Avviso di fine del supporto: il 31 ottobre 2025 AWS interromperà il supporto per Amazon Lookout for Vision. Dopo il 31 ottobre 2025, non potrai più accedere alla console Lookout for Vision o alle risorse Lookout for Vision. Per ulteriori informazioni, consulta questo post del blog.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Informazioni su Amazon Lookout for Vision
Puoi usare Amazon Lookout for Vision per trovare difetti visivi nei prodotti industriali, in modo accurato e su larga scala, per attività come:
-
Rilevamento di parti danneggiate: individua i danni alla qualità della superficie, al colore e alla forma di un prodotto durante il processo di fabbricazione e assemblaggio.
-
Identificazione dei componenti mancanti: determina i componenti mancanti in base all'assenza, alla presenza o al posizionamento degli oggetti. Ad esempio, un condensatore mancante su un circuito stampato.
-
Individuazione dei problemi di processo: rileva i difetti con schemi ripetuti, come graffi ripetuti nello stesso punto su un wafer di silicio.
Con Lookout for Vision crei un modello di visione artificiale che prevede la presenza di anomalie in un'immagine. Fornisci le immagini che Amazon Lookout for Vision utilizza per addestrare e testare il tuo modello. Amazon Lookout for Vision fornisce metriche che puoi utilizzare per valutare e migliorare il tuo modello addestrato. Puoi ospitare il modello addestrato nel AWS cloud oppure puoi distribuirlo su un dispositivo edge. Una semplice operazione API restituisce le previsioni fatte dal modello.
Il flusso di lavoro generale per la creazione, la valutazione e l'utilizzo di un modello è il seguente:
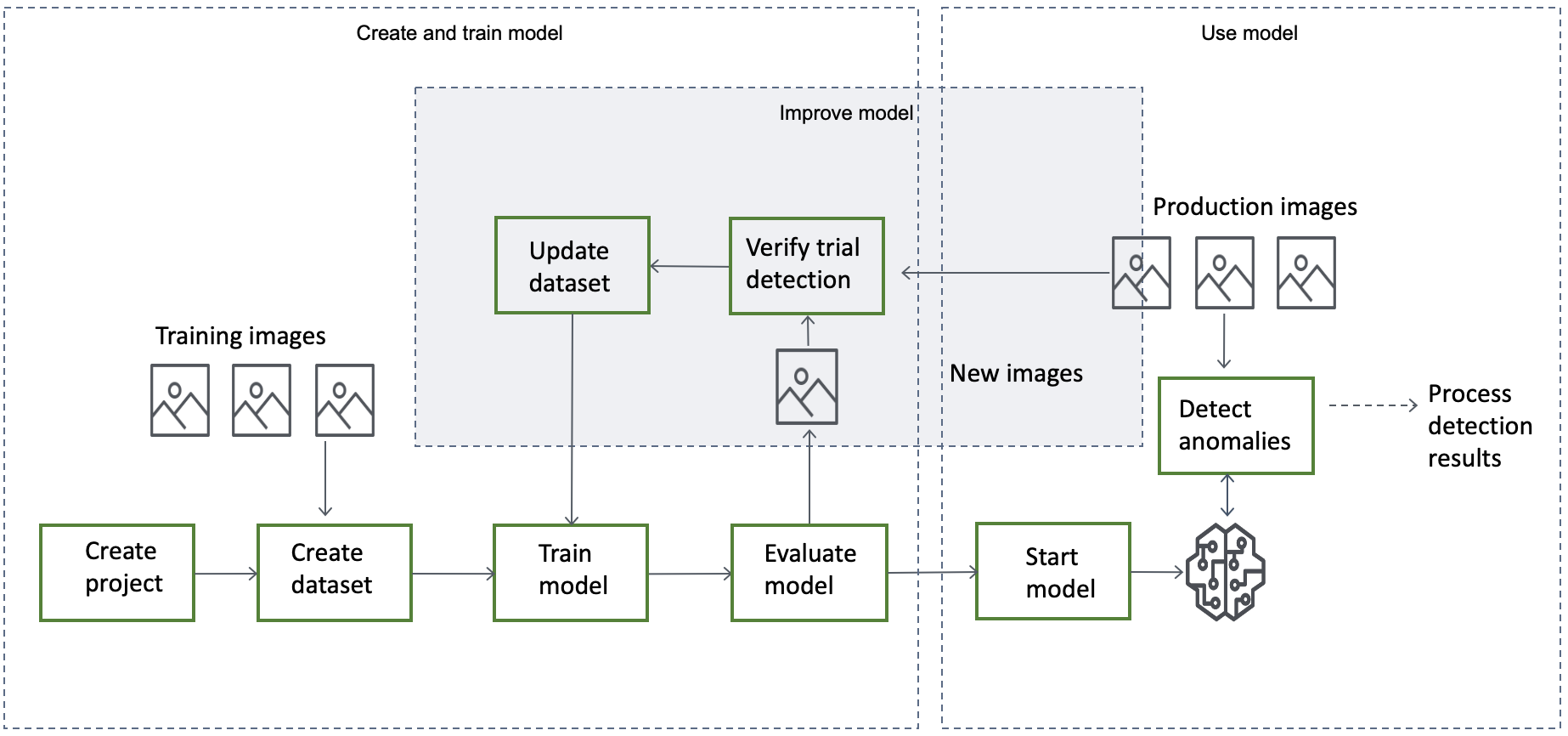
Argomenti
Scegliete il tipo di modello
Prima di creare un modello, è necessario decidere quale tipo di modello si desidera. È possibile creare due tipi di modello, la classificazione delle immagini e la segmentazione delle immagini. Siete voi a decidere quale tipo di modello creare in base al vostro caso d'uso.
Modello di classificazione delle immagini
Se hai solo bisogno di sapere se un'immagine contiene un'anomalia, ma non hai bisogno di conoscerne la posizione, crea un modello di classificazione delle immagini. Un modello di classificazione delle immagini consente di prevedere se un'immagine contiene un'anomalia. La previsione include la fiducia del modello nell'accuratezza della previsione. Il modello non fornisce alcuna informazione sulla posizione di eventuali anomalie rilevate nell'immagine.
Modello di segmentazione dell'immagine
Se hai bisogno di conoscere la posizione di un'anomalia, ad esempio la posizione di un graffio, crea un modello di segmentazione dell'immagine. I modelli Amazon Lookout for Vision utilizzano la segmentazione semantica per identificare i pixel di un'immagine in cui sono presenti i tipi di anomalie (come un graffio o una parte mancante).
Nota
Un modello di segmentazione semantica individua diversi tipi di anomalie. Non fornisce informazioni sulle istanze per singole anomalie. Ad esempio, se un'immagine contiene due ammaccature, Lookout for Vision restituisce informazioni su entrambe le ammaccature in un'unica entità che rappresenta il tipo di anomalia dell'ammaccatura.
Un modello di segmentazione di Amazon Lookout for Vision prevede quanto segue:
Classificazione
Il modello restituisce una classificazione per un'immagine analizzata (normale/anomalia), che include la fiducia del modello nella previsione. Le informazioni sulla classificazione vengono calcolate separatamente dalle informazioni di segmentazione e non si deve presumere una relazione tra di esse.
Segmentazione
Il modello restituisce una maschera di immagine che contrassegna i pixel in cui si verificano le anomalie sull'immagine. Diversi tipi di anomalia sono codificati a colori in base al colore assegnato all'etichetta di anomalia nel set di dati. Un'etichetta di anomalia rappresenta il tipo di anomalia. Ad esempio, la maschera blu nell'immagine seguente indica la posizione di un tipo di anomalia da graffio rilevato su un'auto.

Il modello restituisce il codice colore per ogni etichetta di anomalia nella maschera. Il modello restituisce anche la percentuale di copertura dell'immagine contenuta nell'etichetta di un'anomalia.
Con un modello di segmentazione Lookout for Vision, puoi utilizzare vari criteri per analizzare i risultati dell'analisi del modello. Per esempio:
-
Posizione delle anomalie: se hai bisogno di conoscere la posizione delle anomalie, utilizza le informazioni di segmentazione per visualizzare le maschere che coprono le anomalie.
-
Tipi di anomalia: utilizza le informazioni di segmentazione per decidere se un'immagine contiene più di un numero accettabile di tipi di anomalia.
-
Area di copertura: utilizza le informazioni di segmentazione per decidere se un tipo di anomalia copre più di un'area accettabile di un'immagine.
-
Classificazione delle immagini: se non hai bisogno di conoscere la posizione delle anomalie, utilizza le informazioni di classificazione per determinare se un'immagine contiene anomalie.
Per il codice di esempio, consulta Rilevamento di anomalie in un'immagine.
Dopo aver deciso quale tipo di modello desideri, crei un progetto e un set di dati per gestire il modello. Utilizzando Labels, è possibile classificare le immagini come normali o come anomalie. Le etichette identificano anche informazioni di segmentazione come maschere e tipi di anomalie. Il modo in cui etichettate le immagini nel set di dati determina il tipo di modello che Lookout for Vision crea per voi.
L'etichettatura di un modello di segmentazione delle immagini è più complessa dell'etichettatura di un modello di classificazione delle immagini. Per addestrare un modello di segmentazione, è necessario classificare le immagini di addestramento come normali o anomale. È inoltre necessario definire maschere di anomalia e tipi di anomalia per ogni immagine anomala. Un modello di classificazione richiede solo di identificare le immagini di addestramento come normali o anomale.
Crea il tuo modello
I passaggi per creare un modello sono la creazione di un progetto, la creazione di un set di dati e l'addestramento del modello sono i seguenti:
Crea un progetto
Crea un progetto per gestire i set di dati e i modelli che crei. Un progetto deve essere utilizzato per un singolo caso d'uso, ad esempio per rilevare anomalie in un singolo tipo di parte della macchina.
Puoi utilizzare la dashboard per avere una panoramica dei tuoi progetti. Per ulteriori informazioni, consulta Utilizzo della dashboard di Amazon Lookout for Vision.
Ulteriori informazioni: Crea il tuo progetto.
Creazione di un set di dati
Per addestrare un modello, Amazon Lookout for Vision necessita di immagini di oggetti normali e anomali per il tuo caso d'uso. Fornisci queste immagini in un set di dati.
Un set di dati è un insieme di immagini ed etichette che descrivono queste immagini. Le immagini devono rappresentare un singolo tipo di oggetto su cui possono verificarsi anomalie. Per ulteriori informazioni, consulta Preparazione delle immagini per un set di dati.
Con Amazon Lookout for Vision puoi avere un progetto che utilizza un singolo set di dati o un progetto con set di dati di formazione e test separati. Ti consigliamo di utilizzare un progetto con un singolo set di dati, a meno che tu non desideri un controllo più preciso su formazione, test e ottimizzazione delle prestazioni.
Puoi creare un set di dati importando le immagini. A seconda di come si importano le immagini, è possibile che le immagini siano anche etichettate. In caso contrario, si utilizza la console per etichettare le immagini.
Importazione di immagini
Se crei il set di dati con la console Lookout for Vision, puoi importare le immagini in uno dei seguenti modi:
-
Importa immagini dal tuo computer locale. Le immagini non sono etichettate.
-
Importa immagini da un bucket S3. Amazon Lookout for Vision può classificare le immagini utilizzando i nomi delle cartelle che contengono le immagini. Utilizzare
normalper immagini normali. Utilizzareanomalyper immagini anomale. Non è possibile assegnare automaticamente etichette di segmentazione. -
Importa un file manifest di Amazon SageMaker AI Ground Truth. Le immagini in un file manifesto sono etichettate. È possibile creare e importare il proprio file manifesto. Se hai molte immagini, prendi in considerazione l'utilizzo del servizio di etichettatura SageMaker AI Ground Truth. Importi quindi il file manifesto di output dal job Amazon SageMaker AI Ground Truth.
Immagini etichettate
Le etichette descrivono un'immagine in un set di dati. Le etichette specificano se un'immagine è normale o anomala (classificazione). Le etichette descrivono anche la posizione delle anomalie su un'immagine (segmentazione).
Se le immagini non sono etichettate, puoi utilizzare la console per etichettarle.
Le etichette assegnate alle immagini nel set di dati determinano il tipo di modello creato da Lookout for Vision:
Classificazione delle immagini
Per creare un modello di classificazione delle immagini, utilizza la console Lookout for Vision per classificare le immagini nel set di dati come normali o come anomalie.
Segmentazione delle immagini
Per creare un modello di segmentazione delle immagini, utilizza la console Lookout for Vision per classificare le immagini nel set di dati come normali o come anomalie. È inoltre possibile specificare maschere di pixel per le aree anomale dell'immagine (se esistono) e un'etichetta di anomalia per le singole maschere di anomalia.
Se il progetto ha set di dati di addestramento e test separati, Lookout for Vision utilizza il set di dati di addestramento per apprendere e determinare il tipo di modello. È necessario etichettare le immagini nel set di dati di test nello stesso modo.
Ulteriori informazioni: Creazione del set di dati.
Addestramento del modello
L'addestramento crea un modello e lo addestra a prevedere la presenza di anomalie nelle immagini. Ogni volta che ti alleni, viene creata una nuova versione del modello.
All'inizio della formazione, Amazon Lookout for Vision sceglie l'algoritmo più adatto con cui addestrare il tuo modello. Il modello viene addestrato e quindi testato. Se si Guida introduttiva ad Amazon Lookout for Vision addestra un singolo progetto di set di dati, il set di dati viene suddiviso internamente per creare un set di dati di addestramento e un set di dati di test. Puoi anche creare un progetto con set di dati di addestramento e test separati. In questa configurazione, Amazon Lookout for Vision addestra il tuo modello con il set di dati di addestramento e testa il modello con il set di dati di test.
Importante
Ti viene addebitato il tempo necessario per addestrare correttamente il tuo modello.
Ulteriori informazioni: Addestra il tuo modello.
Valutazione del modello
Valuta le prestazioni del tuo modello utilizzando le metriche delle prestazioni create durante i test.
Utilizzando le metriche prestazionali, puoi comprendere meglio le prestazioni del tuo modello addestrato e decidere se sei pronto per utilizzarlo in produzione.
Ulteriori informazioni: Miglioramento del modello.
Se le metriche delle prestazioni indicano che sono necessari miglioramenti, puoi aggiungere altri dati di allenamento eseguendo un'attività di rilevamento di prova con nuove immagini. Una volta completata l'attività, puoi verificare i risultati e aggiungere le immagini verificate al set di dati di allenamento. In alternativa, puoi aggiungere nuove immagini di allenamento direttamente al set di dati. Successivamente, riqualificate il modello e ricontrollate le metriche delle prestazioni.
Ulteriori informazioni: verifica del modello con un'attività di rilevamento di prova.
Usa il tuo modello
Prima di poter utilizzare il modello nel AWS cloud, avviate il modello con l'StartModeloperazione. Puoi ottenere il comando StartModel CLI per il tuo modello dalla console.
Ulteriori informazioni: Avvia il tuo modello.
Un modello Amazon Lookout for Vision addestrato prevede se un'immagine di input contiene contenuti normali o anomali. Se il modello è un modello di segmentazione, la previsione include una maschera di anomalia che contrassegna i pixel in cui vengono rilevate le anomalie.
Per fare una previsione con il modello, richiamate l'DetectAnomaliesoperazione e passate un'immagine di input dal computer locale. È possibile ottenere il comando CLI che chiama DetectAnomalies dalla console.
Ulteriori informazioni: Rileva anomalie in un'immagine.
Importante
Ti viene addebitato il tempo di funzionamento del modello.
Se non utilizzate più il modello, utilizzate l'StopModeloperazione per arrestarlo. È possibile ottenere il comando CLI dalla console.
Ulteriori informazioni: Arresta il tuo modello.
Usa il tuo modello su un dispositivo edge
Puoi utilizzare un modello Lookout for Vision su AWS IoT Greengrass Version 2 un dispositivo principale.
Ulteriori informazioni: Utilizzo del modello Amazon Lookout for Vision su un dispositivo edge.
Usa la tua dashboard
Puoi utilizzare la dashboard per avere una panoramica di tutti i tuoi progetti e informazioni generali per i singoli progetti.
Ulteriori informazioni: Usa la tua dashboard.
