Avviso di fine del supporto: il 31 ottobre 2025 AWS interromperà il supporto per Amazon Lookout for Vision. Dopo il 31 ottobre 2025, non potrai più accedere alla console Lookout for Vision o alle risorse Lookout for Vision. Per ulteriori informazioni, consulta questo post del blog.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Nozioni di base su Amazon Lookout for Vision
Prima di iniziare queste istruzioni introduttive, ti consigliamo di leggereInformazioni su Amazon Lookout for Vision.
Le istruzioni introduttive mostrano come utilizzare la creazione di un modello di segmentazione delle immagini di esempio. Se desideri creare un modello di classificazione delle immagini di esempio, vediset di dati di classificazione delle immagini.
Se desideri provare rapidamente un modello di esempio, forniamo immagini di allenamento di esempio e immagini di maschere. Forniamo anche uno script Python che crea un file manifest per la segmentazione delle immagini. Utilizzate il file manifest per creare un set di dati per il vostro progetto e non è necessario etichettare le immagini nel set di dati. Quando crei un modello con le tue immagini, devi etichettare le immagini nel set di dati. Per ulteriori informazioni, consulta Creare il tuo set di dati.
Le immagini che forniamo sono di cookie normali e anomali. Un cookie anomalo presenta una crepa nella forma del biscotto. Il modello che addestra con le immagini prevede una classificazione (normale o anomala) e trova l'area (maschera) delle crepe in un cookie anomalo, come mostrato nell'esempio seguente.

Argomenti
Fase 1: crea il file del manifesto e carica delle immagini
In questa procedura, cloni l'archivio della documentazione di Amazon Lookout for Vision sul tuo computer. Utilizzi quindi uno script Python (versione 3.7 o superiore) per creare un file manifest e caricare le immagini di training e le immagini delle maschere in una posizione Amazon S3 specificata. Utilizzate il file manifest per creare il vostro modello. Successivamente, utilizzi le immagini di prova nel repository locale per provare il tuo modello.
Per creare il file manifest e caricare immagini
Configura Amazon Lookout for Vision seguendo le istruzioni in Configurazione di Amazon Lookout for Vision. Assicurati di installare l'AWSSDK per Python
. Nella AWS regione in cui desideri utilizzare Lookout for Vision, crea un bucket S3.
Nel bucket Amazon S3 crea una cartella denominata.
getting-startedAnnotare l'URI Amazon S3 e il nome della risorsa Amazon (ARN) per la cartella. Li usi per configurare le autorizzazioni ed eseguire lo script.
Assicurati che l'utente che chiama lo script disponga delle autorizzazioni per chiamare l'
s3:PutObjectoperazione. È possibile utilizzare la seguente policy. Per assegnare le autorizzazioni, vedere. Assegnare le autorizzazioni{ "Version": "2012-10-17", "Statement": [{ "Sid": "Statement1", "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": [ "arn:aws:s3::: ARN for S3 folder in step 4/*" ] }] }-
Assicurati di avere un profilo locale denominato
lookoutvision-accesse che l'utente del profilo disponga delle autorizzazioni del passaggio precedente. Per ulteriori informazioni, consulta Utilizzo di un profilo su un computer locale. -
Scarica il file zip, getting-started.zip. Il file zip contiene il set di dati introduttivo e lo script di configurazione.
Decomprimi il file
getting-started.zip.Al prompt dei comandi procedere come segue:
Accedere alla cartella
getting-started.-
Esegui il comando seguente per creare un file manifest e caricare le immagini di allenamento e le maschere di immagini nel percorso Amazon S3 indicato nel passaggio 4.
python getting_started.pyS3-URI-from-step-4 Al termine dello script, annota il percorso del
train.manifestfile che lo script visualizza dopoCreate dataset using manifest file:. Il percorso dovrebbe essere simile as3://.path to getting started folder/manifests/train.manifest
Fase 2: creazione del modello
In questa procedura, crei un progetto e un set di dati utilizzando le immagini e il file manifest che hai precedentemente caricato nel tuo bucket Amazon S3. Quindi si crea il modello e si visualizzano i risultati della valutazione dell'addestramento dei modelli.
Poiché crei il set di dati dal file manifest introduttivo, non è necessario etichettare le immagini del set di dati. Quando crei un set di dati con le tue immagini, devi etichettare le immagini. Per ulteriori informazioni, consulta Immagini etichettate.
Importante
Ti viene addebitato il costo di un addestramento di successo di un modello.
Per creare un modello
-
Apri la console Amazon Lookout for Vision all'indirizzo https://console.aws.amazon.com/lookoutvision/
. Assicurati di essere nella stessa AWS regione in cui hai creato il bucket Amazon S3. Fase 1: crea il file del manifesto e carica delle immagini Per modificare la Regione, scegliere il nome della Regione attualmente visualizzata nella barra di navigazione. Quindi seleziona la Regione alla quale desideri passare.
-
Scegliere Inizia.
Nella sezione Progetti, scegli Crea progetto.
-
Nella pagina Crea progetto procedere come segue:
-
In Nome progetto, inserisci
getting-started. -
Seleziona Create project (Crea progetto).
-
-
Nella pagina del progetto, nella sezione Come funziona, scegli Crea set di dati.
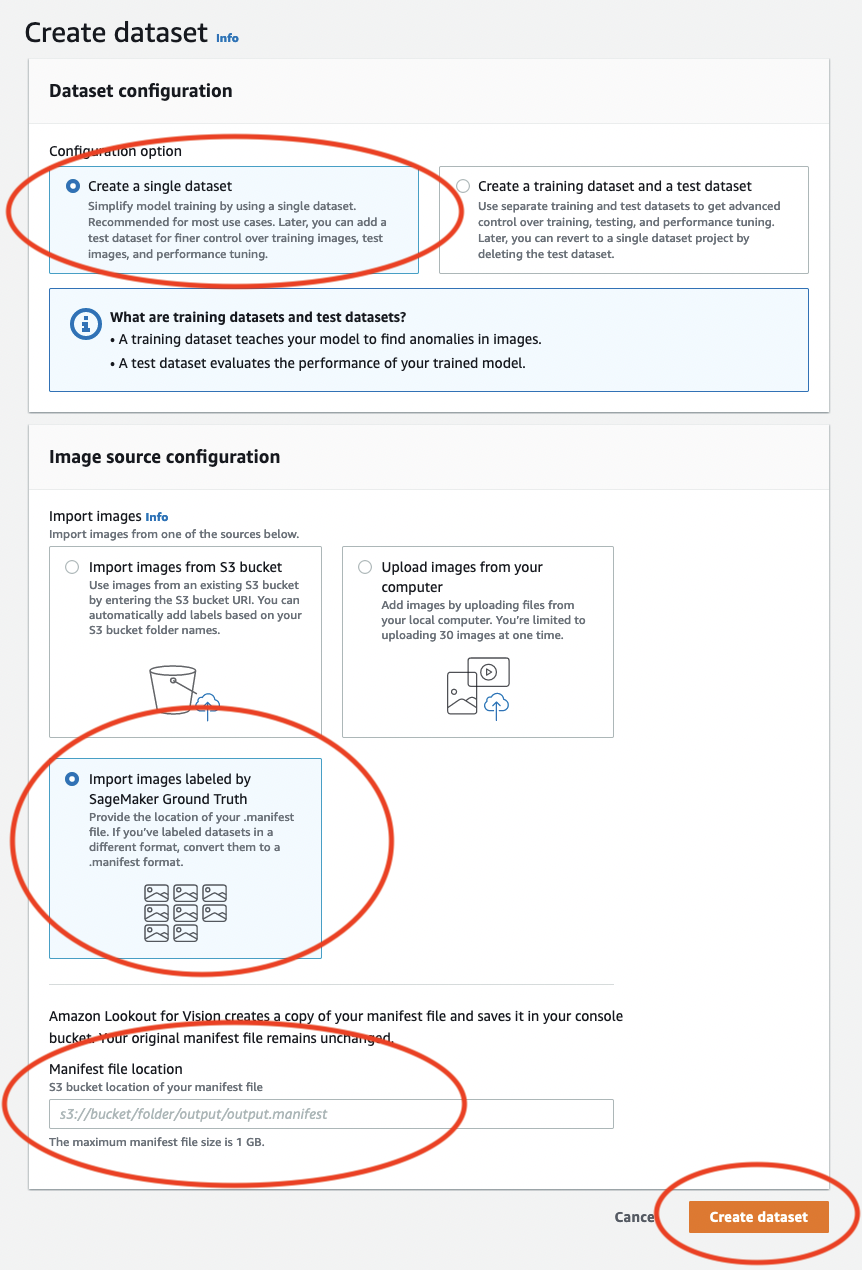
Nella pagina Crea set di dati procedere come segue:
-
Scegli Crea un singolo set di dati.
-
Nella sezione Configurazione della sorgente dell'immagine, scegli Importa immagini etichettate da SageMaker Ground Truth.
-
Per la posizione del file.manifest, inserisci la posizione Amazon S3 del file manifest che hai annotato nel passaggio 6.c. di. Fase 1: crea il file del manifesto e carica delle immagini La posizione di Amazon S3 dovrebbe essere simile a
s3://path to getting started folder/manifests/train.manifest -
Scegli Crea set di dati.
-
-
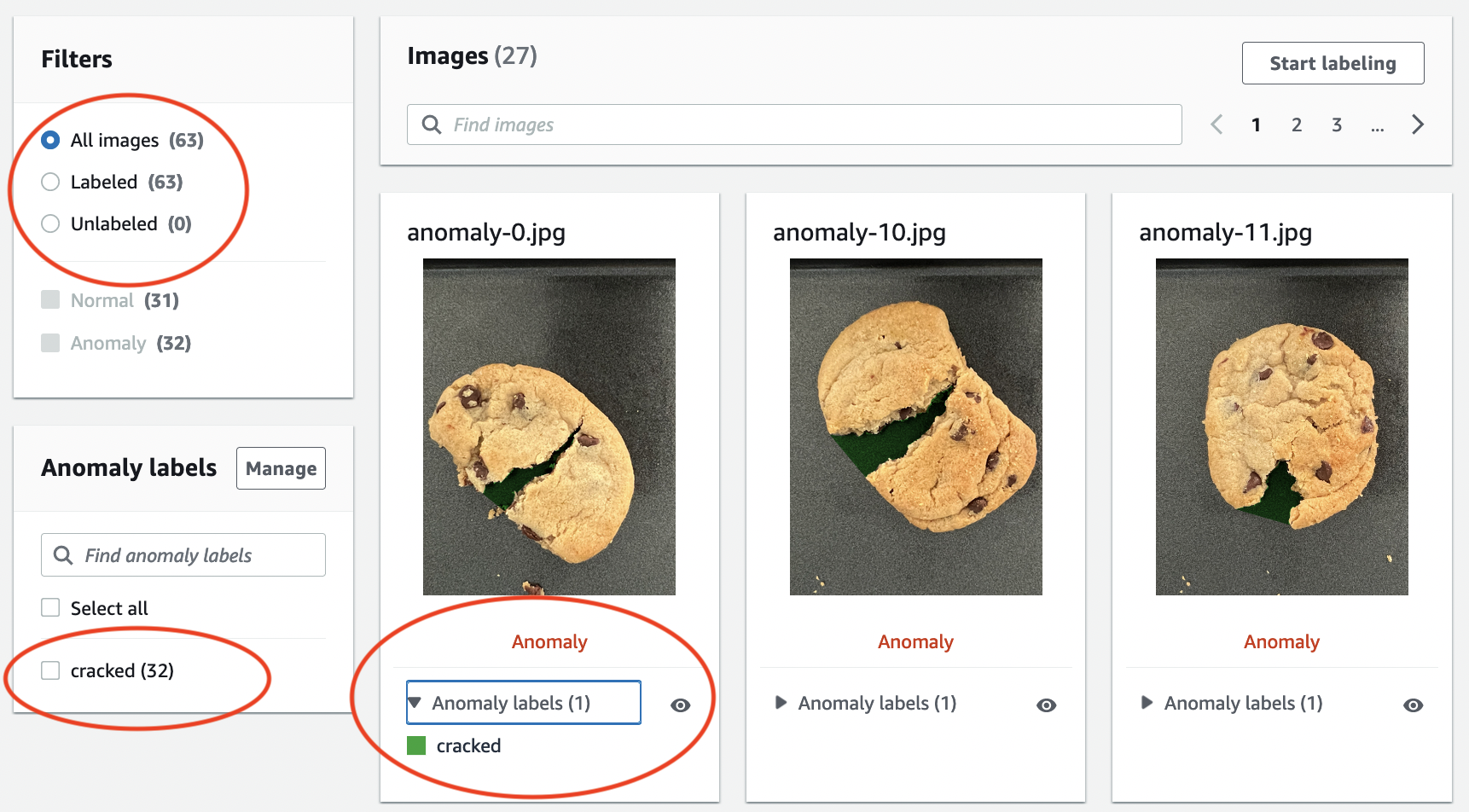
Nella pagina dei dettagli del progetto, nella sezione Immagini, visualizza le immagini del set di dati. È possibile visualizzare le informazioni sulla classificazione e sulla segmentazione delle immagini (etichette di maschere e anomalie) per ogni immagine del set di dati. Puoi anche cercare immagini, filtrare le immagini in base allo stato dell'etichettatura (etichettate/senza etichetta) o filtrare le immagini in base alle etichette di anomalia ad esse assegnate.
-
Nella pagina dei dettagli del progetto, scegli Modello ferroviario.
-
Nella pagina dei dettagli del modello di treno, scegli Modello di treno.
-
Nella sezione Vuoi addestrare il tuo modello? finestra di dialogo scegliere Modello di treno.
-
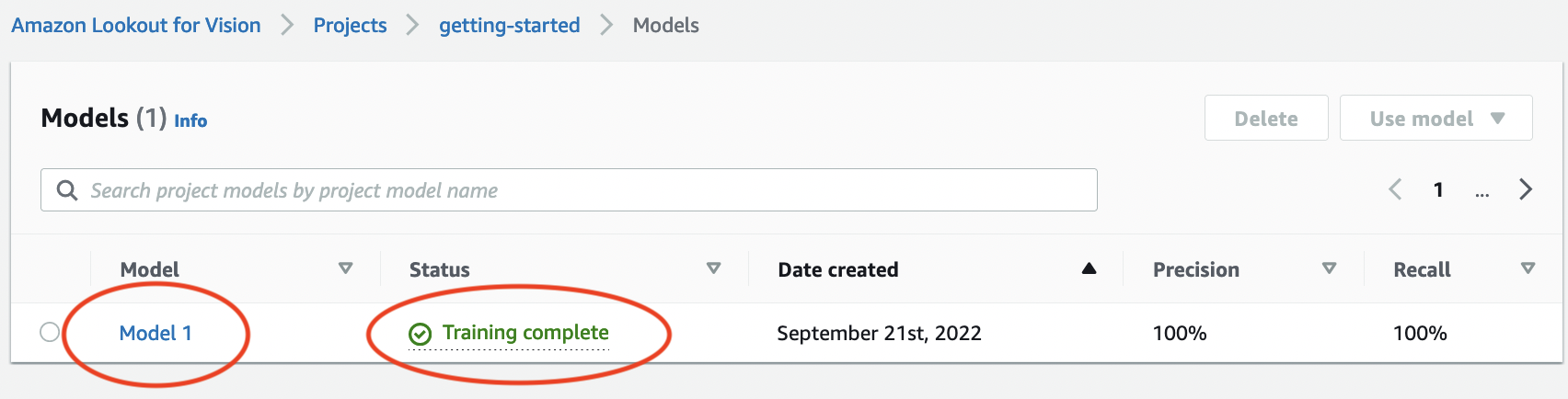
Nella pagina Modelli del progetto, puoi vedere che la formazione è iniziata. Controlla lo stato corrente visualizzando la colonna Stato per la versione del modello. L'addestramento del modello richiede almeno 30 minuti. L'allenamento è terminato con successo quando lo stato cambia in Allenamento completato.
-
Al termine dell'allenamento, scegli il modello Modello 1 nella pagina Modelli.
-
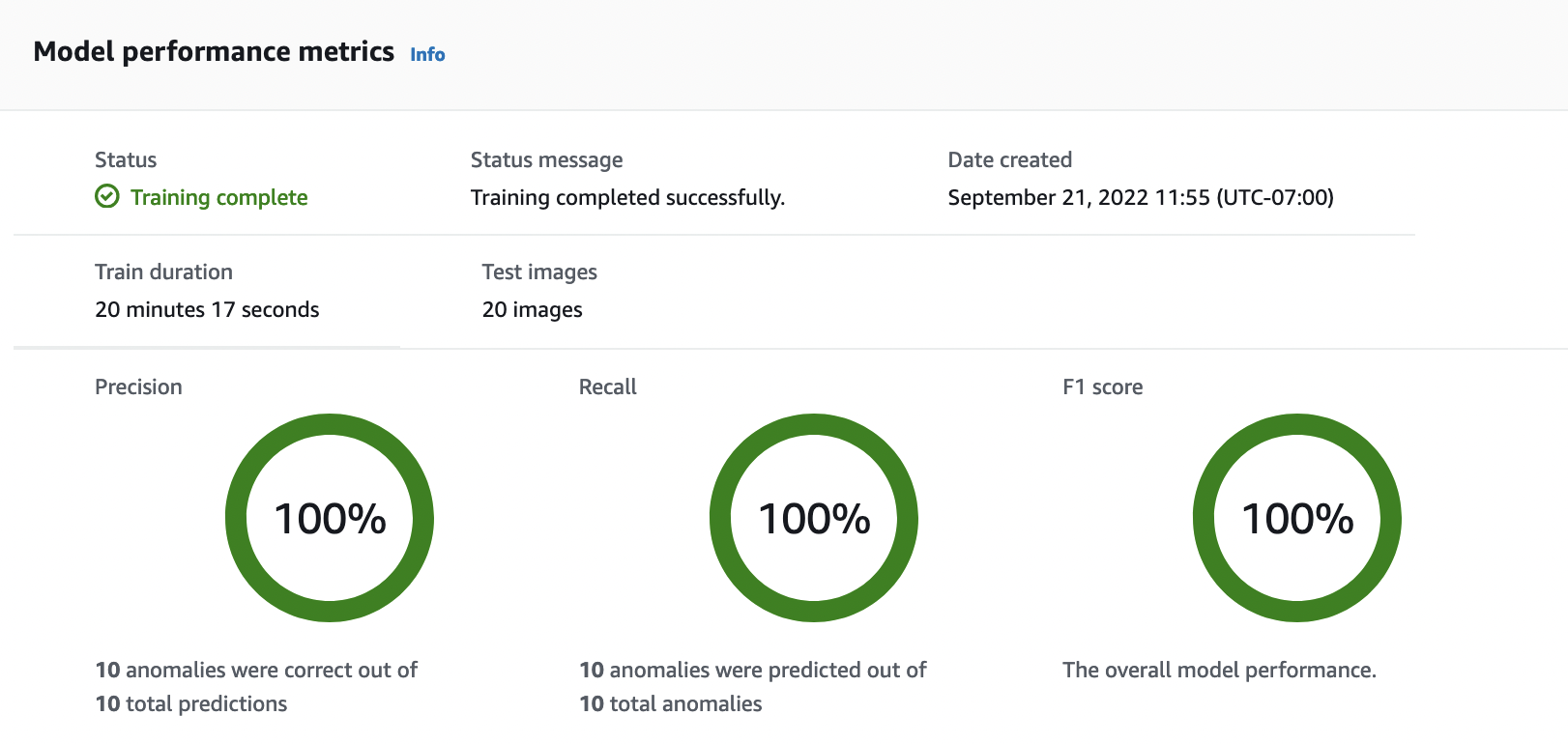
Nella pagina dei dettagli del modello, visualizza i risultati della valutazione nella scheda Metriche delle prestazioni. Esistono metriche per quanto segue:
-
Metriche complessive delle prestazioni del modello (precisione, richiamo e punteggio F1) per le previsioni di classificazione effettuate dal modello.
-
Metriche delle prestazioni per le etichette delle anomalie presenti nelle immagini del test (IoU medio, punteggio F1)

-
Previsioni per le immagini di test (classificazione, maschere di segmentazione ed etichette di anomalie)
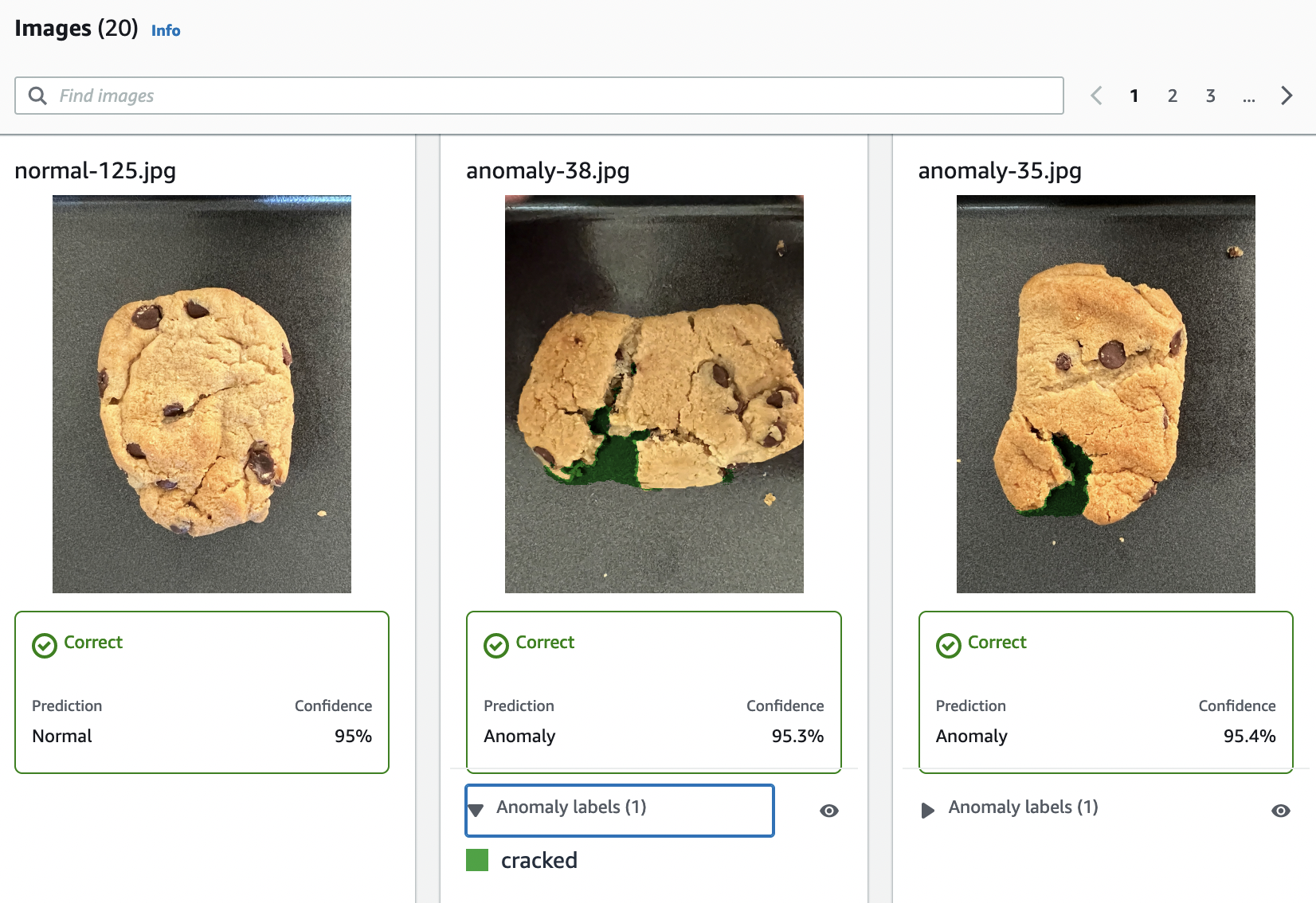
Poiché l'allenamento modello non è deterministico, i risultati della valutazione potrebbero differire dai risultati mostrati in questa pagina. Per ulteriori informazioni, consulta Come migliorare il modello Amazon Lookout for Vision.
-
Fase 3: avvio del modello
In questo passaggio, iniziate a ospitare il modello in modo che sia pronto per analizzare le immagini. Per ulteriori informazioni, consulta Esecuzione del modello Amazon Lookout for Vision addestrato.
Nota
Ti viene addebitato per il tempo di funzionamento del modello. Fai entrare il tuo modelloFase 5: Arresta il modello.
Per avviare il modello.
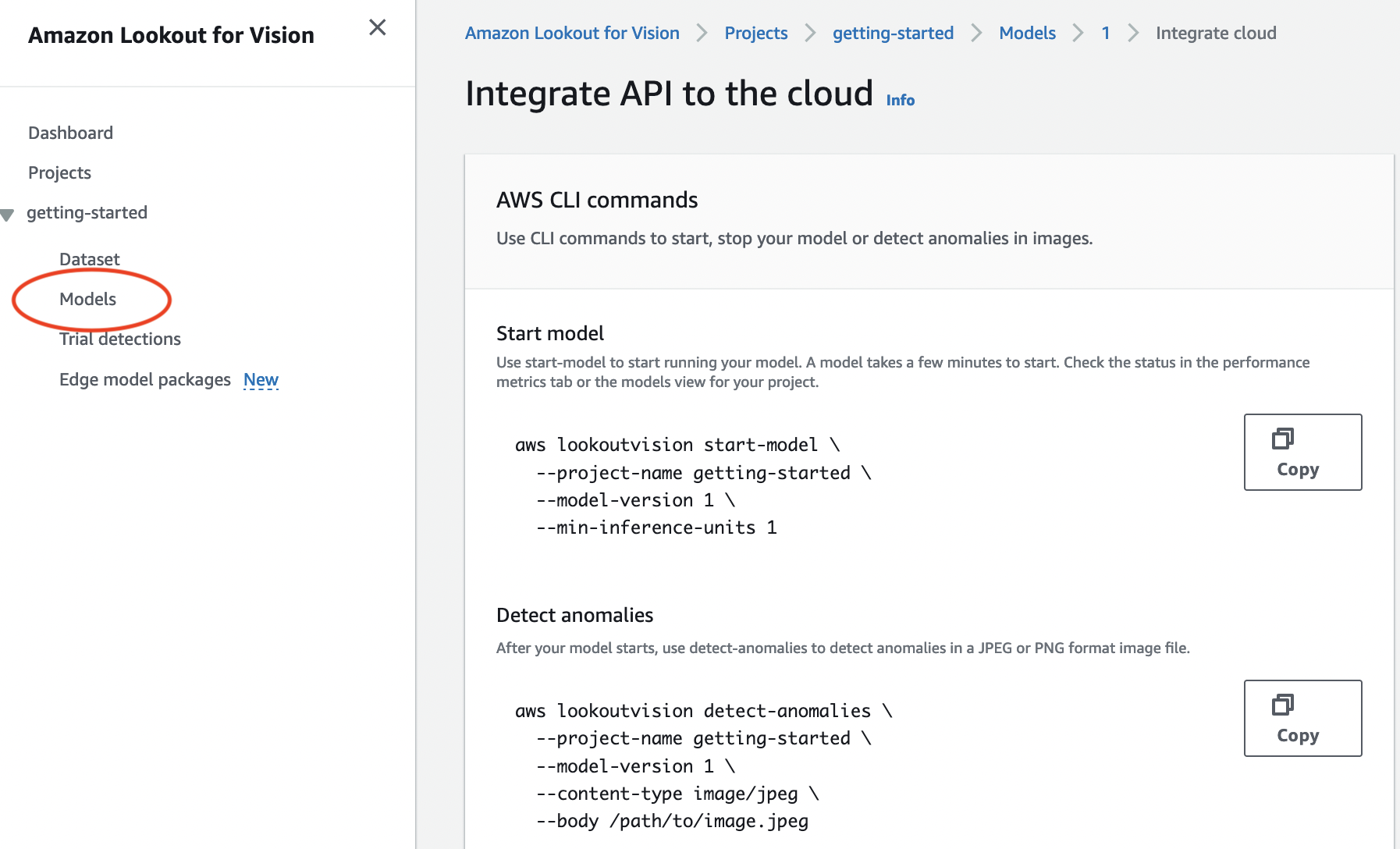
Nella pagina dei dettagli del modello, scegli Usa modello, quindi scegli Integrate API to the cloud.
Nella sezione AWS CLIcomandi, copia il
start-modelAWS CLI comando.
-
Assicurati che AWS CLI sia configurato per funzionare nella stessa AWS regione in cui utilizzi la console Amazon Lookout for Vision. Per modificare la AWS regione AWS CLI utilizzata, vedereInstalla gli SDK AWS.
-
Al prompt dei comandi, avviate il modello immettendo il
start-modelcomando. Se utilizzi illookoutvisionprofilo per ottenere le credenziali, aggiungi il--profile lookoutvision-accessparametro. Ad esempio:aws lookoutvision start-model \ --project-name getting-started \ --model-version 1 \ --min-inference-units 1 \ --profile lookoutvision-accessSe la chiamata ha esito positivo, viene visualizzato il seguente output:
{ "Status": "STARTING_HOSTING" } Nella console scegliere Modelli nel riquadro di navigazione.
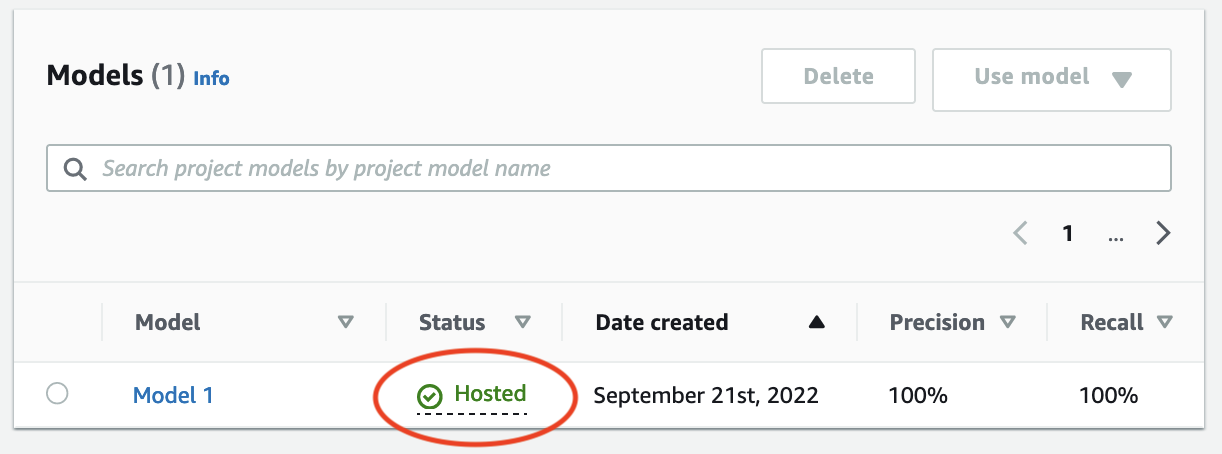
Attendere che lo stato del modello (Modello 1) nella colonna Stato venga visualizzato Hosted. Se hai già addestrato un modello nel progetto, attendi il completamento della versione più recente del modello.
Fase 4: Analisi di un'immagine
In questa fase verrà analizzata un'immagine con il modello. Forniamo immagini di esempio che puoi utilizzare nella test-images cartella Guida introduttiva dell'archivio della documentazione di Lookout for Vision sul tuo computer. Per ulteriori informazioni, consulta Rilevamento di anomalie in un'immagine.
Per analizzare un'immagine
-
Nella pagina Modelli, scegli il modello Modello 1.
-
Nella pagina dei dettagli del modello, scegli Usa modello, quindi scegli Integrate API to the cloud.
-
Nella sezione AWS CLIcomandi, copia il
detect-anomaliesAWS CLI comando.
-
Al prompt dei comandi, analizza un'immagine anomala inserendo il
detect-anomaliescomando del passaggio precedente. Per il --body parametro, specifica un'immagine anomala dalla test-images cartella introduttiva sul tuo computer. Se utilizzi illookoutvisionprofilo per ottenere le credenziali, aggiungi il--profile lookoutvision-accessparametro. Ad esempio:aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-anomaly-1.jpg\ --profile lookoutvision-accessL'output visualizzato dovrebbe essere simile al seguente:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": true, "Confidence": 0.983975887298584, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 0.9818974137306213, "Color": "#FFFFFF" } }, { "Name": "cracked", "PixelAnomaly": { "TotalPercentageArea": 0.018102575093507767, "Color": "#23A436" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAAMACA......" } } -
Nell'output, tenere presente quanto segue:
-
IsAnomalousè un valore booleano per la classificazione prevista.truese l'immagine è anomala, altrimenti.false -
Confidenceè un valore variabile che rappresenta la fiducia di Amazon Lookout for Vision nella previsione. 0 è il livello di confidenza più basso, 1 è l'affidabilità massima. -
Anomaliesè un elenco di anomalie rilevate nell'immagine.Nameè l'etichetta dell'anomalia.PixelAnomalyinclude l'area percentuale totale dell'anomalia (TotalPercentageArea) e un colore (Color) per l'etichetta dell'anomalia. L'elenco include anche un'anomalia di «sfondo» che copre l'area al di fuori delle anomalie rilevate nell'immagine. -
AnomalyMaskè un'immagine di maschera che mostra la posizione delle anomalie sull'immagine analizzata.
È possibile utilizzare le informazioni nella risposta per visualizzare una combinazione dell'immagine analizzata e maschera delle anomalie, come illustrato nell'esempio seguente. Per il codice di esempio, consulta Visualizzazione delle informazioni di classificazione e segmentazione.

-
-
Al prompt dei comandi, analizza un'immagine normale dalla
test-imagescartella introduttiva. Se utilizzi illookoutvisionprofilo per ottenere le credenziali, aggiungi il--profile lookoutvision-accessparametro. Ad esempio:aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-normal-1.jpg\ --profile lookoutvision-accessL'output visualizzato dovrebbe essere simile al seguente:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": false, "Confidence": 0.9916400909423828, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 1.0, "Color": "#FFFFFF" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAA....." } } -
Nell'output, nota che il
falsevalore diIsAnomalousclassifica l'immagine come priva di anomalie.ConfidenceUtilizzalo per determinare la tua fiducia nella classificazione. Inoltre, l'Anomaliesarray ha solo l'etichetta dell'backgroundanomalia.
Fase 5: Arresta il modello
In questa fase verrà interrotto l'hosting del modello. Ti viene addebitato il periodo di funzionamento del tuo modello. Se non utilizzi il modello, è necessario interromperlo. È possibile riavviare il modello quando è di nuovo necessario. Per ulteriori informazioni, consulta Avvio del modello Amazon Lookout for Vision.
Per fermare il modello.
-
Nel riquadro di navigazione scegliere Modelli.
Nella pagina Modelli, scegli il modello Modello 1.
Nella pagina dei dettagli del modello, scegli Usa modello, quindi scegli Integrate API to the cloud.
Nella sezione AWS CLIcomandi, copia il
stop-modelAWS CLI comando.
-
Al prompt dei comandi, arrestate il modello immettendo il
stop-modelAWS CLI comando del passaggio precedente. Se utilizzi illookoutvisionprofilo per ottenere le credenziali, aggiungi il--profile lookoutvision-accessparametro. Ad esempio:aws lookoutvision stop-model \ --project-name getting-started \ --model-version 1 \ --profile lookoutvision-accessSe la chiamata ha esito positivo, viene visualizzato il seguente output:
{ "Status": "STOPPING_HOSTING" } Torna alla console, scegli Modelli nella pagina di navigazione a sinistra.
Il modello si è fermato quando lo stato del modello nella colonna Stato è Allenamento completato.
Fasi successive
Quando sei pronto a creare un modello con le tue immagini, inizia seguendo le istruzioni inCreare il tuo progetto. Le istruzioni includono i passaggi per creare un modello con la console Amazon Lookout for Vision e con l'AWSSDK.
Se vuoi provare altri set di dati di esempio, vediCodice e set di dati di esempio.
