翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
カスタム分類子の調教 (コンソール)
コンソールを使用してカスタム分類子を作成して調教し、そのカスタム分類子を使用して文書を分析できます。
カスタム分類子を調教するには、一連の調教文書が必要です。これらの文書には、文書分類子に認識させたいカテゴリのラベルを付けます。調教文書の作成については、「分類子調教データの作成」を参照してください。
文書分類モデルを作成して調教するには
-
にサインイン AWS マネジメントコンソール し、https://console.aws.amazon.com/comprehend/
で Amazon Comprehend コンソールを開きます。 -
左側のメニューから [カスタマイズ] を選択し、[カスタム分類] を選択します。
-
[モデルの作成] を選択します。
-
[モデルの設定] に分類子のモデル名を入力します。この名前は、自分のアカウント内と現在のリージョンで一意でなければなりません。
(オプション) バージョン名を入力します。この名前は、自分のアカウント内と現在のリージョンで一意でなければなりません。
-
調教文書の言語を選択します。分類子がサポートする言語については、「調教分類モデル」を参照してください。
-
(オプション) Amazon Comprehend が調教ジョブを処理している間にストレージボリューム内のデータを暗号化する場合は、[分類子の暗号化]を選択します。次に、自分の現在のアカウントに関連付けられた KMS キーを使用するか、別のアカウントの KMS キーを使用するかを選択します。
現在のアカウントに関連付けられているキーを使用している場合は、KMS キー ID のキー ID を選択します。
別のアカウントに関連付けられているキーを使用している場合は、KMS キー ARN の下にキー ID の ARN を入力します。
注記
KMS キーの作成と使用や関連する暗号化の詳細については、AWS Key Management Service (AWS KMS) を参照してください。
-
「データ仕様」で、使用する [調教モデルタイプ] を選択します。
プレーンテキスト文書:このオプションを選択すると、プレーンテキストモデルが作成されます。プレーンテキスト文書を使用してモデルを調教します。
ネイティブ文書:ネイティブ文書モデルを作成するには、このオプションを選択します。ネイティブ文書 (PDF、Word、画像) を使用してモデルを調教します。
-
調教データの [データ形式] を選択します。データ形式の詳細については、「分類子調教ファイルの形式」を参照してください。
CSV ファイル:調教データが CSV ファイル形式を使用している場合は、このオプションを選択してください。
拡張マニフェスト:Ground Truth を使用して調教データ用の拡張マニフェストファイルを作成した場合は、このオプションを選択してください。この形式は、調教モデルタイプとして [プレーンテキスト文書] を選択した場合に使用できます。
-
使用する [分類子モード] を選択します。
シングルラベルモード:文書に割り当てるカテゴリが相互に排他的であり、各文書に 1 つのラベルを割り当てるように分類子を学習させる場合は、このモードを選択します。Amazon Comprehend API では、シングルラベルモードはマルチクラスモードと呼ばれています。
マルチラベルモード:1 つの文書に複数のカテゴリを同時に適用でき、各文書に 1 つまたは複数のラベルを割り当てるように分類子を調教する場合は、このモードを選択します。
-
マルチラベルモードを選択すると、ラベルの区切り文字を選択できます。調教文書に複数のクラスがある場合は、この区切り文字を使用してラベルを区切ります。デフォルトの区切り文字はパイプ文字です。
-
(オプション) データ形式として拡張マニフェストを選択した場合、最大 5 つの拡張マニフェストファイルを入力できます。各拡張マニフェストファイルには、調教データセットまたはテストデータセットが含まれます。少なくとも 1 つの調教データセットを指定する必要があります。テストデータセットは任意です。次の手順に従って、拡張マニフェストファイルを設定します。
-
「調教とテストデータセット」で、「入力場所」パネルを展開します。
-
[データセットタイプ] で [調教データ] または [テストデータ] を選択します。
-
SageMaker AI Ground Truth 拡張マニフェストファイル S3 の場所については、マニフェストファイルを含む Amazon S3 バケットの場所を入力するか、Browse S3 を選択して移動します。調教ジョブのアクセス許可に使用する IAM ロールには、S3 バケットに対する読み取り許可が必要です。
-
[属性名] に、注釈を含む属性の名前を入力します。ファイルに複数のチェーンラベリングジョブのアノテーションが含まれている場合は、ジョブごとに属性を追加します。
別の入力場所を追加するには、[入力場所を追加] を選択し、次の場所を設定します。
-
-
(オプション) データ形式として CSV ファイルを選択した場合は、次の手順に従って調教データセットとオプションのテストデータセットを設定します。
-
[調教データセット] で、調教データの CSV ファイルを含む Amazon S3 バケットの場所を入力するか、[S3 を参照] を選択してその場所に移動します。調教ジョブのアクセス許可に使用する IAM ロールには、S3 バケットに対する読み取り許可が必要です。
(オプション) 調教モデルタイプとしてネイティブ文書を選択した場合は、調教サンプルファイルの入った Amazon S3 フォルダの URL も指定します。
-
[テストデータセット] で、調教済みモデルをテストするための追加データを Amazon Comprehend に提供するかどうかを選択します。
-
Autosplit: Autosplit は調教データの 10% を自動的に選択し、テストデータとして使用するために確保します。
(オプション) 顧客提供: Amazon S3 のテストデータの CSV ファイルの URL を入力します。Amazon S3 内のその場所に移動して [フォルダを選択] を選択することもできます。
(オプション) 調教モデルタイプとしてネイティブ文書を選択した場合は、テストファイルの入った Amazon S3 フォルダの URL も指定します。
-
-
-
(オプション) 文書読み取りモードでは、デフォルトのテキスト抽出アクションをオーバーライドできます。このオプションはスキャンされた文書のテキスト抽出に適用されるため、プレーンテキストモデルには必要ありません。詳細については、「テキスト抽出オプションの設定」を参照してください。
-
(プレーンテキストモデルの場合はオプション) [出力データ] には、混同行列などの調教出力データを保存する Amazon S3 バケットの場所を入力します。詳細については、「混同行列」を参照してください。
(オプション) 調教ジョブの出力結果を暗号化する場合は、[暗号化] を選択します。次に、現在のアカウントに関連付けられた KMS キーを使用するか、別のアカウントの KMS キーを使用するかを選択します。
現在のアカウントに関連付けられているキーを使用している場合は、KMS キー ID のキーエイリアスを選択します。
別のアカウントに関連付けられているキーを使用している場合は、KMS キー ID の下にキーエイリアス の ARN または ID を入力します。
-
IAM ロールには、[既存の IAM ロールを選択] を選択し、調教文書を含む S3 バケットの読み取り権限を持つ既存の IAM ロールを選択します。ロールには、
comprehend.amazonaws.comで始まる信頼ポリシーが必要です。このような権限を持つ IAM ロールがまだない場合は、[IAM ロールの作成] を選択して作成してください。このロールを付与するアクセス権限を選択し、アカウント内の IAM ロールと区別できるように名前のサフィックスを選択します。
注記
暗号化された入力文書の場合、使用する IAM ロールにも権限が必要です。
kms:Decrypt詳細については、「KMS 暗号化を使用するために必要なアクセス許可」を参照してください。 -
(オプション) VPC から Amazon Comprehend にリソースを起動するには、VPC の下に VPC ID を入力するか、ドロップダウンリストから ID を選択します。
[サブネット] でサブネットを選択します。最初のサブネットを選択すると、追加のサブネットを選択できます。
セキュリティグループを指定した場合は、[セキュリティグループ] で、使用するセキュリティグループを選択します。最初のセキュリティグループを選択すると、追加のセキュリティグループを選択できます。
注記
分類ジョブで VPC を使用する場合、[作成] と [開始] 操作に使用する
DataAccessRoleには、入力文書と出力バケットへの VPC アクセス権限が必要です。 -
(オプション) カスタム分類子にタグを追加するには、[タグ] にキーと値のペアを入力します。[タグを追加] を選択します。分類子を作成する前にこのペアを削除するには、[タグを削除] を選択します。詳細については、「リソースのタグ付け」を参照してください。
-
[作成] を選択します。
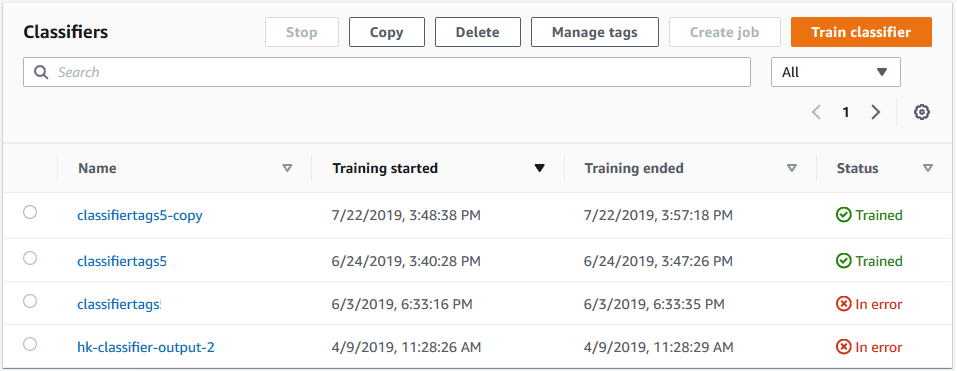
コンソールに「分類子」ページが表示されます。新しい分類子が表で表示され、そのステータス Submitted が表示されます。分類子が調教文書の処理を開始すると、ステータスが Training に変わります。分類子が使用できるようになると、ステータスが Trained または Trained with warnings に変わります。ステータスが TRAINED_WITH_WARNINGS の場合、分類子の調教出力 のスキップしたファイルのフォルダを確認してください。
Amazon Comprehend の作成中または調教中にエラーが発生した場合、ステータスは In error に変わります。表中の分類子ジョブを選択すると、エラーメッセージを含む分類子に関する詳細情報を取得できます。