Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
| Per l'archiviazione e l'analisi degli eventi, Amazon SNS ora consiglia di utilizzare la sua integrazione nativa con Amazon Data Firehose. Puoi abbonare i flussi di distribuzione Firehose agli argomenti SNS, il che ti consente di inviare notifiche a endpoint di archiviazione e analisi come i bucket Amazon Simple Storage Service (Amazon S3), le tabelle Amazon Redshift, Amazon Service (Service) e altro ancora. OpenSearch OpenSearch L'uso di Amazon SNS con i flussi di distribuzione Firehose è una soluzione completamente gestita e priva di codice che non richiede l'utilizzo di funzioni. AWS Lambda Per ulteriori informazioni, consulta Flussi di distribuzione da Fanout a Firehose. |
È possibile utilizzare Amazon SNS per creare applicazioni basate su eventi che utilizzano i servizi del sottoscrittore per eseguire automaticamente il lavoro in risposta a eventi attivati dai servizi del publisher. Questo modello di architettura può rendere i servizi più riutilizzabili, interoperabili e scalabili. Tuttavia, può essere impegnativo eseguire il forking dell'elaborazione di eventi in pipeline rivolte ai requisiti di gestione di eventi comuni, come l’archiviazione, il backup, la ricerca, l'analisi dei dati e la riproduzione.
Per accelerare lo sviluppo delle tue applicazioni basate sugli eventi, puoi sottoscrivere pipeline di gestione degli eventi, basate su AWS Event Fork Pipelines, agli argomenti di Amazon SNS. AWS Event Fork Pipelines è una suite di applicazioni annidate open source, basata sul AWS Serverless Application Model
Per un AWS caso d'uso di Event Fork Pipelines, vedi. Implementazione e test dell'applicazione di esempio Amazon SNS Event Fork Pipeline
Argomenti
Come funziona AWS Event Fork Pipelines
AWS Event Fork Pipelines è un modello di progettazione senza server. Tuttavia, è anche una suite di applicazioni serverless annidate basate su AWS SAM (che potete implementare direttamente da (AWS SAR) alle vostre piattaforme per AWS Serverless Application Repository arricchire le vostre piattaforme basate sugli Account AWS eventi). È possibile distribuire queste applicazioni nidificate individualmente, come richiesto dall'architettura.
Argomenti
Il diagramma seguente mostra un'applicazione AWS Event Fork Pipelines integrata da tre applicazioni annidate. È possibile distribuire qualsiasi pipeline della suite AWS Event Fork Pipelines sul SAR in modo indipendente, come richiesto dall'architettura. AWS
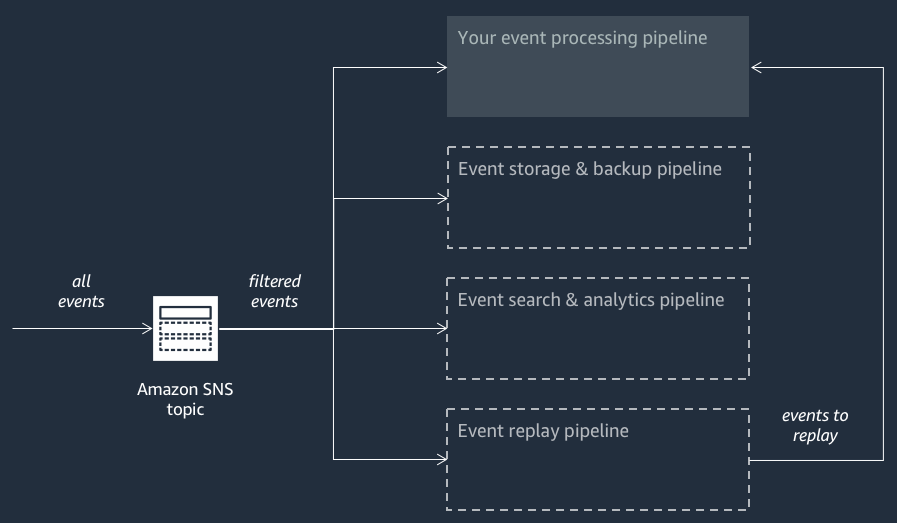
Ogni pipeline è sottoscritta allo stesso argomento Amazon SNS, facendo così in modo di elaborare eventi non appena vengono pubblicati nell'argomento. Ogni pipeline è indipendente ed è in grado di impostare la propria Policy di filtro per le sottoscrizioni. In questo modo una pipeline può elaborare solo un sottoinsieme di eventi a cui è interessata (invece che tutti gli eventi pubblicati nell'argomento).
Nota
Poiché colloca le tre AWS Event Fork Pipeline insieme alle normali pipeline di elaborazione degli eventi (probabilmente già iscritto al tuo argomento Amazon SNS), non è necessario modificare alcuna parte del tuo attuale editore di messaggi per sfruttare AWS Event Fork Pipelines nei tuoi carichi di lavoro esistenti.
La pipeline di archiviazione di eventi e di backup
Il seguente diagramma mostra la Pipeline di archiviazione di eventi e di backup
Questa pipeline è composta da una coda Amazon SQS che memorizza nel buffer gli eventi forniti dall'argomento Amazon SNS, AWS Lambda una funzione che esegue automaticamente il polling di questi eventi nella coda e li inserisce in un flusso Amazon Data Firehose e un bucket Amazon S3 che esegue il backup durevole degli eventi caricati dallo stream.
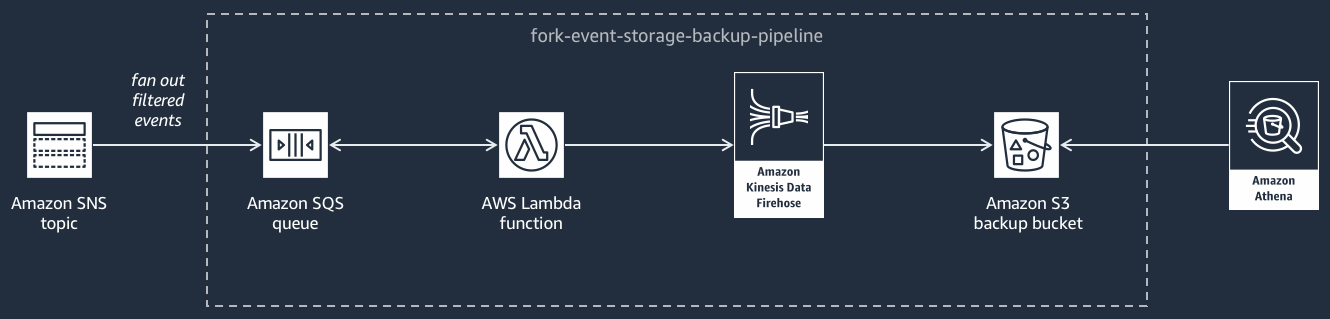
Per affinare il comportamento del flusso Firehose, puoi configurarlo in modo che trasformi, comprima ed esegua il buffering degli eventi prima di caricarli nel bucket. Man mano che gli eventi vengono caricati, puoi utilizzare Amazon Athena per eseguire query sul bucket utilizzando query SQL standard. Puoi anche configurare la pipeline in modo che riutilizzi un bucket Amazon S3 esistente o ne crei uno nuovo.
La pipeline di ricerca di eventi e di analisi dei dati
Il seguente diagramma mostra la Pipeline di ricerca di eventi e di analisi dei dati
Questa pipeline è composta da una coda Amazon SQS che memorizza nel buffer gli eventi forniti dall'argomento Amazon SNS, AWS Lambda una funzione che analizza gli eventi dalla coda e li inserisce in un flusso Amazon Data Firehose, un dominio Amazon OpenSearch Service che indicizza gli eventi caricati dal flusso Firehose e un bucket Amazon S3 che memorizza gli eventi con lettera morta che non può essere indicizzato nel dominio di ricerca.
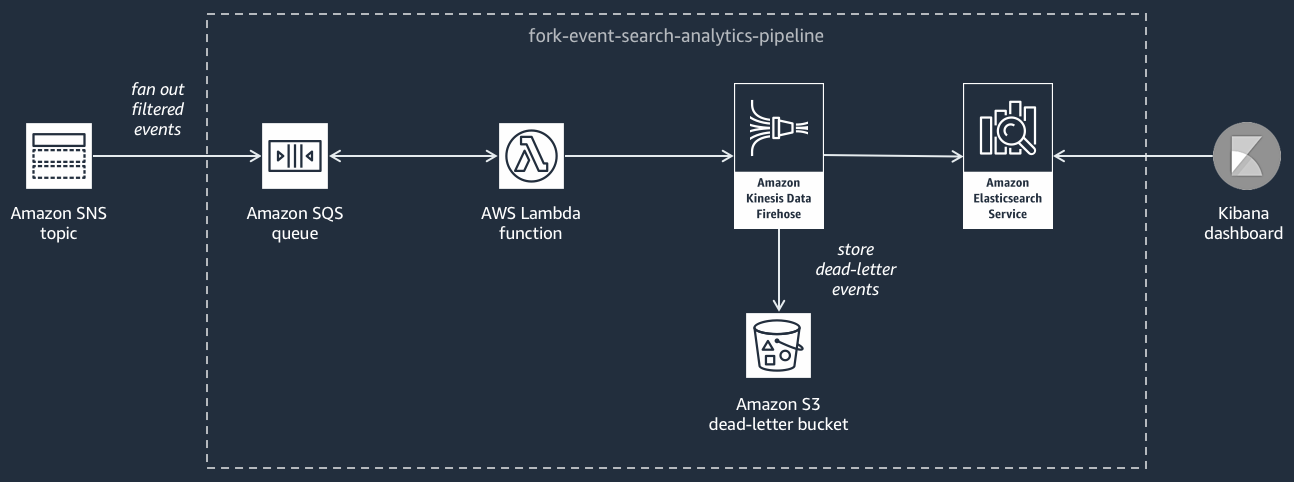
Per affinare il flusso Firehose in termini di buffering, trasformazione e compressione degli eventi, puoi configurare questa pipeline.
Puoi anche configurare se la pipeline deve riutilizzare un OpenSearch dominio esistente nel tuo dominio Account AWS o crearne uno nuovo per te. Man mano che gli eventi vengono indicizzati nel dominio di ricerca, puoi utilizzare Kibana per eseguire l’analisi dei dati sugli eventi e aggiornare i pannelli di controllo visivi in tempo reale.
Pipeline di riproduzione eventi
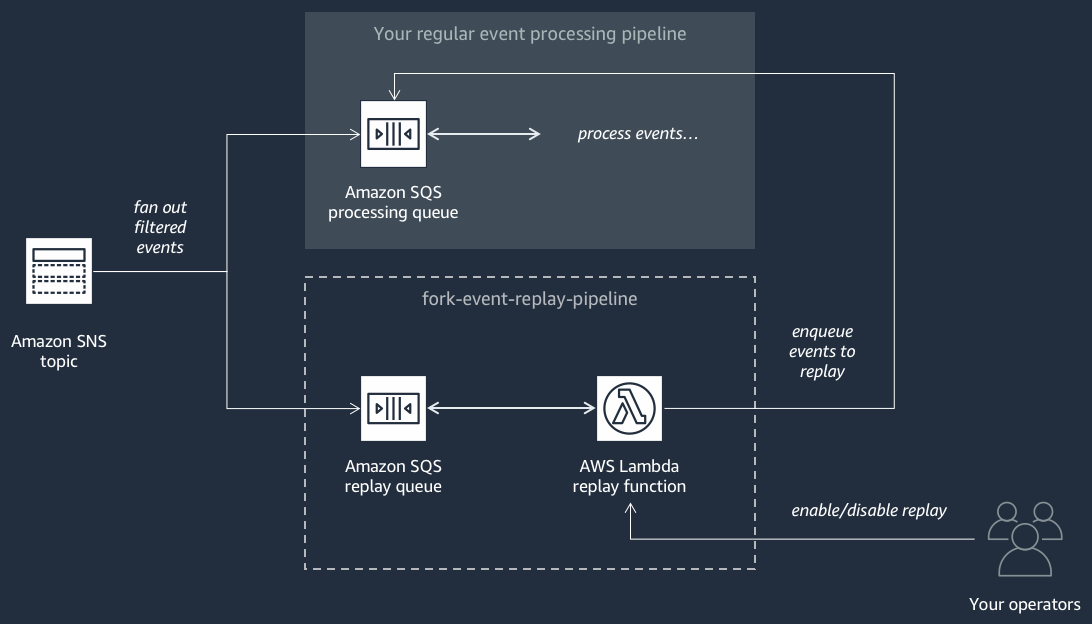
Il seguente diagramma mostra la Pipeline di riproduzione eventi
Questa pipeline è composta da una coda Amazon SQS che memorizza nel buffer gli eventi forniti dall'argomento Amazon SNS e da AWS Lambda una funzione che analizza gli eventi dalla coda e li reindirizza nella normale pipeline di elaborazione degli eventi, anch'essa associata al tuo argomento.
Nota
Per impostazione predefinita, la funzione di riproduzione è disattivata e gli eventi non vengono reindirizzati. Se devi rielaborare gli eventi, devi abilitare la coda di riproduzione Amazon SQS come origine dell'evento per la funzione di riproduzione AWS Lambda .
Implementazione di Event Fork AWS Pipelines
La suite AWS Event Fork Pipelines
In uno scenario di produzione, consigliamo di incorporare AWS Event Fork Pipelines nel modello SAM generale dell'applicazione. AWS La funzionalità di applicazione annidata consente di eseguire questa operazione aggiungendo la risorsa AWS::Serverless::Application al modello AWS SAM, facendo riferimento al AWS SAR ApplicationId e all'applicazione nidificata. SemanticVersion
Ad esempio, è possibile utilizzare Event Storage and Backup Pipeline come applicazione annidata aggiungendo il seguente frammento YAML alla sezione del Resources modello SAM. AWS
Backup:
Type: AWS::Serverless::Application
Properties:
Location:
ApplicationId: arn:aws:serverlessrepo:us-east-2:123456789012:applications/fork-event-storage-backup-pipeline
SemanticVersion: 1.0.0
Parameters:
#The ARN of the Amazon SNS topic whose messages should be backed up to the Amazon S3 bucket.
TopicArn: !Ref MySNSTopicQuando specificate i valori dei parametri, potete utilizzare le funzioni AWS CloudFormation intrinseche per fare riferimento ad altre risorse del modello. Ad esempio, nello snippet YAML riportato sopra, il TopicArn parametro fa riferimento alla AWS::SNS::Topic risorsaMySNSTopic, definita altrove nel modello. AWS SAM Per ulteriori informazioni, consulta la Riferimento funzione intrinseca nella AWS CloudFormation Guida per l’utente.
Nota
La pagina della AWS Lambda console dell'applicazione AWS SAR include il pulsante Copia come risorsa SAM, che copia il codice YAML necessario per annidare un'applicazione SAR negli appunti. AWS
