterà un costo aggiuntivo quando si utilizza la Kinesis Consumer Library
-
-
Quando si utilizza GraphQL, la progettazione di una singola tabella sarà più difficile da implementare
-
Quando si utilizzano client SDK di livello superiore come DynamoDBMapper o Enhanced Client di Java, può essere più difficile elaborare i risultati perché gli elementi nella stessa risposta possono essere associati a classi diverse
Quando usare
La progettazione a tabella singola è ideale per le applicazioni che spesso interrogano più tipi di entità insieme o devono mantenere relazioni tra diversi tipi di dati. È particolarmente efficace quando i modelli di accesso traggono vantaggio dall’ubicazione dei dati e quando si desidera ridurre al minimo il sovraccarico derivante dalla gestione di più tabelle.
Base della progettazione tabelle multiple
La seconda scelta per la base dello schema DynamoDB è la progettazione tabelle multiple. La progettazione tabelle multiple è un modello più simile a una progettazione di database tradizionale in cui si archivia un singolo tipo (entità) di dati in ogni tabella DynamoDB. I dati all'interno di ciascuna tabella saranno comunque organizzati per chiave di partizione, pertanto le prestazioni all'interno di un singolo tipo di entità saranno ottimizzate per scalabilità e prestazioni, ma le query su più tabelle devono essere eseguite in modo indipendente.
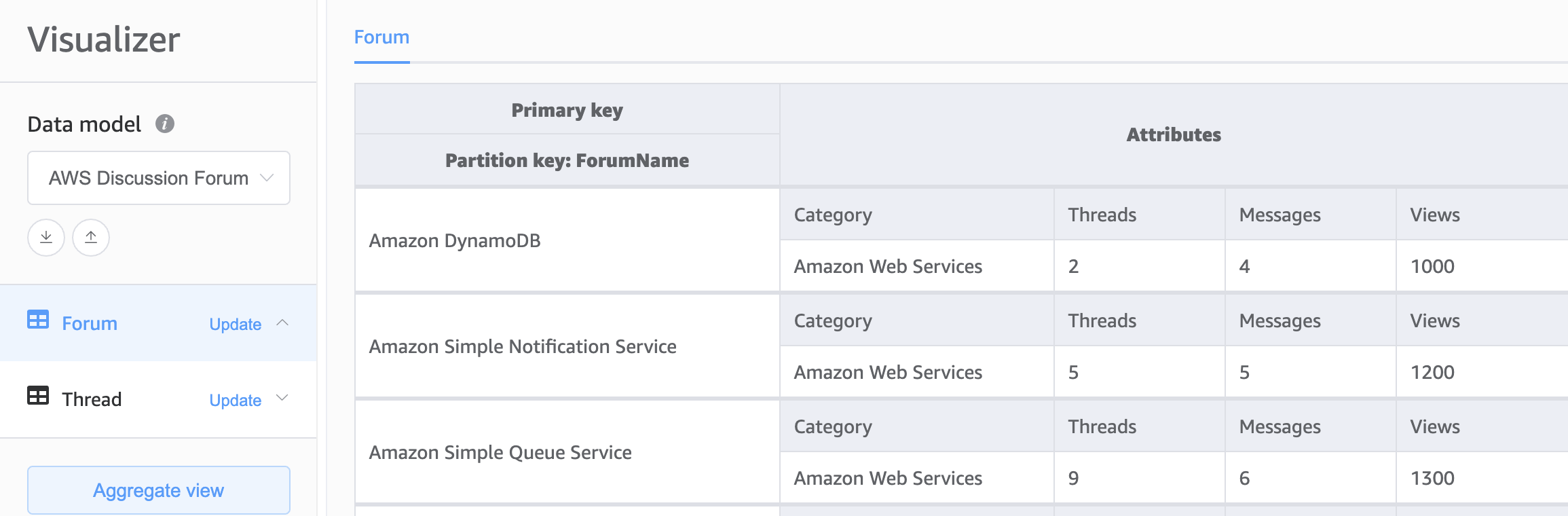
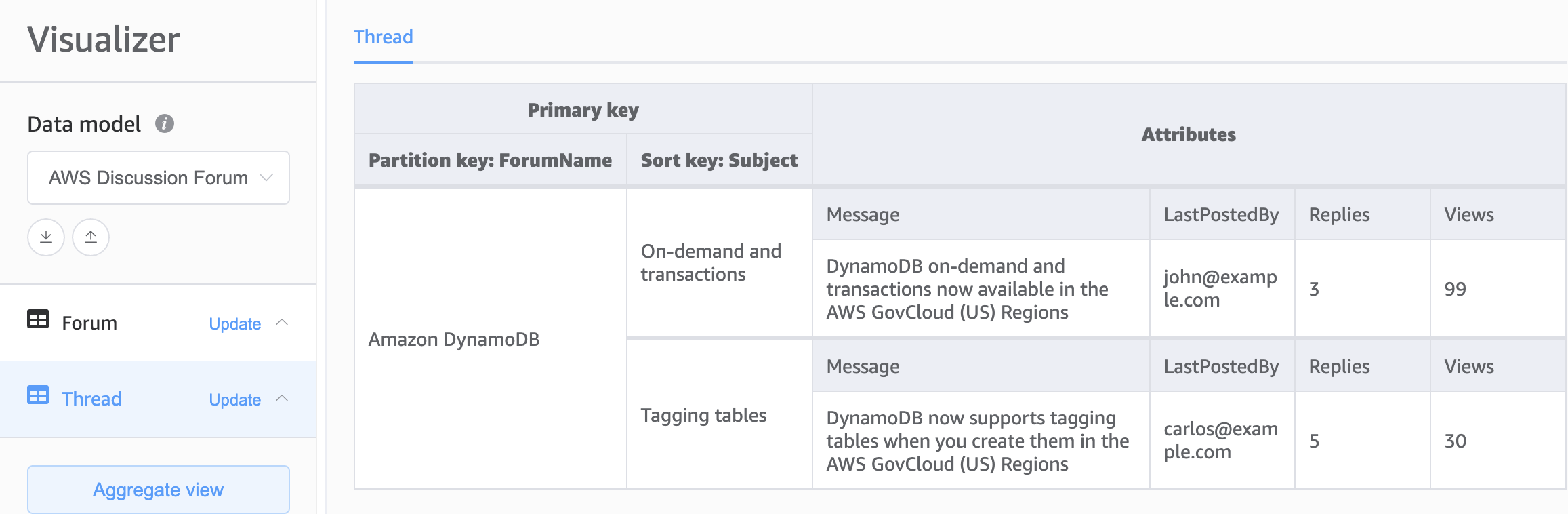
Vantaggi
-
Più semplice da progettare per chi non è abituato a utilizzare la progettazione tabella singola
-
Implementazione più semplice dei resolver GraphQL grazie alla mappatura di ogni resolver su una singola entità (tabella)
-
Consente requisiti di dati univoci per diversi tipi di entità:
-
Backup possono essere eseguiti per le singole tabelle che sono mission critical
-
La crittografia della tabella può essere gestita per ciascuna tabella. Per applicazioni multi-tenant con requisiti di crittografia del singolo tenant, tabelle tenant separate consentono a ciascun cliente di disporre della propria chiave di crittografia
-
La classe di storage ad accesso infrequente può essere abilitata solo sulle tabelle con dati storici per ottenere il massimo vantaggio in termini di riduzione dei costi. Per ulteriori informazioni, consulta Classi di tabella DynamoDB
-
-
Ogni tabella avrà il proprio flusso di dati di modifica. Ciò consente di progettare una funzione Lambda dedicata per ogni tipo di elemento anziché un singolo processore monolitico
Svantaggi
-
Per i modelli di accesso che richiedono dati su più tabelle, saranno necessarie più letture da DynamoDB e potrebbe essere necessario che i dati si trovino nel codice client processed/joined .
-
Le operazioni e il monitoraggio di più tabelle richiedono più CloudWatch allarmi e ogni tabella deve essere ridimensionata in modo indipendente
-
Le autorizzazioni di ciascuna tabella devono essere gestite separatamente. L'aggiunta di tabelle in futuro richiederà la modifica degli eventuali ruoli o policy IAM necessari
Quando usare
Se i modelli di accesso dell'applicazione non richiedono di interrogare più entità o tabelle insieme, la progettazione di più tabelle è un approccio valido e sufficiente.
