Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice operative per Amazon OpenSearch Service
Questo capitolo fornisce le best practice per la gestione dei domini Amazon OpenSearch Service e include linee guida generali che si applicano a molti casi d'uso. Ogni carico di lavoro è unico, con caratteristiche uniche, quindi nessun suggerimento generico è adatto per ogni caso d'uso. La best practice più importante consiste nell'implementare, testare e ottimizzare i domini in un ciclo continuo per trovare la configurazione, la stabilità e il costo ottimali per il tuo carico di lavoro.
Monitoraggio e avvisi
Le seguenti best practice si applicano al monitoraggio dei domini OpenSearch di servizio.
Configura CloudWatch gli allarmi
OpenSearch Il servizio invia metriche sulle prestazioni ad Amazon. CloudWatch Esamina regolarmente i parametri del cluster e dell'istanza e configura gli CloudWatch allarmi consigliati in base alle prestazioni del carico di lavoro.
Abilitazione della pubblicazione dei log
OpenSearch Il servizio espone i log degli OpenSearch errori, gli slow log di ricerca, gli slow log di indicizzazione e i log di controllo in Amazon Logs. CloudWatch I log di ricerca lenti, i log di indicizzazione lenti e i log di errore sono utili per la risoluzione dei problemi relativi alle prestazioni e alla stabilità. I log di verifica, disponibili solo se abiliti il controllo granulare degli accessi, monitorano l'attività dell'utente. Per ulteriori informazioni, consulta Logs nella documentazione.
I log di ricerca lenti e i log di indicizzazione lenti sono uno strumento importante per comprendere e risolvere i problemi delle prestazioni delle operazioni di ricerca e indicizzazione. Abilita la distribuzione di log lenti di ricerca e di indice per tutti i domini di produzione. È inoltre necessario configurare le soglie di registrazione, altrimenti i registri CloudWatch non verranno acquisiti.
Strategia di partizione
Gli shard distribuiscono il carico di lavoro tra i nodi di dati del dominio di servizio. OpenSearch Gli indici configurati correttamente possono contribuire a migliorare le prestazioni complessive del dominio.
Quando invii dati a OpenSearch Service, invii tali dati a un indice. Un indice è analogo a una tabella di database, con documenti come le righe e campi come le colonne. Quando crei l'indice, dici OpenSearch quanti shard primari vuoi creare. Gli shard primari sono partizioni indipendenti dell'intero set di dati. OpenSearch Il servizio distribuisce automaticamente i dati tra gli shard primari di un indice. Puoi inoltre configurare le repliche dell'indice. Ogni partizione di replica comprende un set completo di copie delle partizioni primarie per quell'indice.
OpenSearch Il servizio mappa gli shard per ogni indice tra i nodi di dati del cluster. Questo assicura che le partizioni primarie e di replica per l'indice risiedano su nodi di dati diversi. La prima replica garantisce la presenza di due copie dei dati nell'indice. Dovresti sempre usare almeno una replica. Le repliche aggiuntive forniscono ridondanza e capacità di lettura aggiuntive.
OpenSearch invia richieste di indicizzazione a tutti i nodi di dati che contengono frammenti che appartengono all'indice. Invia le richieste di indicizzazione prima ai nodi di dati che contengono partizioni primarie e poi ai nodi di dati che contengono partizioni di replica. Le richieste di ricerca vengono indirizzate dal nodo coordinatore a una partizione primaria o di replica per tutte le partizioni appartenenti all'indice.
Ad esempio, per un indice con cinque shard primari e una replica per ogni shard primario, ogni richiesta di indicizzazione riguarda 10 shard. Le richieste di ricerca, invece, vengono inviate a n partizioni, dove n è il numero di partizioni primarie. Per un indice con cinque partizioni primarie e una replica, ogni query di ricerca interessa cinque partizioni (primarie o di replica) da quell'indice.
Determinazione del numero di partizioni e di nodi di dati
Utilizza le seguenti best practice per determinare il numero di partizioni e nodi di dati per il tuo dominio.
Dimensione delle partizioni: la dimensione dei dati su disco è il risultato diretto della dimensione dei dati di origine e cambia man mano che indicizzi più dati. Il rapporto origine/indice può variare notevolmente, da 1:10 a 10:1 o più, ma di solito è di circa 1:1.10. Puoi utilizzare questo rapporto per prevedere la dimensione dell'indice su disco. Puoi inoltre indicizzare alcuni dati e recuperare le dimensioni effettive dell'indice per determinare il rapporto per il tuo carico di lavoro. Una volta ottenuta una dimensione dell'indice prevista, imposta un numero di partizioni in modo che ogni partizione abbia una dimensione compresa tra 10 e 30 GiB (per i carichi di lavoro di ricerca) o tra 30 e 50 GiB (per i carichi di lavoro dei log). 50 GiB dovrebbe essere il massimo; assicurati di pianificare la crescita.
Conteggio partizioni: la distribuzione delle partizioni sui nodi di dati ha un grande impatto sulle prestazioni di un dominio. Quando hai indici con più shard, prova a fare in modo che gli shard contino un multiplo del conteggio dei nodi di dati. Ciò aiuta a garantire che le partizioni siano distribuite uniformemente tra i nodi di dati e previene i nodi ad accesso frequente. Ad esempio, se disponi di 12 partizioni primarie, il numero di nodi di dati deve essere 2, 3, 4, 6 o 12. Tuttavia, il numero delle partizioni è secondario rispetto alla dimensione delle partizioni; se disponi di 5 GiB di dati, dovresti comunque usare una singola partizione.
Partizioni per nodo di dati: il numero totale di partizioni che un nodo può contenere è proporzionale alla memoria heap JVM (Java Virtual Machine) del nodo. Punta a 25 partizioni o meno per GiB di memoria heap. Ad esempio, un nodo con 32 GiB di memoria heap non deve contenere più di 800 partizioni. Sebbene la distribuzione degli shard possa variare in base ai modelli di carico di lavoro, esiste un limite di 1.000 shard per nodo per Elasticsearch e da OpenSearch 1,1 a 2,15 e 4.000 per 2.17 e versioni successive. OpenSearch L'cat/allocation
Rapporto partizione/CPU: quando una partizione è coinvolta in una richiesta di indicizzazione o ricerca, utilizza una vCPU per elaborare la richiesta. Come best practice, utilizza un punto di scala iniziale di 1,5 vCPU per partizione. Se il tuo tipo di istanza presenta 8 vCPU, imposta il conteggio dei nodi di dati in modo che ogni nodo non abbia più di sei partizioni. Si tratta di un'approssimazione. Assicurati di testare il carico di lavoro e dimensionare il cluster di conseguenza.
Per suggerimenti sul volume di storage, la dimensione delle partizioni e il tipo di istanza, consulta le seguenti risorse:
Evitare l'asimmetria di storage
L'asimmetria di archiviazione si verifica quando uno o più nodi all'interno di un cluster detengono una percentuale maggiore di archiviazione per uno o più indici rispetto agli altri. L'utilizzo non uniforme della CPU, la latenza intermittente e irregolare e l'accodamento non uniforme tra i nodi di dati sono tutte indicazioni di asimmetria di archiviazione. Per determinare se sono presenti problemi di asimmetria, consulta le seguenti sezioni sulla risoluzione dei problemi:
Stabilità
Le seguenti best practice si applicano al mantenimento di un dominio di OpenSearch servizio stabile e integro.
Tieniti aggiornato con OpenSearch
Aggiornamenti del software del servizio
OpenSearch Il servizio rilascia regolarmente aggiornamenti software che aggiungono funzionalità o migliorano in altro modo i tuoi domini. Gli aggiornamenti non modificano né la versione del motore Elasticsearch OpenSearch né quella del motore Elasticsearch. Ti consigliamo di pianificare un orario ricorrente per eseguire l'operazione dell'DescribeDomainAPI e di avviare un aggiornamento del software di servizio, se lo è. UpdateStatus ELIGIBLE Se non aggiorni il dominio entro un determinato periodo di tempo (in genere due settimane), il OpenSearch Servizio esegue automaticamente l'aggiornamento.
OpenSearch aggiornamenti di versione
OpenSearch Il servizio aggiunge regolarmente il supporto per le versioni gestite dalla community di. OpenSearch Effettua sempre l'upgrade alle OpenSearch versioni più recenti quando sono disponibili.
OpenSearch Il servizio aggiorna contemporaneamente entrambe le OpenSearch OpenSearch dashboard (o Elasticsearch e Kibana se il dominio utilizza un motore legacy). Se il cluster dispone di nodi master dedicati, gli aggiornamenti vengono completati senza tempi di inattività. In caso contrario, il cluster potrebbe non rispondere per diversi secondi dopo l'aggiornamento mentre elegge un nodo principale. OpenSearch I dashboard potrebbero non essere disponibili durante alcuni o tutti gli upgrade.
Ci sono due modi per aggiornare un dominio:
-
In-place aggiornamento: questa opzione è più semplice perché mantieni lo stesso cluster.
-
Snapshot/restore upgrade: questa opzione è utile per testare nuove versioni su un nuovo cluster o migrare tra cluster.
Indipendentemente dal processo di aggiornamento utilizzato, ti consigliamo di mantenere un dominio destinato esclusivamente allo sviluppo e al test e di aggiornarlo alla nuova versione prima di aggiornare il dominio di produzione. Quando crei il dominio di test, scegli Development and testing (Sviluppo e test) per il tipo di implementazione. Assicurati di aggiornare tutti i client alle versioni compatibili subito dopo l'aggiornamento del dominio.
Migliora le prestazioni delle istantanee
Per evitare che l'istantanea rimanga bloccata durante l'elaborazione, il tipo di istanza per il nodo master dedicato deve corrispondere al numero di shard. Per ulteriori informazioni, consulta Scelta dei tipi di istanza per nodi principali dedicati. Inoltre, ogni nodo non deve avere più dei 25 shard consigliati per GiB di memoria heap Java. Per ulteriori informazioni, consulta Scelta del numero di partizioni.
Abilitare nodi principali dedicati
I nodi principali dedicati migliorano la stabilità del cluster. Un nodo principale dedicato esegue attività di gestione del cluster ma non conserva dati di indice né risponde a richieste del client. Questo offload delle attività di gestione del cluster aumenta la stabilità del dominio e consente di apportare modifiche alla configurazione senza avere tempi di inattività.
Abilita e utilizza tre nodi principali dedicati per una stabilità ottimale del dominio in tre zone di disponibilità. La distribuzione Multi-AZ con Standby configura tre nodi master dedicati per te. Per suggerimenti sul tipo di istanza, consulta Scelta dei tipi di istanza per nodi principali dedicati.
Esecuzione dell'implementazione in più zone di disponibilità
Per prevenire la perdita di dati e ridurre al minimo i tempi di inattività del cluster in caso di interruzione del servizio, puoi distribuire i nodi tra due o tre zone di disponibilità nella stessa Regione AWS. La procedura ottimale consiste nell'eseguire l'implementazione utilizzando Multi-AZ Standby, che configura tre zone di disponibilità, con due zone attive e una che funge da standby, e con due shard di replica per indice. Questa configurazione consente a OpenSearch Service di distribuire gli shard di replica su AZ diversi rispetto ai corrispondenti shard primari. Non sono previsti costi di trasferimento dei dati tra zone di disponibilità per le comunicazioni dei cluster tra zone di disponibilità.
Le zone di disponibilità sono più posizioni isolate all'interno di ogni regione . Con una configurazione a due zone di disponibilità, perdere una zona di disponibilità significa perdere metà della capacità totale del dominio. Il passaggio a tre zone di disponibilità riduce ulteriormente l'impatto della perdita di una singola zona di disponibilità.
Controllo del flusso di importazione e del buffering
Consigliamo di limitare il numero complessivo delle richieste utilizzando l'operazione API _bulk_bulk contenente 5.000 documenti anziché inviare 5.000 richieste contenenti un singolo documento.
Per una stabilità operativa ottimale, a volte è necessario limitare o addirittura sospendere il flusso upstream delle richieste di indicizzazione. Limitare la percentuale di richieste di indicizzazione è un meccanismo importante per gestire picchi imprevisti o occasionali nelle richieste che potrebbero altrimenti sovraccaricare il cluster. Valuta la possibilità di creare un meccanismo di controllo del flusso nella tua architettura upstream.
Il diagramma seguente mostra più opzioni di componenti per un'architettura di importazione dei log. Configura il livello di aggregazione per avere spazio sufficiente per il buffering dei dati in ingresso per picchi di traffico improvvisi e brevi interventi di manutenzione del dominio.
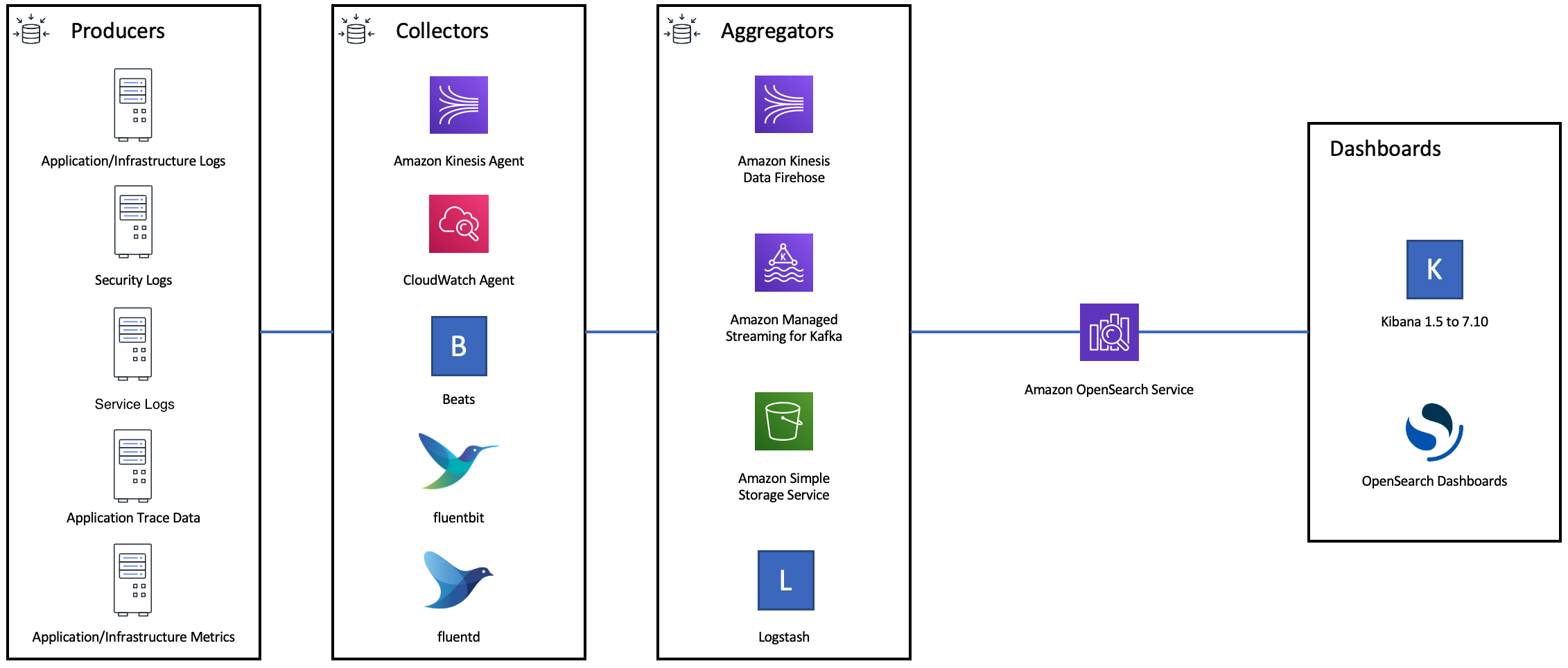
Creare mappature per i carichi di lavoro di ricerca
Per i carichi di lavoro di ricerca, crea mappaturedynamic su strict per evitare l'aggiunta accidentale di nuovi campi.
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
Utilizzare modelli di indici
È possibile utilizzare un modello di indice
Le seguenti impostazioni sono particolarmente utili per la configurazione nei modelli:
-
Numero di partizioni primarie e di replica
-
Intervallo di aggiornamento (con quale frequenza aggiornare e rendere disponibili per la ricerca le modifiche recenti all'indice)
-
Controllo dinamico delle mappature
-
Mappature di campi esplicite
Il seguente modello di esempio contiene ognuna di queste impostazioni:
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
Anche se cambiano raramente, avere impostazioni e mappature definite centralmente OpenSearch è più semplice da gestire rispetto all'aggiornamento di più client upstream.
Gestire gli indici con Index State Management
Se gestisci log o dati di serie temporali, ti consigliamo di utilizzare Index State Management (ISM). ISM consente di automatizzare attività regolari di gestione del ciclo di vita degli indici. Con ISM, puoi creare policy che attivano i rollover degli alias degli indici, eseguire snapshot degli indici, spostare gli indici tra i livelli di archiviazione ed eliminare gli indici precedenti. Puoi persino usare le operazioni di rollover
In primo luogo, configura una policy ISM. Per un esempio, consulta Policy di esempio. Quindi, collega la policy a uno o più indici. Se includi un campo modello ISM nella policy, OpenSearch Service applica automaticamente la policy a qualsiasi indice che corrisponda al modello specificato.
Rimuovere gli indici inutilizzati
Esamina regolarmente gli indici nel tuo cluster e identifica quelli che non sono in uso. Esegui uno snapshot di questi indici in modo che siano archiviati in S3, quindi eliminali. Quando rimuovi gli indici inutilizzati, riduci il numero di partizioni e si consente una distribuzione dell'archiviazione e un utilizzo delle risorse più bilanciati tra i nodi. Anche quando sono inattivi, gli indici consumano alcune risorse durante le attività interne di manutenzione degli indici.
Anziché eliminare manualmente gli indici inutilizzati, puoi utilizzare ISM per eseguire automaticamente un'istantanea ed eliminare gli indici dopo un certo periodo di tempo.
Utilizzare più domini per un'elevata disponibilità
Per ottenere un'elevata disponibilità oltre un tempo di attività del 99,9%
Progetta le tue applicazioni upstream e downstream tenendo presente il failover. Assicurati di testare il processo di failover insieme ad altri processi di ripristino di emergenza.
Performance
Le seguenti best practice si applicano all'ottimizzazione dei domini per ottenere prestazioni ottimali.
Ottimizzare le dimensioni e la compressione delle richieste in blocco
Il dimensionamento in blocco dipende dai dati, dall'analisi e dalla configurazione del cluster, ma un buon punto di partenza è 3-5 MiB per ciascuna richiesta in blocco.
Invia richieste e ricevi risposte dai tuoi OpenSearch domini utilizzando la compressione gzip per ridurre la dimensione del payload di richieste e risposte. Puoi usare la compressione gzip con il client OpenSearch Python o includendo le seguenti intestazioni dal lato client:
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
Per ottimizzare le dimensioni delle richieste in blocco, inizia con una richiesta in blocco di 3 MiB. Quindi, aumentane lentamente la dimensione finché le prestazioni di indicizzazione non smettono di migliorare.
Nota
Per abilitare la compressione gzip sui domini che eseguono Elasticsearch versione 6.x, devi impostare http_compression.enabled a livello di cluster. Questa impostazione è vera per impostazione predefinita nelle versioni 7.x di Elasticsearch e in tutte le versioni di. OpenSearch
Ridurre le dimensioni delle risposte alle richieste in blocco
Per ridurre la dimensione delle OpenSearch risposte, escludi i campi non necessari con il parametro. filter_path Assicurati di non escludere i campi necessari per identificare o provare nuovamente le richieste non riuscite. Per maggiori informazioni ed esempi, consulta Riduzione delle dimensioni della risposta.
Ottimizzare gli intervalli di aggiornamento
OpenSearch gli indici alla fine hanno una consistenza di lettura. Un'operazione di aggiornamento rende disponibili per la ricerca tutti gli aggiornamenti eseguiti su un indice. L'intervallo di aggiornamento predefinito è di un secondo, il che significa che OpenSearch esegue un aggiornamento ogni secondo durante la scrittura di un indice.
Meno frequentemente si aggiorna un indice (intervallo di aggiornamento più elevato), migliori sono le prestazioni complessive di indicizzazione. L'aumento dell'intervallo di aggiornamento comporta un ritardo maggiore tra l'aggiornamento dell'indice e la disponibilità dei nuovi dati per la ricerca. Imposta l'intervallo di aggiornamento al livello più alto che puoi tollerare per migliorare le prestazioni complessive.
Consigliamo di impostare il parametro refresh_interval per tutti gli indici su 30 secondi o più.
Abilita Auto-Tune
Auto-Tuneutilizza le metriche di prestazioni e utilizzo del OpenSearch cluster per suggerire modifiche alle dimensioni delle code, alle dimensioni della cache e alle impostazioni della macchina virtuale Java (JVM) sui nodi. Queste modifiche facoltative migliorano la velocità e la stabilità del cluster. È possibile ripristinare le impostazioni predefinite del OpenSearch servizio in qualsiasi momento. Auto-Tune è abilitato per impostazione predefinita sui nuovi domini, a meno che non venga disabilitato esplicitamente.
Ti consigliamo di abilitarlo Auto-Tune su tutti i domini e di impostare una finestra di manutenzione periodica o di rivederne periodicamente i consigli.
Sicurezza
Le seguenti best practice si applicano alla protezione dei domini.
Abilitare il controllo granulare degli accessi
Fine-grained il controllo degli accessi consente di controllare chi può accedere a determinati dati all'interno di un OpenSearch dominio di servizio. Rispetto al controllo degli accessi generalizzato, il controllo granulare degli accessi fornisce a ciascun cluster, indice, documento e campo la propria policy specifica per l'accesso. I criteri di accesso possono essere basati su una serie di fattori, tra cui il ruolo della persona che richiede l'accesso e l'azione che intende eseguire sui dati. Ad esempio, potresti concedere a un utente l'accesso per scrivere su un indice, mentre a un altro potrebbe essere concesso l'accesso solo per leggere i dati sull'indice senza apportare alcuna modifica.
Fine-grained il controllo degli accessi consente ai dati con requisiti di accesso diversi di esistere nello stesso spazio di archiviazione senza incorrere in problemi di sicurezza o conformità.
Si consiglia di abilitare il controllo granulare degli accessi sui domini.
Distribuire domini all'interno di un VPC
Posizionare il dominio del OpenSearch servizio all'interno di un cloud privato virtuale (VPC) consente una comunicazione sicura tra il OpenSearch Servizio e altri servizi all'interno del VPC, senza la necessità di un gateway Internet, un dispositivo NAT o una connessione VPN. Tutto il traffico rimane sicuro all'interno del Cloud. AWS Grazie a loro isolamento logico, i domini che si trovano all'interno di un VPC hanno un ulteriore livello di sicurezza rispetto ai domini che usano gli endpoint pubblici.
Consigliamo di creare domini all'interno di un VPC.
Applicare una policy di accesso restrittiva
Anche se il tuo dominio è implementato all'interno di un VPC, è meglio implementare la sicurezza a più livelli. Assicurati di controllare la configurazione delle tue attuali policy di accesso.
Applica una politica di accesso restrittiva basata sulle risorse ai tuoi domini e segui il principio del privilegio minimo quando concedi l'accesso all'API di configurazione e alle operazioni dell'API. OpenSearch Come regola generale, evita di utilizzare il principale utente anonimo"Principal": {"AWS": "*" } nelle policy di accesso.
Esistono tuttavia alcune situazioni in cui è accettabile utilizzare una policy di accesso aperto, ad esempio quando abiliti il controllo degli accessi granulare. Una policy di accesso aperto può consentirti di accedere al dominio nei casi in cui la firma delle richieste è difficile o impossibile, ad esempio da determinati client e strumenti.
Abilitare la crittografia dei dati a riposo
OpenSearch I domini di servizio offrono la crittografia dei dati inattivi per impedire l'accesso non autorizzato ai dati. Encryption at rest utilizza AWS Key Management Service (AWS KMS) per archiviare e gestire le chiavi di crittografia e l'algoritmo Advanced Encryption Standard con chiavi a 256 bit (AES-256) per eseguire la crittografia.
Se il dominio archivia i dati sensibili, abilita la crittografia dei dati a riposo.
Abilitare la crittografia da nodo a nodo
Node-to-node la crittografia fornisce un ulteriore livello di sicurezza oltre alle funzionalità di sicurezza predefinite di Service. OpenSearch Implementa Transport Layer Security (TLS) per tutte le comunicazioni tra i nodi che vengono forniti all'interno. OpenSearch Node-to-node crittografia, tutti i dati inviati al dominio del OpenSearch servizio tramite HTTPS rimangono crittografati in transito mentre vengono distribuiti e replicati tra i nodi.
Se il dominio archivia i dati sensibili, abilita la crittografia da nodo a nodo.
Monitora con AWS Security Hub CSPM
Monitora l'utilizzo del OpenSearch Servizio in relazione alle migliori pratiche di sicurezza utilizzando AWS Security Hub CSPM. Security Hub CSPM utilizza i controlli di sicurezza per valutare le configurazioni delle risorse e gli standard di sicurezza per aiutarti a rispettare vari framework di conformità. Per ulteriori informazioni sull'utilizzo di Security Hub CSPM per valutare le risorse OpenSearch del servizio, vedere Amazon OpenSearch Service i controlli nella Guida per l'AWS Security Hub utente.
Ottimizzazione dei costi
Le seguenti best practice si applicano all'ottimizzazione e al risparmio sui costi del OpenSearch Servizio.
Utilizzare tipi di istanza di ultima generazione
OpenSearch Service adotta sempre nuovi tipi di istanze Amazon EC2 che offrono prestazioni migliori a un costo inferiore. Si consiglia di utilizzare sempre istanze di ultima generazione.
Non utilizzare istanze T2 o t3.small per i domini di produzione in quanto possono diventare instabili in presenza di carichi pesanti sostenuti. Le istanze r6g.large sono un'opzione per piccoli carichi di lavoro di produzione (sia come nodi di dati che come nodi principali dedicati).
Utilizzo dei volumi gp3 di Amazon EBS più recenti
OpenSearch i nodi di dati richiedono uno storage a bassa latenza e ad alto throughput per fornire indicizzazione e query rapide. Utilizzando i volumi gp3 Amazon EBS, ottieni prestazioni di base (IOPS e velocità di trasmissione effettiva) più elevate a un costo inferiore del 9,6% rispetto al tipo di volume gp2 Amazon EBS offerto in precedenza. È possibile fornire IOPS evelocità di trasmissione effettiva aggiuntivi indipendentemente dalle dimensioni del volume tramite gp3. Questi volumi sono inoltre più stabili rispetto ai volumi della generazione precedente in quanto non utilizzano crediti di espansione. Il tipo di volume gp3 raddoppia anche i limiti di dimensione del volume per nodo dati del tipo di volume gp2. Con questi volumi più grandi, è possibile ridurre il costo dei dati passivi aumentando la quantità di spazio di archiviazione per nodo di dati.
Utilizzo UltraWarm e conservazione a freddo per i dati di registro delle serie temporali
Se li utilizzi OpenSearch per l'analisi dei log, trasferisci i dati in una cella frigorifera per ridurre i costi. UltraWarm Utilizza Index State Management (ISM) per migrare i dati tra livelli di storage e gestire la conservazione dei dati.
UltraWarmoffre un modo conveniente per archiviare grandi quantità di dati di sola lettura in Service. OpenSearch UltraWarm utilizza Amazon S3 per lo storage, il che significa che i dati sono immutabili e ne è necessaria solo una copia. Paghi solo per lo spazio di archiviazione equivalente alla dimensione delle partizioni primarie negli indici. Le latenze per le UltraWarm query crescono con la quantità di dati S3 necessari per soddisfare la query. Dopo che i dati sono stati memorizzati nella cache dei nodi, le query sugli indici hanno prestazioni simili alle query sugli UltraWarm indici caldi.
Lo storage a freddo è supportato anche da S3. Quando è necessario interrogare dati non aggiornati, è possibile collegarli in modo selettivo ai nodi esistenti. UltraWarm I cold data comportano gli stessi costi di storage gestito UltraWarm, ma gli oggetti in cold storage non consumano le risorse dei UltraWarm nodi. Pertanto, la conservazione a freddo offre una notevole capacità di archiviazione senza influire sulle dimensioni o sul numero dei UltraWarm nodi.
UltraWarm diventa conveniente quando si dispone di circa 2,5 TiB di dati da migrare dallo storage a caldo. Monitora il tasso di riempimento e pianifica di spostare gli indici UltraWarm prima di raggiungere quel volume di dati.
Rivedere i suggerimenti per le istanze riservate
Considera l'acquisto di istanze riservate (RI) dopo aver ottenuto una buona linea guida sulle prestazioni e sul consumo di calcolo. Gli sconti partono dal 30% circa per prenotazioni di 1 anno senza anticipo e possono aumentare fino al 50% per tutti gli impegni anticipati di 3 anni.
Dopo aver osservato un funzionamento stabile per almeno 14 giorni, consulta Accedere ai consigli di prenotazione nella Guida per l'AWS Cost Management utente. L'intestazione Amazon OpenSearch Service mostra consigli di acquisto del RI specifici e risparmi previsti.
