Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Casi d’uso
Di seguito sono riportati i casi d'uso della ricerca vettoriale.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) sfrutta la ricerca vettoriale per recuperare i passaggi pertinenti da un ampio corpus di dati per ampliare un ampio modello linguistico (LLM). In particolare, un codificatore incorpora il contesto di input e la query di ricerca in vettori, quindi utilizza la ricerca approssimativa del vicino più vicino per trovare passaggi semanticamente simili. Questi passaggi recuperati vengono concatenati con il contesto originale per fornire ulteriori informazioni pertinenti all'LLM e restituire una risposta più accurata all'utente.
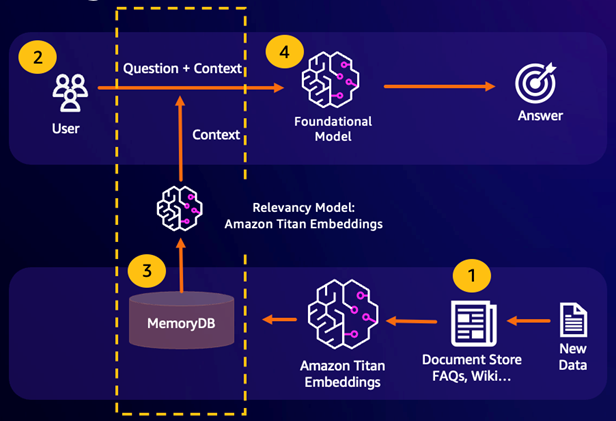
Cache semantica durevole
Il caching semantico è un processo per ridurre i costi di calcolo memorizzando i risultati precedenti dell'FM. Riutilizzando i risultati precedenti delle inferenze precedenti anziché ricalcolarli, la memorizzazione nella cache semantica riduce la quantità di calcolo richiesta durante l'inferenza tramite. FMs MemoryDB consente un caching semantico duraturo, che evita la perdita di dati delle inferenze passate. Ciò consente alle applicazioni di intelligenza artificiale generativa di rispondere entro millisecondi a una cifra con risposte a domande semanticamente simili precedenti, riducendo al contempo i costi evitando inferenze LLM non necessarie.
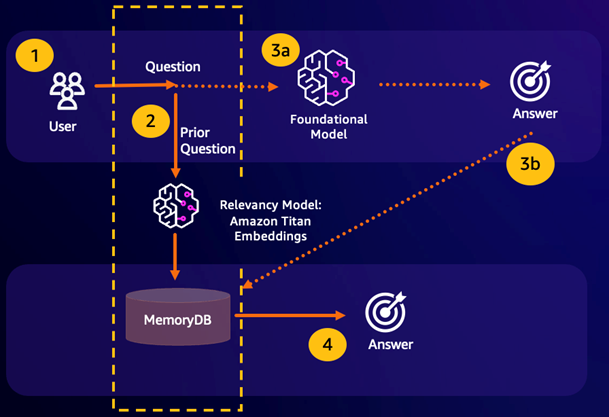
Risultato della ricerca semantica: se la query di un cliente è semanticamente simile a una domanda precedente sulla base di un punteggio di somiglianza definito, la memoria buffer FM (MemoryDB) restituirà la risposta alla domanda precedente nel passaggio 4 e non richiamerà l'FM durante i passaggi 3. In questo modo si eviteranno la latenza del modello di base (FM) e i costi sostenuti, garantendo un'esperienza più rapida per il cliente.
Ricerca semantica non riuscita: se la query di un cliente non è semanticamente simile in base a un punteggio di somiglianza definito a una query precedente, un cliente chiamerà l'FM per fornire una risposta al cliente nella fase 3a. La risposta generata dalla FM verrà quindi archiviata come vettore in MemoryDB per le query future (fase 3b) per ridurre al minimo i costi FM su domande semanticamente simili. In questo flusso, il passaggio 4 non verrebbe richiamato in quanto non esisteva una domanda semanticamente simile per la query originale.
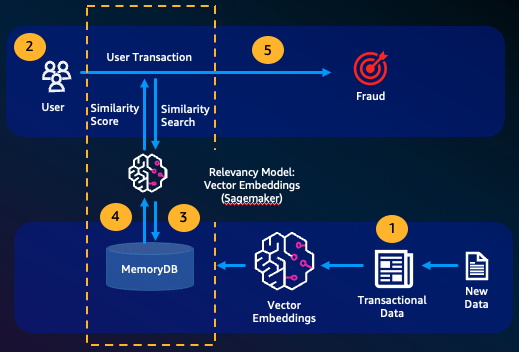
Rilevamento di attività fraudolente
Il rilevamento delle frodi, una forma di rilevamento delle anomalie, rappresenta le transazioni valide come vettori confrontando le rappresentazioni vettoriali delle nuove transazioni nette. La frode viene rilevata quando queste nuove transazioni nette hanno una bassa somiglianza con i vettori che rappresentano i dati transazionali validi. Ciò consente di rilevare le frodi modellando il comportamento normale, anziché cercare di prevedere ogni possibile caso di frode. MemoryDB consente alle organizzazioni di eseguire questa operazione in periodi di elevata produttività, con falsi positivi minimi e una latenza di un millisecondo.
Altri casi d'uso
I motori di raccomandazione possono trovare agli utenti prodotti o contenuti simili rappresentando gli elementi come vettori. I vettori vengono creati analizzando attributi e modelli. In base ai modelli e agli attributi degli utenti, è possibile consigliare agli utenti nuovi elementi invisibili trovando i vettori più simili già valutati positivamente allineati all'utente.
I motori di ricerca di documenti rappresentano i documenti di testo come vettori densi di numeri, che catturano il significato semantico. Al momento della ricerca, il motore converte una query di ricerca in un vettore e trova i documenti con i vettori più simili alla query utilizzando la ricerca approssimativa del vicino più prossimo. Questo approccio alla somiglianza vettoriale consente di abbinare i documenti in base al significato anziché semplicemente alle parole chiave.
