サービスレベル目標 (SLO)
Application Signals を使用すると、重要なビジネスオペレーションまたは依存関係のサービス向けのサービスレベル目標を作成できます。こうしたサービスに SLO を作成したら、SLO ダッシュボードでそれらを追跡できる上、最も重要なオペレーションをひとめで確認することも可能です。
また、重要なオペレーションの現在のステータスを表示できるようオペレーター向けにクイックビューを作成するだけでなく、SLO を使用してサービスの長期的なパフォーマンスを追跡したり、サービスが想定どおりに提供されているかどうかを確認したりすることも可能です。顧客とサービスレベル契約を結んでいる場合、SLO はそれを確実に満たす手段と言えるでしょう。
SLO を使用してサービスの正常性を評価するには、まず、主要なパフォーマンス指標 (サービスレベル指標 (SLI)) に基づいて、明確で測定可能な目標を設定します。SLO を導入すると、設定したしきい値と目標に照らして SLI パフォーマンスを追跡すると同時に、アプリケーションのパフォーマンス値としきい値との差がどの程度開いているかを報告できます。
Application Signals を使用すると、主要なパフォーマンス指標に SLO を設定できます。Application Signals では、検出したすべてのサービスとオペレーションについて Latency と Availability のメトリクスを自動的に収集します。多くの場合、こうしたメトリクスは、SLI としての使用に理想的であり、SLO 作成ウィザードに従うことで独自の SLO に利用できます。その後、Application Signals ダッシュボードから、全 SLO のステータスを追跡することが可能です。
SLO は、サービスで呼び出したり使用したりする特定のオペレーションまたは依存関係に設定できます。また、Latency と Availability のメトリクスの他に、任意の CloudWatch メトリクスまたはメトリクス式を SLI として使用することも可能です。
CloudWatch Application Signals を最大限に活用するには、SLO の作成が非常に重要です。SLO を作成すると、Application Signals コンソールで重要なサービスやオペレーションのステータスを確認し、パフォーマンスが良いものや動作が異常なものを特定できます。SLO の追跡により、次のような大きな利点を得られます。
SLI に照らして測定している重要なサービスについて、オペレーションの現在の正常性を簡単に確認できるため、問題のあるサービスやオペレーションを迅速に優先順位付けし、特定することが可能です。
サービスのパフォーマンスを、測定可能なビジネス目標に照らして長期的に追跡できます。
SLO の設定対象を選択することで情報の重要度を指定でき、Application Signals ダッシュボードには重要度が高いと見なした情報が自動的に表示されます。
SLO の作成時には、CloudWatch アラームを作成して、SLO をモニタリングすることも可能です。しきい値越えや警告レベルをモニタリングするようアラームを設定できます。こうしたアラームによって、SLO メトリクスが設定したしきい値を超えたり、警告のしきい値に近づいたりした場合に自動的に通知を受けられます。例えば、SLO の値が警告のしきい値に近づくと通知が届くため、長期的なパフォーマンス目標を達成するには、そのアプリケーションでのチャーン抑制が必要であると気付くことができます。
トピック
SLO の概念
SLO の構成要素を次に示します。
サービスレベル指標 (SLI): 指定対象のパフォーマンスメトリクスであり、アプリケーションに必要なパフォーマンスレベルを表します。Application Signals では、検出したサービスとオペレーションについて、主要なメトリクスである
LatencyとAvailabilityを自動的に収集します。これらは、SLO の設定に理想的なメトリクスとなることが少なくありません。SLI には、使用するしきい値を選択します。例えば、レイテンシーには 200 ミリ秒などと指定します。
目標または達成度目標: 時間間隔のそれぞれで SLI のしきい値を満たすことが求められる時間の長さまたはリクエストをパーセンテージで示した値です。この間隔には、数時間のように短い期間や、1 年のように長い期間を設定できます。
カレンダー間隔とローリング間隔のいずれも設定可能です。
カレンダー間隔: カレンダーに従った間隔であり、1 か月ごとに追跡する SLO などがこれに該当します。CloudWatch では、1 か月の日数に基づいて、正常性、予算、達成度の数値を自動的に調整します。カレンダー間隔は、カレンダーに沿って測定するビジネス目標に適しています。
ローリング間隔: ローリングベースで測定を行います。この間隔は、アプリケーションで最近提供されたユーザーエクスペリエンスの追跡に適しています。
期間: 短い時間を意味し、間隔は、多数の期間がつながったものと言えます。間隔内の各期間でアプリケーションのパフォーマンスを SLI と比較し、期間ごとに、必要なアプリケーションパフォーマンスが達成されたかどうかを判断します。
例えば、99% という目標で、カレンダー間隔に 1 日、期間に 1 分が指定されている場合、その日のアプリケーションのパフォーマンスは、1 分の 99% に相当する期間、成功のしきい値に達していなければなりません。達していれば、その日の SLO を満たしたことになります。翌日は新規の評価間隔と見なされ、2 日目の SLO を満たすには、2 日目における 1 分の 99% に相当する期間、成功のしきい値に達していることが求められます。
SLI には、Application Signals で収集した新規の標準アプリケーションメトリクスの 1 つ、あるいは、任意の CloudWatch メトリクスまたはメトリクス式を使用できます。標準アプリケーションメトリクスとして SLI に使用できるのは、Latency と Availability です。Availability は、成功の応答をリクエストの合計で割った数値で表し、(1 - 障害率)*100 のように計算します。ここでの Fault 応答数は 5xx エラーの件数を意味し、成功の応答とは 5XX エラーのない応答を指します。4XX 応答は成功の応答と見なされます。
1 回のオペレーションまたはサービスのすべてのオペレーションで SLO を作成できるほか、サービスのオペレーションのサブセットをモニタリングする複合 SLO を作成することもできます。複合 SLO は、複数のオペレーションにまたがる Availability メトリクスを集約し、関連するオペレーション群の信頼性を統合的に把握できるようにします。2~20 個のオペレーションを選択して、複合 SLO に含めることができます。詳細については、「複数のオペレーションで複合 SLO を作成する」を参照してください。
期間ベースの SLO のエラーバジェットと達成度の計算
SLO の情報を表示すると、SLO の現在の正常性とその「エラーバジェット」を確認できます。エラーバジェットとは、対象の間隔内で、しきい値を超えても SLO を満たすことのできる時間の長さを意味し、「総エラーバジェット」は、対象の間隔全体で違反が許容される時間を合計したものです。「残りのエラーバジェット」は、現在の間隔内で許容される残りの違反時間であり、総エラーバジェットから既に発生した違反時間を差し引いた値で表します。
次の図は、間隔が 30 日、期間が 1 分、達成度目標が 99% の目標について、達成度とエラーバジェットの概念を示しています。30 日を分数で表すと 43,200 分であり、43,200 の 99% は 42,768 であるため、SLO を満たすには、当月のうち 42,768 分は正常性を確保しなければなりません。現在の間隔では、異常な期間 (1 分間) がこれまでに 130 回ありました。
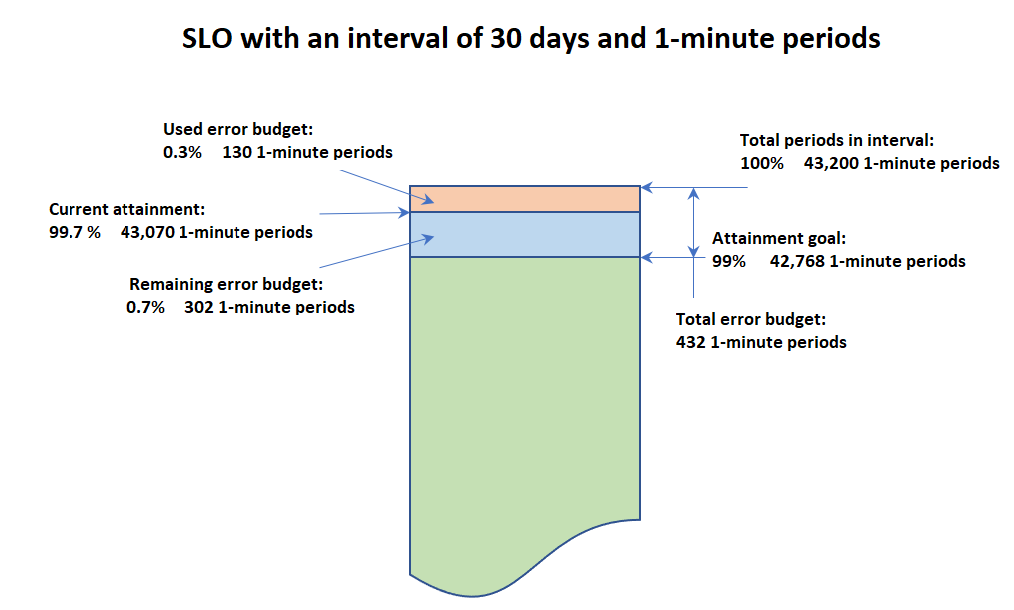
SLO の達成状況を各期間内で判断する
SLI データは、各期間内で SLI に使用する統計に基づいて 1 つのデータポイントに集計され、このデータポイントが期間全体の長さを表すことになります。その 1 つのデータポイントが SLI のしきい値と比較され、その期間の正常性が判断されます。現在の時間範囲内で異常な期間をダッシュボードで確認できるため、サービスの優先順位付けが必要な状況にすぐに気付くことが可能です。
異常と判断された期間は、エラーバジェット上、その期間全体が違反期間としてカウントされます。エラーバジェットの追跡により、対象のサービスが必要なパフォーマンスを長期的に達成しているかどうかを把握できます。
時間枠の除外
時間枠の除外は、定義済みの開始日と終了日がある時間ブロックです。この期間は SLO のパフォーマンスメトリクスから除外され、1 回限りまたは定期的な除外枠をスケジュールできます。例えば、スケジュールされたメンテナンスなどが例として挙げられます。
注記
期間ベースの SLO の場合、除外枠内の SLI データは違反していないものと見なされます。
リクエストベースの SLO の場合、除外枠内のすべての良いリクエストと悪いリクエストは除外されます。
リクエストベースの SLO の間隔が完全に除外されると、デフォルトの達成率メトリクスである 100% が発行されます。
指定できるのは将来の開始日がある時間枠のみです。
リクエストベースの SLO のエラーバジェットと達成度の計算
SLO を作成したら、SLO のエラーバジェットレポートを取得できます。エラーバジェットとは、アプリケーションが SLO の目標に準拠しないことが許容され、アプリケーションがまだ目標を達成することができるリクエストの量です。リクエストベースの SLO の場合、残りのエラーバジェットは動的であり、リクエストの総数に対する正常なリクエストの比率に応じて増減することがあります。
次の表は、5 日間隔で達成目標 85% のリクエストベースの SLO の計算を示しています。この例で、1 日目より前のトラフィックはないと仮定します。SLO は 10 日目に目標を達成しませんでした。
注記
リクエストベースの SLO、TotalRequestCountPerMinute、BadRequestCountPerMinute は、期間ベースの SLO メトリクスと対照的に、追加のメトリクスとして出力されます。これらのメトリクスはオブザーバビリティの目的で提供され、達成率の計算への入力としては使用されません。
これらのメトリクスは定期的に評価されるメトリクスデータから生成されるため、メトリクスの発行タイミングや遅延により、それらの値が予想されるリクエスト数と異なる場合があります。このような不一致は、SLO 達成度計算には影響しません。1 分あたりに出力されるこれらのメトリクスとは独立して計算されるためです。
| Time | Total requests | 不良リクエスト | 過去 5 日間のリクエストの累積合計数 | 過去 5 日間の正常なリクエストの累積合計数 | リクエストベースの達成度 | バジェットリクエストの合計 | 残りのバジェットリクエスト |
|---|---|---|---|---|---|---|---|
|
1 日目 |
10 | 1 |
10 |
9 |
9/10 = 90% |
1.5 |
0.5 |
|
2 日目 |
5 |
1 |
15 |
13 |
13/15=86% |
2.3 |
0.3 |
|
3 日目 |
1 |
1 |
16 |
13 |
13/16=81% |
2.4 |
-0.6 |
|
4 日目 |
24 |
0 |
40 |
37 |
37/40=92% |
6.0 |
3.0 |
|
5 日目 |
20 |
5 |
60 |
52 |
52/60=87% |
9.0 |
1.0 |
|
6 日目 |
6 |
2 |
56 |
47 |
47/56=84% |
8.4 |
-0.6 |
|
7 日目 |
10 |
3 |
61 |
50 |
50/61=82% |
9.2 |
-1.8 |
|
8 日目 |
15 |
6 |
75 |
59 |
59/75=79% |
11.3 |
-4.7 |
| 9 日目 |
12 |
1 |
63 |
46 |
46/63=73% |
9.5 |
-7.5 |
|
10 日目 |
5 |
57 |
40 |
40/57=70% |
8.5 |
-8.5 | |
|
過去 5 日間の最終達成度 |
|
70% |
バーンレートを計算し、オプションでバーンレートアラームを設定する
Application Signals を使用して、サービスレベル目標のバーンレートを計算できます。バーンレートは、SLO の達成目標と比較して、サービスがエラーバジェットをどれだけ速く消費しているかを示すメトリクスです。これはベースラインエラー率の倍数として表されます。
バーンレートは、達成目標に応じてベースラインエラー率に従って計算されます。達成目標は、SLO 目標を達成するために到達する必要がある正常な期間または成功したリクエストの割合です。ベースラインのエラー率は (100% - 達成目標の割合) であり、この数値は SLO の時間間隔の終了時に正確な完全なエラーバジェットを使い果たすことになります。したがって、達成目標が 99% の SLO のベースラインエラー率は 1% になります。
バーンレートをモニタリングすると、ベースラインエラー率からどれだけ乖離しているかがわかります。ここでも、達成目標の 99% を例にとると、次のことが当てはまります。
バーンレート = 1: バーンレートが常にベースラインのエラー率のままである場合、SLO の目標を正確に満たします。
バーンレート < 1: バーンレートがベースラインエラー率より低い場合、SLO 目標を超える見込みです。
バーンレート > 1: バーンレートがベースラインエラー率よりも高い場合、SLO 目標を達成できない可能性があります。
SLO のバーンレートを設定する際、同時に CloudWatch アラームを設定して、そのバーンレートをモニタリングすることもできます。バーンレートのしきい値を設定すると、バーンレートメトリクスが設定したしきい値を超えた場合にアラームが自動的に通知されます。例えば、バーンレートがしきい値に近づくと、SLO のエラー予算がチームの許容できる速度よりも早く消費されていることがわかります。そのため、長期的なパフォーマンス目標を達成するために、アプリケーションの変更ペースを落とす必要があるかもしれません。
アラームの作成には料金がかかります。CloudWatch の料金の詳細については、「Amazon CloudWatch の料金
バーンレートを計算する
バーンレートを計算するには、ルックバックウィンドウを指定する必要があります。ルックバックウィンドウは、エラー率を測定する期間です。
burn rate = error rate over the look-back window / (100% - attainment goal)
注記
バーンレート期間にデータがない場合、Application Signals は達成度に基づいてバーンレートを計算します。
エラー率は、バーンレート期間中のイベントの合計数に対する不良イベントの数の比率として計算されます。
期間ベースの SLO の場合、エラー率は不良期間を総期間で割って計算されます。総期間は、ルックバックウィンドウの期間全体を表します。
リクエストベースの SLO の場合、これは不正なリクエストの数を総リクエストの数で割った値です。リクエストの合計数は、ルックバックウィンドウ中のリクエストの数です。
ルックバックウィンドウは SLO 期間時間の倍数で、SLO 間隔より短くする必要があります。
バーンレートアラームの適切なしきい値を決定する
バーンレートアラームを設定する際、アラームしきい値としてバーンレート値を選択してください。このしきい値は、SLO 間隔の長さとルックバックウィンドウ、およびチームが採用する方法またはメンタルモデルによって異なります。しきい値を決定するには、主に 2 つの方法があります。
方法 1: チームがルックバックウィンドウ内で許容できる推定総エラーバジェットの割合を決定します。
推定エラーバジェットの X% が最後のバーンレートのルックバック時間内に費やされたときにアラームが発生する場合、バーンレートのしきい値は次のとおりです。
burn rate threshold = X% * SLO interval length / look-back window size
例えば、1 時間にわたって消費される 30 日 (720 時間) のエラーバジェットの 5% には、5% * 720 / 1 = 36 のバーンレートが必要です。したがって、バーンレートのルックバックウィンドウが 1 時間の場合、バーンレートのしきい値を 36 に設定します。
CloudWatch コンソールでこの方法を使用してバーンレートアラームを作成できます。数値 X を指定すると、しきい値が上記の式を基に決まります。
SLO 間隔の長さは、SLO 間隔タイプに基づいて決まります。
ローリング間隔の SLO の場合、間隔の長さは時間単位です。
カレンダーベース間隔の SLO の場合:
単位が日または週の場合、間隔の長さは時間単位です。
単位が 1 か月の場合、推定期間として 30 日かかり、それを時間に変換します。
方法 2: 次の間隔の時間単位バジェットが使い果たされるまでの時間を算出する
最新のルックバックウィンドウの現在のエラーレートが、(バジェットの残りが現在 100% であると仮定して) バジェットが使い果たされるまでの時間が X 時間未満であることを示す場合にアラームを通知するには、次の式を使用してバーンレートのしきい値を決定できます。
burn rate threshold = SLO interval length / X
上記の式のバジェットを使い果たすまでの時間 (X) は、現在残っているバジェットの合計が 100% であると想定しているため、この間隔で既に消費されているバジェットの量は考慮されていません。また、次の間隔のバジェットを使い果たすまでの時間と考えることもできます。
バーンレートアラームのチュートリアル
例えば、28 日間のローリング間隔の SLO を考えてみます。この SLO のバーンレートアラームの設定するには、次の 2 つのステップが必要です。
バーンレートとルックバックウィンドウを設定します。
バーンレートをモニタリングする CloudWatch アラームを作成します。
開始するには、特定の時間枠内にサービスが消費する合計エラーバジェットの量を決定します。つまり、「合計エラーバジェットの X% が M 分以内に消費されたときにアラートを受け取りたい。」という文を使用して、目標を記述します。
例えば、60 分以内に合計エラーバジェットの 2% が消費されると、目標にアラートが送信されるように設定することができます。
バーンレートを設定するには、まずルックバックウィンドウを定義します。ルックバックウィンドウは M で、この例では 60 分です。
次に、CloudWatch アラームを作成します。これには、バーンレートのしきい値を指定する必要があります。バーンレートがこのしきい値を超えると、アラームが通知されます。しきい値を検索するには、次の式を使用します。
burn rate threshold = X% * SLO interval length/ look-back window size
この例では、エラーバジェットの 2% が 60 分以内に消費された場合にアラートを受け取るため、X は 2 になります。間隔の長さは 40,320 分 (28 日) で、60 分はルックバックウィンドウであるため、答えは次のとおりです。
burn rate threshold = 2% * 40,320 / 60 = 13.44.
この例では、アラームしきい値として 13.44 を設定します。
異なるウィンドウを持つ複数のアラーム
複数のルックバックウィンドウにアラームを設定することで、短いウィンドウの急激なエラー率の上昇を早期に検知し、また、小さなエラー率の上昇が長期的に蓄積されてエラーバジェットを枯渇させるのを防ぐことができます。
さらに、複合アラームをロングウィンドウのバーンレートとショートウィンドウのバーンレート (ロングウィンドウの 1/12) に設定し、両方のバーンレートがしきい値を超えた場合にのみ通知を受け取ることができます。これにより、現在も発生している状況についてのみアラートを受け取ることができます。CloudWatch 複合アラームの詳細については、「アラームの組み合わせ」を参照してください。
注記
バーンレートを作成するときに、バーンレートにメトリクスアラームを設定できます。複数のバーンレートアラームに複合アラームを設定するには、「アラームの組み合わせ」の手順に従う必要があります。
Google Site Reliability Engineering ワークブック
1 時間のウィンドウと 5 分のウィンドウが設定された 2 つのアラームをモニタリングする、複合アラーム。
6 時間と 30 分のウィンドウが設定された 2 つのアラームをモニタリングする、2 つ目の複合アラーム。
3 日ウィンドウと 6 時間ウィンドウが設定された 2 つのアラームをモニタリングする 3 つ目の複合アラーム。
この設定の手順は次のとおりです。
-
5 分、30 分、1 時間、6 時間、3 日間のウィンドウを使用して、5 つのバーンレートを作成します。
次の 3 つの CloudWatch アラームペアを作成します。各ペアには、ロングウィンドウとロングウィンドウの 12 分の 1 のショートウィンドウが含まれ、しきい値は バーンレートアラームの適切なしきい値を決定する の手順を使用して決定されます。ペア内の各アラームのしきい値を計算するときは、計算にペアの長いルックバックウィンドウを使用します。
1 時間および 5 分のバーンレートのアラーム (しきい値はバジェット全体の 2% で設定)
6 時間および 30 分のバーンレートのアラーム (しきい値はバジェット全体の 5% で設定)
3 日および 6 時間のバーンレートのアラーム (しきい値はバジェット全体の 10% で設定)
これらのペアごとに複合アラームを作成し、両方のアラームが ALARM 状態になるとアラートを受け取ります。複合アラームの作成の詳細については、「アラームの組み合わせ」を参照してください。
例えば、最初のペア (1 時間のウィンドウと 5 分のウィンドウ) のアラームに
OneHourBurnRateとFiveMinuteBurnRateという名前が付けられている場合、CloudWatch 複合アラームルールはALARM(OneHourBurnRate) AND ALARM(FiveMinuteBurnRate)になります。
前の戦略は、間隔の長さが 3 時間以上の SLO でのみ可能です。間隔の長さが短い SLO では、1 つのアラームのルックバックウィンドウが他のアラームのルックバックウィンドウの 1/12 であるバーンレートアラームのペアから開始することをお勧めします。次に、このペアに複合アラームを設定します。
SLO を作成する
重要なアプリケーションにはレイテンシーと可用性の両方の SLO を設定することをお勧めします。Application Signals で収集するこれらのメトリクスは一般的なビジネス目標として使用できます。
また、任意の CloudWatch メトリクスや、1 つの時系列となるメトリクス数学式に SLO を設定することもできます。
アカウントに SLO を初めて作成したときに CloudWatch がアカウントに AWSServiceRoleForCloudWatchApplicationSignals サービスにリンクされたロールをまだ作成していない場合は自動的に作成します。このサービスにリンクされたロールにより、CloudWatch は CloudWatch Logs データ、X-Ray トレースデータ、CloudWatch メトリクスデータ、タグ付けデータをアカウントのアプリケーションから収集できるようになります。CloudWatch サービスにリンクされたロールの詳細については、「CloudWatch のサービスにリンクされたロールの使用」を参照してください。
SLO を作成するときは、期間ベースの SLO かリクエストベースの SLO かを指定します。SLO の各タイプでは、達成目標に対してアプリケーションのパフォーマンスを評価する方法が異なります。
期間ベースの SLO では、指定された合計時間間隔内の定義された期間を使用します。Application Signals は、期間ごとに、アプリケーションが目標を達成したかどうかを判定します。達成率は、
number of good periods/number of total periodsとして計算されます。例えば、期間ベースの SLO の場合、99.9% の達成目標を達成するということは、時間間隔内で、アプリケーションが期間の少なくとも 99.9% でパフォーマンス目標を達成する必要があることを意味します。
リクエストベースの SLO では、事前定義された期間を使用しません。その代わりに、SLO は間隔中の
number of good requests/number of total requestsを測定します。任意の時点で、指定したタイムスタンプまでの間隔のリクエストの総数に対する正常なリクエストの比率を確認し、SLO で設定された目標に対するその比率を測定できます。
期間ベースの SLO の作成
以下の手順に従って、期間ベースの SLO を作成します。
期間ベースの SLO を作成するには
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
[SLO の作成] を選択します。
[サービスレベルインジケータ (SLI) の設定] では、次のいずれかの操作を行います。
サービスのオペレーション単位、すべてのオペレーション、またはサービスの依存関係に SLO を設定するには、標準アプリケーションメトリクスの
LatencyまたはAvailabilityのいずれかを使用します。[タイプ] には [サービス] を選択します。
この SLO がモニタリングするアカウントを選択します。
この SLO でモニタリングするサービスを選択します。
[タイプ] には、以下のいずれかを選択します。
[サービスオペレーション] — サービスオペレーション、すべてのオペレーション、またはオペレーションのサブセットに対して SLO を作成します。
[サービス依存関係] — サービスの依存関係に基づいて SLO を作成します。
[サービスオペレーション] を選択した場合は、この SLO がモニタリングするオペレーションを選択します。すべてのオペレーションでサービスの全体的な状態をモニタリングするサービスレベルの SLO を作成するには、すべてのオペレーションを選択します。それ以外の場合は、モニタリングする特定のオペレーションを選択します。
オペレーションのサブセットをモニタリングする SLO を作成するには、「複数のオペレーションで複合 SLO を作成する」を参照してください。
[サービス依存関係] を選択した場合は、以下の操作を実行します。
[オペレーションの選択] で特定のオペレーションを 1 つ選択するか、[すべてのオペレーション] を選択して、依存関係を呼び出すこのサービスのすべてのオペレーションのメトリクスを使用します。
[依存関係を選択] で、信頼性を測定するために必要な依存関係を検索して選択できます。
依存関係を選択すると、依存関係に基づいて更新されたグラフと履歴データを表示できます。
[計算方法の選択] で、[期間] を選択します。
[サービスの選択] と [オペレーションの選択] ドロップダウンには、過去 24 時間以内にアクティブになったサービスとオペレーションが表示されます。
[可用性] または [レイテンシー] を選択して、しきい値を設定します。
任意の CloudWatch メトリクス、または CloudWatch メトリクスの数式に SLO を設定するには:
[タイプ] で [CloudWatch Metric] を選択します。
[CloudWatch メトリクスの選択] を選択します。
[メトリクスの選択] 画面が表示されます。[ブラウズ] タブまたは [クエリ] タブを使用して、対象のメトリクスを検索するか、メトリクスの数式を作成します。
対象のメトリクスを選択したら、[グラフ化したメトリクス] タブを選択し、SLO に使用する [統計] と [期間] を選択します。次に [Select metric] (メトリクスの選択) を選択します。
これらの画面の詳細については、「メトリクスをグラフ化する」と「CloudWatch グラフに数式を追加する」を参照してください。
[計算方法の選択] で、[期間] を選択します。
[条件の設定] では、SLO で成功の指標として使用する比較演算子としきい値を選択します。
ステップ 4 で [サービス] を選択した場合、この SLO の期間の長さを設定します。
SLO の名前を入力します。サービスやオペレーションの名前と、レイテンシーや可用性といった適切なキーワードを含めると、優先順位付けの対象となっている SLO のステータスを簡単に特定できます。
SLO の [間隔] と [達成度目標] を設定します。間隔と達成度目標、およびこれら 2 つの関連性については、「SLO の概念」を参照してください。
(オプション) SLO バーンレートを設定するには、以下を実行します。
バーンレートのルックバックウィンドウの長さ (分単位) を設定します。この長さの選択方法については、「バーンレートアラームのチュートリアル」を参照してください。
この SLO のバーンレートをさらに作成するには、[さらにバーンレートを追加] を選択し、追加のバーンレートのルックバックウィンドウを設定します。
(オプション) 以下を実行して、バーンレートアラームを作成します。
[バーンレートアラームの設定] で、アラームを作成する各バーンレートのチェックボックスをオンにします。これらの各アラームに対して以下の操作を行います。
アラームが ALARM 状態になったときの通知に使用する Amazon SNS トピックを指定します。
バーンレートのしきい値を設定するか、直近のルックバックウィンドウに消費したバジェットが総バジェットの何パーセント以下に収まるかを指定します。推定総バーンバジェットの割合を設定すると、バーンレートのしきい値が計算され、アラームで使用されます。設定するしきい値を決定するか、このオプションを使用してバーンレートしきい値を計算する方法を理解するには、「バーンレートアラームの適切なしきい値を決定する」を参照してください。
(オプション) SLO に CloudWatch のアラームまたは警告上のしきい値を 1 つ以上設定します。
CloudWatch アラームを使用すると、SLI のパフォーマンスに基づいてアプリケーションの異常を判断し、Amazon SNS による通知をプロアクティブに受けることができます。
アラームを作成するには、アラームのチェックボックスの 1 つを選択し、アラームが
ALARM状態になった旨の通知に使用する Amazon SNS トピックを入力または作成します。CloudWatch アラームの詳細については、「Amazon CloudWatch でのアラームの使用」を参照してください。アラームの作成には料金がかかります。CloudWatch の料金の詳細については、「Amazon CloudWatch の料金」をご覧ください。 警告のしきい値を設定すると、Application Signals の画面にその値が表示されるため、現在正常値であっても達成が難しくなりそうな SLO を特定できます。
警告しきい値を設定するには、[警告しきい値] にしきい値を入力します。SLO のエラーバジェットが警告しきい値を下回ると、複数の Application Signals 画面でその SLO に [警告] のマークが付きます。警告しきい値は、エラーバジェットのグラフにも表示でき、警告しきい値に基づいて [SLO 警告アラーム] を作成することも可能です。
(オプション) [Set SLO time window exclusion] で、以下を実行します。
[Exclude time window] で、SLO パフォーマンスメトリクスから除外する時間枠を設定します。
[Set time window] を選択して 1 時間または 1 か月単位で開始ウィンドウを入力するか、[Set time window with CRON] を選択して CRON 式を入力できます。
[繰り返し] で、この時間枠の除外が繰り返し発生するかどうかを設定します。
(オプション) [Add reason] で、時間枠の除外理由を入力できます。例えば、スケジュールされたメンテナンスなどを入力します。
[時間枠を追加] を選択して、最大 10 個の除外時間枠を追加します。
この SLO にタグを追加するには、[タグ] タブを選択し、[新規タグの追加] を選択します。タグは、 リソースの管理、識別、整理、検索、フィルタリングに役立ちます。タグ付けの詳細については、「AWS リソースのタグ付け」を参照してください。
注記
この SLO に関連するアプリケーションが AWS Service Catalog AppRegistry に登録されている場合は、
awsApplicationタグを使用することで、その SLO を AppRegistry 内の対象アプリケーションに関連付けることができます。詳細については、「What is AppRegistry?」を参照してください。[SLO の作成] を選択します。1 つ以上のアラームを作成すると、それに応じてボタン名が変更されます。
リクエストベースの SLO の作成
以下の手順に従って、リクエストベースの SLO を作成します。
リクエストベースの SLO を作成するには
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
[SLO の作成] を選択します。
[サービスレベルインジケータ (SLI) の設定] では、次のいずれかの操作を行います。
サービスのオペレーション単位、すべてのオペレーション、またはサービスの依存関係に SLO を設定するには、標準アプリケーションメトリクスの
LatencyまたはAvailabilityのいずれかを使用します。[タイプ] には [サービス] を選択します。
この SLO でモニタリングするサービスを選択します。
[タイプ] には、以下のいずれかを選択します。
[サービスオペレーション] — サービスオペレーション、すべてのオペレーション、またはオペレーションのサブセットに対して SLO を作成します。
[サービス依存関係] — サービスの依存関係に基づいて SLO を作成します。
[サービスオペレーション] を選択した場合は、この SLO がモニタリングするオペレーションを選択します。すべてのオペレーションでサービスの全体的な状態をモニタリングするサービスレベルの SLO を作成するには、すべてのオペレーションを選択します。それ以外の場合は、モニタリングする特定のオペレーションを選択します。
オペレーションのサブセットをモニタリングする SLO を作成するには、「複数のオペレーションで複合 SLO を作成する」を参照してください。
[サービス依存関係] を選択した場合は、以下の操作を実行します。
[オペレーションの選択] で特定のオペレーションを 1 つ選択するか、[すべてのオペレーション] を選択して、依存関係を呼び出すこのサービスのすべてのオペレーションのメトリクスを使用します。
[依存関係を選択] で、信頼性を測定するために必要な依存関係を検索して選択できます。
依存関係を選択すると、依存関係に基づいて更新されたグラフと履歴データを表示できます。
[計算方法の選択] で、[リクエスト] を選択します。
-
[サービスの選択] と [オペレーションの選択] ドロップダウンには、過去 24 時間以内にアクティブになったサービスとオペレーションが表示されます。
[可用性] または [レイテンシー] を選択します。[レイテンシー] を選択した場合は、しきい値を設定します。
任意の CloudWatch メトリクス、または CloudWatch メトリクスの数式に SLO を設定するには:
[タイプ] で [CloudWatch Metric] を選択します。
-
[ターゲットリクエストの定義] では、以下の操作を実行します。
[正常なリクエスト] と [不正なリクエスト] のどちらを測定するかを選択します。
-
[CloudWatch メトリクスの選択] を選択します。このメトリクスは、リクエストの総数に対するターゲットリクエストの比率の分子になります。レイテンシーメトリクスを使用する場合は、トリミング数 (TC) の統計を使用します。しきい値が 9 ミリ秒で、より小さい (<) 比較演算子を使用している場合は、しきい値 TC (:threshold - 1) を使用します。TC の詳細については、「構文」を参照してください。
[メトリクスの選択] 画面が表示されます。[ブラウズ] タブまたは [クエリ] タブを使用して、対象のメトリクスを検索するか、メトリクスの数式を作成します。
-
[リクエスト総数の定義] で、ソースに使用する CloudWatch メトリクスを選択します。このメトリクスは、リクエストの総数に対するターゲットリクエストの比率の分母になります。
[メトリクスの選択] 画面が表示されます。[ブラウズ] タブまたは [クエリ] タブを使用して、対象のメトリクスを検索するか、メトリクスの数式を作成します。
対象のメトリクスを選択したら、[グラフ化したメトリクス] タブを選択し、SLO に使用する [統計] と [期間] を選択します。次に [Select metric] (メトリクスの選択) を選択します。
リクエストごとに 1 つのデータポイントを出力するレイテンシーメトリクスを使用する場合は、[サンプル数統計] を使用してリクエストの総数をカウントします。
これらの画面の詳細については、「メトリクスをグラフ化する」と「CloudWatch グラフに数式を追加する」を参照してください。
SLO の名前を入力します。サービスやオペレーションの名前と、レイテンシーや可用性といった適切なキーワードを含めると、優先順位付けの対象となっている SLO のステータスを簡単に特定できます。
SLO の [間隔] と [達成度目標] を設定します。間隔と達成度目標、およびこれら 2 つの関連性については、「SLO の概念」を参照してください。
(オプション) SLO バーンレートを設定するには、以下を実行します。
バーンレートのルックバックウィンドウの長さ (分単位) を設定します。この長さの選択方法については、「バーンレートアラームのチュートリアル」を参照してください。
この SLO のバーンレートをさらに作成するには、[さらにバーンレートを追加] を選択し、追加のバーンレートのルックバックウィンドウを設定します。
(オプション) 以下を実行して、バーンレートアラームを作成します。
[バーンレートアラームの設定] で、アラームを作成する各バーンレートのチェックボックスをオンにします。これらの各アラームに対して以下の操作を行います。
アラームが ALARM 状態になったときの通知に使用する Amazon SNS トピックを指定します。
バーンレートのしきい値を設定するか、直近のルックバックウィンドウに消費したバジェットが総バジェットの何パーセント以下に収まるかを指定します。推定総バーンバジェットの割合を設定すると、バーンレートのしきい値が計算され、アラームで使用されます。設定するしきい値を決定するか、このオプションを使用してバーンレートしきい値を計算する方法を理解するには、「バーンレートアラームの適切なしきい値を決定する」を参照してください。
(オプション) SLO に CloudWatch のアラームまたは警告上のしきい値を 1 つ以上設定します。
CloudWatch アラームを使用すると、SLI のパフォーマンスに基づいてアプリケーションの異常を判断し、Amazon SNS による通知をプロアクティブに受けることができます。
アラームを作成するには、アラームのチェックボックスの 1 つを選択し、アラームが
ALARM状態になった旨の通知に使用する Amazon SNS トピックを入力または作成します。CloudWatch アラームの詳細については、「Amazon CloudWatch でのアラームの使用」を参照してください。アラームの作成には料金がかかります。CloudWatch の料金の詳細については、「Amazon CloudWatch の料金」をご覧ください。 警告のしきい値を設定すると、Application Signals の画面にその値が表示されるため、現在正常値であっても達成が難しくなりそうな SLO を特定できます。
警告しきい値を設定するには、[警告しきい値] にしきい値を入力します。SLO のエラーバジェットが警告しきい値を下回ると、複数の Application Signals 画面でその SLO に [警告] のマークが付きます。警告しきい値は、エラーバジェットのグラフにも表示でき、警告しきい値に基づいて [SLO 警告アラーム] を作成することも可能です。
(オプション) [Set SLO time window exclusion] で、以下を実行します。
[Exclude time window] で、SLO パフォーマンスメトリクスから除外する時間枠を設定します。
[Set time window] を選択して 1 時間または 1 か月単位で開始ウィンドウを入力するか、[Set time window with CRON] を選択して CRON 式を入力できます。
[繰り返し] で、この時間枠の除外が繰り返し発生するかどうかを設定します。
(オプション) [Add reason] で、時間枠の除外理由を入力できます。例えば、スケジュールされたメンテナンスなどを入力します。
[時間枠を追加] を選択して、最大 10 個の除外時間枠を追加します。
この SLO にタグを追加するには、[タグ] タブを選択し、[新規タグの追加] を選択します。タグは、 リソースの管理、識別、整理、検索、フィルタリングに役立ちます。タグ付けの詳細については、「AWS リソースのタグ付け」を参照してください。
注記
この SLO に関連するアプリケーションが AWS Service Catalog AppRegistry に登録されている場合は、
awsApplicationタグを使用することで、その SLO を AppRegistry 内の対象アプリケーションに関連付けることができます。詳細については、「What is AppRegistry?」を参照してください。[SLO の作成] を選択します。1 つ以上のアラームを作成すると、それに応じてボタン名が変更されます。
アプリモニターで SLO を作成する
SLO を作成して、CloudWatch RUM アプリモニターのパフォーマンスをモニタリングできます。これにより、実際のユーザーエクスペリエンスメトリクスを追跡し、ウェブおよびモバイルアプリケーションがパフォーマンス目標を満たすことができるようになります。アプリモニター上の SLO は、リクエストベースの評価を使用します。これは、正常なリクエストと合計リクエストの比率を測定します。
アプリモニターで SLO を作成するには
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
[SLO の作成] を選択します。
[サービスレベルインジケータ (SLI) の設定] では、RUM AppMonitor を選択します。
この SLO がモニタリングするアプリモニターをドロップダウンリストから選択します。このリストには、サポートされているプラットフォーム (ウェブ、iOS、または Android) とともにアプリモニター名が表示されます。
(オプション) モニタリングする特定のページまたは画面を選択します。ページを選択しない場合、SLO はアプリモニターのすべてのページをモニタリングします。
[メトリクスの選択] では、SLI に使用するメトリクスを選択します。使用可能なメトリクスはプラットフォームによって異なります:
ウェブアプリケーションでは:
PerformanceNavigationDuration、JSErrorCount、Http4xxCount、およびHttp5xxCountモバイルアプリケーション (iOS および Android) では:
ScreenLoadTime、CrashCount、Http4xxCount、およびHttp5xxCount
[条件の設定] では、SLO で成功の指標として使用する比較演算子としきい値を選択します。
SLO の名前を入力します。アプリモニター名と適切なキーワードを含めると、トリアージ中に SLO ステータスが示す内容をすばやく特定できます。
SLO の [間隔] と [達成度目標] を設定します。詳細については、「SLO の概念」を参照してください。
(オプション) 必要に応じてバーンレートとアラームを設定します。詳細については、「バーンレートを計算し、オプションでバーンレートアラームを設定する」を参照してください。
(オプション) 必要に応じて時間枠の除外を設定します。
(オプション) この SLO の整理と識別に役立つタグを追加します。
[SLO の作成] を選択します。
Canary で SLO を作成する
SLO を作成して、CloudWatch Synthetics Canary のパフォーマンスをモニタリングできます。これにより、合成モニタリング結果を追跡し、エンドポイントと API が可用性とパフォーマンスの目標を満たすことができるようになります。Canary 上の SLO は期間ベースの評価を使用し、各 Canary 実行は個別の評価期間として扱われます。
Canary で SLO を作成するには
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
[SLO の作成] を選択します。
[サービスレベルインジケータ (SLI) の設定] では、Synthetics Canary を選択します。
この SLO がモニタリングする Canary をドロップダウンリストから選択します。
[メトリクスの選択] では、
SuccessPercentまたはDurationを選択します:SuccessPercentは、成功した Canary 実行の割合を測定しますDurationは、各 Canary 実行の完了にかかる時間を測定します
[条件の設定] では、SLO で成功の指標として使用する比較演算子としきい値を選択します。
SLO の名前を入力します。Canary 名と適切なキーワードを含めると、トリアージ中に SLO ステータスが示す内容をすばやく特定できます。
SLO の [間隔] と [達成度目標] を設定します。詳細については、「SLO の概念」を参照してください。
(オプション) 必要に応じてバーンレートとアラームを設定します。詳細については、「バーンレートを計算し、オプションでバーンレートアラームを設定する」を参照してください。
(オプション) 必要に応じて時間枠の除外を設定します。
(オプション) この SLO の整理と識別に役立つタグを追加します。
[SLO の作成] を選択します。
複数のオペレーションで複合 SLO を作成する
サービスのオペレーションのサブセット全体にわたって Availability メトリクスをモニタリングする複合 SLO を作成できます。これは、単一のオペレーションやすべてのオペレーションをモニタリングするのではなく、関連するオペレーションのグループの信頼性をまとめて追跡する場合に便利です。
複合 SLO は、期間ベースとリクエストベースの評価の両方をサポートします。含めるオペレーションは 2~20 個から選択できます。オペレーションを選択する方法は 2 つあります。
[明示的な選択] — ドロップダウンから個々のオペレーションを手動で選択します。
[パターンマッチング] — プレフィックスまたは正規表現でオペレーションを使用して、オペレーションの名前を自動的に一致させます。
注記
複合 SLO は Availability メトリクスのみをサポートします。Latency メトリクスでは複合 SLO は使用できません。
複合 SLO を作成するには
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
[SLO の作成] を選択します。
[サービスレベルインジケータ (SLI) の設定] で、[タイプ] として [サービス] を選択します。
この SLO でモニタリングするサービスを選択します。
[タイプ] で、[サービスオペレーション] を選択します。
この複合 SLO に含めるオペレーションを選択します。次のいずれかを行います。
オペレーションを手動で選択するには、[オペレーション] ドロップダウンから複数の [オペレーション] を選択します。2~20 個のオペレーションを選択できます。
選択したオペレーションは、ドロップダウンの下にトークンとして表示されます。オペレーションを削除するには、そのトークンにある削除アイコンを選択します。
パターンでオペレーションを選択するには、[パターンマッチングを使用する] チェックボックスをオンにします。次に、以下の操作を実行します。
[パターンタイプ] で、[プレフィックス] または [正規表現] を選択します。
[プレフィックス] は、入力したテキストで始まるすべてのオペレーション名と一致します。例えば、「
Invoke」と入力すると、「InvokeFunction」,「InvokeAsync」などの名前のオペレーションに一致します。[正規表現] は、入力した正規表現パターンと一致する名前を持つすべてのオペレーションに一致します。例えば、
^Invoke.*と入力すると、プレフィックスの例と同じオペレーションと一致します。
パターンフィールドに [パターン] を入力します。コンソールでは、一致したオペレーションがフィールドの下にトークンとして表示されるため、結果を確認できます。
オペレーションを選択すると、メトリクスは自動的に [可用性] に設定されます。
[計算方法の選択] で、[期間] または [リクエスト] のいずれかを選択します。
[期間] を選択した場合は、この SLO の期間の長さと可用性のしきい値を設定します。
SLO の名前を入力するか、自動生成された名前を使用します。自動生成された名前には、サービス名と「複合」という単語が含まれており、識別しやすくなっています。
SLO の [間隔] と [達成度目標] を設定します。間隔と達成度目標、およびこれら 2 つの関連性については、「SLO の概念」を参照してください。
(オプション) 必要に応じてバーンレートとアラームを設定します。詳細については、「バーンレートを計算し、オプションでバーンレートアラームを設定する」を参照してください。
(オプション) SLO に CloudWatch のアラームまたは警告上のしきい値を 1 つ以上設定します。
(オプション) 必要に応じて時間枠の除外を設定します。
(オプション) この SLO の整理と識別に役立つタグを追加します。
[SLO の作成] を選択します。
SLO の推奨事項を使用する
Application Signals は、過去 30 日間の履歴メトリクスデータに基づいて SLO 設定の推奨事項を提供できます。サービスおよび作成する SLO のタイプに関する基本情報を提供すると、Application Signals はメトリクスデータを分析し、メトリクスのしきい値、SLO 目標、およびバーンレート枠の最適な値を提案します。
SLO の推奨事項を受け取るには、次の情報を提供する必要があります:
サービスオペレーションまたはサービス依存関係を選択します:
[サービスオペレーション] では、サービスとオペレーションを指定します
[サービス依存関係] では、サービス、オペレーション (またはすべてのオペレーション)、および依存関係を指定します
SLO 評価タイプ: 期間ベースまたはリクエストベース
標準アプリケーションメトリクスのタイプ:
LatencyまたはAvailability
この情報とサービスの履歴パフォーマンスデータに基づいて、Application Signals は次の SLO 設定パラメータを推奨します:
[メトリクスしきい値] - 過去 30 日間のサービスの実際のパフォーマンスに基づいて計算された SLI のパフォーマンスしきい値。
[SLO 目標] - サービスの過去の信頼性と一致する、推奨される達成目標の割合。
[バーンレート枠] - サービスがエラー予算をどれだけ速く消費するかをモニタリングするための推奨ルックバック枠期間。
推奨される値を受け入れることも、特定のビジネス要件に基づいて調整することもできます。推奨事項は、サービスの実際のパフォーマンス特性を反映する SLO を設定するためのデータ駆動型の出発点を提供します。
SLO ステータスの表示と優先順位付けを行う
CloudWatch コンソールの [サービスレベル目標] または [サービス] のオプションを使用すると、SLO の正常性をすぐに確認できます。[サービス] ビューでは、設定済み SLO を基に計算された異常なサービスの割合をひとめで把握できます。[サービス] オプションの使用については、「Application Signals を使用したアプリケーションの運用状態のモニタリング」で詳しく確認できます。
[サービスレベル目標] ビューでは、組織をマクロ的に確認できます。例えば、達成できている SLO と達成できていない SLO を全体的に把握することが可能です。これにより、期待どおりの成果を長期的に得られているサービスおよびオペレーションの数を、選択した SLI に基づいて確認できます。
[Service Level Objects] ビューですべての SLO を表示するには
-
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
[サービスレベル目標 (SLO)] リストが表示されます。
SLO の現在のステータスは [SLI ステータス] 列ですぐに確認できます。すべての異常な SLO がリストの一番上に表示されるように並べ替えるには、異常な SLO がすべて一番上になるまで [SLI ステータス] 列を選択します。
SLO テーブルには次のようなデフォルトの列があります。表示する列を調整するには、リストの上にある歯車アイコンを選択してください。目標、SLI、達成度、間隔の詳細については、「SLO の概念」を参照してください。
SLO の名前。
[目標] 列には、各間隔における期間の割合が表示されます。この割合を SLO 目標の SLI しきい値に照らして達成しなければなりません。この列には、SLO の間隔の長さも表示されます。
[SLI ステータス] には、アプリケーションの現在のオペレーション状態が正常かどうかが表示されます。現在選択している時間範囲内のいずれかの期間で SLO 違反が生じた場合、[SLI ステータス] に [異常] と表示されます。
この SLO が依存関係をモニタリングするように設定されている場合、[依存関係] 列と [リモートオペレーション] 列に、その依存関係の詳細が表示されます。
[終了時の達成度] は、選択した時間範囲の終了時点で達成したレベルを表します。この列を基準にして並べ替えると、達成できない可能性が最も高い SLO を確認できます。
[達成度差] は、選択した時間範囲の開始時と終了時における達成レベルの差であり、これがマイナスの場合、メトリクスが下降傾向にあることを示しています。この列を基準にして並べ替えると、最近の SLO の傾向を確認できます。
[終了時エラーバジェット (%)] は、異常な期間があっても SLO を達成したと見なされる期間の合計時間をパーセンテージで示した値です。これを 5% に設定した場合、SLI が異常であっても、その長さが間隔内の残りの期間で 5% 以下であれば SLO を達成したと見なされます。
[エラーバジェット差] は、選択した時間範囲の開始時と終了時におけるエラーバジェットの差であり、これがマイナスの場合、メトリクスが下降傾向にあることを示しています。
[終了時エラーバジェット (時間)] は、対象の間隔において、異常が発生しても SLO を達成したと見なされる時間の長さです。例えば、これが 14 分の場合、残りの間隔で SLI が異常な時間があっても、それが 14 分未満であれば、SLO を達成したと見なされます。
-
[終了時エラーバジェット (リクエスト)] は、対象の間隔において、異常が発生しても SLO を達成したと見なされるリクエストの量です。リクエストベースの SLO の場合、この値は動的であり、リクエストの累積合計数が時間の経過と共に変化すると変動することがあります。
[サービス]、[オペレーション]、[タイプ] 列には、この SLO が設定されているサービスとオペレーションの情報が表示されます。
SLO の達成度とエラーバジェットのグラフを表示するには、SLO 名の横にあるラジオボタンを選択します。
ページ上部に表示されるそれらのグラフで、[SLO の達成度] と [エラーバジェット] のステータスを確認でき、この SLO に関連する SLI メトリクスのグラフも表示することが可能です。
達成されていない SLO にさらに優先順位付けを行うには、その SLO に関連するサービス名、オペレーション名、または依存関係名を選択します。優先順位付けをさらに行える詳細ページが表示されます。詳細については、「サービスの詳細ページで詳細なサービスアクティビティとオペレーションヘルスを表示する」を参照してください。
そのページにあるチャートと表の時間範囲を変更するには、画面の上部近くで新しい時間範囲を選択します。
既存の SLO を編集する
既存の SLO を編集するには、次のステップに従います。SLO の編集で、変更できるのは、しきい値、間隔、達成度目標、タグのみです。それ以外のサービス、オペレーション、メトリクスなどを変更するには、既存の SLO を編集せず、SLO を新規作成します。
SLO で最も重要な要素 (期間やしきい値など) を変更すると、達成度や正常性に関する以前のデータポイントや評価がすべて無効になります。SLO は実質的に削除され、再作成されます。
注記
SLO を編集しても、その SLO に関連するアラームは、自動更新されません。SLO との同期を維持するには、アラームの更新が必要となる場合もあります。
既存の SLO を編集するには
-
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
編集する SLO の横にあるラジオボタンを選択し、[アクション]、[SLO の編集] を選択します。
変更後、[変更の保存] を選択します。
SLO を削除する
既存の SLO を削除するには、次のステップに従います。
注記
SLO を削除しても、その SLO に関連するアラームは、自動削除されないため、手動で削除する必要があります。詳細については、「アラームの管理」を参照してください。
SLO を削除するには
-
CloudWatch コンソールの https://console.aws.amazon.com/cloudwatch/
を開いてください。 ナビゲーションペインで、[サービスレベル目標 (SLO)] を選択します。
編集する SLO の横にあるラジオボタンを選択し、[アクション]、[SLO の削除] を選択します。
[確認] を選択してください。
