翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Rekognition Video は、ビデオの分析に使用できる API です。Amazon Rekognition Video では、Amazon Simple Storage Service (Amazon S3) バケットに保存されているビデオ内のラベル、顔、人物、有名人、およびアダルト (暗示的および明示的) コンテンツを検出できます。Amazon Rekognition Video は、メディア/エンターテインメントや公共安全などのカテゴリで利用できます。これまでのような物体や人物が撮影されたビデオの人間によるスキャンでは、かなりの時間がかかるだけでなく、エラーも頻繁に発生していました。Amazon Rekognition Video を使うことで、ビデオ全体を通しての項目の検出や、項目が登場したタイミングの検出を自動化することができます。
このセクションでは、Amazon Rekognition Video で実行できる分析のタイプ、API の概要、および Amazon Rekognition Video の使用例について説明します。
トピック
分析のタイプ
Amazon Rekognition Video を使用して、以下の情報についてビデオを分析できます。
詳細については、「Amazon Rekognition の仕組み」を参照してください。
Amazon Rekognition Video API の概要
Amazon Rekognition Video は、Amazon S3 バケットに保存されたビデオを処理します。その設計パターンは、複数のオペレーションの非同期セットとなっており、StartLabelDetection などの Start オペレーションを呼び出すと、ビデオの分析が開始されます。リクエストの完了ステータスは、Amazon Simple Notification Service (Amazon SNS) トピックに発行されます。Amazon SNS トピックから完了ステータスを取得するには、Amazon Simple Queue Service (Amazon SQS) キューまたは AWS Lambda 関数を使用できます。完了ステータスを取得したら、GetLabelDetection などの Get オペレーションを呼び出してリクエストの結果を取得します。
次の図表は、Amazon S3 バケットに保存されているビデオ内のラベルを検出するプロセスを示しています。この図では、Amazon SQS キューが Amazon SNS トピックから完了ステータスを取得しています。または、 AWS Lambda 関数を使用することもできます。
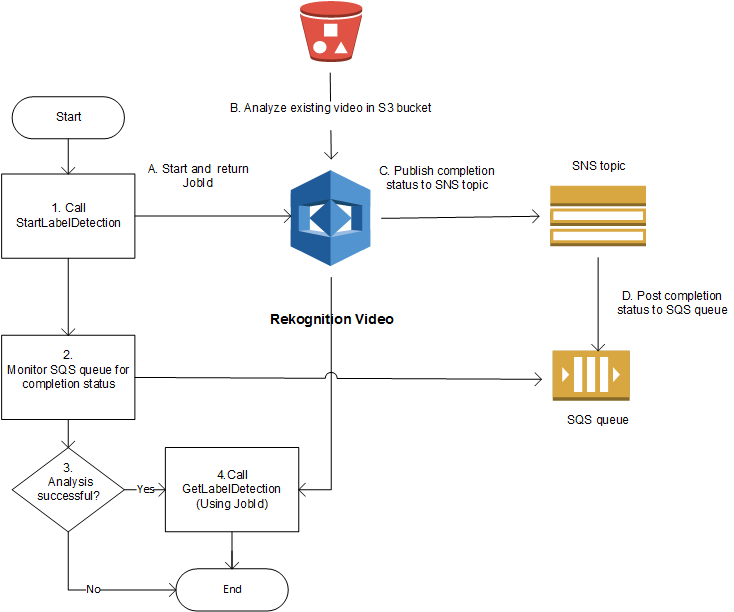
このプロセスは、他の Amazon Rekognition Video オペレーションでも同じです。以下の表は、非ストレージの各 Amazon Rekognition オペレーションの Start オペレーションと Get オペレーションを一覧したものです。
| 検出 | Start オペレーション | Get オペレーション |
|---|---|---|
|
ビデオセグメント |
||
|
ラベル |
||
|
明示的および暗示的なアダルトコンテンツ |
||
|
[テキスト] |
||
|
有名人 |
||
|
顔 |
||
|
人員 |
Get 以外の GetCelebrityRecognition オペレーションの場合、Amazon Rekognition Video は入力ビデオ全体でエンティティ検出時の追跡情報を返します。
Amazon Rekognition Video の使用の詳細については、Amazon Rekognition Video オペレーションを呼び出す を参照してください。Amazon SQS を使用してビデオ分析を行う例については、Java または Python を使用した、Amazon S3 バケットに保存されたビデオの分析 (SDK) を参照してください。 AWS CLI 例については、「」を参照してくださいを使用したビデオの分析 AWS Command Line Interface。
ビデオの形式とストレージ
Amazon Rekognition のオペレーションでは、Amazon S3 バケットに保存されているビデオを分析できます。ビデオ分析オペレーションの全制限のリストについては、「Amazon Rekognition のガイドラインとクォータ」を参照してください。
ビデオは H.264 コーデックでエンコードする必要があります。サポートされているファイル形式は MPEG-4 および MOV です。
コーデックとは、データ圧縮による高速な配信と、受信データからオリジナル形式への解凍を可能にするソフトウェアまたはハードウェアです。H.264 コーデックは、ビデオコンテンツの記録、圧縮、配信に広く使われています。1 つのビデオ形式には 1 つ以上のコーデックを含めることができます。MOV または MPEG-4 形式のビデオファイルが Amazon Rekognition Video で動作しない場合、H.264 コーデックがビデオのエンコードに使われているかどうかを確認してください。
オーディオデータを分析する Amazon Rekognition Video API は、AAC オーディオコーデックのみをサポートします。
保存済みビデオの最大ファイルサイズは 10 GB です。
人物の検索
コレクションに保存された顔のメタデータを使ってビデオ内の人物を検索できます。例えば、アーカイブされたビデオから特定の人物や複数の人物を検索できます。IndexFaces オペレーションを使用して、ソースイメージの顔のメタデータをコレクションに保存します。次に StartFaceSearch を使用して、コレクション内の顔の検索を非同期で開始します。検索結果の取得には、GetFaceSearch を使用します。詳細については、「 保存したビデオでの顔の検索」を参照してください。人物の検索は、代表的なストレージベースの Amazon Rekognition オペレーションです。詳細については、「ストレージ型 API オペレーション」を参照してください。
ストリーミングビデオ内の人物を検索することもできます。詳細については、「ストリーミングビデオイベントの操作」を参照してください。
