サービスの詳細ページで詳細なサービスアクティビティとオペレーションヘルスを表示する
アプリケーションを計測すると、Amazon CloudWatch Application Signals は、アプリケーションが検出したすべてのサービスをマッピングします。特定のサービスのサービス概要、オペレーション、依存関係、Canary、クライアントリクエストを確認するには、サービスの詳細ページを使用します。これらの詳細を表示するには、以下を実行します。
-
CloudWatch コンソール
を開きます。 -
左側のナビゲーションペインの [Application Signals] のセクションで[サービス] をクリックします。
-
[サービス]、[上位サービス]、[依存関係] のテーブルから、任意のサービスの名前を選択します。
[schedule-visits] では、サービス名の下にアカウント ラベルと ID が表示されます。
サービスの詳細ページは、次のタブで構成されています。
-
[概要] - このタブは、オペレーション、依存関係、Synthetics、クライアントページの数など、特定のサービスの概要を表示するときに使用します。また、サービス全体に関する主要なメトリクス、上位のオペレーション、依存関係が表示されます。これらのメトリクスには、そのサービスのすべてのサービスオペレーションの、レイテンシー、障害、エラーに関する時系列データが含まれます。
-
[サービスオペレーション] — このタブは、サービスが呼び出すオペレーションの一覧と、各オペレーションのヘルスを測定する主要メトリクスで構成された、実況グラフを表示するときに使用します。グラフ内のデータポイントを選択すると、そのデータポイントに関連付けられたトレース、ログ、メトリクスに関する情報を取得できます。
-
[依存関係] — このタブは、サービスが呼び出す依存関係の一覧と、それら依存関係のメトリクスの一覧を表示するときに使用します。
-
[Synthetics Canary] — このタブは、サービスへのユーザーコールをシミュレートする Synthetics Canary の一覧と、それら Canary の主要なパフォーマンスメトリクスを表示するときに使用します。
-
[クライアントページ] — このタブは、サービスを呼び出すクライアントページの一覧と、クライアントとアプリケーションとのインタラクションの質を測定する、メトリクスを表示するときに使用します。
-
関連メトリクス — このタブを使用して、サービス、そのオペレーションまたは依存関係の標準メトリクス、ランタイムメトリクス、カスタムメトリクスなどの関連メトリクスを関連付けます。
サービス概要の表示
サービス概要ページを使用すると、すべてのサービスオペレーションの、メトリクスの概要を 1 か所で表示できます。オペレーション、依存関係、クライアントページ、Synthetics Canary のすべてとアプリケーションとのインタラクションのパフォーマンスをチェックします。この情報があれば、問題を特定し、エラーをトラブルシューティングし、最適化の機会の見つけるために、どこに重点をおくべきかを判断するのに役立ちます。
[サービスの詳細] で任意のリンクをクリックし、特定のサービスに関連する情報を表示します。例えば、Amazon EKS でホストされているサービスの場合、サービスの詳細ページに [クラスター]、[名前空間]、[ワークロード] の情報が表示されます。Amazon ECS または Amazon EC2 でホストされているサービスの場合、[サービスの詳細] ページに [環境] の値が表示されます。
[サービス] の [概要] タブには、以下の項目の概要が表示されます。
-
[オペレーション] – このタブは、サービスオペレーションのヘルスを確認するときに使用します。ヘルスの状態は、サービスレベル目標 (SLO) の一部として定義されているサービスレベル指標 (SLI) によって判定されます。
-
[依存関係] — このタブは、アプリケーションによって呼び出されるサービスの上位の依存関係を障害率別に表示するときとサービスの依存関係の正常性を表示するときに使用します。ヘルスの状態は、サービスレベル目標 (SLO) の一部として定義されているサービスレベル指標 (SLI) によって判定されます。
-
[Synthetics Canary] – このタブは、サービスに関連付けられたエンドポイントまたは API への、シミュレートされた呼び出しの結果と、失敗した Canary の数を表示するときに使用します。
-
[クライアントページ] – このタブは、非同期 JavaScript と XML (AJAX) にエラーがあるクライアントが呼び出した、トップページを表示するときに使用します。
次の図に、サービスの概要を示します。

[概要] タブには、すべてのサービスのうち、レイテンシーが最も高い上位 4 件の依存関係のグラフも表示されます。p99、p90、p50 の各レイテンシーメトリクスを使用すると、次のように、どの依存関係がサービス全体のレイテンシーの一因になっているかをすばやく評価できます。

例えば、上記のグラフはカスタマーサービスの依存関係に対して行われたリクエストの 99% が完了までに約 4,950 ミリ秒かかっていることを示しています。他の依存関係はそこまで時間がかかっていません。
上位 4 つのサービスオペレーションをレイテンシー別に示したグラフでは、次のイメージのように、サービスごとにリクエスト量、可用性、障害率、エラー率が表示されます。
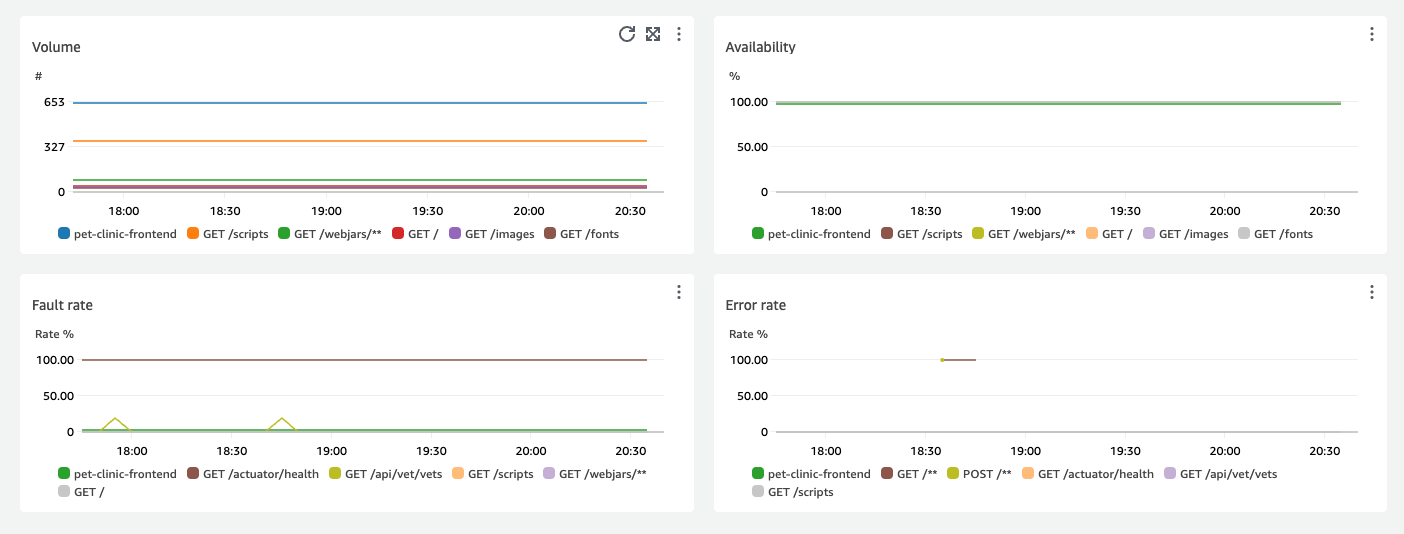
[サービスの詳細] セクションには、[アカウント ID] と [アカウントラベル] を含むサービスの詳細が表示されます。
サービスオペレーションを表示する
アプリケーションを計測すると、Application Signals は、アプリケーションが呼び出したすべてのサービスオペレーションを検出します。[サービスオペレーション] タブは、サービスオペレーションを含むテーブルと、選択したオペレーションのパフォーマンスを測定する、一連のメトリクスを表示するときに使用します。このメトリクスには、次に示すように、SLI のステータス、依存関係の数、レイテンシー、ボリューム、可用性が含まれています。
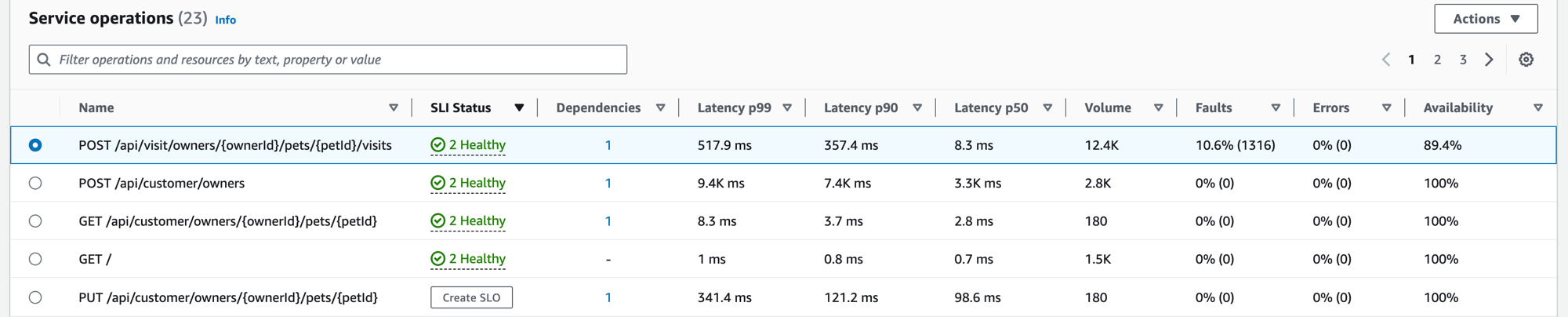
フィルターテキストボックスから 1 つまたは複数のプロパティを選択してテーブルをフィルタリングすると、サービスオペレーションが見つけやすくなります。各プロパティを選択すると、フィルター条件が表示され、フィルターテキストボックスの下にフィルター全体が表示されます。[フィルターのクリア] を選択すると、いつでもテーブルのフィルターを削除できます。
オペレーションの SLI ステータスを選択すると、次のテーブルに示すように、異常な SLI へのリンクと、そのオペレーションのすべての SLO を確認するためのリンクがポップアップに表示されます。
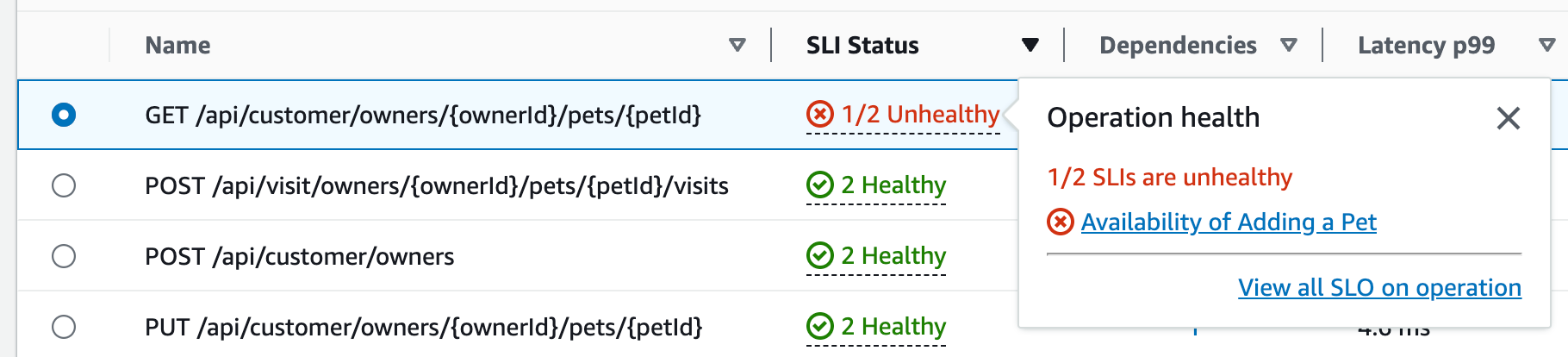
サービスオペレーションテーブルには、SLI のステータス、正常または異常な SLI の数、各オペレーションの SLO の合計数、が一覧表示されます。
SLI は、サービスの運用状態を測定するレイテンシー、可用性、その他運用メトリクスをモニタリングするために使用されます。SLO は、サービスとオペレーションのパフォーマンスと運用状態をチェックするために使用されます。
SLO を作成するには、次の手順を実行します。
-
オペレーションに SLO がない場合は、[SLI ステータス] 列で [SLO の作成] をクリックします。
-
オペレーションに既に SLO がある場合は、次の手順を実行します。
-
オペレーション名の横にあるラジオボタンをクリックします。
-
テーブルの右上にある[アクション] の下矢印から [SLO の作成] を選択します。
-
詳細については、「サービスレベル目標 (SLO)」を参照してください。
[依存関係] 列には、このオペレーションが呼び出す依存関係の数が表示されます。この数を選択すると、選択したオペレーションにフィルタリングされた [依存関係] タブが開きます。
サービスオペレーションのメトリクス、相関トレース、およびアプリケーションログの表示
Application Signals は、サービスオペレーションメトリクスを AWS X-Ray トレース、CloudWatch Container Insights、アプリケーションログに関連付けます。これらのメトリクスを使用して、運用状態の問題をトラブルシューティングします。メトリクスをグラフで表示するには、次の手順を実行します。
-
[サービスオペレーション] のテーブルでサービスオペレーションを選択すると、[ボリュームと可用性]、[レイテンシー]、[障害とエラー] のメトリクスを示すテーブルの上に、選択したオペレーションの一連のグラフが表示されます
-
グラフ内のポイントにカーソルを合わせると、詳しい情報が表示されます。
-
グラフでポイントを選択すると、そのポイントの相関トレース、メトリクス、アプリケーションログを示す診断ペインが開きます。
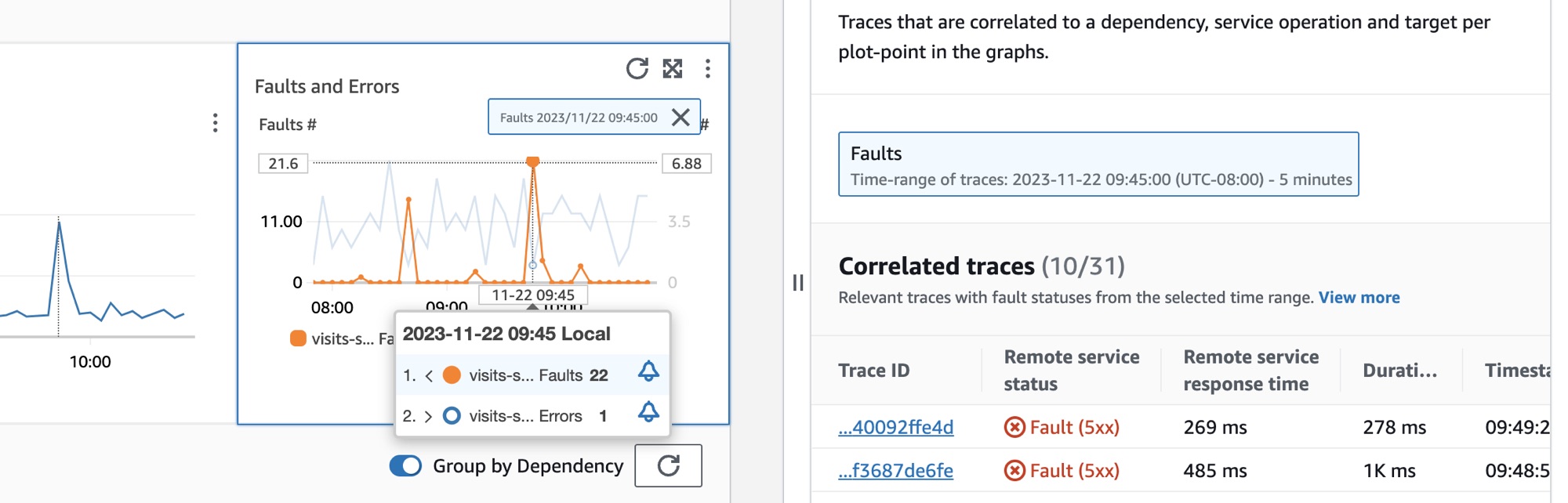
次のイメージに示すように、グラフ内のポイントにカーソルを合わせるとツールヒントが表示され、ポイントをクリックすると診断ペインが表示されます。ツールヒントでは、[障害とエラー] グラフ内の対応するデータポイントに関する情報を確認できます。このペインには、選択されているポイントに関連する [相関トレース]、[上位の寄与要因]、[アプリケーションログ] が表示されます。
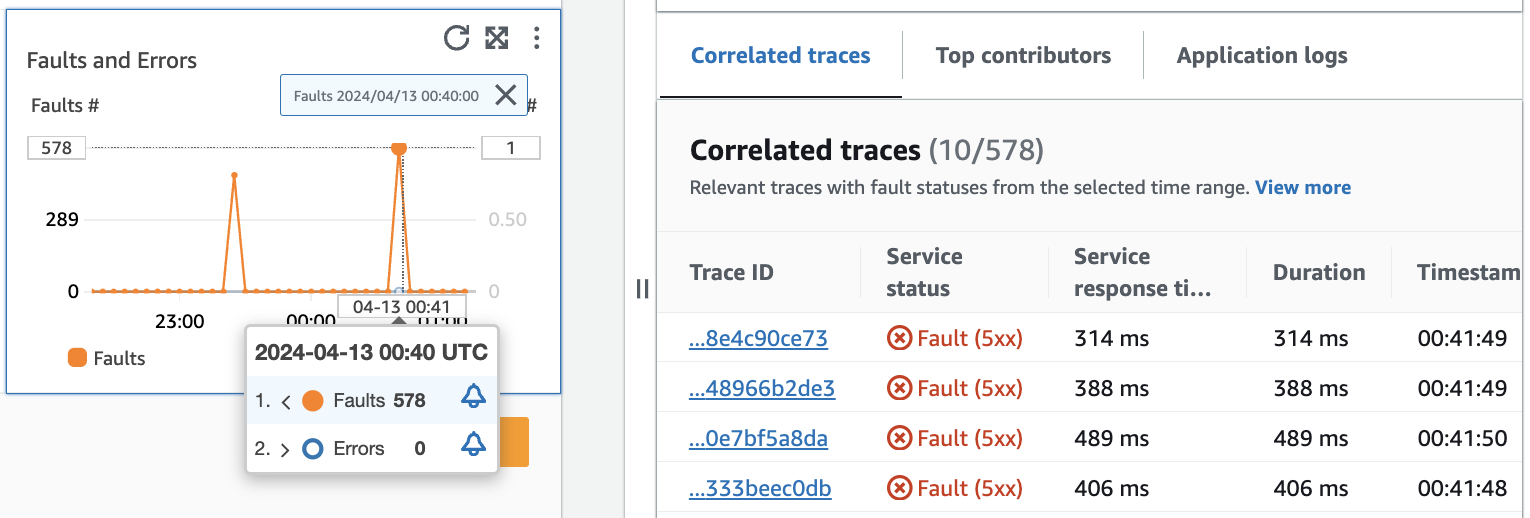
相関トレース
トレースの根本的な問題を理解するには、関連するトレースを確認します。相関するトレース、またはそれらに関連付けられたサービスノードが、類似した動作をしているかどうかを確認できます。相関するトレースを調べるには、[相関するトレース] のテーブルで [トレース ID] を選択し、選択したトレースの [X-Ray トレースの詳細] ページを開きます。このトレース詳細ページには、選択されているトレースに関連するサービスノードのマップと、トレースセグメントのタイムラインが表示されます。
トップコントリビューター
上位の寄稿者を表示して、メトリクスへの主要な入力ソースを特定します。寄稿者を、さまざまなコンポーネントごとにグループ化して、グループ内の類似点を特定し、トレース間での動作の違いを見きわめます。
[上位の寄稿者] タブに、各グループの [呼び出し量]、[可用性]、[平均レイテンシー]、[エラー]、[障害] のメトリクスが表示されます。次の例には、Amazon EKS プラットフォームにデプロイされたアプリケーションの、一連のメトリクスの上位の寄稿者が示されています。
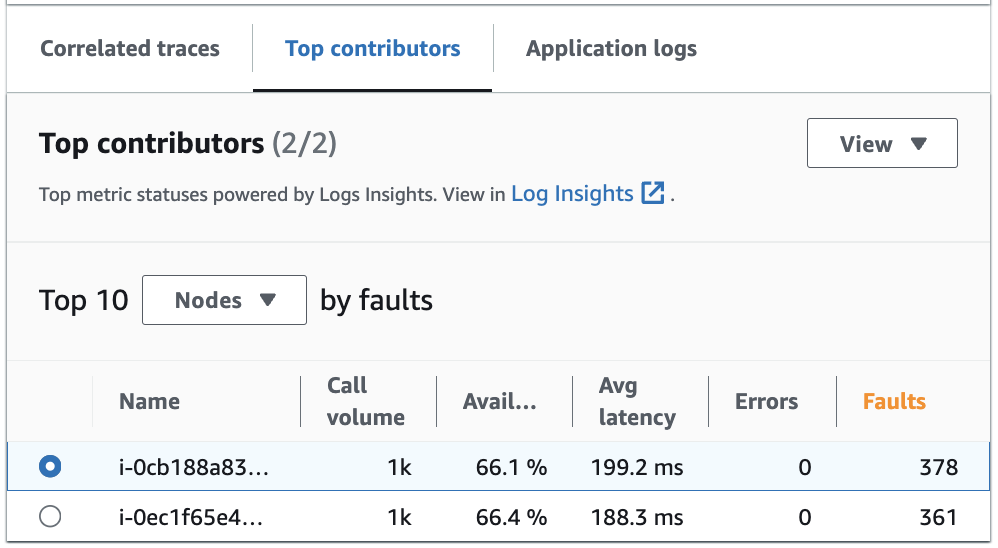
上位の寄稿者には、次のメトリクスが含まれています。
-
[呼び出し量] - 呼び出し量は、特定グループの、時間間隔あたりのリクエスト数を理解するときに使用します。
-
[可用性] - 可用性は、特定のグループで、障害が検出されなかった時間の割合を把握するときに使用します。
-
[平均レイテンシー] - レイテンシーは、調査対象のリクエストが実行された時期に応じて、特定のグループに対して特定の期間実行されたリクエストの、平均時間を確認するときに使用します。15 日以上前に行われたリクエストは、1 分間隔で評価されます。15~30 日前に行われたリクエストは、5 分間隔で評価されます。例えば、15 日前に障害の原因となったリクエストを調査している場合、呼び出し量メトリクスは 5 分間隔あたりのリクエスト数と等しくなります。
-
[エラー] - 特定の時間間隔で測定されたグループあたりのエラーの数。
-
[障害] - 特定の時間間隔におけるグループあたりの障害の数。
Amazon EKS または Kubernetes を使用している上位の寄稿者
Amazon EKS または Kubernetes にデプロイされたアプリケーションの、上位の寄稿者の情報を使用して、[ノード]、[ポッド]、[PodTemplateHash] でグループ化された運用状態のメトリクスを確認します。各要因の定義は次のとおりです。
-
ポッドは、ストレージとリソースを共有する 1 つ以上の Docker コンテナから成るグループです。Kubernetes プラットフォームにデプロイできる最小単位がポッドです。ポッド別にグループ化すると、エラーがポッド固有の制限に関連しているかどうかを確認できます。
-
ノードは、ポッドを実行するサーバーです。ノード別にグループ化すると、エラーがノード固有の制限に関連しているかどうかを確認できます。
-
ポッドテンプレートハッシュは、特定のバージョンのデプロイを検出するために使用します。ポッドテンプレートハッシュでグループ化すると、エラーが特定のデプロイに関連しているかどうかを確認できます。
Amazon EC2 を使用している上位の寄稿者
Amazon EKS にデプロイされたアプリケーションの、上位の寄稿者の情報を使用して、[インスタンス ID] および [Auto Scaling グループ] でグループ化された運用状態のメトリクスを確認します。各要因の定義は次のとおりです。
-
インスタンス ID は、サービスが実行されている Amazon EC2 インスタンスの一意の識別子です。インスタンス ID でグループ化すると、エラーが特定の Amazon EC2 インスタンスに関連しているかどうかを確認できます。
-
Auto Scaling グループは、アプリケーションのリクエストに応える必要があるリソースをスケールアップするかスケールダウンする際に使用できる Amazon EC2 インスタンスの集まりです。必要に応じて Auto Scaling グループでグループ化すると、エラーの範囲がグループ内のインスタンスに限定されているかどうかを確認できます。
カスタムプラットフォームを使用している上位の寄稿者
カスタム計測を使用してデプロイされたアプリケーションの、上位の寄稿者の情報を使用して、[ホスト名] でグループ化された運用状態のメトリクスを確認します。各要因の定義は次のとおりです。
-
ホスト名は、ネットワークに接続されているエンドポイントや Amazon EC2 インスタンスなどのデバイスを識別するものです。ホスト名でグループ化すると、エラーが特定の物理デバイスまたは仮想デバイスに関連しているかどうかを確認できます。
Log Insights および Container Insights で上位の寄稿者を表示する
Log Insights で、上位の寄稿者に関するメトリクスを生成する自動クエリを表示し、修正します。Container Insights で、インフラストラクチャのパフォーマンスメトリクスを、ポッドやノードなど特定のグループごとに表示します。クラスター、ノード、またはワークロードをリソース消費量別にソートして、エンドユーザーエクスペリエンスが影響を受ける前に異常をすばやく特定したり、プロアクティブにリスクを軽減したりできます。次のイメージに、これらのオプションを選択する方法を示します。
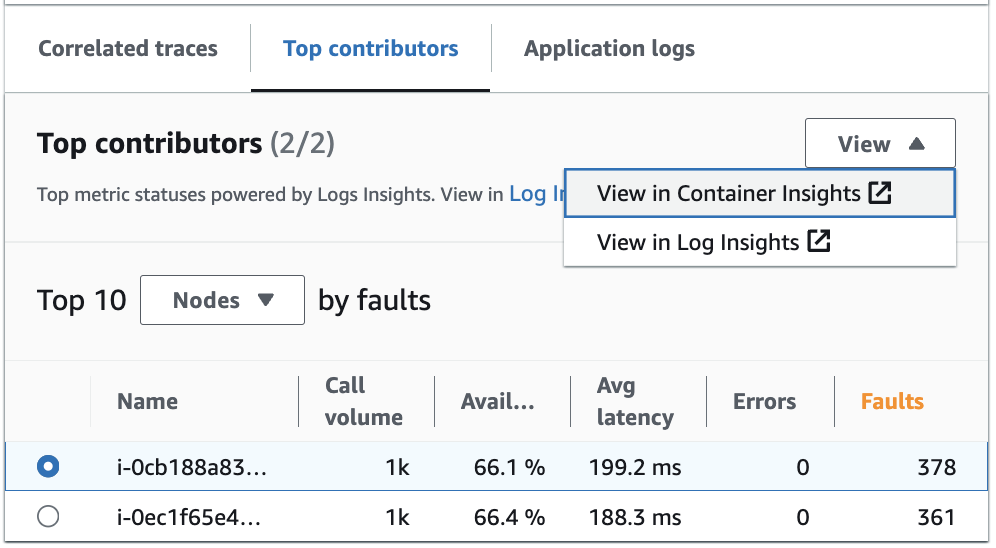
Container Insights では、Amazon EKS コンテナや Amazon ECS コンテナに関するメトリクスのうち、上位の寄与要因のグループ化に固有のものを表示できます。例えば、EKS コンテナをポッド別にグループ化して上位の寄与要因を生成した場合、Container Insights にはポッドでフィルタリングされたメトリクスと統計が表示されます。
Log Insights では、次の手順を使用して、[上位の寄与要因] にメトリクスを生成したクエリを変更できます。
-
[Log Insights に表示] を選択します。[Log Insights] ページが開いて、自動的に生成されたクエリが表示されます。次の情報が含まれています。
-
ログクラスターグループ名。
-
CloudWatch で調査していたオペレーション。
-
グラフで操作したオペレーションヘルスメトリクスの集計。
ログ結果は自動的にフィルタリングされて、サービスグラフ上のデータポイントを選択するまでの過去 5 分間のデータが表示されます。
-
-
クエリを編集するには、生成されたテキストを変更後の内容に置き換えます。また、クエリジェネレーターを使用して、新しいクエリを生成したり、既存のクエリを更新したりすることもできます。
アプリケーションログ
[アプリケーションログ] タブのクエリを使用して、現在のロググループ、サービスに関するログ情報を生成し、タイムスタンプを挿入します。ロググループは、アプリケーションを設定する際に定義できるログストリームのグループです。
ロググループを使用して、次のような特性を持つログを整理します。
-
特定の組織、ソース、機能からログをキャプチャします。
-
特定のユーザーがアクセスするログをキャプチャします。
-
特定の期間のログをキャプチャします。
これらのログストリームを使用して、特定のグループまたは時間枠を追跡します。これらのロググループのモニタリングルール、アラーム、通知を設定することもできます。ロググループの詳細については、「ロググループとログストリームを操作」を参照してください。
アプリケーションログクエリは、ログ、繰り返し発生するテキストパターン、およびグラフィカルに可視化したロググループを返します。
クエリを実行するには、[Logs Insights でクエリを実行] を選択して、自動生成されたクエリを実行するか、クエリを変更します。クエリを編集するには、自動生成されたテキストを変更後の内容に置き換えます。また、クエリジェネレーターを使用して、新しいクエリを生成したり、既存のクエリを更新したりすることもできます。
次のイメージに、サービスオペレーショングラフで選択されているポイントに基づいて自動的に生成されたサンプルのクエリを示します。
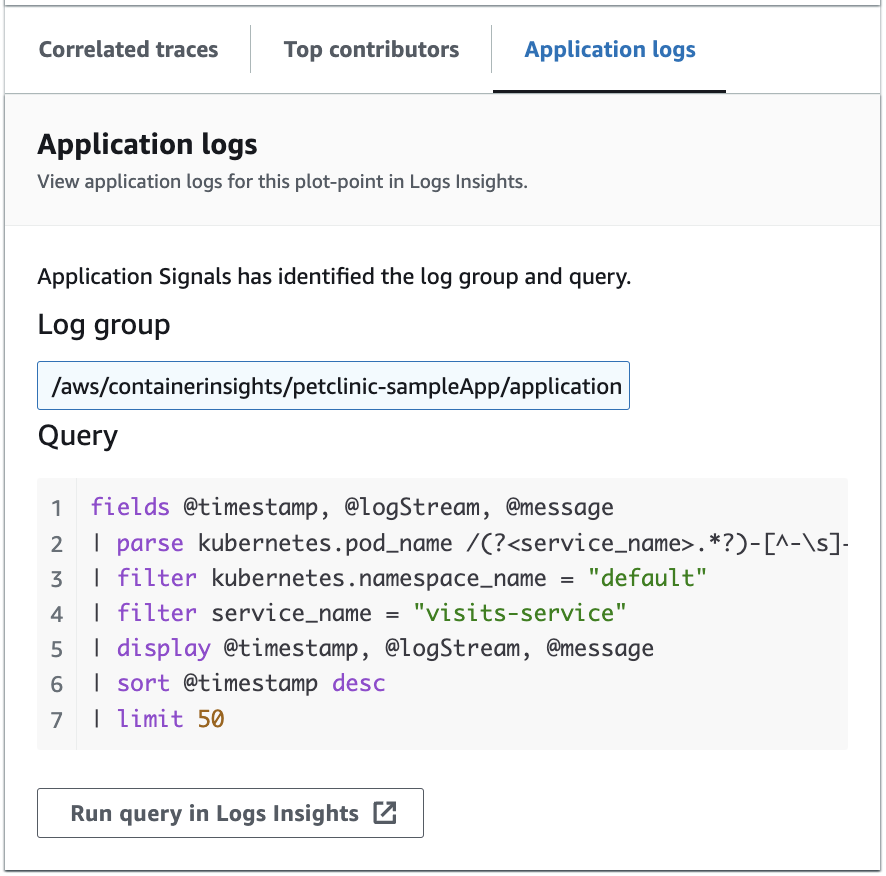
前のイメージでは、CloudWatch は選択されたポイントに関連付けられているロググループを自動的に検出して、生成されたクエリに含めていました。
サービスの依存関係を表示する
[依存関係] タブを選択すると、[依存関係] テーブルと、すべてのサービスオペレーションまたは 1 つのオペレーションの依存関係に関する一連のメトリクスが表示されます。このテーブルには、SLI ステータス、レイテンシー、コール量、障害率、エラー率、可用性のメトリクスなど、Application Signals によって検出された依存関係のリストが含まれています。
ページ上部の下向き矢印のリストからオペレーションを選択して依存関係を表示するか、[すべて] を選択してすべてのオペレーションの依存関係を表示します。
フィルターテキストボックスから 1 つまたは複数のプロパティを選択して、テーブルをフィルタリングすると、探しているものを見つけやすくなります。各プロパティを選択すると、フィルター条件が表示され、フィルターテキストボックスの下にフィルター全体が表示されます。[フィルターのクリア] を選択すると、いつでもテーブルのフィルターを削除できます。テーブルの右上にある [依存関係別にグループ化] を選択すると、依存関係をサービスとオペレーション名でグループ化できます。グループ化がオンになっている場合は、依存関係名の横にある [+] アイコンを使用して、依存関係のグループを展開するか折りたたみます。

[依存関係] 列には依存関係サービス名が表示され、[リモートオペレーション] 列にはサービスオペレーション名が表示されます。[SLI ステータス] 列には、正常な SLI と異常な SLI の数、および各依存関係の SLI の合計数が表示されます。AWS のサービスを呼び出すと、[ターゲット] 列には DynamoDB のテーブルや Amazon SNS のキューといった AWS リソースが表示されます。
依存関係を選択するには、[依存関係] テーブルの依存関係の横にあるオプションを選択します。呼び出し量、可用性、障害、エラーに関する詳細なメトリクスを表示する一連のグラフが表示されます。グラフ内のポイントにカーソルを合わせると、ポップアップが開いて詳しい情報が表示されます。グラフ内のポイントを選択すると、診断ペインが開いて、グラフ内でのそのポイントの相関トレースが表示されます。[相関トレース] テーブルからトレース ID を選択して、選択したトレースの [X-Ray トレースの詳細] ページを開きます。
Synthetics Canary を表示する
[Synthetics Canary] タブを選択すると、[Synthetics Canary] テーブルが表示され、そのテーブルには一連のメトリクスが canary ごとに表示されます。このテーブルには、成功率、平均所要時間、実行、失敗率に関するメトリクスが含まれています。AWS X-Ray トレースが有効になっている Canary のみが表示されます。
Synthetics Canary テーブルのフィルターテキストボックスを使用して、関心のある Canary を見つけます。作成する各フィルターは、フィルターテキストボックスの下に表示されます。[フィルターのクリア] を選択すると、いつでもテーブルのフィルターを削除できます。
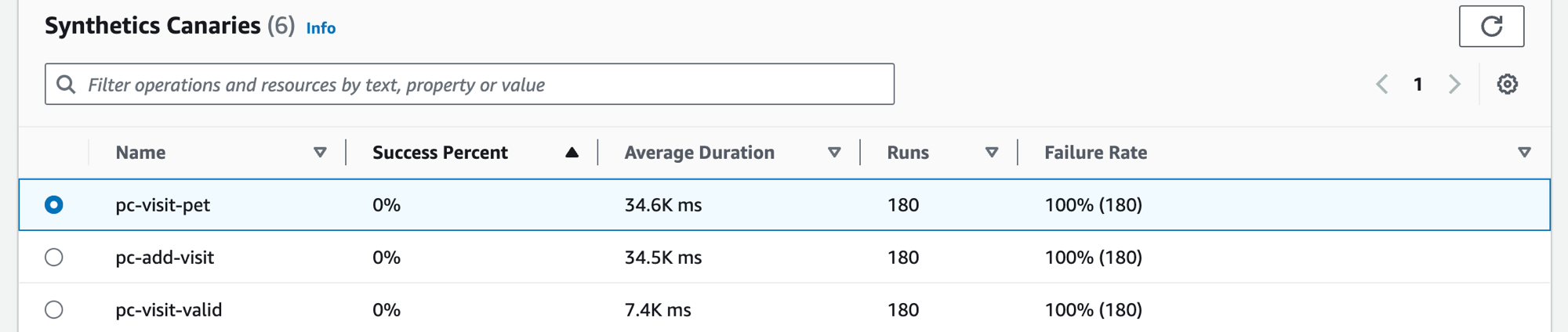
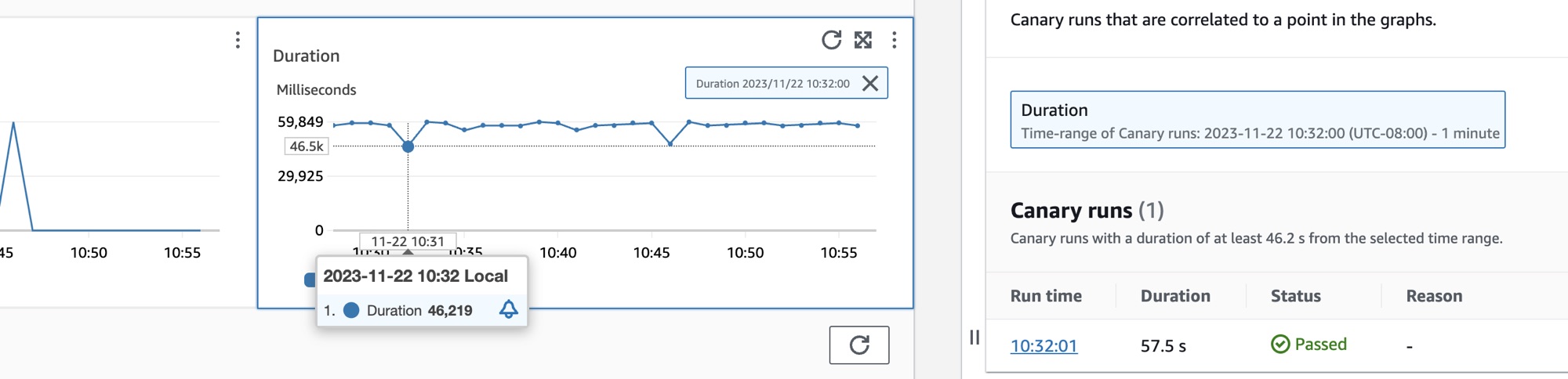
Canary の名前の横にあるラジオボタンをクリックすると、成功、エラー、期間など、グラフの詳細なメトリクスを含む一連のタブが表示されます。グラフ内のポイントにカーソルを合わせると、ポップアップが開いて詳しい情報が表示されます。グラフ内のポイントを選択すると、選択したポイントと相関する Canary 実行を示す、診断ペインが開きます。Canary 実行を選択して [ランタイム] をクリックすると、ログ、HTTP アーカイブ (HAR) ファイル、スクリーンショット、問題のトラブルシューティングに役立つ推奨のステップなど、選択した Canary 実行のアーティファクトが表示されます。[詳細] をクリックして、[Canary 実行] の横にある [CloudWatch Synthetics Canary] のページを開きます。
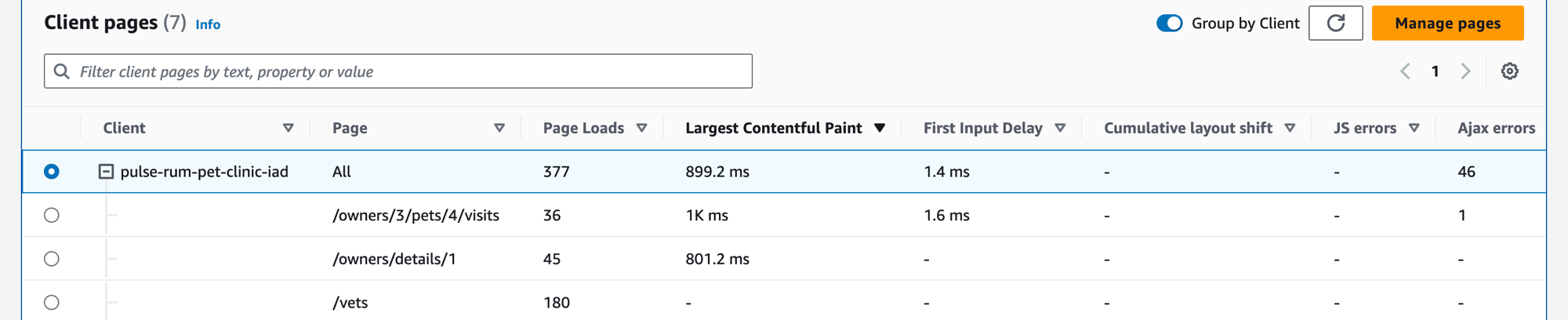
クライアントページを表示する
[クライアントページ] タブをクリックすると、サービスを呼び出すクライアントウェブページの一覧が表示されます。サービスまたはアプリケーションを操作する際のクライアントエクスペリエンスの質を測定するときは、選択したクライアントページの、一連のメトリクスを使用します。これらのメトリクスには、ページロード、ウェブバイタル、エラーなどが含まれます。
テーブルにクライアントページを表示するには、CloudWatch RUM ウェブクライアントを X-Ray トレースに設定し、クライアントページの Application Signals メトリクスをオンにします。[ページの管理] をクリックして、Application Signals メトリクスを有効にするページを選択します。
フィルターテキストボックスを使用して、フィルターテキストボックスの下で、関心のあるクライアントページまたはアプリケーションモニターを特定します。[フィルターのクリア] を選択すると、テーブルのフィルターを削除できます。[クライアント別にグループ化] を選択すると、クライアントページをクライアントごとにグループ化できます。グループ化したら、クライアント名の横にある [+] アイコンを選択して行を展開し、そのクライアントのすべてのページを表示します。
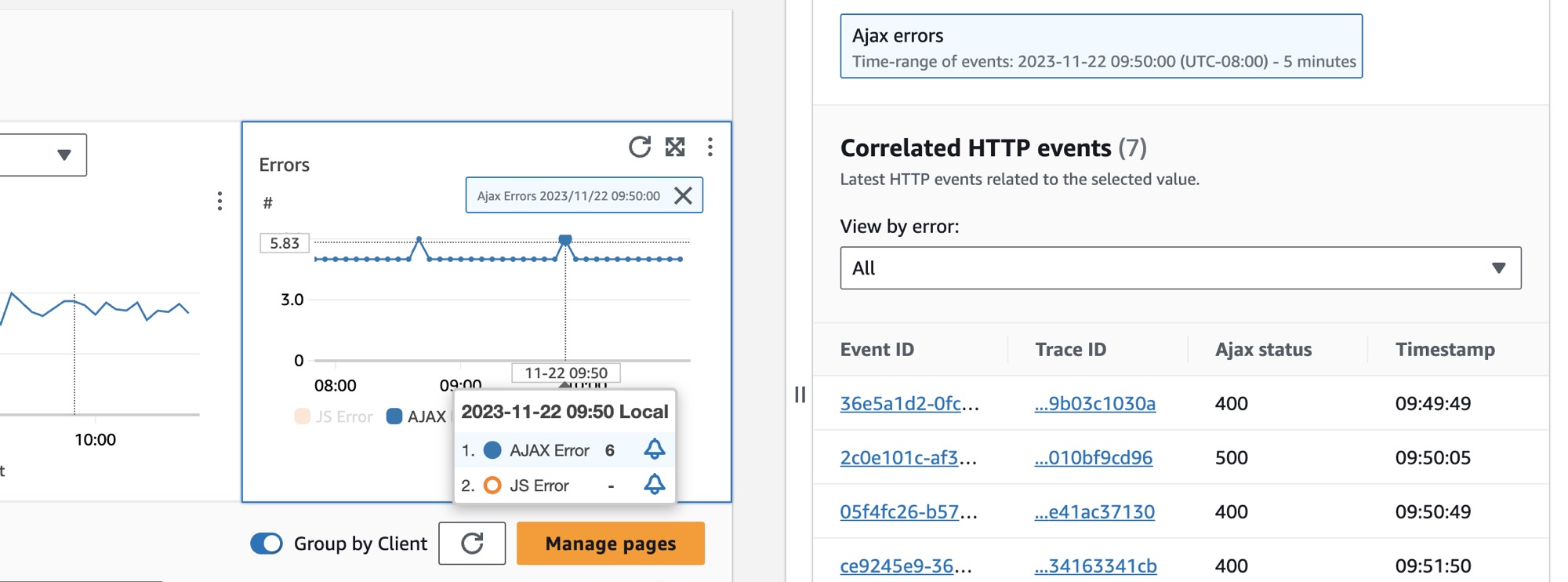
クライアントページを選択するには、[クライアントページ] テーブルのクライアントページの横にあるオプションを選択します。詳細なメトリクスを表示する一連のグラフが表示されます。グラフ内のポイントにカーソルを合わせると、ポップアップが開いて詳しい情報が表示されます。グラフ内のポイントを選択すると、そのグラフ内の選択したポイントの相関パフォーマンスナビゲーションイベントを示す診断ペインが開きます。ナビゲーションイベントのリストからイベント ID を選択し、選択したイベントの CloudWatch RUM ページビューを開きます。
注記
クライアントページ内の AJAX エラーを確認するには、CloudWatch RUM ウェブクライアントバージョン 1.15 以降を使用してください。
サービスごとに、最大 100 のオペレーション、Canary、クライアントページと、最大 250 の依存関係を表示できます。
関連メトリクスを表示する
[関連メトリクス] タブを使用して、複数のメトリクスを視覚化し、相関パターンを特定し、問題の根本原因を特定します。
メトリクステーブルには、以下の 3 種類のメトリクスが表示されます。
標準メトリクス - Application Signals では、検出したサービスから標準アプリケーションメトリクスを収集します。詳細については、「収集される標準アプリケーションメトリクス」を参照してください
ランタイムメトリクス - Application Signals は AWS Distro for OpenTelemetry SDK を使用し、Java および Python アプリケーションから OpenTelemetry 互換メトリクスを自動的に収集します。詳細については、「ランタイムメトリクス」を参照してください
カスタムメトリクス – Application Signals を使用すると、アプリケーションからカスタムメトリクスを生成できます。詳細については、Application Signals を使用したカスタムメトリクスを参照してください。
関連メトリクスタブには、[サービス概要]、[サービスオペレーション]、[依存関係]、[Synthetics Canary]、または [RUM] タブからアクセスできます。

-
左側のナビゲーションパネルは、すべてのオペレーションと依存関係が選択されていない状態で始まります
-
グラフには、最初に、障害率が最も高かったオペレーションの障害メトリクスが表示されます
相関関係の分析を開始する前に、サービスオペレーションまたは依存関係にデータポイントが表示されていることを確認してください。相関関係を分析するには:
[サービスオペレーション] または [依存関係] ページを開きます。
任意のグラフのデータポイントを選択します。
右側のパネルで、[他のメトリクスに相関] を選択します。
開いた [関連メトリクス] タブには、以下が表示されます。
左側のナビゲーションで選択したオペレーションまたは依存関係
[メトリクスの参照] テーブルでグラフ化された選択したメトリクス
データポイントを選択したときの相関スパン
複数のメトリクスをグラフ化するには、[関連メトリクス] タブの [参照] ビューから 1 つ以上のメトリクスを選択します。[グラフ化されたメトリクス] を選択して、グラフ化されたメトリクスをすべて表示します。
メトリクスをフィルタリングするには、左側のパネルフィルターを使用して特定のオペレーションまたは依存関係に焦点を当て、テーブルヘッダーフィルターバーを使用して名前、タイプ、またはその他の属性で検索します。これらのフィルタリングオプションは、パターンを検出し、問題をより効率的にトラブルシューティングするのに役立ちます。
関連するメトリクスを詳細に分析するには、[関連メトリクス] タブでデータポイントを選択します。その後、以下を表示できます。
Top Contributors – CloudWatch Logs Insights クエリを実行してメトリクスを分析します。これらのクエリは、以下の詳細分析のためのキー属性を含む拡張メトリクス形式 (EMF) レコードを処理します。
レイテンシー測定値
障害の発生
サービスの可用性メトリクス
以下のメトリクスは Top Contributors をサポートしていません。
OTEL メトリクス
サーバー側のスパンメトリクス
RED メトリクスとクライアント側のスパンメトリクスの Top Contributors を表示できます。
相関スパン – 相関スパンセクションは、[サービスオペレーション] タブと一貫して動作します。関連するトレースとメトリクスを識別しやすくするために、相関メカニズムは以下によって機能します。
メトリクス名とスパン属性の比較
選択した期間中に一致するパターンの特定
関連するトレース情報の表示
メトリクスとスパンを効果的に分析するには、さまざまなメトリクスタイプがどのように相関するかを理解する必要があります。主な制限事項は以下のとおりです。
OTEL メトリクスは独立した命名システムを使用しているため、スパンと相関しません
サーバーまたはクライアント側のスパンメトリクスをスパンと関連付けるには:
設定に Service ディメンションフィールドを含める
この Service ディメンションがないと、これらのメトリクスをスパンと関連付けることはできません
ログアプリケーション – ログアプリケーションの詳細については、「サービスオペレーションを表示する」を参照してください。
