기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
검색 및 응답 생성을 구성하고 사용자 지정하여 응답의 관련성을 더욱 개선할 수 있습니다. 예를 들어, 문서 메타데이터 필드/속성에 필터를 적용하여 가장 최근에 업데이트된 문서나 최근 수정 시간이 있는 문서를 사용하도록 할 수 있습니다.
콘솔 또는 API에서 이러한 구성이 어떻게 적용되는지 자세히 알아보려면 다음 주제를 살펴보세요.
지식 기반을 쿼리하면 Amazon Bedrock은 기본적으로 최대 5개의 결과를 반환합니다. 각 결과는 소스 청크에 해당합니다.
이 파라미터는 반환할 최대 결과 수를 설정하므로 응답의 실제 결과 수는 지정된 numberOfResults 값보다 작을 수 있습니다. 청킹 전략에 대한 계층적 청킹을 구성한 경우 numberOfResults 파라미터는 지식 기반에서 검색할 하위 청크 수에 매핑됩니다. 동일한 상위 청크를 공유하는 하위 청크는 최종 응답에서 상위 청크로 대체되므로 반환되는 결과 수는 요청된 양보다 적을 수 있습니다.
반환할 최대 결과 수를 수정하려면 원하는 방법에 해당하는 탭을 선택하고 다음 단계를 따릅니다.
- Console
-
지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 구성 창에서 소스 청크 섹션을 확장하고 반환할 최대 소스 청크 수를 입력합니다.
- API
Retrieve 또는 RetrieveAndGenerate 요청을 수행할 때 KnowledgeBaseRetrievalConfiguration 객체에 매핑된 retrievalConfiguration 필드를 포함합니다. 이 필드의 위치를 확인하려면 API 참조의 Retrieve 및 RetrieveAndGenerate 요청 본문을 참조하세요.
다음 JSON 객체는 반환할 최대 결과 수를 설정하는 데 KnowledgeBaseRetrievalConfiguration 객체에 필요한 최소 필드를 보여줍니다.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": number
}
}
numberOfResults 필드에 반환할 검색된 결과의 최대 수를 지정합니다(허용된 값 범위는 KnowledgeBaseRetrievalConfiguration의 numberOfResults 필드 참조).
검색 유형은 지식 기반에서 데이터 소스를 쿼리하는 방법을 정의합니다. 다음과 같은 검색 유형을 사용할 수 있습니다.
하이브리드 검색은 필터링 가능한 텍스트 필드가 포함된 Amazon RDS, Amazon OpenSearch Serverless 및 MongoDB 벡터 스토어에 대해서만 지원됩니다. 다른 벡터 스토어를 사용하거나 벡터 스토어에 필터링 가능한 텍스트 필드가 없는 경우 쿼리는 시맨틱 검색을 사용합니다.
검색 유형을 정의하는 방법을 알아보려면 원하는 방법에 해당하는 탭을 선택하고 다음 단계를 따릅니다.
- Console
-
지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 구성 창을 열 때 검색 유형 섹션을 확장하고 기본 검색 재정의를 켠 다음 옵션을 선택합니다.
- API
Retrieve 또는 RetrieveAndGenerate 요청을 수행할 때 KnowledgeBaseRetrievalConfiguration 객체에 매핑된 retrievalConfiguration 필드를 포함합니다. 이 필드의 위치를 확인하려면 API 참조의 Retrieve 및 RetrieveAndGenerate 요청 본문을 참조하세요.
다음 JSON 객체는 검색 유형 구성을 설정하는 데 필요한 KnowledgeBaseRetrievalConfiguration 객체의 최소 필드를 보여줍니다.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"overrideSearchType": "HYBRID | SEMANTIC"
}
}
overrideSearchType 필드에 검색 유형을 지정합니다. 다음과 같은 옵션이 있습니다.
-
값을 지정하지 않으면 Amazon Bedrock이 벡터 스토어 구성에 가장 적합한 검색 전략을 결정합니다.
-
HYBRID – Amazon Bedrock이 벡터 임베딩과 원시 텍스트를 모두 사용하여 지식 기반을 쿼리합니다.
-
SEMANTIC – Amazon Bedrock이 벡터 임베딩을 사용하여 지식 기반을 쿼리합니다.
- Console
-
지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 구성 창을 열 때 스트리밍 기본 설정 섹션을 확장하고 스트림 응답을 켭니다.
- API
-
응답을 스트리밍하려면 RetrieveAndGenerateStream API를 사용합니다. 필드 작성에 대한 자세한 내용은 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성의 API 탭을 참조하세요.
필터를 문서 필드/속성에 적용하여 응답의 관련성을 더욱 개선할 수 있습니다. 데이터 소스에는 필터링할 문서 메타데이터 속성/필드가 포함될 수 있으며 임베딩에 포함할 필드를 지정할 수 있습니다.
예를 들어 'epoch_modification_time'은 문서가 마지막으로 업데이트된 1970년 1월 1일(UTC) 이후 초 단위의 시간을 나타냅니다. 'epoch_modification_time'이 특정 수보다 큰 최신 데이터를 기준으로 필터링할 수 있습니다. 이러한 최신 문서를 쿼리에 사용할 수 있습니다.
지식 기반을 쿼리할 때 필터를 사용하려면 지식 기반이 다음 요구 사항을 충족하는지 확인합니다.
-
데이터 소스 커넥터를 구성할 때 대부분의 커넥터는 문서의 기본 메타데이터 필드를 크롤링합니다. Amazon S3 버킷을 데이터 소스로 사용하는 경우, 버킷에는 연결된 파일 또는 문서에 대해 하나 이상의 fileName.extension.metadata.json이 포함되어야 합니다. 메타데이터 파일 구성에 대한 자세한 내용은 연결 구성의 문서 메타데이터 필드를 참조하세요.
-
지식 베이스의 벡터 인덱스가 Amazon OpenSearch Serverless 벡터 스토어에 있는 경우, 벡터 인덱스가 faiss 엔진으로 구성되어 있는지 확인합니다. 벡터 인덱스가 nmslib 엔진으로 구성되어 있다면 다음 중 하나를 수행해야 합니다.
-
지식 기반이 S3 벡터 버킷에서 벡터 인덱스를 사용하는 경우 startsWith 및 stringContains 필터를 사용할 수 없습니다.
-
Amazon Aurora 데이터베이스 클러스터의 기존 벡터 인덱스에 메타데이터를 추가하는 경우 사용자 지정 메타데이터 열의 필드 이름을 제공하여 모든 메타데이터를 단일 열에 저장하는 것이 좋습니다. 데이터 수집 중에 이 열은 데이터 소스의 메타데이터 파일에 있는 모든 정보를 채우는 데 사용됩니다. 이 필드를 제공하기로 선택한 경우 이 열에 인덱스를 생성해야 합니다.
-
콘솔에서 새 지식 기반을 생성하고 Amazon Bedrock이 Amazon Aurora 데이터베이스를 구성하도록 하면 자동으로 단일 열을 생성하고 메타데이터 파일의 정보로 채웁니다.
-
벡터 스토어에서 다른 벡터 인덱스를 생성하도록 선택한 경우 메타데이터 파일의 정보를 저장할 사용자 지정 메타데이터 필드 이름을 제공해야 합니다. 이 필드 이름을 제공하지 않는 경우 파일의 각 메타데이터 속성에 대한 열을 생성하고 데이터 유형(텍스트, 숫자 또는 부울)을 지정해야 합니다. 예를 들어, genre 속성이 데이터 소스에 있는 경우 genre라는 열을 추가하고 text를 데이터 유형으로 지정합니다. 수집 과정에서 이러한 별도의 열은 해당 속성 값으로 채워집니다.
데이터 소스에 PDF 문서가 있고 벡터 스토어에 Amazon OpenSearch Serverless를 사용하는 경우: Amazon Bedrock Knowledge Bases는 문서 페이지 번호를 생성하고 x-amz-bedrock-kb-document-page-number라는 메타데이터 필드/속성에 저장합니다. 문서에 청킹을 선택하지 않으면 메타데이터 필드에 저장된 페이지 번호가 지원되지 않습니다.
다음 필터링 연산자를 사용하여 쿼리에서 결과를 필터링할 수 있습니다.
필터링 연산자
| 연산자 |
콘솔 |
API 필터 이름 |
지원되는 속성 데이터 유형 |
필터링 결과 |
| 같음 |
= |
같음 |
문자열, 숫자, 부울 |
속성이 사용자가 제공한 값과 일치합니다. |
| 같지 않음 |
!= |
notEquals |
문자열, 숫자, 부울 |
속성이 사용자가 제공한 값과 일치하지 않습니다. |
| 보다 큼 |
> |
greaterThan |
number |
속성이 사용자가 제공한 값보다 큽니다. |
| 크거나 같음 |
>= |
greaterThanOrEquals |
number |
속성이 사용자가 제공한 값보다 크거나 같습니다. |
| 보다 작음 |
< |
lessThan |
number |
속성이 사용자가 제공한 값보다 작습니다. |
| 작거나 같음 |
<= |
lessThanOrEquals |
number |
속성이 사용자가 제공한 값보다 작거나 같습니다. |
| 있음 |
: |
in |
문자열 목록 |
속성이 사용자가 제공한 목록에 있습니다(현재 Amazon OpenSearch Serverless 및 Neptune Analytics GraphRAG 벡터 스토어에서 가장 잘 지원됨) |
| 없음 |
!: |
notIn |
문자열 목록 |
속성이 사용자가 제공한 목록에 없습니다(현재 Amazon OpenSearch Serverless 및 Neptune Analytics GraphRAG 벡터 스토어에서 가장 잘 지원됨) |
| 문자열 나열 |
사용할 수 없음 |
stringContains |
문자열 |
속성은 문자열이어야 합니다. 속성 이름은 키와 일치하며 값이 하위 문자열로 제공한 값을 포함하는 문자열이거나 하위 문자열로 제공한 값을 포함하는 멤버가 있는 목록입니다(현재 Amazon OpenSearch Serverless 벡터 스토어에서 가장 잘 지원됨. Neptune Analytics GraphRAG 벡터 스토어는 문자열 변형을 지원하지만 이 필터의 목록 변형은 지원하지 않습니다). |
| 목록 나열 |
사용할 수 없음 |
listContains |
문자열 |
속성은 반드시 문자열 목록이어야 합니다. 속성 이름은 키와 일치하며 값이 멤버 중 하나로 제공한 값이 포함된 목록입니다(현재 Amazon OpenSearch Serverless 벡터 스토어에서 가장 잘 지원됨). |
필터링 연산자를 결합하려면 다음 논리 연산자를 사용할 수 있습니다.
논리 연산자
| 연산자 |
콘솔 |
API 필터 필드 이름 |
필터링 결과 |
| 및 |
및 |
andAll |
결과가 그룹의 모든 필터링 표현식을 충족합니다. |
| 또는 |
또는 |
orAll |
결과가 그룹의 필터링 표현식 중 하나 이상을 충족합니다. |
메타데이터를 사용하여 결과를 필터링하는 방법을 알아보려면 원하는 방법에 해당하는 탭을 선택하고 다음 단계를 따릅니다.
- Console
-
지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 구성 창을 열면 필터 섹션이 표시됩니다. 다음 절차에서는 다양한 사용 사례를 설명합니다.
-
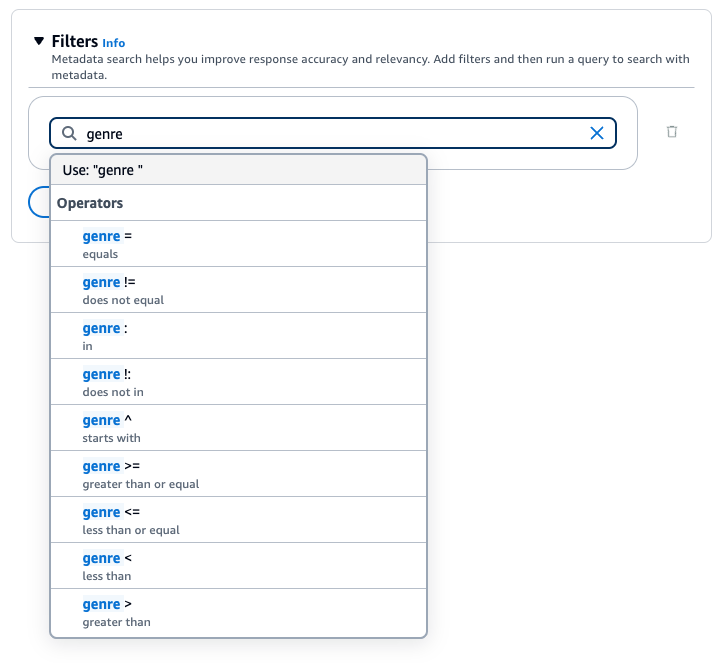
필터를 추가하려면 상자에 메타데이터 속성, 필터링 연산자, 값을 입력하여 필터링 표현식을 만듭니다. 표현식의 각 부분은 공백으로 구분합니다. Enter 키를 눌러 필터를 추가합니다.
허용되는 필터링 연산자 목록은 위의 필터링 연산자 테이블을 참조하세요. 메타데이터 속성 뒤에 공백을 추가할 때 필터링 연산자 목록을 확인할 수도 있습니다.
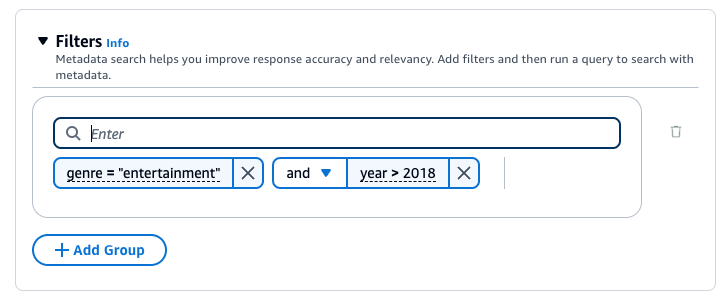
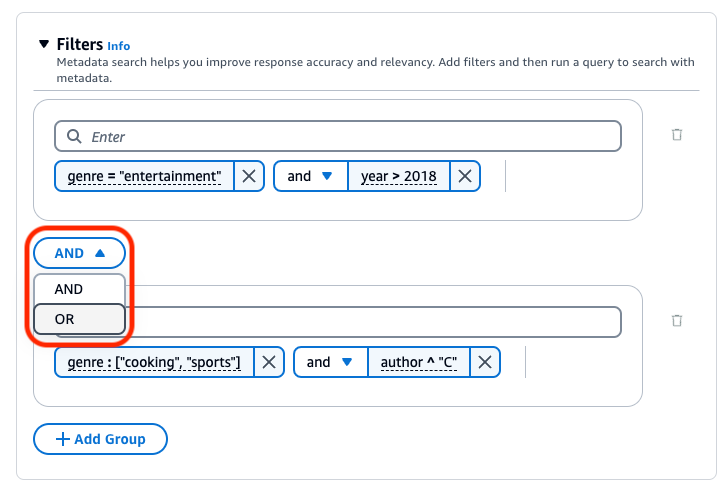
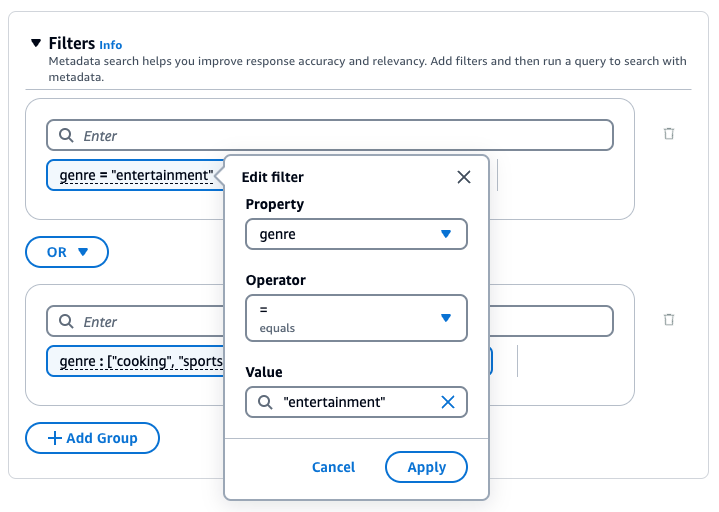
예를 들어, 값이 "entertainment"인 genre 메타데이터 속성이 포함된 소스 문서의 결과를 필터링하려면 genre = "entertainment" 필터를 추가합니다.
-
또 다른 필터를 추가하려면 상자에 다른 필터링 표현식을 입력하고 Enter 키를 누릅니다. 그룹에는 최대 5개의 필터를 추가할 수 있습니다.
-
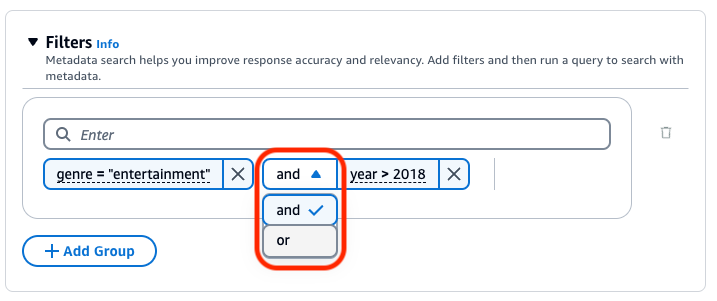
기본적으로 쿼리는 사용자가 제공하는 모든 필터링 표현식을 충족하는 결과를 반환합니다. 필터링 표현식 중 하나 이상을 충족하는 결과를 반환하려면 두 필터링 연산 사이에 있는 and 드롭다운 메뉴를 선택하고 or를 선택합니다.
-
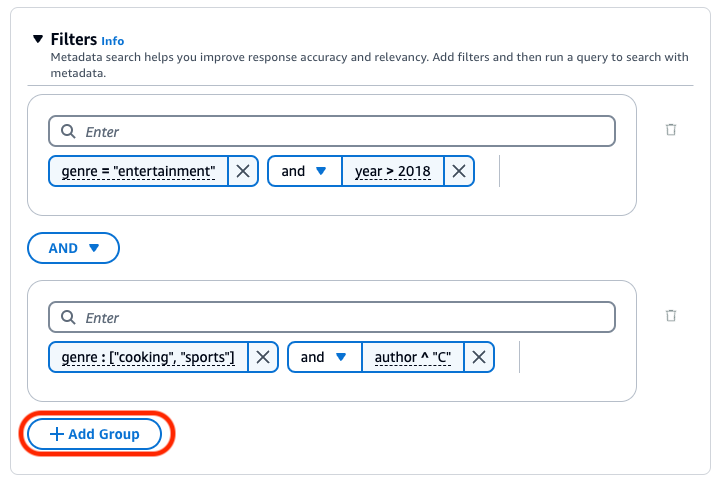
여러 논리 연산자를 결합하려면 + 그룹 추가를 선택하여 필터 그룹을 추가합니다. 새 그룹에 필터링 표현식을 입력합니다. 최대 5개의 필터 그룹을 추가할 수 있습니다.
-
모든 필터링 그룹 사이에 사용되는 논리 연산자를 변경하려면 두 필터 그룹 사이의 AND 드롭다운 메뉴를 선택하고 OR를 선택합니다.
-
필터를 편집하려면 필터를 선택하고 필터링 연산을 수정한 다음 적용을 선택합니다.
-
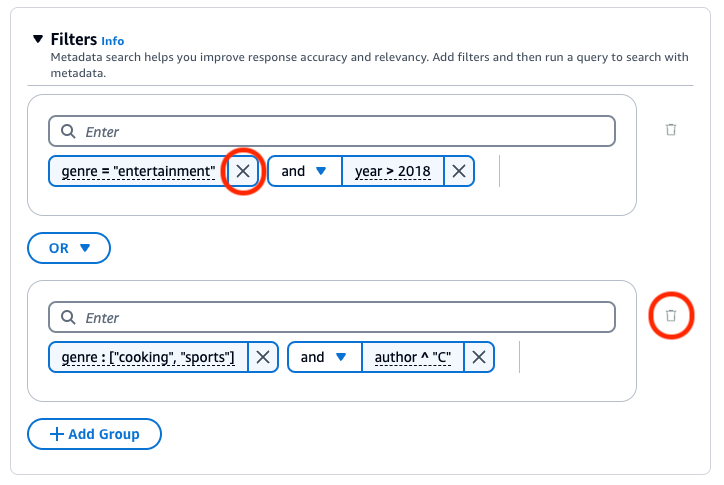
필터 그룹을 제거하려면 그룹 옆의 휴지통 아이콘(
 )을 선택합니다. 필터를 제거하려면 필터 옆의 삭제 아이콘(
)을 선택합니다. 필터를 제거하려면 필터 옆의 삭제 아이콘(
 )을 선택합니다.
)을 선택합니다.
다음 이미지는 장르가 "entertainment"이고 2018년 이후에 작성된 모든 문서와 장르가 "cooking" 또는 "sports"이고 작성자가 "C"로 시작하는 문서를 반환하는 필터 구성의 예제를 보여줍니다.
- API
Retrieve 또는 RetrieveAndGenerate 요청을 수행할 때 KnowledgeBaseRetrievalConfiguration 객체에 매핑된 retrievalConfiguration 필드를 포함합니다. 이 필드의 위치를 확인하려면 API 참조의 Retrieve 및 RetrieveAndGenerate 요청 본문을 참조하세요.
다음 JSON 객체는 다양한 사용 사례에 대한 필터를 설정하는 데 KnowledgeBaseRetrievalConfiguration 객체에 필요한 최소 필드를 보여줍니다.
-
하나의 필터링 연산자를 사용합니다(위의 필터링 연산자 테이블 참조).
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
}
}
}
-
논리 연산자(위의 논리 연산자 테이블 참조)를 사용하여 최대 5개까지 결합합니다.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
}
}
}
-
논리 연산자를 사용하여 최대 5개의 필터링 연산자를 필터 그룹으로 결합하고, 두 번째 논리 연산자를 사용하여 해당 필터 그룹을 다른 필터링 연산자와 결합합니다.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
],
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
]
}
}
}
-
최대 5개의 필터 그룹을 다른 논리 연산자 내에 임베딩하여 결합합니다. 한 단계의 임베딩을 생성할 수 있습니다.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
],
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
]
}
}
}
다음 테이블은 사용할 수 있는 필터 유형을 설명합니다.
| Field |
지원되는 값 데이터 유형 |
필터링 결과 |
equals |
문자열, 숫자, 부울 |
속성이 사용자가 제공한 값과 일치합니다. |
notEquals |
문자열, 숫자, 부울 |
속성이 사용자가 제공한 값과 일치하지 않습니다. |
greaterThan |
number |
속성이 사용자가 제공한 값보다 큽니다. |
greaterThanOrEquals |
number |
속성이 사용자가 제공한 값보다 크거나 같습니다. |
lessThan |
number |
속성이 사용자가 제공한 값보다 작습니다. |
lessThanOrEquals |
number |
속성이 사용자가 제공한 값보다 작거나 같습니다. |
in |
문자열 목록 |
속성이 사용자가 제공한 목록에 있습니다. |
notIn |
문자열 목록 |
속성이 사용자가 제공한 목록에 없습니다. |
startsWith |
문자열 |
속성이 사용자가 제공한 문자열로 시작됩니다(Amazon OpenSearch Serverless 벡터 스토어에 대해서만 지원) |
필터 유형을 결합하려면 다음 논리 연산자 중 하나를 사용할 수 있습니다.
| Field |
매핑 |
필터링 결과 |
andAll |
최대 5개의 필터 유형 목록 |
결과가 그룹의 모든 필터링 표현식을 충족합니다. |
orAll |
최대 5개의 필터 유형 목록 |
결과가 그룹의 필터링 표현식 중 하나 이상을 충족합니다. |
예제는 쿼리 보내기 및 필터(Retrieve) 포함 및 쿼리 보내기 및 필터(RetrieveAndGenerate) 포함을 참조하세요.
Amazon Bedrock Knowledge Bases는 사용자 쿼리 및 메타데이터 스키마를 기반으로 검색 필터를 생성하고 적용합니다.
암시적 메타데이터 필터링은 Anthropic Claude 모델에서 지원됩니다. 지원되는 모델에 대한 자세한 내용은 모델을 한눈에 참조하세요.
implicitFilterConfiguration은 Retrieve 요청 본문의 vectorSearchConfiguration에 지정됩니다. 여기에는 다음 필드가 포함될 수 있습니다.
다음은 metadataAttributes의 배열에 추가할 수 있는 메타데이터 스키마의 예입니다.
[
{
"key": "company",
"type": "STRING",
"description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc"
},
{
"key": "ticker",
"type": "STRING",
"description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL"
},
{
"key": "pe_ratio",
"type": "NUMBER",
"description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper."
},
{
"key": "is_us_company",
"type": "BOOLEAN",
"description": "Indicates whether the company is a US company."
},
{
"key": "tags",
"type": "STRING_LIST",
"description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc"
}
]
사용 사례 및 책임 있는 AI 정책을 위한 지식 기반 보호 장치를 구현할 수 있습니다. 다양한 사용 사례에 맞게 조정된 여러 가드레일을 만들고 이를 여러 요청 및 응답 조건에 적용하여 일관된 사용자 환경을 제공하고 지식 기반 전반에 안전 제어를 표준화할 수 있습니다. 거부된 주제와 콘텐츠 필터를 구성하여 모델 입력 및 응답에서 바람직하지 않은 주제와 유해한 콘텐츠를 차단할 수 있습니다. 자세한 내용은 Amazon Bedrock Guardrails를 사용하여 유해한 콘텐츠 감지 및 필터링 섹션을 참조하세요.
현재 Claude 3 Sonnet 및 Haiku에서는 가드레일을 지식 기반에 대한 컨텍스트 근거와 함께 사용할 수 없습니다.
일반적인 프롬프트 엔지니어링 지침은 프롬프트 엔지니어링 개념 섹션을 참조하세요.
원하는 방법의 탭을 선택한 후 다음 단계를 따릅니다.
- Console
-
지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 테스트 창에서 응답 생성을 켭니다. 그런 다음 구성 창에서 가드레일 섹션을 확장합니다.
-
가드레일 섹션에서 가드레일의 이름과 버전을 선택합니다. 선택한 가드레일 및 버전의 세부 정보를 보려면 보기를 선택합니다.
또는 가드레일 링크를 선택하여 새 가드레일을 만들 수 있습니다.
-
편집을 마쳤으면 변경 사항 저장을 선택합니다. 저장하지 않고 종료하려면 변경 사항 취소를 선택합니다.
- API
-
RetrieveAndGenerate 요청을 수행할 때 generationConfiguration에 guardrailConfiguration 필드를 포함시켜 요청에 가드레일을 사용할 수 있습니다. 이 필드의 위치를 보려면 API 참조의 RetrieveAndGenerate 요청 본문을 참조하세요.
다음 JSON 객체는 GenerationConfiguration에서 guardrailConfiguration을 설정하는 데 필요한 최소 필드를 보여줍니다.
"generationConfiguration": {
"guardrailConfiguration": {
"guardrailId": "string",
"guardrailVersion": "string"
}
}
선택한 가드레일의 guardrailId 및 guardrailVersion을 지정합니다.
리랭커 모델을 사용하여 지식 기반 쿼리의 결과 순위를 다시 매길 수 있습니다. 지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 구성 창을 열 때 순위 조정 섹션을 확장합니다. 리랭커 모델을 선택하고, 필요한 경우 권한을 업데이트하고, 추가 옵션을 수정합니다. 프롬프트를 입력하고 실행을 선택하여 순위를 다시 매긴 후 결과를 테스트합니다.
쿼리 분해는 복잡한 쿼리를 더 작고 관리 가능한 하위 쿼리로 세분화하는 데 사용되는 기법입니다. 이 접근 방식은 특히 초기 쿼리가 다면적이거나 너무 광범위한 경우 더 정확하고 관련성 있는 정보를 검색하는 데 도움이 될 수 있습니다. 이 옵션을 활성화하면 지식 기반에 대해 여러 쿼리가 실행되어 최종 응답이 더 정확해질 수 있습니다.
예를 들어, “2022 FIFA 월드컵에서 아르헨티나와 프랑스 중 어디가 더 점수가 높았나요?”와 같은 질문에 대해 Amazon Bedrock Knowledge Bases는 최종 답변을 생성하기 전에 먼저 다음과 같은 하위 쿼리를 생성할 수 있습니다.
-
2022년 FIFA 월드컵 결승전에서 아르헨티나는 몇 골을 득점했나요?
-
2022 FIFA 월드컵 결승전에서 프랑스는 몇 골을 득점했나요?
- Console
-
-
데이터 소스를 생성 및 동기화하거나 기존 지식 기반을 사용합니다.
-
테스트 창으로 이동하여 구성 패널을 엽니다.
-
쿼리 분해를 활성화합니다.
- API
-
POST /retrieveAndGenerate HTTP/1.1
Content-type: application/json
{
"input": {
"text": "string"
},
"retrieveAndGenerateConfiguration": {
"knowledgeBaseConfiguration": {
"orchestrationConfiguration": { // Query decomposition
"queryTransformationConfiguration": {
"type": "string" // enum of QUERY_DECOMPOSITION
}
},
...}
}
정보 검색을 기반으로 응답을 생성할 때 추론 파라미터를 사용하여 추론 과정에서 모델의 동작을 더 잘 제어하고 모델의 출력에 영향을 미칠 수 있습니다.
추론 파라미터를 수정하는 방법을 알아보려면 원하는 방법에 해당하는 탭을 선택하고 다음 단계를 따릅니다.
- Console
-
지식 기반을 쿼리할 때 추론 파라미터를 수정하는 방법 - 지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따르세요. 구성 창을 열면 추론 파라미터 섹션이 표시됩니다. 필요에 따라 파라미터를 수정합니다.
문서와의 채팅에서 추론 파라미터를 수정하는 방법 - 지식 기반이 구성되지 않은 문서와의 채팅 섹션의 단계를 따르세요. 구성 창에서 추론 파라미터 섹션을 확장하고 필요에 따라 파라미터를 수정합니다.
- API
-
RetrieveAndGenerate API에 대한 직접 호출에서 모델 파라미터를 제공합니다. 지식 기반을 쿼리하는 경우 knowledgeBaseConfiguration의 inferenceConfig 필드에, 문서와의 채팅의 경우 externalSourcesConfiguration의 필드에 추론 파라미터를 제공하여 모델을 사용자 지정합니다.
inferenceConfig 필드 내에는 다음과 같은 파라미터가 포함된 textInferenceConfig 필드가 있습니다.
-
temperature
-
topP
-
maxTokenCount
-
stopSequences
externalSourcesConfiguration 및 knowledgeBaseConfiguration의 inferenceConfig 필드에서 다음 파라미터를 사용하여 모델을 사용자 지정할 수 있습니다.
-
temperature
-
topP
-
maxTokenCount
-
stopSequences
이러한 각 파라미터의 함수에 대한 자세한 설명은 추론 파라미터를 사용하여 응답 생성에 영향을 주는 방법 섹션을 참조하세요.
또한 additionalModelRequestFields 맵을 통해 textInferenceConfig에서 지원하지 않는 사용자 지정 파라미터를 제공할 수도 있습니다. 이 인수를 사용하여 특정 모델에 고유한 파라미터를 제공할 수 있습니다. 고유한 파라미터에 대한 내용은 파운데이션 모델의 추론 요청 파라미터 및 응답 필드 섹션을 참조하세요.
파라미터가 textInferenceConfig에서 생략된 경우 기본값이 사용됩니다. textInferneceConfig에서 인식되지 않는 파라미터는 무시되지만, AdditionalModelRequestFields에서 인식되지 않는 파라미터는 예외로 이어질 수 있습니다.
additionalModelRequestFields 및 TextInferenceConfig 모두에 동일한 파라미터가 있는 경우 검증 예외가 발생합니다.
RetrieveAndGenerate에서 모델 파라미터 사용
다음은 RetrieveAndGenerate 요청 본문의 generationConfiguration에 해당하는 inferenceConfig 및 additionalModelRequestFields 구조의 예제입니다.
"inferenceConfig": {
"textInferenceConfig": {
"temperature": 0.5,
"topP": 0.5,
"maxTokens": 2048,
"stopSequences": ["\nObservation"]
}
},
"additionalModelRequestFields": {
"top_k": 50
}
다음 예제에서는 temperature를 0.5로, top_p를 0.5로, maxTokens를 2048로 설정하고, 생성된 응답에서 문자열 ‘\nObservation’을 발견하면 생성을 중지하고 사용자 지정 top_k 값인 50을 전달합니다.
지식 기반을 쿼리하고 응답 생성을 요청할 때, Amazon Bedrock는 지침과 컨텍스트를 사용자 쿼리와 결합하는 프롬프트 템플릿을 사용하여 응답 생성을 위해 모델로 전송되는 생성 프롬프트를 구성합니다. 사용자의 프롬프트를 검색 쿼리로 변환하는 오케스트레이션 프롬프트를 사용자 지정할 수 있습니다. 다음과 같은 도구를 사용하여 프롬프트 템플릿을 엔지니어링할 수 있습니다.
-
프롬프트 자리 표시자 - Amazon Bedrock Knowledge Bases에 사전 정의된 변수로, 지식 기반 쿼리 과정에서 런타임에 동적으로 채워집니다. 이러한 자리 표시자는 시스템 프롬프트에서 $ 기호로 둘러싸여 있습니다. 다음 목록은 사용할 수 있는 자리 표시자를 설명합니다.
$output_format_instructions$ 자리 표시자는 인용이 응답에 표시되기 위한 필수 필드입니다.
| 변수 |
프롬프트 템플릿 |
대체 |
모델 |
필수 |
| $query$ |
오케스트레이션, 생성 |
지식 기반에 전송된 사용자 쿼리로 대체됩니다. |
Anthropic Claude Instant, Anthropic Claude v2.x |
예 |
| Anthropic Claude 3 Sonnet |
아니요(모델 입력에 자동으로 포함됨) |
| $search_results$ |
생성 |
사용자 쿼리에 대해 검색된 결과로 대체됩니다. |
모두 |
예 |
| $output_format_instructions$ |
오케스트레이션 |
응답 생성 및 인용 형식 지정에 대한 기본 지침으로 대체됩니다. 모델에 따라 다릅니다. 자체 서식 지정 지침을 정의할 경우 이 자리 표시자를 제거하는 것이 좋습니다. 이 자리 표시자가 없으면 응답에 인용이 포함되지 않습니다. |
모두 |
예 |
| $current_time$ |
오케스트레이션, 생성 |
현재 시간으로 대체됩니다. |
모두 |
아니요 |
-
XML 태그 - Anthropic 모델은 XML 태그를 사용하여 프롬프트를 구성하고 설명할 수 있도록 지원합니다. 최적의 결과를 얻으려면 설명형 태그 이름을 사용합니다. 예를 들어, 기본 시스템 프롬프트에는 이전에 질문한 데이터베이스 설명에 사용된 <database> 태그가 표시됩니다. 자세한 내용을 알아보려면 Anthropic 사용 설명서의 XML 태그 사용을 참조하세요.
일반적인 프롬프트 엔지니어링 지침은 프롬프트 엔지니어링 개념 섹션을 참조하세요.
원하는 방법의 탭을 선택한 후 다음 단계를 따릅니다.
- Console
-
지식 기반 쿼리 및 데이터 검색 또는 지식 기반 쿼리 및 검색된 데이터를 기반으로 응답 생성 섹션의 콘솔 단계를 따릅니다. 테스트 창에서 응답 생성을 켭니다. 그런 다음 구성 창에서 지식 기반 프롬프트 템플릿 섹션을 확장합니다.
-
편집을 선택합니다.
-
필요에 따라 텍스트 편집기에서 프롬프트 자리 표시자 및 XML 태그를 비롯한 시스템 프롬프트를 편집합니다. 기본 프롬프트 템플릿으로 되돌리려면 기본값으로 재설정을 선택합니다.
-
편집을 마쳤으면 변경 사항 저장을 선택합니다. 시스템 프롬프트를 저장하지 않고 종료하려면 변경 사항 취소를 선택합니다.
- API
-
RetrieveAndGenerate 요청을 수행할 때 GenerationConfiguration 객체에 매핑된 generationConfiguration 필드를 포함합니다. 이 필드의 위치를 보려면 API 참조의 RetrieveAndGenerate 요청 본문을 참조하세요.
다음 JSON 객체는 반환할 검색된 결과의 최대 수를 설정하는 데 GenerationConfiguration 객체에 필요한 최소 필드를 보여줍니다.
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": "string"
}
}
필요에 따라 textPromptTemplate 필드에 프롬프트 자리 표시자 및 XML 태그를 포함하여 사용자 지정 프롬프트 템플릿을 입력합니다. 시스템 프롬프트에서 허용되는 최대 문자 수는 GenerationConfiguration의 textPromptTemplate 필드를 참조하세요.