Aurora PostgreSQL で Amazon Aurora 機械学習を使用する
Aurora PostgreSQL DB クラスターで Amazon Aurora 機械学習を使用することで、必要に応じて Amazon Comprehend、Amazon SageMaker AI、または Amazon Bedrock を使用できます。これらのサービスが特定の機械学習のユースケースをサポートしています。
Aurora 機械学習は、特定の AWS リージョン と Aurora PostgreSQL の一部のバージョンでのみサポートされています。Aurora 機械学習を設定する前に、Aurora PostgreSQL で利用できるバージョンとリージョンを確認してください。詳細については、「Aurora PostgreSQL を使用した Aurora Machine Learning」を参照してください。
トピック
Aurora 機械学習 を Aurora PostgreSQL で使用するための要件
AWS 機械学習サービスは、お客様の本番環境で設定し、実行するマネージドサービスです。Aurora 機械学習は、Amazon Comprehend、SageMaker AI、および Amazon Bedrock の統合をサポートしています。Aurora PostgreSQL DB クラスターを設定して Aurora 機械学習を使用開始する前に、次の要件と前提条件を理解していることを確認してください。
Amazon Comprehend、SageMaker AI、および Amazon Bedrock のサービスは、お使いの Aurora PostgreSQL DB クラスターと同じ AWS リージョンで実行する必要があります。別のリージョンにある Aurora PostgreSQL DB クラスターから、Amazon Comprehend、SageMaker AI、または Amazon Bedrock サービスは使用できません。
Aurora PostgreSQL DB クラスターが、Amazon Comprehend や SageMaker AI サービスとは異なる Amazon VPC サービスに基づく仮想パブリッククラウド (VPC) にある場合、VPC のセキュリティグループが対象の Aurora 機械学習サービスへのアウトバウンド接続を許可する必要があります。詳細については、「Amazon Aurora から他の AWS のサービスへのネットワーク通信の有効化」を参照してください。
SageMaker AI では、推論に使用する機械学習コンポーネントが設定され、使用できる状態になっている必要があります。Aurora PostgreSQL DB クラスターの設定プロセス時に、SageMaker AI エンドポイントの Amazon リソースネーム (ARN) を用意する必要があります。SageMaker AI と連携してモデルを準備し、その他のタスクを処理するのは、チームのデータサイエンティストが最も適任だと考えられます。Amazon SageMaker AI を使い始めるには、「Get Started with Amazon SageMaker AI」を参照してください。推論とエンドポイントの詳細については、「リアルタイム推論」を参照してください。
-
Amazon Bedrock の場合、Aurora PostgreSQL DB クラスターの設定プロセス中に推論に使用する Bedrock モデルのモデル ID が必要です。チームのデータサイエンティストは、Bedrock と連携して使用するモデルを決定し、必要に応じて微調整して、他のタスクを処理するのが最も最適と考えられます。Amazon Bedrock の使用を開始するには、「Bedrock のセットアップ方法」を参照してください。
-
Amazon Bedrock ユーザーがモデルを使用するには、まずそのモデルへのアクセスをリクエストする必要があります。テキスト、チャット、イメージを生成するための新しいモデルを追加する場合は、Amazon Bedrock のモデルへのアクセスをリクエストする必要があります。詳細については、「モデルアクセス」を参照してください。
Aurora PostgreSQL で Aurora 機械学習を使用する場合にサポートされている機能と制限事項
Aurora 機械学習は、ContentType の text/csv 値を介して、カンマ区切り値 (CSV) 形式を読み書きできる SageMaker AI エンドポイントをサポートしています。現在、この形式を受け入れている組み込みの SageMaker AI アルゴリズムは以下のとおりです。
線形学習
ランダムカットフォレスト
XGBoost
これらのアルゴリズムの詳細については、「Amazon SageMaker デベロッパーガイド」の「Choose an Algorithm」を参照してください。
Amazon Bedrock を Aurora 機械学習と合わせて使用する場合、次の制限事項が適用されます。
-
ユーザー定義関数 (UDF) は、Amazon Bedrock を操作するためのネイティブな方法を提供します。UDF には特定のリクエストまたはレスポンス要件がないため、どのモデルも使用できます。
-
UDF を使用して必要なワークフローを構築できます。例えば、
pg_cronなどの基本プリミティブを組み合わせて、クエリの実行、データの取得、推論の生成、テーブルへの書き込みを行ってクエリを直接処理できます。 -
UDF はバッチ呼び出しまたは並列呼び出しをサポートしていません。
-
Aurora 機械学習の拡張機能は、ベクトルインターフェイスをサポートしていません。拡張機能の一部として、関数を使用してモデルのレスポンスの埋め込みを
float8[]形式で出力し、それらの埋め込みを Aurora に保存できます。float8[]の使用の詳細については、「Aurora PostgreSQL DB クラスターでの Amazon Bedrock の使用」を参照してください。
Aurora 機械学習を使用するように PostgreSQL DB クラスターを設定する
Aurora 機械学習を Aurora PostgreSQL DB クラスターと連携させるには、使用するサービスごとにAWS Identity and Access Management (IAM) ロールを作成する必要があります。IAM ロールによって、Aurora PostgreSQL DB クラスターがクラスターに代わって Aurora 機械学習サービスを使用することができます。また、Aurora 機械学習拡張機能のインストールが必要です。以下のトピックでは、これらの Aurora 機械学習サービスごとの設定手順を参照できます。
トピック
Amazon Bedrock を使用するように Aurora PostgreSQL を設定する
以下の手順では、まず、クラスターに代わって Amazon Bedrock を使用するアクセス権限を Aurora PostgreSQL に付与する IAM ロールとポリシーを作成します。次に、Aurora PostgreSQL DB クラスターが Amazon Bedrock の操作に使用する IAM ロールにポリシーをアタッチします。説明を簡単にするため、この手順では AWS マネジメントコンソール を使用してすべてのタスクを完了します。
Amazon Bedrock を使用するように Aurora PostgreSQL DB クラスターを設定には
AWS マネジメントコンソール にサインインして、IAM コンソール https://console.aws.amazon.com/iam/
を開きます。 IAM コンソール (https://console.aws.amazon.com/iam/
) を開きます。 AWS Identity and Access Management (IAM) コンソールメニューで [Policies] (ポリシー) ([Access management] (アクセス管理) の下) を選択します。
[Create policy] (ポリシーの作成) を選択します。ビジュアルエディタのページで [サービス] を選択し、[サービスの選択] フィールドに [Bedrock] と入力します。読み取りアクセスレベルを拡張します。Amazon Bedrock の読み取り設定から InvokeModel を選択します。
ポリシーを介して読み取りアクセスを許可する [基礎/プロビジョニング済み] モデルを選択します。
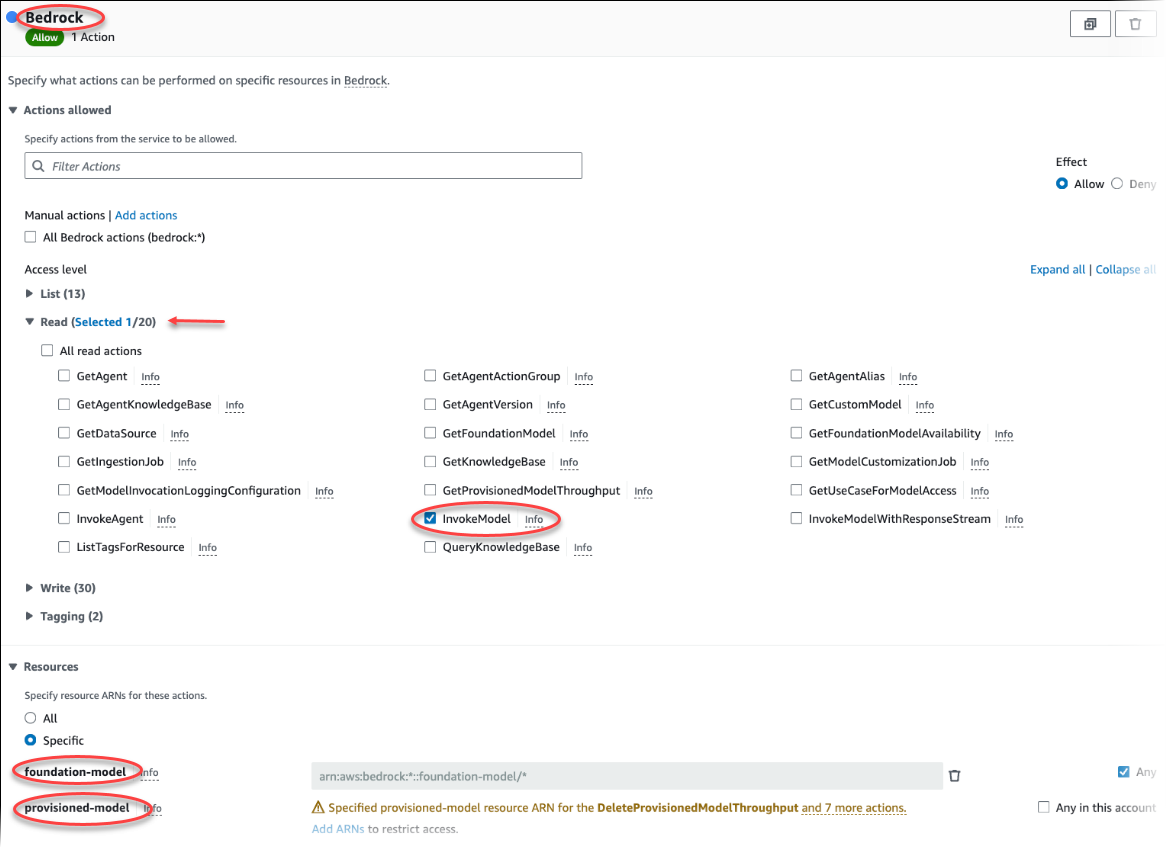
[Next: Tags] (次へ: タグ) を選択し、任意のタグを定義します (これはオプションです)。[次へ: レビュー] を選択します。画像のように ポリシーの名前と説明を入力します。
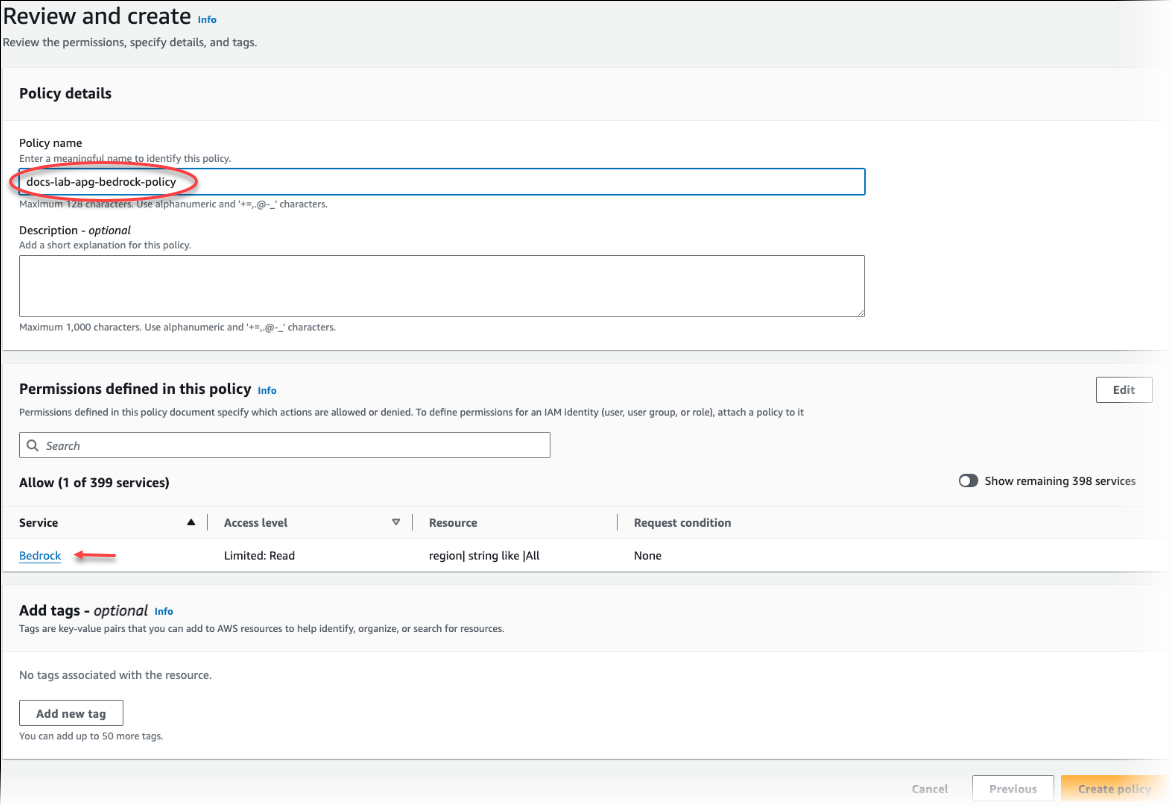
[Create policy] (ポリシーの作成) を選択します。ポリシーが保存されると、コンソールにアラートが表示されます。これはポリシーのリストで確認できます。
IAM コンソールで、[Roles] (ロール) ([Access management] (アクセス管理) の下) を選択します。
[ロールの作成] を選択してください。
[信頼されたエンティティを選択] ページで、[AWS のサービス] タイルを選択し、[RDS] を選択してセレクタを開きます。
[RDS – ロールをデータベースに追加する] を選択します。
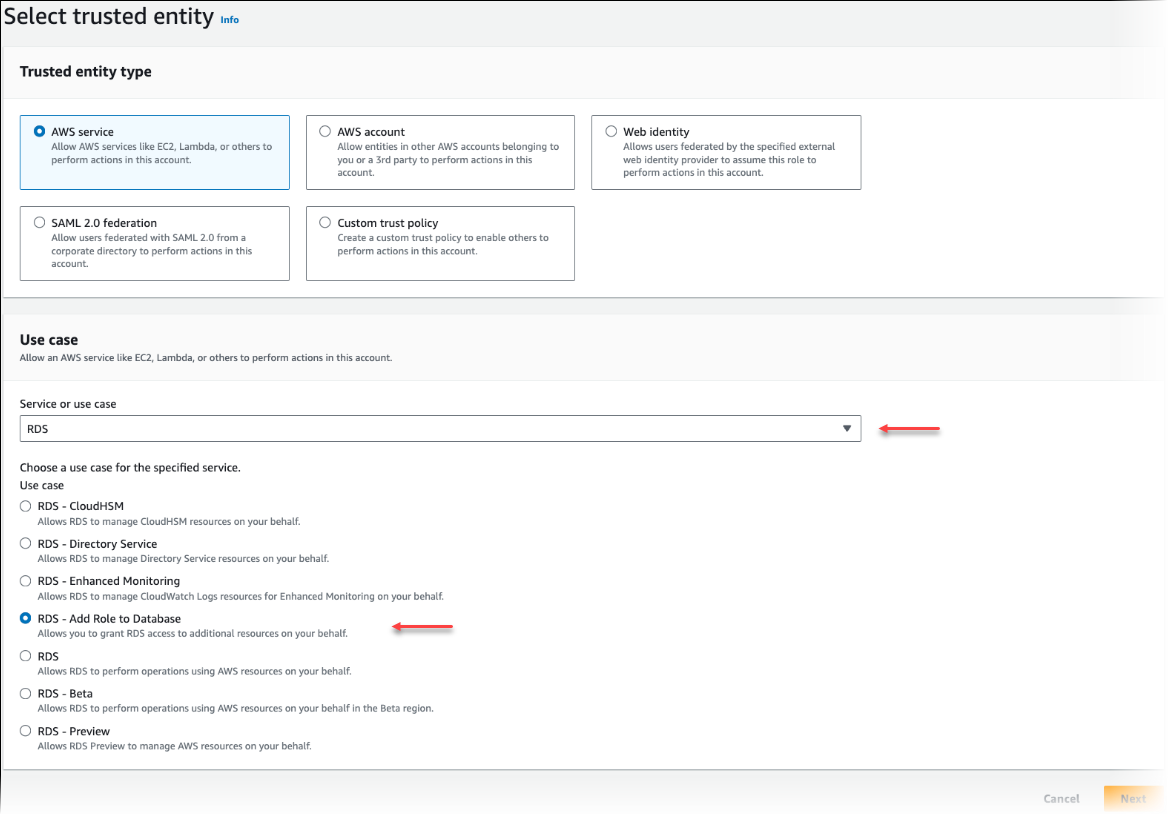
[次へ] を選択します。[Add permissions] (権限の追加) ページで、前の手順で作成したポリシーをリストから検索して選択します。[次へ] を選択します。
[Next: Review] (次へ: 確認)。IAM ロールの名前と説明を入力します。
Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 Aurora PostgreSQL DB クラスターがある AWS リージョン に移動します。
-
ナビゲーションペインで、[データベース] を選択して、Bedrock で使用する Aurora PostgreSQL DB クラスターを選択します。
-
[Connectivity & security] (接続とセキュリティ) タブを選択し、ページをスクロールして [Manage IAM roles] (IAM ロールの管理) セクションを見つけます。[Add IAM roles to this cluster] (IAM ロールをこのクラスターに追加する) セレクタから、前の手順で作成したロールを選択します。[機能] セレクタで [Bedrock] を選択し、[ロールを追加] を選択します。
ロール (およびそのポリシー) は、Aurora PostgreSQL DB クラスターに関連付けられています。プロセスが完了すると、次に示すように、このクラスターの現在の IAM ロールリストにロールが表示されます。
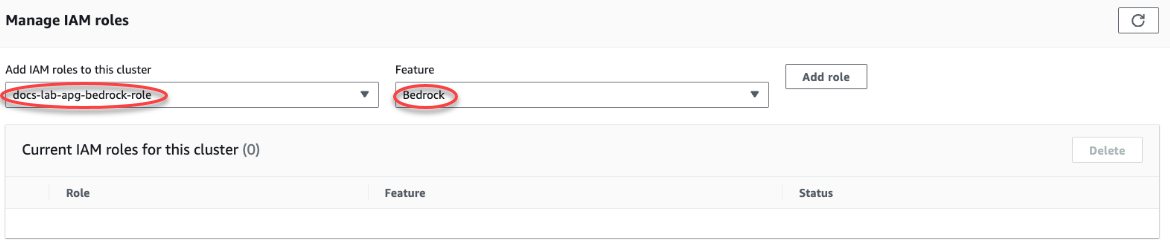
Amazon Bedrock の IAM 設定が完了しました。「Aurora 機械学習拡張拡張のインストール」の説明のように、Aurora PostgreSQL を Aurora 機械学習と連携するように設定を継続するには、拡張機能をインストールします
Amazon Comprehend を使用するように Aurora PostgreSQL を設定する
以下の手順では、まず、クラスターに代わって Amazon Comprehend を使用するアクセス権限を Aurora PostgreSQL に付与する IAM ロールとポリシーを作成します。次に、Aurora PostgreSQL DB クラスターが Amazon Comprehend と連携するために使用する IAM ロールにポリシーをアタッチします。わかりやすくするために、この手順では AWS マネジメントコンソール を使用してすべてのタスクを完了します。
Amazon Comprehend を使用するように Aurora PostgreSQL DB クラスターを設定には
AWS マネジメントコンソール にサインインして、IAM コンソール https://console.aws.amazon.com/iam/
を開きます。 IAM コンソール (https://console.aws.amazon.com/iam/
) を開きます。 AWS Identity and Access Management (IAM) コンソールメニューで [Policies] (ポリシー) ([Access management] (アクセス管理) の下) を選択します。
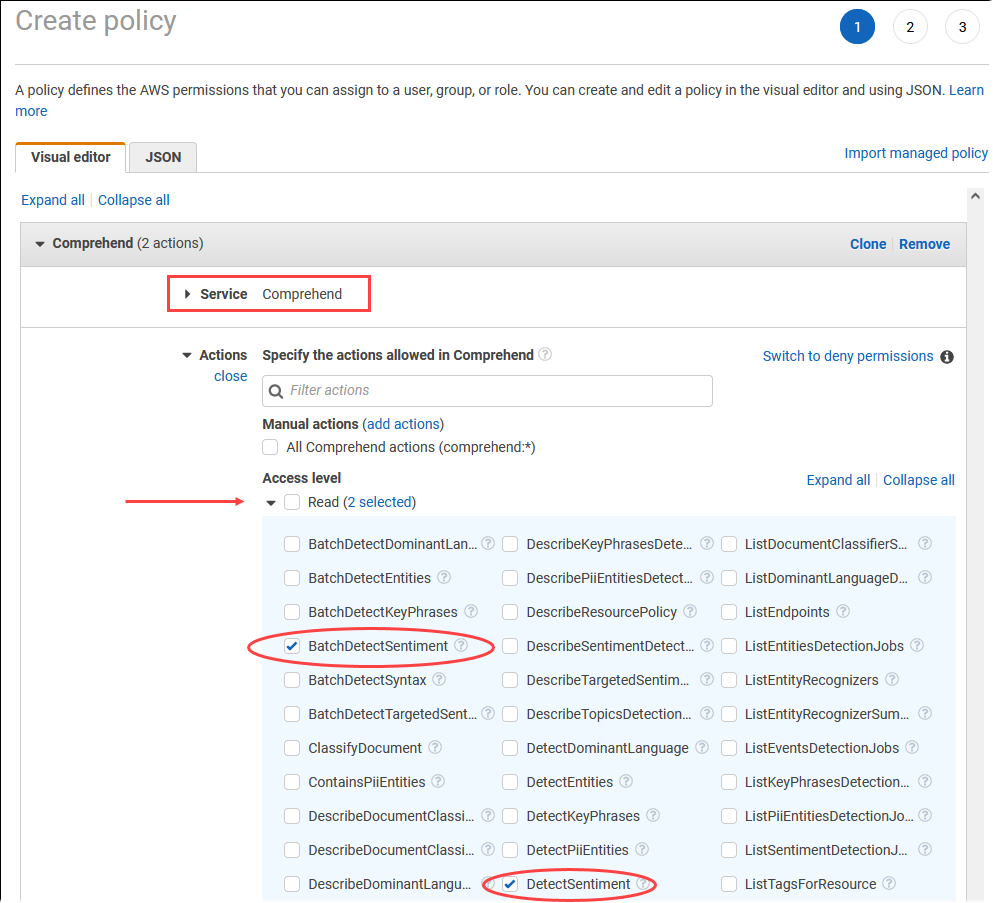
[Create policy] (ポリシーの作成) を選択します。ビジュアルエディタのページで[Service] (サービス) を選択し、[Select a service] (サービス選択) フィールドに [Comprehend] と入力します。読み取りアクセスレベルを拡張します。Amazon Comprehend の読み取り設定から BatchDetectSentiment と DetectSentiment を選択します。
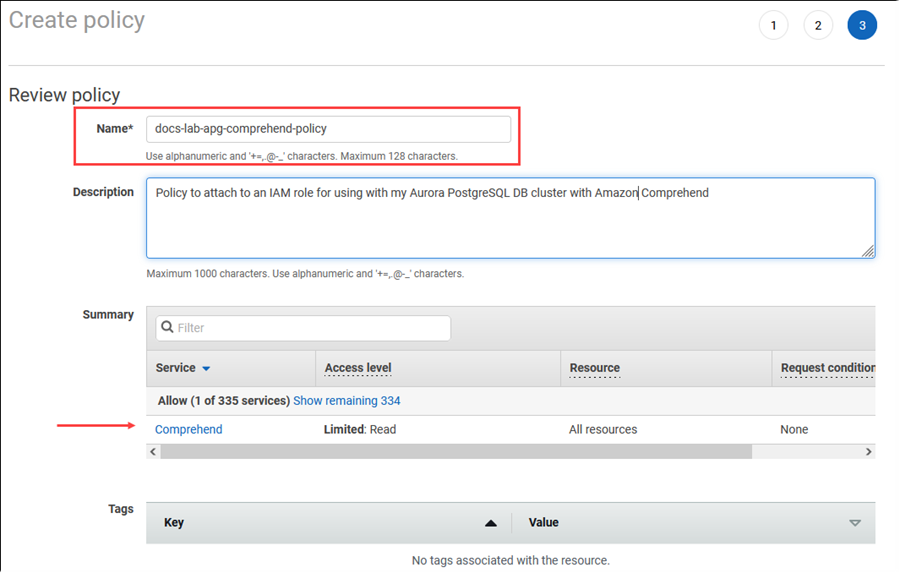
[Next: Tags] (次へ: タグ) を選択し、任意のタグを定義します (これはオプションです)。[次へ: レビュー] を選択します。画像のように ポリシーの名前と説明を入力します。
[Create policy] (ポリシーの作成) を選択します。ポリシーが保存されると、コンソールにアラートが表示されます。これはポリシーのリストで確認できます。
IAM コンソールで、[Roles] (ロール) ([Access management] (アクセス管理) の下) を選択します。
[ロールの作成] を選択してください。
[信頼されたエンティティを選択] ページで、[AWS のサービス] タイルを選択し、[RDS] を選択してセレクタを開きます。
[RDS – Add Role to Database] (RDS – ロールをデータベースに追加する) を選択します。
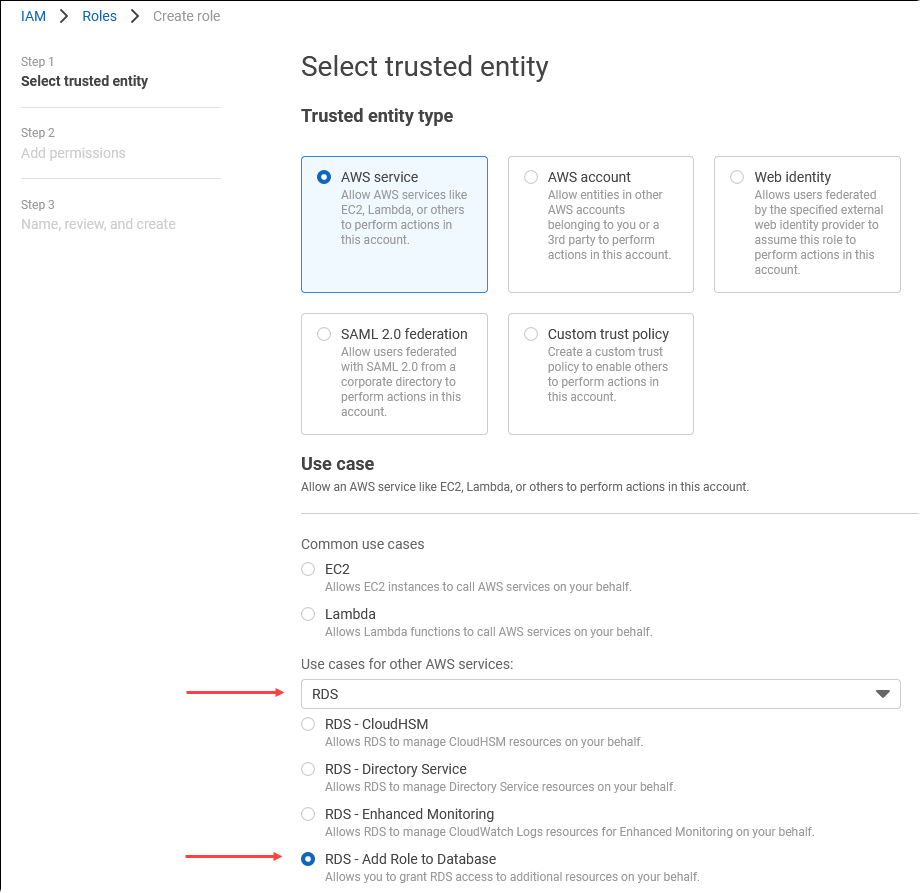
[次へ] を選択します。[Add permissions] (権限の追加) ページで、前の手順で作成したポリシーをリストから検索して選択します。[Next] (次へ) を選択します。
[Next: Review] (次へ: 確認)。IAM ロールの名前と説明を入力します。
Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 Aurora PostgreSQL DB クラスターがある AWS リージョン に移動します。
-
ナビゲーションペインで、[Databases] (データベース) を選択して、Amazon Comprehend で使用する Aurora PostgreSQL DB クラスターを選択します。
-
[Connectivity & security] (接続とセキュリティ) タブを選択し、ページをスクロールして [Manage IAM roles] (IAM ロールの管理) セクションを見つけます。[Add IAM roles to this cluster] (IAM ロールをこのクラスターに追加する) セレクタから、前の手順で作成したロールを選択します。[機能] セレクタで [Comprehend] を選択し、[ロールを追加] を選択します。
ロール (およびそのポリシー) は、Aurora PostgreSQL DB クラスターに関連付けられています。プロセスが完了すると、次に示すように、このクラスターの現在の IAM ロールリストにロールが表示されます。
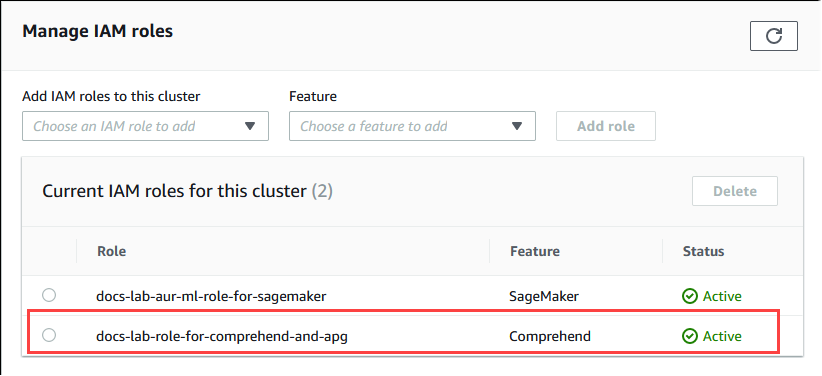
Amazon Comprehend の IAM 設定が完了しました。「Aurora 機械学習拡張拡張のインストール」の説明のように、Aurora PostgreSQL を Aurora 機械学習と連携するように設定を継続するには、拡張機能をインストールします
Amazon SageMaker AI を使用するように Aurora PostgreSQL を設定する
Aurora PostgreSQL DB クラスターの IAM ポリシーとロールを作成する前に、SageMaker AI モデルの設定とエンドポイントを利用できるようにする必要があります。
SageMaker AI を使用するように Aurora PostgreSQL DB クラスターを設定するには
AWS マネジメントコンソール にサインインして、IAM コンソール https://console.aws.amazon.com/iam/
を開きます。 AWS Identity and Access Management (IAM) コンソールメニューで [Policies] (ポリシー) ([Access management] (アクセス管理) の下) を選択し、次に [Create policy] (ポリシーの作成) を選択します。ビジュアルエディタで、[Service] (サービス) に [SageMaker] を選択します。アクションについては、読み取りセレクタ (アクセスレベルの下) を開き、[InvokeEndpoint] を選択します。これを実行すると、警告アイコンが表示されます。
リソースセレクタを開き、InvokeEndpoint アクションのエンドポイントリソース ARN の指定で、[Add ARN to restrict access] (アクセスを制限する ARN を追加する) リンクを選択します。
SageMaker AI リソースの AWS リージョン とエンドポイントの名前を入力します。AWS アカウントは事前に入力されています。
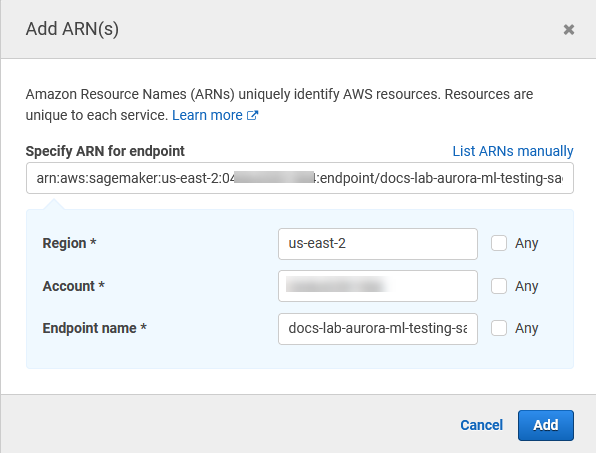
[Add] (追加) を選択して保存します。[Next: Tags] (次へ: タグ) と [Next: Review] (次へ: 確認) を選択して、ポリシー作成プロセスの最後のページに進みます。
ポリシーの名前と説明を入力して、[Create policy] (ポリシーの作成) を選択します。ポリシーが作成され、ポリシーのリストに追加されます。これが発生すると、コンソールにアラートが表示されます。
IAM コンソールで、[Roles] (ロール) を選択します。
[ロールの作成] を選択してください。
[信頼されたエンティティを選択] ページで、[AWS のサービス] タイルを選択し、[RDS] を選択してセレクタを開きます。
[RDS – Add Role to Database] (RDS – ロールをデータベースに追加する) を選択します。
[次へ] を選択します。[Add permissions] (権限の追加) ページで、前の手順で作成したポリシーをリストから検索して選択します。[Next] (次へ) を選択します。
[Next: Review] (次へ: 確認)。IAM ロールの名前と説明を入力します。
Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 Aurora PostgreSQL DB クラスターがある AWS リージョン に移動します。
-
ナビゲーションペインで [データベース] を選択して、SageMaker AI で使用する Aurora PostgreSQL DB クラスターを選択します。
-
[Connectivity & security] (接続とセキュリティ) タブを選択し、ページをスクロールして [Manage IAM roles] (IAM ロールの管理) セクションを見つけます。[Add IAM roles to this cluster] (IAM ロールをこのクラスターに追加する) セレクタから、前の手順で作成したロールを選択します。[機能] セレクタで [SageMaker AI] を選択し、[ロールを追加] を選択します。
ロール (およびそのポリシー) は、Aurora PostgreSQL DB クラスターに関連付けられています。プロセスが完了すると、このクラスターの現在の IAM ロールリストにロールが表示されます。
SageMaker AI の IAM 設定が完了しました。「Aurora 機械学習拡張拡張のインストール」の説明のように、Aurora PostgreSQL を Aurora 機械学習と連携するように設定を継続するには、拡張機能をインストールします。
SageMaker AI で Amazon S3 を使用するように Aurora PostgreSQL を設定する (高度)
SageMaker AI が提供する構築済みコンポーネントを使用せず、独自のモデルで SageMaker AI を使用するには、Aurora PostgreSQL DB クラスターが使用する Amazon Simple Storage Service (Amazon S3) バケットを設定する必要があります。これは高度なトピックであり、この「Amazon Aurora ユーザーガイド」にはすべては記載されていません。一般的な手順は、SageMaker AI のサポートを統合する場合と同じで、次のようになります。
Amazon S3 の IAM ポリシーとロールを作成します。
Aurora PostgreSQL DB クラスターの [Connectivity & security] (接続とセキュリティ) タブに、IAM ロールと Amazon S3 のインポートまたはエクスポートを機能として追加します。
Aurora DB クラスターのパラメータグループに、ロールの ARN を追加します。
基本的な使用に関する情報については、「SageMaker AI モデルトレーニング用のデータを Amazon S3 にエクスポートする (高度)」を参照してください。
Aurora 機械学習拡張拡張のインストール
Aurora 機械学習の拡張機能 aws_ml 1.0 には、Amazon Comprehend および SageMaker AI サービスの呼び出しに使用できる 2 つの関数があり、aws_ml 2.0 には、Amazon Bedrock サービスの呼び出しに使用できる 2 つの追加関数があります。Aurora PostgreSQL DB クラスターにこれらの拡張機能をインストールすると、その機能の管理者ロールも作成されます。
注記
これらの機能を使用するには、「Aurora 機械学習を使用するように PostgreSQL DB クラスターを設定する」の説明に従って Aurora 機械学習サービス (Amazon Comprehend、SageMaker AI、Amazon Bedrock) の IAM 設定が完了している必要があります。
aws_comprehend.detect_sentiment — この関数を使用して、Aurora PostgreSQL DB クラスターのデータベースに保存されているテキストに感情分析を適用します。
aws_sagemaker.invoke_endpoint — SQL コードでこの関数を使用して、クラスターから SageMaker AI エンドポイントと通信します。
aws_bedrock.invoke_model – SQL コードでこの関数を使用して、クラスターから Bedrock モデルと通信します。この関数のレスポンスは TEXT の形式になるため、モデルが JSON 本文の形式で応答する場合、この関数の出力は文字列の形式でエンドユーザーに中継されます。
aws_bedrock.invoke_model_get_embeddings – SQL コードでこの関数を使用して、JSON レスポンス内で出力埋め込みを返す Bedrock Models を呼び出します。これは、json-key に直接関連付けられた埋め込みを抽出して、セルフマネージドワークフローでのレスポンスを効率化する場合に利用できます。
Aurora 機械学習拡張機能を使用するように PostgreSQL DB クラスターにインストールするには
psqlを使用して、Aurora PostgreSQL DB クラスターのライターインスタンスに接続します。aws_ml拡張機能をインストールする対象のデータベースに接続します。psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
また、aws_ml 拡張機能をインストールすると、次のように aws_ml 管理者ロールと 3 つの新しいスキーマが作成されます。
aws_comprehend— Amazon Comprehend サービスのスキーマとdetect_sentiment関数のソース (aws_comprehend.detect_sentiment)。aws_sagemaker— SageMaker AI サービスのスキーマとinvoke_endpoint関数のソース (aws_sagemaker.invoke_endpoint)。aws_bedrock— Amazon Bedrock サービスのスキーマとinvoke_model(aws_bedrock.invoke_model)およびinvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings)関数のソース。
この rds_superuser ロールには aws_ml 管理者ロールが付与され、これら 3 つの Aurora 機械学習スキーマの OWNER で構成されています。他のデータベースユーザーが Aurora 機械学習機能にアクセスできるようにするには、rds_superuser では Aurora 機械学習機能の EXECUTE 権限を付与する必要があります。デフォルトでは、2 つの Aurora 機械学習スキーマの関数に対して、PUBLIC から EXECUTE 権限が取り消されます。
マルチテナントデータベース構成では、保護する特定の Aurora 機械学習スキーマで REVOKE USAGE を使用することで、テナントが Aurora 機械学習関数にアクセスするのを防ぐことができます。
Aurora PostgreSQL DB クラスターでの Amazon Bedrock の使用
Aurora PostgreSQL の場合、Aurora 機械学習では、テキストデータを扱うために次のような Amazon Bedrock 関数が用意されています。この機能は、aws_ml 2.0 拡張機能をインストールしてすべての設定手順を完了した後にのみ使用できます。詳細については、「Aurora 機械学習を使用するように PostgreSQL DB クラスターを設定する」を参照してください。
- aws_bedrock.invoke_model
-
この関数は、JSON でフォーマットされたテキストを入力として受け取り、Amazon Bedrock でホストされているさまざまなモデルに対して処理し、モデルから JSON テキストレスポンスを返します。このレスポンスには、テキスト、画像、埋め込みが含まれる場合があります。関数のドキュメントの概要は次のとおりです。
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
この関数の入力と出力は次のとおりです。
-
model_id- モデルの識別子。 content_type- Bedrock のモデルへのリクエストのタイプ。accept_type- Bedrock のモデルに期待されるレスポンスのタイプ。通常、ほとんどのモデルのアプリケーション/JSON。model_input- プロンプト。content_type で指定された形式のモデルへの特定の入力セット。モデルが受け入れるリクエスト形式/構造の詳細については、「基盤モデルの推論パラメータ」を参照してください。model_output- Bedrock モデルのテキストとしての出力。
次の例は、invoke_model を使用して Bedrock の Anthropic Claude 2 モデルを呼び出す方法を示しています。
例例: Amazon Bedrock の関数を使用する簡単なクエリ
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
モデル出力は、場合によってはベクトル埋め込みを指すことがあります。レスポンスはモデルによって異なるため、別の関数 invoke_model_get_embeddings を使用できます。これは invoke_model とまったく同じように機能しますが、適切な json-key を指定して埋め込みを出力します。
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
この関数の入力と出力は次のとおりです。
-
model_id- モデルの識別子。 content_type- Bedrock のモデルへのリクエストのタイプ。ここで、accept_type はデフォルト値のapplication/jsonに設定されます。model_input- プロンプト。content_type で指定された形式のモデルへの特定の入力セット。モデルが受け入れるリクエスト形式/構造の詳細については、「基盤モデルの推論パラメータ」を参照してください。json_key– 埋め込みの抽出元のフィールドへの参照。これは、埋め込みモデルが変更されると異なる場合があります。-
model_output– 16 ビットの小数を持つ埋め込みの配列としての Bedrock モデルの出力。
次の例は、Titan Embeddings G1 - Text embedding モデルを使用して「PostgreSQL I/O monitoring views」というフレーズの埋め込みを生成する方法を示しています。
例例: Amazon Bedrock 関数を使用する簡単なクエリ
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Aurora PostgreSQL DB クラスターで Amazon Comprehend を使用する
Aurora PostgreSQL の場合、Aurora 機械学習では、テキストデータを扱うために次のような Amazon Comprehend 関数が用意されています。この機能は、aws_ml 拡張機能をインストールしてすべての設定手順を完了した後にのみ使用できます。(詳しくは、「Aurora 機械学習を使用するように PostgreSQL DB クラスターを設定する」を参照してください。)
- aws_comprehend.detect_sentiment
-
この関数は、テキストを入力として受け取り、そのテキストの感情的な姿勢がポジティブ、ネガティブ、中立、または混合のいずれであるかを評価します。この感情を、信頼度とともに評価用に出力します。関数のドキュメントの概要は次のとおりです。
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
この関数の入力と出力は次のとおりです。
-
input_text— 評価して、感情 (ネガティブ、ポジティブ、中立、混合) を割り当てるテキスト。 language_code— 必要に応じて、地域サブタグ付きの 2 文字の ISO 639-1 識別子、または ISO 639-2 の 3 文字のコードを使用して識別されるinput_text言語。例えば、enは英語のコード、zhは中国語 (簡体字) のコードです。詳細については、「Amazon Comprehend デベロッパーガイド」の「サポートしている言語」を参照してください。max_rows_per_batch– バッチモード処理のバッチあたりの最大行数。(詳しくは、「バッチモードと Aurora 機械学習関数の理解」を参照してください。)sentiment— 入力テキストの感情で、POSITIVE (ポジティブ)、NEGATIVE (ネガティブ)、NEUTRAL (中立) 、MIXED (混合) として識別されます。confidence– 指定されたsentimentの値の精度に対する信頼度。値の範囲は 0.0~1.0 です。
以下では、この関数の使用方法について説明しています。
例例: Amazon Comprehend 関数を使用する簡単なクエリ
ここでは、この関数を呼び出し、サポートチームに対する顧客満足度を評価する簡単なクエリの例を示します。ヘルプをリクエストするたびに顧客からのフィードバックを保存するデータベーステーブル (support) があるとします。このクエリ例では、テーブルの feedback 列のテキストに aws_comprehend.detect_sentiment 関数を適用し、感情と、その感情に対する信頼度を出力します。また、このクエリは結果を降順で出力します。
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
テーブル行ごとに感情の検出が複数回発生しないように、分析の結果をマテリアライズできます。対象の行でこれを実行します。例えば、臨床医のメモは、フランス語 (fr) のものだけが感情検出関数を使用するように更新されています。
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
関数呼び出しの最適化の詳細については、「Aurora PostgreSQL で Aurora 機械学習を使用した場合のパフォーマンスに関する考慮事項」を参照してください。
Aurora PostgreSQL DB クラスターで SageMaker AI を使用する
「Amazon SageMaker AI を使用するように Aurora PostgreSQL を設定する」の説明にあるように、SageMaker AI 環境を設定して Aurora PostgreSQL と統合すると、aws_sagemaker.invoke_endpoint 関数を使用してオペレーションを呼び出すことができます。aws_sagemaker.invoke_endpoint 関数は、同じ AWS リージョン のモデルエンドポイントにのみ接続します。複数の AWS リージョン にデータベースインスタンスのレプリカがある場合は、必ず各 SageMaker AI モデルをすべての AWS リージョン に設定し、デプロイします。
aws_sagemaker.invoke_endpoint への呼び出しは、Aurora PostgreSQL DB クラスターを SageMaker AI サービスに関連付けるために設定した IAM ロールと、設定プロセス時に指定したエンドポイントを使用して認証されます。SageMaker AI モデルエンドポイントは個別のアカウントをスコープとし、パブリックではありません。endpoint_name の URL には、アカウント ID は含まれません。SageMaker AI は、データベースインスタンスの SageMaker AI IAM ロールによって提供される認証トークンからアカウント ID を判断します。
- aws_sagemaker.invoke_endpoint
この関数は、SageMaker AI エンドポイントを入力として受け取り、バッチとして処理すべき行数を受け取ります。また、SageMaker AI モデルエンドポイントに必要な複数のパラメータを入力として受け取ります。この関数のリファレンスドキュメントは次のとおりです。
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
この関数の入力と出力は次のとおりです。
endpoint_name– AWS リージョン に依存しないエンドポイントの URL。max_rows_per_batch– バッチモード処理のバッチあたりの最大行数。(詳しくは、「バッチモードと Aurora 機械学習関数の理解」を参照してください。)model_input– モデルの 1 つまたは複数の入力パラメータ。これらは、SageMaker AI モデルに必要なあらゆるデータ型にすることができます。PostgreSQL では、1 つの関数に対して最大 100 の入力パラメータを指定できます。配列のデータ型は 1 次元でなければなりませんが、SageMaker AI モデルで必要とされる数の要素を含めることができます。SageMaker AI モデルへの入力の数は、SageMaker AI の 6 MB のメッセージサイズ制限によってのみ制限されます。model_output– SageMaker AI モデルの、テキストとしての出力。
SageMaker AI モデルを呼び出すユーザー定義関数の作成
SageMaker AI の各モデルに対して aws_sagemaker.invoke_endpoint を呼び出す個別のユーザー定義関数を作成します。ユーザー定義関数は、モデルをホストする SageMaker AI エンドポイントを表します。この aws_sagemaker.invoke_endpoint 関数は、ユーザー定義関数内で実行されます。ユーザー定義関数には、次のような多くの利点があります。
-
すべての SageMaker AI モデルに対して
aws_sagemaker.invoke_endpointを呼び出すだけでなく、SageMaker AI モデルに独自の名前を付けることができます。 -
モデルエンドポイントの URL は、SQL アプリケーションコード内の 1 か所だけで指定できます。
-
各 Aurora 機械学習関数に対する
EXECUTE権限は、個別に制御できます。 -
SQL タイプを使用して、モデルの入力および出力タイプを宣言することができます。SQL は、SageMaker AI モデルに渡される引数の数と型を強制し、必要に応じて型変換を実行します。SQL タイプを使用すると、
SQL NULLも SageMaker AI モデルで求められる適切なデフォルト値に変換されます。 -
初期の数行を少し速く返す場合は、最大バッチサイズを小さくすることができます。
ユーザー定義関数を指定するには、SQL データ定義言語 (DDL) ステートメント CREATE FUNCTION を使用します。関数を定義するときは、以下を指定します。
-
モデルへの入力パラメータ。
-
呼び出す特定の SageMaker AI エンドポイント。
-
戻り型。
このユーザー定義関数は、入力パラメータでモデルを実行した後、SageMaker AI エンドポイントによって計算された推論を返します。次の例では、2 つの入力パラメータを持つ SageMaker AI モデルのユーザー定義関数を作成します。
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;次の点に注意してください。
-
aws_sagemaker.invoke_endpoint関数入力には、任意のデータ型の 1 つ以上のパラメータを指定できます。 -
この例では、INT 出力型を使用します。ある
varchar型から別の型に出力をキャストする場合は、INTEGER、REAL、FLOAT、またはNUMERICなどのPostgreSQL組み込みスカラー型にキャストする必要があります。このような型の詳細については、PostgreSQL ドキュメントの「データ型」を参照してください。 -
パラレルクエリ処理を有効にするには、
PARALLEL SAFEを指定します。詳細については、「パラレルクエリ処理によるレスポンス時間の向上」を参照してください。 -
関数を実行するためのコストを見積もるには
COST 5000を指定します。関数の推定実行コストを示す正の数をcpu_operator_costの単位で使用します 。
配列を入力として SageMaker AI モデルに渡す
この aws_sagemaker.invoke_endpoint 関数は、PostgreSQL 関数の上限である、最大 100 個の入力パラメータを持つことができます。SageMaker AI モデルが同じ型のパラメータを 100 個以上必要とする場合は、モデルパラメータを配列として渡します。
次の例では、SageMaker AI リグレッションモデルへの入力として配列を渡す関数を定義します。出力は値に REAL キャストされます。
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
SageMaker AI モデルの呼び出し時にバッチサイズを指定する
次の例では、バッチサイズのデフォルトを NULL に設定する SageMaker AI モデルのユーザー定義関数を作成します。この関数では、呼び出し時に異なるバッチサイズを指定することもできます。
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;次の点に注意してください。
-
オプションの
max_rows_per_batchパラメータを使用すると、バッチモード関数呼び出しの行数を制御できます。NULL の値を使用すると、クエリオプティマイザは最大バッチサイズを自動的に選択します。詳細については、「バッチモードと Aurora 機械学習関数の理解」を参照してください。 -
デフォルトでは、パラメータの値として NULL を渡すと、SageMaker AI に渡す前に空の文字列に変換されます。この例では、入力のタイプが異なります。
-
テキスト以外の入力、または空の文字列以外の値をデフォルトにする必要があるテキスト入力がある場合は、
COALESCEステートメントを使用します。COALESCEを使用して、aws_sagemaker.invoke_endpointへの呼び出しで NULL を目的の NULL 置換値に変換します 。この例のamountパラメータでは、NULL 値が 0.0 に変換されます。
複数の出力を持つ SageMaker AI モデルの呼び出し
次の例では、複数の出力を返す SageMaker AI モデルのユーザー定義関数を作成します。関数は、aws_sagemaker.invoke_endpoint 関数の出力を対応するデータ型にキャストする必要があります。例えば、組み込み PostgreSQL ポイント型を (x,y) ペアまたはユーザー定義のコンポジット型に使用できます。
このユーザー定義関数は、出力にコンポジット型を使用して複数の出力を返すモデルから値を返します。
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
コンポジット型の場合、モデル出力に表示されるのと同じ順序でフィールドを使用し、aws_sagemaker.invoke_endpoint の出力をコンポジット型にキャストします。呼び出し元は、名前または PostgreSQL「*」表記で個々のフィールドを抽出することができます。
SageMaker AI モデルトレーニング用のデータを Amazon S3 にエクスポートする (高度)
独自のモデルをトレーニングするよりも、提供されているアルゴリズムや例を使用して Aurora 機械学習と SageMaker AI に慣れることをお勧めします。詳細については、「Get Started with Amazon SageMaker AI」を参照してください。
SageMaker AI モデルをトレーニングするには、データを Amazon S3 バケットにエクスポートします。Amazon S3 バケットは、デプロイ前にモデルをトレーニングするために SageMaker AI によって使用されます。Aurora PostgreSQL DB クラスターからデータをクエリし、Amazon S3 バケットに保存されているテキストファイルに直接保存できます。その後、SageMaker AI は、トレーニングのために Amazon S3 バケットからデータを消費します。SageMaker AI モデルトレーニングの詳細については、「Train a model with Amazon SageMaker AI」を参照してください。
注記
SageMaker AI モデルトレーニングまたはバッチスコアリング用に Amazon S3 バケットを作成する場合は、Amazon S3 バケット名に sagemaker を使用してください。詳細については、「Amazon SageMaker AI デベロッパーガイド」の「Specify a Amazon S3 Bucket to Upload Training Datasets and Store Output Data」を参照してください。
データのエクスポートの詳細については、「Aurora PostgreSQL DB クラスターから Amazon S3 へのデータのエクスポート」を参照してください。
Aurora PostgreSQL で Aurora 機械学習を使用した場合のパフォーマンスに関する考慮事項
Amazon Comprehend と SageMaker AI のサービスは、Aurora の機械学習関数によって呼び出された際には、ほとんどの作業を行います。つまり、これらのリソースを必要に応じて個別にスケーリングできることになります。Aurora PostgreSQL DB クラスターでは、関数呼び出しを最大限効率的に行うことができます。以下に、Aurora PostgreSQL から Aurora 機械学習を使用する際に注意すべきパフォーマンスに関する考慮事項をいくつか示します。
バッチモードと Aurora 機械学習関数の理解
通常、PostgreSQL は関数を一度に 1 行ずつ実行します。Aurora 機械学習は、このオーバーヘッドを削減するため、バッチモード実行と呼ばれるアプローチを使用して、多くの行のための外部 Aurora 機械学習サービスの呼び出しをバッチ処理に結合します。バッチモードでは、Aurora 機械学習は入力行のバッチに対する応答を受け取り、その応答を一度に 1 行ずつ実行中のクエリに返送します。この最適化により、PostgreSQL クエリオプティマイザを制限せずに、Aurora クエリのスループットが向上します。
関数が SELECT リスト、WHERE 句、または HAVING 句から参照される場合、Aurora は自動的にバッチモードを使用します。トップレベルの単純な CASE 表現は、バッチモードの実行の対象であることに注意してください。最上位レベルの検索 CASE 表現は、初期の WHEN 句がバッチモード関数呼び出しを伴う単純な述語である場合にも、バッチモード実行の対象となります。
ユーザー定義関数は LANGUAGE SQL 関数で、PARALLEL SAFE と COST 5000 を指定する必要があります。
SELECT ステートメントから FROM 句への関数の移行
通常、バッチモード実行の対象となる aws_ml 関数は、Aurora によって自動的に FROM 句に移行されます。
対象のバッチモード関数から FROM 句への移行は、クエリごとのレベルで手動で調べることができます。これを行うには、EXPLAIN ステートメント (および ANALYZE および VERBOSE) を使用し、各バッチモード Function Scan の下に「バッチ処理」情報を見つけます。クエリを実行せずに EXPLAIN (VERBOSE 付き) を使用することもできます。次に、関数への呼び出しが、元のステートメントで指定されていないネストされたループ結合の下に Function
Scan と表示されるかどうかを観察します。
次の例では、プランにネストされたループ結合演算子によって、Aurora が anomaly_score 関数を移行したことを示しています。この関数を SELECT リストから、バッチモード実行の対象である、FROM 句に移行しました。
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)バッチモードの実行を無効にするには、apg_enable_function_migration パラメータを false に設定します。これにより、SELECT から aws_ml 句への FROM 関数の移行が防止されます。以下にその方法を示します。
SET apg_enable_function_migration = false;apg_enable_function_migration パラメータは、クエリプラン管理の Aurora PostgreSQL apg_plan_mgmt エクステンションによって認識される Grand Unified Configuration (GUC) パラメータです。セッションで関数の移行を無効にするには、クエリプラン管理を使用して、結果のプランを approved プランとして保存します。実行時に、クエリプラン管理によって、approved プランが apg_enable_function_migration 設定で適用されます。この強制は、apg_enable_function_migration GUC パラメータの設定に関係なく発生します。詳細については、「Aurora PostgreSQL のクエリ実行計画の管理」を参照してください。
max_rows_per_batch パラメータを使用する
aws_comprehend.detect_sentiment 関数と aws_sagemaker.invoke_endpoint 関数の両方に max_rows_per_batch パラメータがあります。このパラメータには、Aurora 機械学習サービスに送信できる行数を指定します。関数で処理されるデータセットが大きいほど、バッチサイズを大きくすることができます。
バッチモード関数は、 Aurora 機械学習関数呼び出しのコストを多数の行に分散させる行のバッチを構築することにより、効率を向上させます。ただし、SELECT 句が原因で LIMIT ステートメントが早期終了した場合、クエリが使用する行よりも多くの行にわたってバッチを構築できます。この方法では、AWS アカウントに追加料金が発生する可能性があります。バッチモード実行の利点を得て、大きすぎるバッチの作成を避けるには、関数呼び出しで max_rows_per_batch パラメータに小さい値を使用します。
バッチモードの実行を使用するクエリの EXPLAIN (VERBOSE、ANALYZE) を実行すると、ネストされたループ結合の下にある FunctionScan 演算子が表示されます。EXPLAIN によって報告されるループ回数は、FunctionScan 演算子から行がフェッチされた回数に等しくなります。ステートメントが LIMIT 句を使用する場合、フェッチの数は一貫しています。バッチのサイズを最適化するには、max_rows_per_batch パラメータをこの値に設定します。ただし、バッチモード関数が WHERE 句または HAVING 句の述語で参照されている場合、事前にフェッチの数を知ることができない可能性があります。この場合、ループをガイドラインとして使用し、max_rows_per_batch で実験して、パフォーマンスを最適化する設定を見つけます。
バッチモード実行の検証
関数がバッチモードで実行されたかどうかを確認するには、EXPLAIN ANALYZE を使用します。バッチモードの実行が使用された場合、クエリプランは「バッチ処理」セクションに情報を含めます。
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273この例では、3,333 行を含む 1 つのバッチがあり、処理に 146.273 ミリ秒かかりました。「バッチ処理」セクションには、次の項目が表示されます。
-
この関数スキャン操作に対して存在したバッチ数
-
バッチサイズの平均、最小および最大
-
バッチ実行時間の平均、最小および最大
通常、最終バッチは残りのバッチよりも小さく、多くの場合、平均よりかなり小さい最小バッチサイズになります。
初期の数行をより速く返すには、max_rows_per_batch パラメータを小さい値に設定します。
ユーザー定義関数で LIMIT を使用するときに ML サービスへのバッチモード呼び出し回数を減らすには、max_rows_per_batch パラメータの値を小さくします。
パラレルクエリ処理によるレスポンス時間の向上
多数の行からできるだけ早く結果を得るために、パラレルクエリ処理とバッチモード処理を組み合わせることができます。SELECT、CREATE TABLE AS SELECT、および CREATE
MATERIALIZED VIEW ステートメントに対してパラレルクエリ処理を使用できます。
注記
PostgreSQL はまだデータ操作言語 (DML) ステートメントのパラレルクエリをサポートしていません。
パラレルクエリ処理は、データベース内と ML サービス内の両方で行われます。データベースのインスタンスクラスのコア数によって、クエリの実行中に使用できるパラレル性の程度が制限されます。データベースサーバーは、パラレルワーカーのセット間でタスクをパーティショニングするパラレルクエリ実行プランを構築できます。その後、これらのワーカーのそれぞれは、数万行 (または各サービスで許可される行数) を含むバッチリクエストを構築できます。
すべてのパラレルワーカーからのバッチ結合されたリクエストは、SageMaker AI のエンドポイントに送信されます。エンドポイントがサポートできる並列性の程度は、エンドポイントをサポートするインスタンスの数とタイプによって制限されます。K 度の並列性には、少なくとも K 個のコアを持つデータベースインスタンスクラスが必要です。また、十分に高性能なインスタンスクラスの初期インスタンスを K 個持つように、モデルの SageMaker AI エンドポイントを設定する必要があります。
パラレルクエリ処理を利用するには、渡す予定のデータを含むテーブルの parallel_workers 格納パラメータを設定します。parallel_workers は、aws_comprehend.detect_sentiment などのバッチモード関数に設定します。オプティマイザがパラレルクエリプランを選択した場合、AWS ML サービスはバッチとパラレルの両方で呼び出すことができます。
aws_comprehend.detect_sentiment 関数で以下のパラメータを使用すると、四方向パラレル処理でプランを取得できます。次の 2 つのパラメータのいずれかを変更した場合、データベースインスタンスを再起動して変更を反映させる必要があります。
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;パラレルクエリの制御情報の詳細については、PostgreSQL ドキュメントの「パラレルプラン
マテリアライズドビューとマテリアライズド列の使用
SageMaker AI や Amazon Comprehend などの AWS のサービスをデータベースから呼び出すと、それらのサービスの料金ポリシーに基づきアカウントが課金されます。アカウントへの請求を最小限に抑えるために、AWS サービスを呼び出した結果をマテリアライズド列に生成して、AWS のサービスが入力行ごとに複数回呼び出されないようにすることができます。必要に応じて、materializedAt タイムスタンプカラムを追加して、カラムがマテリアライズされた時刻を記録できます。
通常の単一行 INSERT ステートメントのレイテンシーは、通常、バッチモード関数を呼び出すレイテンシーよりもはるかに短くなります。したがって、アプリケーションが実行するすべての単一行 INSERT に対してバッチモード関数を呼び出すと、アプリケーションのレイテンシー要件を満たすことができない場合があります。AWS のサービスをマテリアライズド列に呼び出した結果をマテリアライズするには、通常、高性能アプリケーションはマテリアライズド列に値を設定する必要があります。これを行うために、大量の行のバッチを同時に処理する UPDATE ステートメントを定期的に発行します。
UPDATE では、実行中のアプリケーションに影響を与える可能性のある行レベルのロックが行われます。したがって、SELECT ... FOR UPDATE SKIP LOCKED を使用するか、MATERIALIZED
VIEW を使用する必要があります。
大量の行をリアルタイムで操作する分析クエリは、バッチモードのマテリアライズとリアルタイム処理を組み合わせることができます。これを行うために、これらのクエリは、事前マテリアライズド結果の UNION ALL をアセンブルし、まだマテリアライズド結果がない行をクエリします。場合によっては、このような UNION ALL が複数の場所で必要になるか、またはサードパーティーのアプリケーションによってクエリが生成されます。その場合は、VIEW を作成し、UNION ALL 操作をカプセル化して、この詳細が SQL アプリケーションの残りの部分に表示されないようにすることができます。
マテリアライズドビューを使用すると、スナップショットで任意の SELECT ステートメントの結果をマテリアライズできます。また、これを使用して、将来いつでもマテリアライズドビューを更新することもできます。現在、PostgreSQL は増分更新をサポートしていないため、マテリアライズドビューが更新されるたびにマテリアライズドビューが完全に再計算されます。
CONCURRENTLY オプションを使用してマテリアライズドビューをリフレッシュできます。このオプションを使用すると、排他ロックを取らずにマテリアライズドビューの内容が更新されます。これにより、SQL アプリケーションはマテリアライズドビューの更新中にマテリアライズドビューから読み取ることができます。
Aurora 機械学習のモニタリング
カスタム DB クラスターパラメータグループの track_functions パラメータを all に設定することで、aws_ml 関数をモニタリングできます。デフォルトでは、このパラメータは pl に設定されており、プロシージャ言語関数のみが追跡されることになります。これを all に変更すると、aws_ml 関数も追跡されます。詳細については、PostgreSQL のドキュメントで「ランタイム統計
Aurora 機械学習関数から呼び出される SageMaker AI オペレーションのパフォーマンスのモニタリングについては、「Amazon SageMaker AI デベロッパーガイド」の「Monitor Amazon SageMaker AI」を参照してください。
track_functions を all に設定すると、pg_stat_user_functions ビューをクエリして、Aurora 機械学習サービスを呼び出すために定義および使用した関数に関する統計を取得できます。各関数について、ビューに calls、total_time、self_time の数が表示されます。
aws_sagemaker.invoke_endpoint 関数と aws_comprehend.detect_sentiment 関数の統計を表示するには、次のクエリを使用してスキーマ名で結果をフィルタリングできます。
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
統計を消去するには、以下の手順を実行してください。
SELECT pg_stat_reset();
PostgreSQL pg_proc システムカタログにクエリすることで、aws_sagemaker.invoke_endpoint 関数を呼び出す SQL 関数の名前を取得できます。このカタログには、関数、プロシージャなどに関する情報が保存されています。詳細については、PostgreSQL ドキュメントの「pg_procprosrc) に invoke_endpoint というテキストが含まれている関数 (proname) の名前を取得するためにテーブルをクエリする例を示しています。
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
