기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
RunBooks
다음 섹션에는 발생할 수 있는 문제, 이를 감지하는 방법, 문제 해결 방법에 대한 제안이 포함되어 있습니다.
설치 문제
주제
- RES를 설치한 후 사용자 지정 도메인을 설정하려고 함
- AWS CloudFormation 스택이 "WaitCondition 수신 실패 메시지와 함께 생성되지 않습니다. Error:States.TaskFailed"
- 스택이 성공적으로 생성된 후 AWS CloudFormation 이메일 알림이 수신되지 않음
- 실패한 상태의 인스턴스 순환 또는 vdc 컨트롤러
- 종속 객체 오류로 인해 환경 CloudFormation 스택이 삭제되지 않음
- 환경 생성 중 CIDR 블록 파라미터에 오류가 발생했습니다.
- 환경 생성 중 CloudFormation 스택 생성 실패
- AdDomainAdminNode CREATE_FAILED에서 외부 리소스(데모) 스택 생성 실패
........................
RES를 설치한 후 사용자 지정 도메인을 설정하려고 함
참고
사전 조건: 이러한 단계를 수행하기 전에 Secrets Manager 보안 암호에 인증서 및 PrivateKey 콘텐츠를 저장해야 합니다.
웹 클라이언트에 인증서 추가
-
외부-alb 로드 밸런서의 리스너에 연결된 인증서를 업데이트합니다.
-
AWS 콘솔의 EC2 > 로드 밸런싱 > 로드 밸런서에서 RES 외부 로드 밸런서로 이동합니다.
-
명명 규칙를 따르는 로드 밸런서를 검색합니다
<env-name>-external-alb -
로드 밸런서에 연결된 리스너를 확인합니다.
-
기본 SSL/TLS 인증서가 새 인증서 세부 정보와 연결된 리스너를 업데이트합니다.
-
변경 내용을 저장합니다.
-
-
클러스터 설정 테이블에서:
-
DynamoDB -> 테이블 ->에서 클러스터 설정 테이블을 찾습니다
<env-name>.cluster-settings -
항목 탐색 및 속성별 필터링 - 이름 "key", 유형 "string", 조건 "contains", 값 "external_alb"로 이동합니다.
-
True
cluster.load_balancers.external_alb.certificates.provided로 설정합니다. -
값을 업데이트합니다
cluster.load_balancers.external_alb.certificates.custom_dns_name. 웹 사용자 인터페이스의 사용자 지정 도메인 이름입니다. -
값을 업데이트합니다
cluster.load_balancers.external_alb.certificates.acm_certificate_arn. Amazon Certificate Manager(ACM)에 저장된 해당 인증서의 Amazon 리소스 이름(ARN)입니다.
-
-
외부 alb 로드 밸런서의 DNS 이름을 가리키도록 웹 클라이언트에 대해 생성한 해당 Route53 하위 도메인 레코드를 업데이트합니다
<env-name>-external-alb. -
SSO가 환경에 이미 구성되어 있는 경우 RES 웹 포털의 환경 관리 > 자격 증명 관리 > Single Sign-On > 상태 > 편집 버튼에서 처음 사용한 것과 동일한 입력으로 SSO를 다시 구성합니다.
VDIs에 인증서 추가
-
보안 암호에 다음 태그를 추가하여 보안 암호에 대해 GetSecret 작업을 수행할 수 있는 권한을 RES 애플리케이션에 부여합니다.
-
res:EnvironmentName:<env-name> -
res:ModuleName:virtual-desktop-controller
-
-
클러스터 설정 테이블에서:
-
DynamoDB -> 테이블 ->에서 클러스터 설정 테이블을 찾습니다
<env-name>.cluster-settings -
항목 탐색 및 속성별 필터링 - 이름 "key", 유형 "string", 조건 "contains", 값 "dcv_connection_gateway"로 이동합니다.
-
True
vdc.dcv_connection_gateway.certificate.provided로 설정합니다. -
값을 업데이트합니다
vdc.dcv_connection_gateway.certificate.custom_dns_name. VDI 액세스를 위한 사용자 지정 도메인 이름입니다. -
값을 업데이트합니다
vdc.dcv_connection_gateway.certificate.certificate_secret_arn. 인증서 내용을 포함하는 보안 암호의 ARN입니다. -
값을 업데이트합니다
vdc.dcv_connection_gateway.certificate.private_key_secret_arn. 프라이빗 키 콘텐츠를 보유한 보안 암호의 ARN입니다.
-
-
게이트웨이 인스턴스에 사용되는 시작 템플릿을 업데이트합니다.
-
AWS 콘솔의 EC2 > Auto Scaling > Auto Scaling 그룹에서 Auto Scaling 그룹을 엽니다.
-
RES 환경에 해당하는 게이트웨이 Auto Scaling 그룹을 선택합니다. 이름은 이름 지정 규칙을 따릅니다
<env-name>-vdc-gateway-asg -
세부 정보 섹션에서 시작 템플릿을 찾아 엽니다.
-
세부 정보 > 작업 > 템플릿 수정(새 버전 생성)을 선택합니다.
-
아래로 스크롤하여 고급 세부 정보로 이동합니다.
-
맨 아래로 스크롤하여 사용자 데이터로 이동합니다.
-
CERTIFICATE_SECRET_ARN및 단어를 찾습니다PRIVATE_KEY_SECRET_ARN. 인증서(2.c단계 참조) 및 프라이빗 키(2.d단계 참조) 콘텐츠를 보유한 보안 암호에 지정된 ARNs으로 이러한 값을 업데이트합니다. -
Auto Scaling 그룹이 최근에 생성된 시작 템플릿 버전을 사용하도록 구성되어 있는지 확인합니다(Auto Scaling 그룹 페이지에서).
-
-
가상 데스크톱에 대해 생성한 해당 Route53 하위 도메인 레코드를 업데이트하여 외부 nlb 로드 밸런서의 DNS 이름인를 가리킵니다
<env-name>-external-nlb -
기존 dcv-gateway 인스턴스를 종료
<env-name>-vdc-gateway
........................
AWS CloudFormation 스택이 "WaitCondition 수신 실패 메시지와 함께 생성되지 않습니다. Error:States.TaskFailed"
문제를 식별하려면 라는 Amazon CloudWatch 로그 그룹을 검사합니다<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>. 동일한 이름의 로그 그룹이 여러 개 있는 경우 사용 가능한 첫 번째 로그 그룹을 검사합니다. 로그 내의 오류 메시지는 문제에 대한 자세한 정보를 제공합니다.
참고
파라미터 값에 공백이 없는지 확인합니다.
........................
스택이 성공적으로 생성된 후 AWS CloudFormation 이메일 알림이 수신되지 않음
AWS CloudFormation 스택이 성공적으로 생성된 후 이메일 초대를 받지 못한 경우 다음을 확인합니다.
-
이메일 주소 파라미터가 올바르게 입력되었는지 확인합니다.
이메일 주소가 잘못되었거나 액세스할 수 없는 경우 Research and Engineering Studio 환경을 삭제하고 재배포합니다.
-
Amazon EC2 콘솔에서 순환 인스턴스의 증거를 확인하세요.
<envname>접두사가 종료된 것으로 표시된 후 새 인스턴스로 대체되는 Amazon EC2 인스턴스가 있는 경우 네트워크 또는 Active Directory 구성에 문제가 있을 수 있습니다. -
AWS 고성능 컴퓨팅 레시피를 배포하여 외부 리소스를 생성한 경우 스택에서 VPC, 프라이빗 및 퍼블릭 서브넷과 기타 선택한 파라미터가 생성되었는지 확인합니다.
파라미터 중 하나라도 잘못된 경우 RES 환경을 삭제하고 다시 배포해야 할 수 있습니다. 자세한 내용은 제품 제거 단원을 참조하십시오.
-
자체 외부 리소스와 함께 제품을 배포한 경우 네트워킹 및 Active Directory가 예상 구성과 일치하는지 확인합니다.
인프라 인스턴스가 Active Directory에 성공적으로 조인되었는지 확인하는 것이 중요합니다. 의 단계를 수행하여 문제를 실패한 상태의 인스턴스 순환 또는 vdc 컨트롤러 해결합니다.
........................
실패한 상태의 인스턴스 순환 또는 vdc 컨트롤러
이 문제의 가장 가능한 원인은 리소스(들)가 Active Directory에 연결하거나 조인할 수 없기 때문입니다.
문제를 확인하려면:
-
명령줄에서 vdc 컨트롤러의 실행 중인 인스턴스에서 SSM으로 세션을 시작합니다.
-
sudo su -을(를) 실행합니다. -
systemctl status sssd을(를) 실행합니다.
상태가 비활성 상태이거나 실패했거나 로그에 오류가 표시되면 인스턴스가 Active Directory에 조인할 수 없는 것입니다.
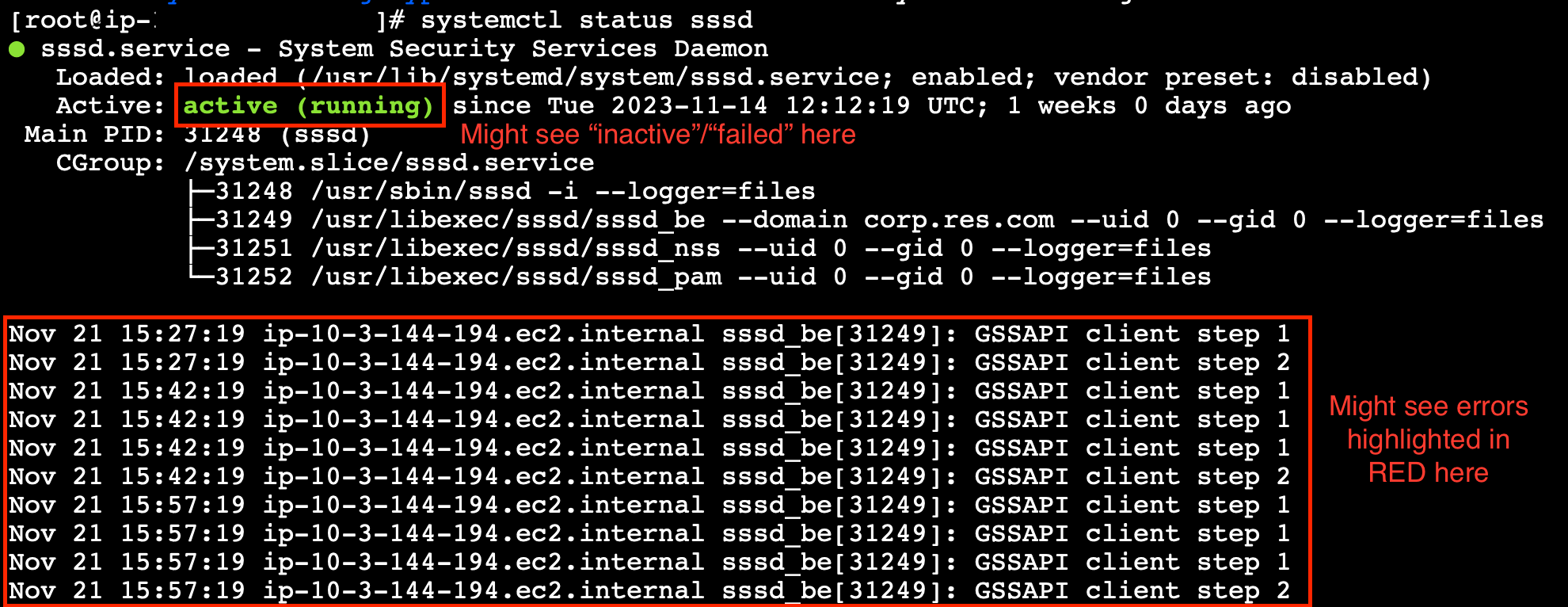
SSM 오류 로그
문제를 해결하려면:
-
동일한 명령줄 인스턴스에서를 실행
cat /root/bootstrap/logs/userdata.log하여 로그를 조사합니다.
이 문제에는 세 가지 근본 원인 중 하나가 있을 수 있습니다.
로그를 검토합니다. 다음과 같은 작업이 여러 번 반복되면 인스턴스가 Active Directory에 조인할 수 없습니다.
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
RES 스택 생성 중에 다음에 대한 파라미터 값이 올바르게 입력되었는지 확인합니다.
-
directoryservice.ldap_connection_uri
-
directoryservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.ou
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
directoryservice.name
-
-
DynamoDB 테이블에서 잘못된 값을 업데이트합니다. 테이블은 DynamoDB 콘솔의 테이블에서 찾을 수 있습니다. 테이블 이름은 여야 합니다
<stack name>.cluster-settings -
테이블을 업데이트한 후 현재 환경 인스턴스를 실행 중인 클러스터 관리자 및 vdc 컨트롤러를 삭제합니다. Auto Scaling은 DynamoDB 테이블의 최신 값을 사용하여 새 인스턴스를 시작합니다.
로그가 Insufficient permissions to modify computer account를 반환하면 스택 생성 중에 입력한 ServiceAccount 이름이 잘못되었을 수 있습니다.
-
AWS 콘솔에서 Secrets Manager를 엽니다.
-
directoryserviceServiceAccountUsername를 찾습니다. 보안 암호는 여야 합니다<stack name>-directoryservice-ServiceAccountUsername -
보안 암호를 열어 세부 정보 페이지를 봅니다. 보안 암호 값에서 보안 암호 값 검색을 선택하고 일반 텍스트를 선택합니다.
-
값이 업데이트된 경우 현재 실행 중인 환경의 클러스터 관리자 및 vdc 컨트롤러 인스턴스를 삭제합니다. Auto Scaling은 Secrets Manager의 최신 값을 사용하여 새 인스턴스를 시작합니다.
로그에가 표시되면 스택 생성 중에 입력한 ServiceAccount 암호Invalid credentials가 잘못되었을 수 있습니다.
-
AWS 콘솔에서 Secrets Manager를 엽니다.
-
directoryserviceServiceAccountPassword를 찾습니다. 보안 암호는 여야 합니다<stack name>-directoryservice-ServiceAccountPassword -
보안 암호를 열어 세부 정보 페이지를 봅니다. 보안 암호 값에서 보안 암호 값 검색을 선택하고 일반 텍스트를 선택합니다.
-
암호를 잊었거나 입력한 암호가 올바른지 확실하지 않은 경우 Active Directory 및 Secrets Manager에서 암호를 재설정할 수 있습니다.
-
에서 암호를 재설정하려면 AWS Managed Microsoft AD:
-
AWS 콘솔을 열고 로 이동합니다 AWS Directory Service.
-
RES 디렉터리의 디렉터리 ID를 선택하고 작업을 선택합니다.
-
사용자 암호 재설정을 선택합니다.
-
ServiceAccount 사용자 이름을 입력합니다.
-
새 암호를 입력하고 암호 재설정을 선택합니다.
-
-
Secrets Manager에서 암호를 재설정하려면:
-
AWS 콘솔을 열고 Secrets Manager로 이동합니다.
-
directoryserviceServiceAccountPassword를 찾습니다. 보안 암호는 여야 합니다<stack name>-directoryservice-ServiceAccountPassword -
보안 암호를 열어 세부 정보 페이지를 봅니다. 보안 암호 값에서 보안 암호 값 검색을 선택한 다음 일반 텍스트를 선택합니다.
-
편집을 선택합니다.
-
ServiceAccount 사용자의 새 암호를 설정하고 저장을 선택합니다.
-
-
-
값을 업데이트한 경우 현재 실행 중인 환경의 클러스터 관리자 및 vdc 컨트롤러 인스턴스를 삭제합니다. Auto Scaling은 최신 값을 사용하여 새 인스턴스를 시작합니다.
........................
종속 객체 오류로 인해 환경 CloudFormation 스택이 삭제되지 않음
와 같은 종속 객체 오류로 인해 <env-name>-vdcvdcdcvhostsecuritygroup, 이는 콘솔을 사용하여 AWS RES 생성 서브넷 또는 보안 그룹으로 시작된 Amazon EC2 인스턴스 때문일 수 있습니다.
문제를 해결하려면 이러한 방식으로 시작된 모든 Amazon EC2 인스턴스를 찾아 종료합니다. 그런 다음 환경 삭제를 재개할 수 있습니다.
........................
환경 생성 중 CIDR 블록 파라미터에 오류가 발생했습니다.
환경을 생성할 때 응답 상태가 [FAILED]인 CIDR 블록 파라미터에 대한 오류가 나타납니다.
오류의 예:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
문제를 해결하기 위해 예상되는 형식은 x.x.x.0/24 또는 x.x.x.0/32입니다.
........................
환경 생성 중 CloudFormation 스택 생성 실패
환경을 생성하려면 일련의 리소스 생성 작업이 필요합니다. 일부 리전에서는 용량 문제가 발생하여 CloudFormation 스택 생성이 실패할 수 있습니다.
이 경우 환경을 삭제하고 생성을 다시 시도합니다. 또는 다른 리전에서 생성을 다시 시도할 수 있습니다.
........................
AdDomainAdminNode CREATE_FAILED에서 외부 리소스(데모) 스택 생성 실패
다음 오류와 함께 데모 환경 스택 생성에 실패하는 경우 인스턴스 시작 후 프로비저닝 중에 예기치 않게 Amazon EC2 패치가 발생했기 때문일 수 있습니다.
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
실패 원인을 확인하려면:
-
SSM 상태 관리자에서 패치가 구성되어 있는지, 모든 인스턴스에 대해 구성되어 있는지 확인합니다.
-
SSM RunCommand/Automation 실행 기록에서 패치 관련 SSM 문서의 실행이 인스턴스 시작과 일치하는지 확인합니다.
-
환경의 Amazon EC2 인스턴스에 대한 로그 파일에서 로컬 인스턴스 로깅을 검토하여 프로비저닝 중에 인스턴스가 재부팅되었는지 확인합니다.
패치 적용으로 인해 문제가 발생한 경우 RES 인스턴스에 대한 패치 적용은 시작 후 최소 15분 후에 지연합니다.
........................
자격 증명 관리 문제
Single Sign-On(SSO) 및 자격 증명 관리와 관련된 대부분의 문제는 잘못된 구성으로 인해 발생합니다. SSO 구성 설정에 대한 자세한 내용은 다음을 참조하세요.
자격 증명 관리와 관련된 다른 문제를 해결하려면 다음 문제 해결 주제를 참조하세요.
주제
........................
iam:PassRole을 수행하도록 인증되지 않음
iam:PassRole 작업을 수행할 권한이 없다는 오류가 수신되면 역할을 RES에 전달할 수 있도록 정책을 업데이트해야 합니다.
일부 AWS 서비스를 사용하면 새 서비스 역할 또는 서비스 연결 역할을 생성하는 대신 기존 역할을 해당 서비스에 전달할 수 있습니다. 이렇게 하려면 사용자가 서비스에 역할을 전달할 수 있는 권한을 가지고 있어야 합니다.
다음 예제 오류는 marymajor라는 IAM 사용자가 콘솔을 사용하여 RES에서 작업을 수행하려고 할 때 발생합니다. 하지만 작업을 수행하려면 서비스 역할이 부여한 권한이 서비스에 있어야 합니다. Mary는 서비스에 역할을 전달할 수 있는 권한을 가지고 있지 않습니다.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
이 경우 Mary가 iam:PassRole 작업을 수행할 수 있도록 Mary의 정책을 업데이트해야 합니다. 도움이 필요한 경우 AWS 관리자에게 문의하십시오. 관리자는 로그인 자격 증명을 제공한 사람입니다.
........................
내 AWS 계정 외부의 사용자가 리소스에서 내 Research and Engineering Studio에 AWS 액세스하도록 허용하고 싶습니다.
다른 계정의 사용자 또는 조직 외부의 사람이 리소스에 액세스할 때 사용할 수 있는 역할을 생성할 수 있습니다. 역할을 수임할 신뢰할 수 있는 사람을 지정할 수 있습니다. 리소스 기반 정책 또는 액세스 제어 목록(ACL)을 지원하는 서비스의 경우, 이러한 정책을 사용하여 다른 사람에게 리소스에 대한 액세스 권한을 부여할 수 있습니다.
자세히 알아보려면 다음을 참조하세요.
-
소유한 AWS 계정 전체에서 리소스에 대한 액세스 권한을 제공하는 방법을 알아보려면 IAM 사용 설명서의 소유한 다른 AWS 계정의 IAM 사용자에게 액세스 권한 제공을 참조하세요.
-
타사 AWS 계정에 리소스에 대한 액세스 권한을 제공하는 방법을 알아보려면 IAM 사용 설명서의 타사 소유 AWS 계정에 대한 액세스 권한 제공을 참조하세요.
-
자격 증명 페더레이션을 통해 액세스를 제공하는 방법을 알아보려면 IAM 사용 설명서의 외부 인증 사용자에게 액세스 권한 제공(자격 증명 페더레이션)을 참조하세요.
-
교차 계정 액세스를 위한 역할 및 리소스 기반 정책 사용의 차이점을 알아보려면 IAM 사용 설명서의 IAM 역할이 리소스 기반 정책과 어떻게 다른지 참조하세요.
........................
환경에 로그인할 때 즉시 로그인 페이지로 돌아갑니다.
이 문제는 SSO 통합이 잘못 구성된 경우에 발생합니다. 문제를 확인하려면 컨트롤러 인스턴스 로그를 확인하고 구성 설정에 오류가 있는지 검토합니다.
로그를 확인하려면:
-
CloudWatch 콘솔
을 엽니다. -
로그 그룹에서 라는 그룹을 찾습니다
/.<environment-name>/cluster-manager -
로그 그룹을 열어 로그 스트림에서 오류를 검색합니다.
구성 설정을 확인하려면:
-
DynamoDB 콘솔
열기 -
테이블에서 라는 테이블을 찾습니다
<environment-name>.cluster-settings -
테이블을 열고 테이블 항목 탐색을 선택합니다.
-
필터 섹션을 확장하고 다음 변수를 입력합니다.
-
속성 이름 - 키
-
조건 - 포함
-
값 - sso
-
-
Run(실행)을 선택합니다.
-
반환된 문자열에서 SSO 구성 값이 올바른지 확인합니다. 잘못된 경우 sso_enabled 키의 값을 False로 변경합니다.
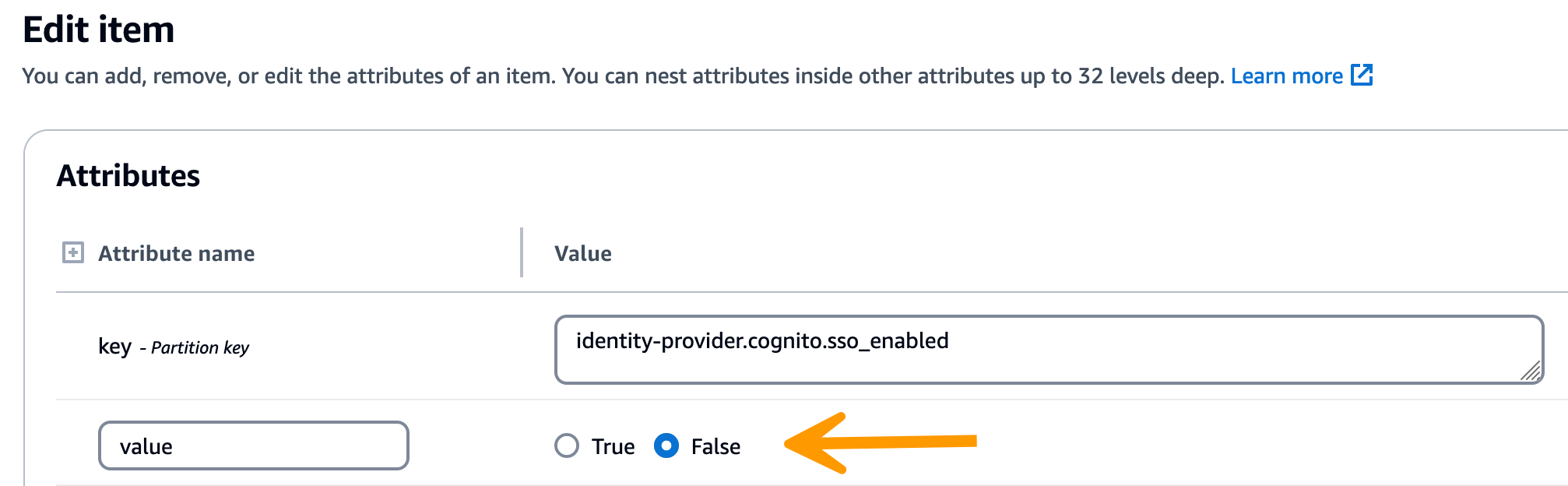
-
RES 사용자 인터페이스로 돌아가 SSO를 재구성합니다.
........................
로그인을 시도할 때 "사용자를 찾을 수 없음" 오류
사용자가 RES 인터페이스에 로그인하려고 할 때 "사용자를 찾을 수 없음" 오류가 표시되고 Active Directory에 사용자가 있는 경우:
-
사용자가 RES에 없고 최근에 AD에 사용자를 추가한 경우
-
사용자가 아직 RES에 동기화되지 않았을 수 있습니다. RES는 매시간 동기화되므로 다음 동기화 후 사용자를 추가했는지 기다려 확인해야 할 수 있습니다. 즉시 동기화하려면의 단계를 따릅니다Active Directory에 추가되었지만 RES에서 누락된 사용자.
-
-
사용자가 RES에 있는 경우:
-
속성 매핑이 올바르게 구성되었는지 확인합니다. 자세한 내용은 Single Sign-On을 위한 자격 증명 공급자 구성(SSO) 단원을 참조하십시오.
-
SAML 제목과 SAML 이메일이 모두 사용자의 이메일 주소에 매핑되는지 확인합니다.
-
........................
Active Directory에 추가되었지만 RES에서 누락된 사용자
참고
이 섹션은 RES 2024.10 이하에 적용됩니다. RES 2024.12 이상은 섹션을 참조하세요동기화를 수동으로 실행하는 방법(릴리스 2024.12 이상).
Active Directory에 사용자를 추가했지만 RES에 누락된 경우 AD 동기화를 트리거해야 합니다. AD 동기화는 AD 항목을 RES 환경으로 가져오는 Lambda 함수에 의해 시간별로 수행됩니다. 경우에 따라 새 사용자 또는 그룹을 추가한 후 다음 동기화 프로세스가 실행될 때까지 지연이 발생할 수 있습니다. Amazon Simple Queue Service에서 동기화를 수동으로 시작할 수 있습니다.
동기화 프로세스를 수동으로 시작합니다.
-
Amazon SQS 콘솔
을 엽니다. -
대기열에서 를 선택합니다
<environment-name>-cluster-manager-tasks.fifo. -
[메시지 전송 및 수신(Send and receive messages)]을 선택합니다.
-
메시지 본문에 다음을 입력합니다.
{ "name": "adsync.sync-from-ad", "payload": {} } -
메시지 그룹 ID에 다음을 입력합니다.
adsync.sync-from-ad -
메시지 중복 제거 ID에 임의의 영숫자 문자열을 입력합니다. 이 항목은 이전 5분 이내에 수행된 모든 호출과 달라야 합니다. 그렇지 않으면 요청이 무시됩니다.
........................
세션을 생성할 때 사용자를 사용할 수 없음
세션을 생성하는 관리자이지만 세션을 생성할 때 Active Directory에 있는 사용자를 사용할 수 없는 경우 사용자가 처음으로 로그인해야 할 수 있습니다. 세션은 활성 사용자에 대해서만 생성할 수 있습니다. 활성 사용자는 환경에 한 번 이상 로그인해야 합니다.
........................
CloudWatch 클러스터 관리자 로그에서 크기 제한 초과 오류
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
CloudWatch 클러스터 관리자 로그에서이 오류가 발생하면 LDAP 검색에서 너무 많은 사용자 레코드가 반환되었을 수 있습니다. 이 문제를 해결하려면 IDP의 LDAP 검색 결과 제한을 늘리세요.
........................
스토리지
주제
........................
RES를 통해 파일 시스템을 생성했지만 VDI 호스트에 탑재되지 않음
파일 시스템은 VDI 호스트에서 탑재하기 전에 "사용 가능" 상태여야 합니다. 아래 단계에 따라 파일 시스템이 필수 상태인지 확인합니다.
Amazon EFS
-
Amazon EFS 콘솔
로 이동합니다. -
파일 시스템 상태가 사용 가능한지 확인합니다.
-
파일 시스템 상태가 사용 가능이 아닌 경우 VDI 호스트를 시작하기 전에 기다립니다.
Amazon FSx ONTAP
-
Amazon FSx 콘솔
로 이동합니다. -
상태가 사용 가능한지 확인합니다.
-
상태를 사용할 수 없는 경우 VDI 호스트를 시작하기 전에 기다립니다.
........................
RES를 통해 파일 시스템을 온보딩했지만 VDI 호스트에 탑재되지 않음
RES에 온보딩된 파일 시스템에는 VDI 호스트가 파일 시스템을 탑재할 수 있도록 구성된 필수 보안 그룹 규칙이 있어야 합니다. 이러한 파일 시스템은 RES 외부에서 생성되므로 RES는 연결된 보안 그룹 규칙을 관리하지 않습니다.
온보딩된 파일 시스템과 연결된 보안 그룹은 다음 인바운드 트래픽을 허용해야 합니다.
Linux VDC 호스트의 NFS 트래픽(포트: 2049)
Windows VDC 호스트의 SMB 트래픽(포트: 445)
........................
VDI 호스트에서 읽기/쓰기를 수행할 수 없음
ONTAP은 볼륨에 대해 UNIX, NTFS 및 MIXED 보안 스타일을 지원합니다. 보안 스타일에 따라 ONTAP이 데이터 액세스를 제어하는 데 사용하는 권한 유형과 이러한 권한을 수정할 수 있는 클라이언트 유형이 결정됩니다.
예를 들어 볼륨이 UNIX 보안 스타일을 사용하는 경우 SMB 클라이언트는 ONTAP의 다중 프로토콜 특성으로 인해 여전히 데이터에 액세스할 수 있습니다(적절한 인증 및 권한 부여가 필요한 경우). 그러나 ONTAP은 UNIX 클라이언트만 기본 도구를 사용하여 수정할 수 있는 UNIX 권한을 사용합니다.
권한 처리 사용 사례 예
Linux 워크로드에서 UNIX 스타일 볼륨 사용
권한은 sudoer가 다른 사용자에 대해 구성할 수 있습니다. 예를 들어, 다음은 디렉터리에 대한 <group-ID> 전체 읽기/쓰기 권한을 모든 멤버에게 부여합니다/<project-name>.
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Linux 및 Windows 워크로드에서 NTFS 스타일 볼륨 사용
공유 권한은 특정 폴더의 공유 속성을 사용하여 구성할 수 있습니다. 예를 들어 사용자user_01와 폴더를 지정하면 myfolder, Change또는의 권한을 Allow 또는 Full ControlRead로 설정할 수 있습니다Deny.
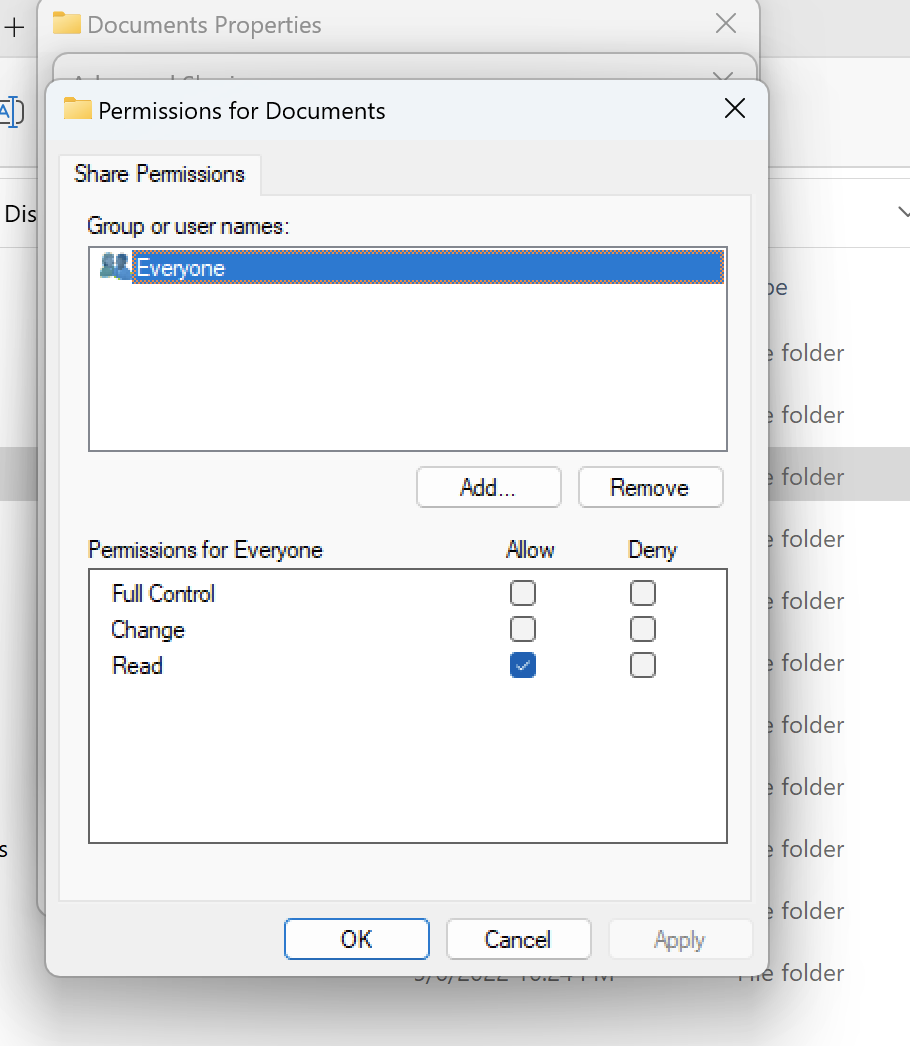
Linux 클라이언트와 Windows 클라이언트 모두에서 볼륨을 사용할 경우 모든 Linux 사용자 이름을 동일한 사용자 이름에 domain\username의 NetBIOS 도메인 이름 형식과 연결하는 이름 매핑을 SVM에 설정해야 합니다. 이는 Linux 사용자와 Windows 사용자 간에 번역하는 데 필요합니다. 자세한 내용은 Amazon FSx for NetApp ONTAP을 사용하여 멀티프로토콜 워크로드 활성화
........................
RES에서 Amazon FSx for NetApp ONTAP을 생성했지만 도메인에 조인되지 않음
현재 RES 콘솔에서 Amazon FSx for NetApp ONTAP을 생성하면 파일 시스템이 프로비저닝되지만 도메인에 조인되지 않습니다. 생성된 ONTAP 파일 시스템 SVM을 도메인에 조인하려면 SVMs Microsoft Active Directory에 조인을 참조하고 Amazon FSx 콘솔
도메인에 조인된 후 클러스터 설정 DynamoDB 테이블에서 SMB DNS 구성 키를 편집합니다.
-
Amazon DynamoDB 콘솔
로 이동합니다. -
테이블을 선택한 다음를 선택합니다
<stack-name>-cluster-settings. -
테이블 항목 탐색에서 필터를 확장하고 다음 필터를 입력합니다.
속성 이름 - 키
조건 - 같음
-
값 -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
반환된 항목을 선택한 다음 작업, 항목 편집을 선택합니다.
-
이전에 복사한 SMB DNS 이름으로 값을 업데이트합니다.
-
[Save and close]를 선택합니다.
또한 파일 시스템과 연결된 보안 그룹이 Amazon VPC를 사용한 파일 시스템 액세스 제어에서 권장하는 대로 트래픽을 허용하는지 확인합니다. 파일 시스템을 사용하는 새 VDI 호스트는 이제 도메인 조인된 SVM 및 파일 시스템을 탑재할 수 있습니다.
또는 RES 온보드 파일 시스템 기능을 사용하여 도메인에 이미 조인된 기존 파일 시스템을 온보딩할 수 있습니다. 환경 관리에서 파일 시스템, 온보드 파일 시스템을 선택합니다.
........................
스냅샷
........................
스냅샷의 상태는 실패입니다.
RES 스냅샷 페이지에서 스냅샷의 상태가 실패인 경우 오류가 발생한 시간 동안 클러스터 관리자에 대한 Amazon CloudWatch 로그 그룹으로 이동하여 원인을 확인할 수 있습니다.
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
스냅샷이 테이블을 가져올 수 없음을 나타내는 로그와 함께 적용되지 않습니다.
이전 env에서 가져온 스냅샷이 새 env에 적용되지 않는 경우 클러스터 관리자가 문제를 식별할 수 있도록 CloudWatch 로그를 살펴봅니다. 문제가 필요한 테이블 클라우드를 가져오지 않는다고 언급하는 경우 스냅샷이 유효한 상태인지 확인합니다.
-
metadata.json 파일을 다운로드하고 다양한 테이블의 ExportStatus가 COMPLETED 상태인지 확인합니다. 다양한 테이블에
ExportManifest필드 세트가 있는지 확인합니다. 위의 필드 세트를 찾을 수 없는 경우 스냅샷은 잘못된 상태이므로 스냅샷 적용 기능과 함께 사용할 수 없습니다. -
스냅샷 생성을 시작한 후 스냅샷 상태가 RES에서 완료됨으로 바뀌는지 확인합니다. 스냅샷 생성 프로세스는 최대 5~10분이 걸립니다. 스냅샷 관리 페이지를 다시 로드하거나 다시 방문하여 스냅샷이 성공적으로 생성되었는지 확인합니다. 이렇게 하면 생성된 스냅샷이 유효한 상태가 됩니다.
........................
인프라
........................
정상 인스턴스가 없는 로드 밸런서 대상 그룹
서버 오류 메시지와 같은 문제가 UI 또는 데스크톱 세션에 나타날 경우 연결할 수 없습니다. 이는 인프라 Amazon EC2 인스턴스에 문제가 있음을 나타낼 수 있습니다.
문제의 원인을 확인하는 방법은 먼저 Amazon EC2 콘솔에서 종료되고 새 인스턴스로 대체되는 것으로 보이는 Amazon EC2 인스턴스가 있는지 확인하는 것입니다. 이 경우 Amazon CloudWatch logs를 확인하여 원인을 확인할 수 있습니다.
또 다른 방법은 시스템의 로드 밸런서를 확인하는 것입니다. Amazon EC2 콘솔에서 발견된 로드 밸런서가 등록된 정상 인스턴스를 표시하지 않는 경우 시스템 문제가 있을 수 있음을 나타냅니다.
일반적인 모습의 예는 다음과 같습니다.
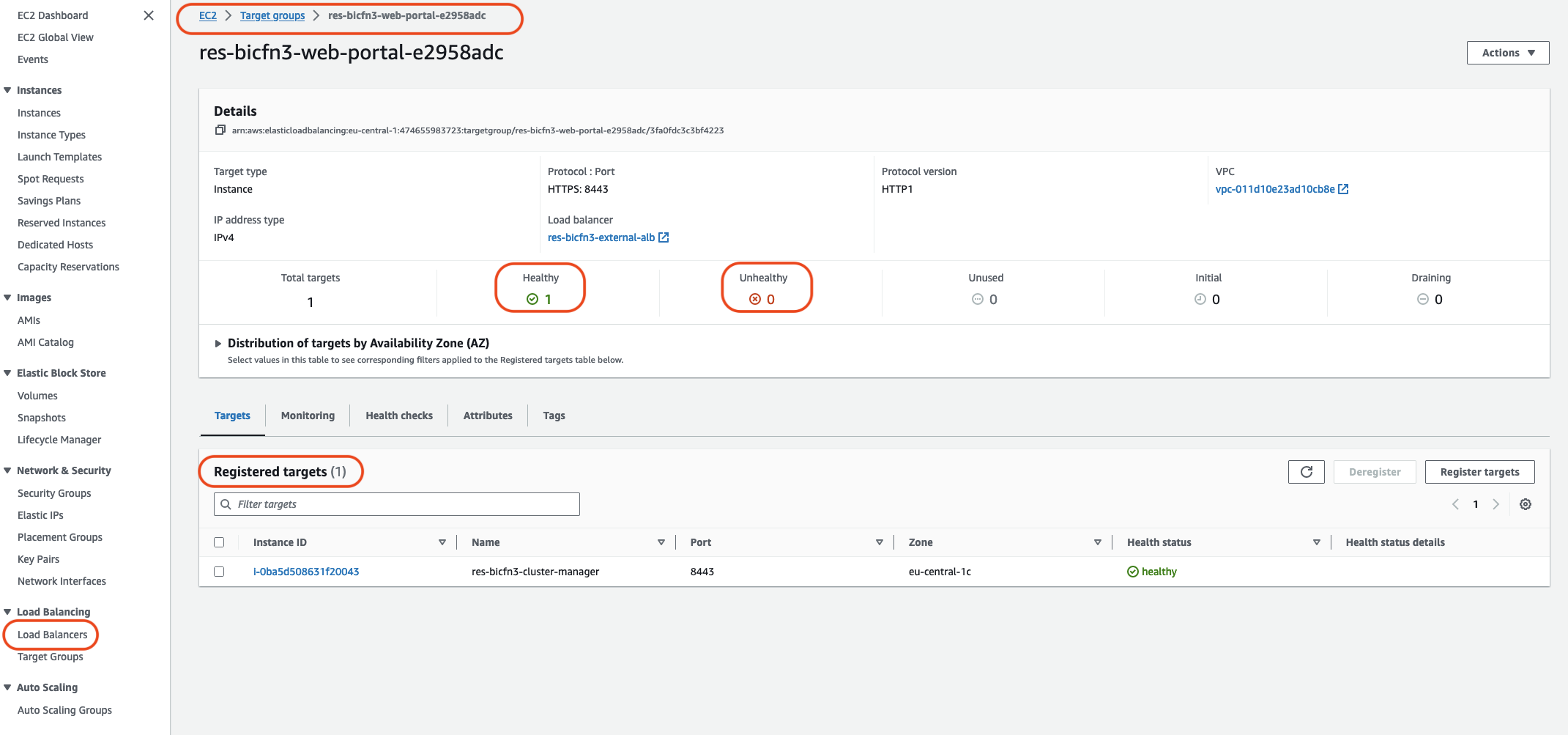
정상 항목이 0이면 요청을 처리할 수 있는 Amazon EC2 인스턴스가 없음을 나타냅니다.
비정상 항목이 0이 아닌 경우 이는 Amazon EC2 인스턴스가 순환 중일 수 있음을 나타냅니다. 이는 설치된 애플리케이션 소프트웨어가 상태 확인을 통과하지 못했기 때문일 수 있습니다.
정상 항목과 비정상 항목이 모두 0인 경우, 이는 잠재적인 네트워크 구성 오류를 나타냅니다. 예를 들어 퍼블릭 및 프라이빗 서브넷에 해당 AZs. 이 조건이 발생하면 콘솔에 네트워크 상태가 존재함을 나타내는 추가 텍스트가 있을 수 있습니다.
........................
가상 데스크톱 시작
주제
........................
외부 리소스 CertificateRenewalNode 사용 시 인증서 만료
외부 리소스 레시피를 배포하고 Linux VDIs에 연결하는 "The connection has been closed. Transport error" 동안 라는 오류가 발생하는 경우 가장 가능성이 높은 원인은 Linux의 잘못된 pip 설치 경로로 인해 자동으로 새로 고쳐지지 않는 만료된 인증서입니다. 인증서는 3개월 후에 만료됩니다.
Amazon CloudWatch 로그 그룹은 다음과 유사한 메시지와 함께 연결 시도 오류를 기록할 <envname>/vdc/dcv-connection-gateway
| 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Error in connection task: TLS handshake error: received fatal alert: CertificateUnknown | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 | | 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Certificate error: AlertReceived(CertificateUnknown) | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 |
문제 해결
-
AWS 계정에서 EC2
로 이동합니다. *-CertificateRenewalNode-*이름이 인 인스턴스가 있는 경우 인스턴스를 종료합니다. -
Lambda
로 이동합니다. 라는 Lambda 함수가 표시되어야 합니다 *-CertificateRenewalLambda-*. Lambda 코드에서 다음과 유사한 것을 확인하세요.export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py python3 ./get-pip.py pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates git clone https://github.com/Neilpang/acme.sh.git cd acme.sh -
여기에서
최신 외부 리소스 Certs 스택 템플릿을 찾아보세요. 템플릿에서 Lambda 코드를 찾습니다. 리소스 → CertificateRenewalLambda → 속성 → 코드. 다음과 비슷한 것을 찾을 수 있습니다. sudo yum install -y wget export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py mkdir -p pip python3 ./get-pip.py --target $PWD/pip $PWD/pip/bin/pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates VERSION=3.1.0 wget https://github.com/acmesh-official/acme.sh/archive/refs/tags/$VERSION.tar.gz -O acme-$VERSION.tar.gz tar -xvf acme-$VERSION.tar.gz cd acme.sh-$VERSION -
*-CertificateRenewalLambda-*Lambda 함수의 2단계 섹션을 3단계의 코드로 바꿉니다. 배포를 선택하고 코드 변경이 적용될 때까지 기다립니다. -
Lambda 함수를 수동으로 트리거하려면 테스트 탭으로 이동한 다음 테스트를 선택합니다. 추가 입력은 필요하지 않습니다. 그러면 Secret Manager에서 인증서 및 PrivateKey 보안 암호를 업데이트하는 인증서 EC2 인스턴스가 생성되어야 합니다.
-
기존 dcv-gateway 인스턴스를 종료
<env-name>-vdc-gateway
........................
이전에 작동하던 가상 데스크톱이 더 이상 성공적으로 연결할 수 없음
데스크톱 연결이 닫히거나 더 이상 연결할 수 없는 경우 기본 Amazon EC2 인스턴스가 실패하거나 Amazon EC2 인스턴스가 RES 환경 외부에서 종료되거나 중지되었기 때문일 수 있습니다. 관리자 UI 상태는 준비 상태를 계속 표시할 수 있지만 연결 시도는 실패합니다.
Amazon EC2 콘솔을 사용하여 인스턴스가 종료 또는 중지되었는지 확인해야 합니다. 중지된 경우 다시 시작해 보세요. 상태가 종료되면 다른 데스크톱을 생성해야 합니다. 새 인스턴스가 시작될 때 사용자 홈 디렉터리에 저장된 모든 데이터를 계속 사용할 수 있어야 합니다.
이전에 실패한 인스턴스가 관리자 UI에 계속 표시되는 경우 관리자 UI를 사용하여 종료해야 할 수 있습니다.
........................
5개의 가상 데스크톱만 시작할 수 있습니다.
사용자가 시작할 수 있는 가상 데스크톱 수의 기본 제한은 5입니다. 다음과 같이 관리자 UI를 사용하여 관리자가 변경할 수 있습니다.
데스크톱 설정으로 이동합니다.
서버 탭을 선택합니다.
DCV 세션 패널에서 오른쪽의 편집 아이콘을 클릭합니다.
사용자당 허용된 세션의 값을 원하는 새 값으로 변경합니다.
제출을 선택합니다.
페이지를 새로 고쳐 새 설정이 적용되었는지 확인합니다.
........................
데스크톱 Windows 연결 시도가 실패하고 "연결이 닫혔습니다. 전송 오류"
UI 오류와 함께 Windows 데스크톱 연결이 실패하는 경우 "연결이 닫혔습니다. 전송 오류", 원인은 Windows 인스턴스에서 인증서 생성과 관련된 DCV 서버 소프트웨어의 문제로 인한 것일 수 있습니다.
Amazon CloudWatch 로그 그룹은 다음과 유사한 메시지로 연결 시도 오류를 기록할 <envname>/vdc/dcv-connection-gateway 수 있습니다.
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
이 경우 SSM 세션 관리자를 사용하여 Windows 인스턴스에 대한 연결을 열고 다음 2개의 인증서 관련 파일을 제거하는 것이 해결 방법일 수 있습니다.
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
파일은 자동으로 다시 생성되어야 하며 후속 연결 시도가 성공할 수 있습니다.
이 방법으로 문제가 해결되고 Windows 데스크톱을 새로 시작할 때 동일한 오류가 발생하는 경우 소프트웨어 스택 생성 함수를 사용하여 재생성된 인증서 파일이 있는 고정 인스턴스의 새 Windows 소프트웨어 스택을 생성합니다. 이로 인해 성공적인 시작 및 연결에 사용할 수 있는 Windows 소프트웨어 스택이 생성될 수 있습니다.
........................
VDIs 프로비저닝 상태에서 멈춤
데스크톱 시작이 관리자 UI에서 프로비저닝 상태로 유지되는 경우 여러 가지 이유로 인해 발생할 수 있습니다.
원인을 확인하려면 데스크톱 인스턴스의 로그 파일을 검사하고 문제를 일으킬 수 있는 오류를 찾습니다. 이 문서에는 유용한 로그 및 이벤트 정보 소스라는 레이블이 지정된 섹션에 관련 정보가 포함된 로그 파일 및 Amazon CloudWatch 로그 그룹 목록이 포함되어 있습니다.
다음은이 문제의 잠재적 원인입니다.
-
사용된 AMI ID는 소프트웨어 스택으로 등록되었지만 RES에서는 지원되지 않습니다.
Amazon Machine Image(AMI)에 필요한 예상 구성 또는 도구가 없으므로 부트스트랩 프로비저닝 스크립트를 완료하지 못했습니다. Linux 인스턴스와 같은 인스턴스
/root/bootstrap/logs/의 로그 파일에는 이와 관련된 유용한 정보가 포함될 수 있습니다. AWS Marketplace에서 가져온 AMIs ID는 RES 데스크톱 인스턴스에서 작동하지 않을 수 있습니다. 지원되는지 확인하기 위해 테스트가 필요합니다. -
사용자 지정 AMI에서 Windows 가상 데스크톱 인스턴스를 시작할 때는 사용자 데이터 스크립트가 실행되지 않습니다.
기본적으로 사용자 데이터 스크립트는 Amazon EC2 인스턴스가 시작될 때 한 번 실행됩니다. 기존 가상 데스크톱 인스턴스에서 AMI를 생성한 다음 AMI에 소프트웨어 스택을 등록하고이 소프트웨어 스택으로 다른 가상 데스크톱을 시작하려고 하면 새 가상 데스크톱 인스턴스에서 사용자 데이터 스크립트가 실행되지 않습니다.
문제를 해결하려면 AMI를 생성하는 데 사용한 원래 가상 데스크톱 인스턴스에서 관리자로 PowerShell 명령 창을 열고 다음 명령을 실행합니다.
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –Schedule그런 다음 인스턴스에서 새 AMI를 생성합니다. 새 AMI를 사용하여 소프트웨어 스택을 등록하고 나중에 새 가상 데스크톱을 시작할 수 있습니다. 프로비저닝 상태로 유지되는 인스턴스에서 동일한 명령을 실행하고 인스턴스를 재부팅하여 가상 데스크톱 세션을 수정할 수도 있지만 잘못 구성된 AMI에서 다른 가상 데스크톱을 시작할 때 동일한 문제가 다시 발생합니다.
........................
시작 후 VDIs 오류 상태로 전환됨
- 가능한 문제 1: 홈 파일 시스템에는 다른 POSIX 권한을 가진 사용자를 위한 디렉터리가 있습니다.
-
이는 다음 시나리오가 참인 경우 직면하고 있는 문제일 수 있습니다.
-
배포된 RES 버전은 2024.01 이상입니다.
-
RES 스택을 배포하는 동안에 대한 속성이 로 설정
EnableLdapIDMapping되었습니다True. -
RES 스택 배포 중에 지정된 홈 파일 시스템이 RES 2024.01 이전 버전에서 사용되었거나가 로
EnableLdapIDMapping설정된 이전 환경에서 사용되었습니다False.
해결 단계: 파일 시스템에서 사용자 디렉터리를 삭제합니다.
-
SSM에서 클러스터-관리자 호스트로.
-
cd /home. -
ls-admin1는 ,admin2.. 등과 같이 사용자 이름과 일치하는 디렉터리 이름을 가진 디렉터리를 나열해야 합니다. -
디렉터리를 삭제합니다
sudo rm -r 'dir_name'. ssm-user 및 ec2-user 디렉터리를 삭제하지 마십시오. -
사용자가 이미 새 env에 동기화된 경우 사용자의 DDB 테이블에서 사용자의를 삭제합니다(clusteradmin 제외).
-
AD 동기화 시작 - 클러스터 관리자 Amazon EC2
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-ad에서 실행합니다. -
RES 웹 페이지에서
Error상태의 VDI 인스턴스를 재부팅합니다. VDI가 약 20분 내에Ready상태로 전환되는지 확인합니다.
-
........................
가상 데스크톱 구성 요소
주제
- Amazon EC2 인스턴스가 콘솔에서 종료된 것을 반복적으로 표시합니다.
- AD/eVDI 모듈에 조인 실패로 인해 vdc-controller 인스턴스가 순환 중입니다. API 상태 확인 실패가 표시됩니다.
- 프로젝트를 추가하기 위해 소프트웨어 스택을 편집할 때 풀다운에 프로젝트가 표시되지 않음
- cluster-manager Amazon CloudWatch 로그에 "<user-home-init> 계정을 아직 사용할 수 없습니다. 사용자가 동기화될 때까지 대기"(계정이 사용자 이름인 경우)가 표시됩니다.
- 로그인 시 Windows 데스크톱에 "계정이 비활성화되었습니다. 관리자에게 문의하세요.”
- 외부/고객 AD 구성 관련 DHCP 옵션 문제
- Firefox 오류 MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
........................
Amazon EC2 인스턴스가 콘솔에서 종료된 것을 반복적으로 표시합니다.
Amazon EC2 콘솔에서 인프라 인스턴스가 반복적으로 종료된 것으로 표시되는 경우 원인은 구성과 관련이 있을 수 있으며 인프라 인스턴스 유형에 따라 달라집니다. 다음은 원인을 확인하는 방법입니다.
Amazon EC2 콘솔에서 vdc 컨트롤러 인스턴스가 반복적으로 종료된 상태를 표시하는 경우 잘못된 보안 암호 태그 때문일 수 있습니다. RES에서 관리하는 보안 암호에는 인프라 Amazon EC2 인스턴스에 연결된 IAM 액세스 제어 정책의 일부로 사용되는 태그가 있습니다. vdc 컨트롤러가 순환 중이고 CloudWatch 로그 그룹에 다음 오류가 나타나는 경우 보안 암호에 태그가 올바르게 지정되지 않았기 때문일 수 있습니다. 보안 암호에 다음 태그를 지정해야 합니다.
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
이 오류에 대한 Amazon CloudWatch 로그 메시지는 다음과 비슷하게 표시됩니다.
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Amazon EC2 인스턴스의 태그를 확인하고 위 목록과 일치하는지 확인합니다.
........................
AD/eVDI 모듈에 조인 실패로 인해 vdc-controller 인스턴스가 순환 중입니다. API 상태 확인 실패가 표시됩니다.
eVDI 모듈이 상태 확인에 실패하면 환경 상태 섹션에 다음이 표시됩니다.
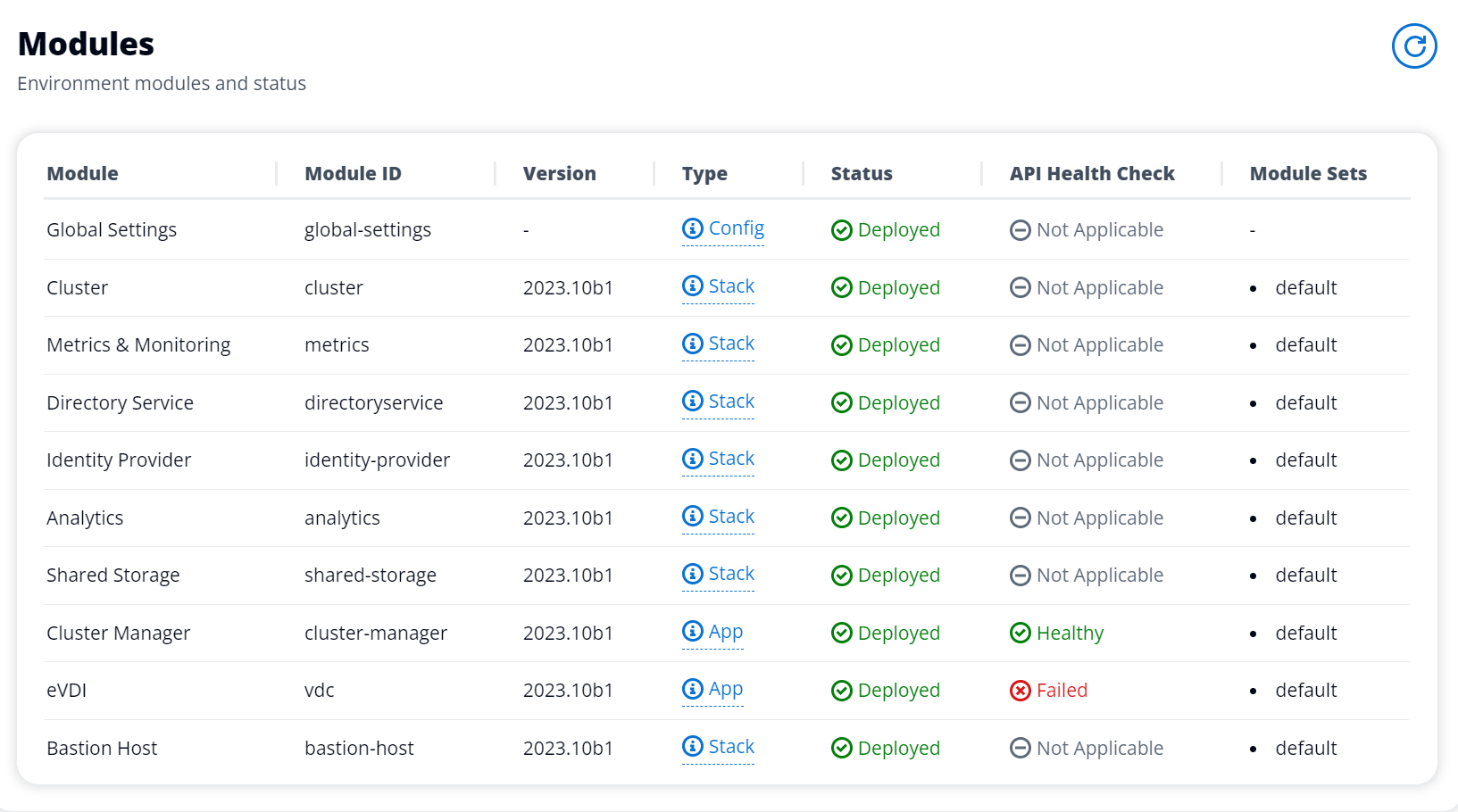
이 경우 디버깅의 일반적인 경로는 클러스터 관리자 CloudWatch<env-name>/cluster-manager.)
가능한 문제:
-
로그에 텍스트가 포함된 경우 res 스택이 생성될 때 지정된 ServiceAccount 사용자 이름의 철자가 올바른지
Insufficient permissions확인합니다.로그 라인 예:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
SecretsManager 콘솔
에서 RES 배포 중에 제공된 ServiceAccount 사용자 이름에 액세스할 수 있습니다. Secrets Manager에서 해당 보안 암호를 찾고 일반 텍스트 검색을 선택합니다. 사용자 이름이 잘못된 경우 편집을 선택하여 보안 암호 값을 업데이트합니다. 현재 클러스터 관리자 및 vdc 컨트롤러 인스턴스를 종료합니다. 새 인스턴스는 안정적인 상태로 표시됩니다. -
제공된 외부 리소스 스택에서 생성된 리소스를 사용하는 경우 사용자 이름은 "ServiceAccount"여야 합니다. RES 배포 중에
DisableADJoin파라미터가 False로 설정된 경우 "ServiceAccount" 사용자에게 AD에서 컴퓨터 객체를 생성할 수 있는 권한이 있는지 확인합니다.
-
-
사용된 사용자 이름이 정확했지만 로그에 텍스트가 포함된
Invalid credentials경우 입력한 암호가 잘못되었거나 만료되었을 수 있습니다.로그 라인 예:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
Secrets Manager 콘솔
에 암호를 저장하는 보안 암호에 액세스하여 env 생성 중에 입력한 암호를 읽을 수 있습니다. 보안 암호(예: <env_name>directoryserviceServiceAccountPassword)를 선택하고 일반 텍스트 검색을 선택합니다. -
보안 암호의 암호가 잘못된 경우 편집을 선택하여 보안 암호의 값을 업데이트합니다. 현재 클러스터 관리자 및 vdc 컨트롤러 인스턴스를 종료합니다. 새 인스턴스는 업데이트된 암호를 사용하고 안정적인 상태로 나타납니다.
-
암호가 올바르면 연결된 Active Directory에서 암호가 만료되었을 수 있습니다. 먼저 Active Directory에서 암호를 재설정한 다음 보안 암호를 업데이트해야 합니다. 디렉터리 서비스 콘솔
에서 Active Directory의 사용자 암호를 재설정할 수 있습니다. -
적절한 디렉터리 ID 선택
-
작업, 사용자 암호 재설정을 선택한 다음 사용자 이름(예: "ServiceAccount")과 새 암호를 사용하여 양식을 작성합니다.
-
새로 설정한 암호가 이전 암호와 다른 경우 해당 Secret Manager 보안 암호(예:
<env_name>directoryserviceServiceAccountPassword. -
현재 클러스터 관리자 및 vdc 컨트롤러 인스턴스를 종료합니다. 새 인스턴스는 안정적인 상태로 표시됩니다.
-
-
........................
프로젝트를 추가하기 위해 소프트웨어 스택을 편집할 때 풀다운에 프로젝트가 표시되지 않음
이 문제는 사용자 계정을 AD와 동기화하는 것과 관련된 다음 문제와 관련이 있을 수 있습니다. 이 문제가 나타나면 클러스터 관리자 Amazon CloudWatch 로그 그룹에 "<user-home-init> account not available yet. waiting for user to be synced" 오류가 있는지 확인하여 원인이 동일한지 또는 관련이 있는지 확인합니다.
........................
cluster-manager Amazon CloudWatch 로그에 "<user-home-init> 계정을 아직 사용할 수 없습니다. 사용자가 동기화될 때까지 대기"(계정이 사용자 이름인 경우)가 표시됩니다.
SQS 구독자가 사용 중이며 사용자 계정에 연결할 수 없기 때문에 무한 루프에 멈췄습니다. 이 코드는 사용자 동기화 중에 사용자를 위한 홈 파일 시스템을 생성하려고 할 때 트리거됩니다.
사용자 계정에 연결할 수 없는 이유는 사용 중인 AD에 대해 RES가 올바르게 구성되지 않았기 때문일 수 있습니다. 예를 들어 BI/RES 환경 생성에 사용된 ServiceAccountCredentialsSecretArn 파라미터가 올바른 값이 아니었을 수 있습니다.
........................
로그인 시 Windows 데스크톱에 "계정이 비활성화되었습니다. 관리자에게 문의하세요.”
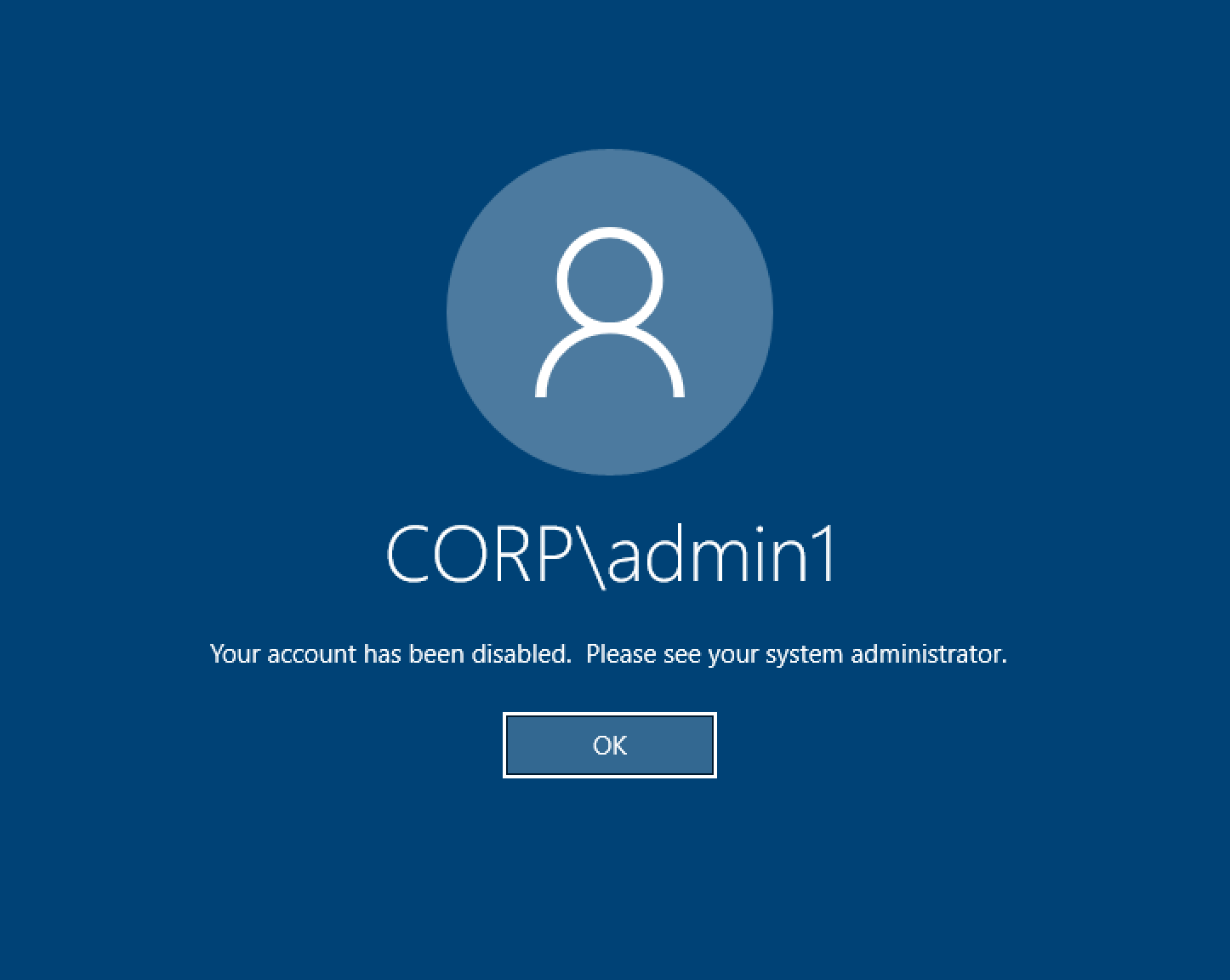
사용자가 잠긴 화면에 다시 로그인할 수 없는 경우 SSO를 통해 성공적으로 로그인한 후 사용자가 RES에 대해 구성된 AD에서 비활성화되었음을 나타낼 수 있습니다.
AD에서 사용자 계정이 비활성화된 경우 SSO 로그인이 실패합니다.
........................
외부/고객 AD 구성 관련 DHCP 옵션 문제
자체 Active Directory"The connection has been closed. Transport error"에서 RES를 사용할 때 Windows 가상 데스크톱에서 라는 오류가 발생하면 dcv-connection-gateway Amazon CloudWatch 로그에서 다음과 유사한 항목을 확인합니다.
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
자체 VPC의 DHCP 옵션에 AD 도메인 컨트롤러를 사용하는 경우 다음을 수행해야 합니다.
-
AmazonProvidedDNS를 두 도메인 컨트롤러 IPs에 추가합니다.
-
도메인 이름을 ec2.internal로 설정합니다.
여기에 예제가 나와 있습니다. 이 구성이 없으면 RES/DCV가 ip-10-0-x-xx.ec2.internal hostname을 찾기 때문에 Windows 데스크톱에서 전송 오류가 발생합니다.

........................
Firefox 오류 MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Firefox 웹 브라우저를 사용하면 가상 데스크톱에 연결하려고 할 때 MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING 오류 메시지 유형이 발생할 수 있습니다.
원인은 RES 웹 서버가 TLS + Stapling On으로 설정되었지만 Stapling Validation으로 응답하지 않기 때문입니다(https://support.mozilla.org/en-US/questions/1372483
https://really-simple-ssl.com/mozilla_pkix_error_required_tls_feature_missing
........................
Env 삭제
주제
........................
res-xxx-cluster 스택이 "DELETE_FAILED" 상태이고 "역할이 유효하지 않거나 수임할 수 없음" 오류로 인해 수동으로 삭제할 수 없음
"res-xxx-cluster" 스택이 "DELETE_FAILED" 상태이고 수동으로 삭제할 수 없는 경우 다음 단계를 수행하여 삭제할 수 있습니다.
스택이 "DELETE_FAILED" 상태로 표시되면 먼저 수동으로 삭제해 보십시오. 스택 삭제를 확인하는 대화 상자가 표시될 수 있습니다. Delete(삭제)를 선택합니다.
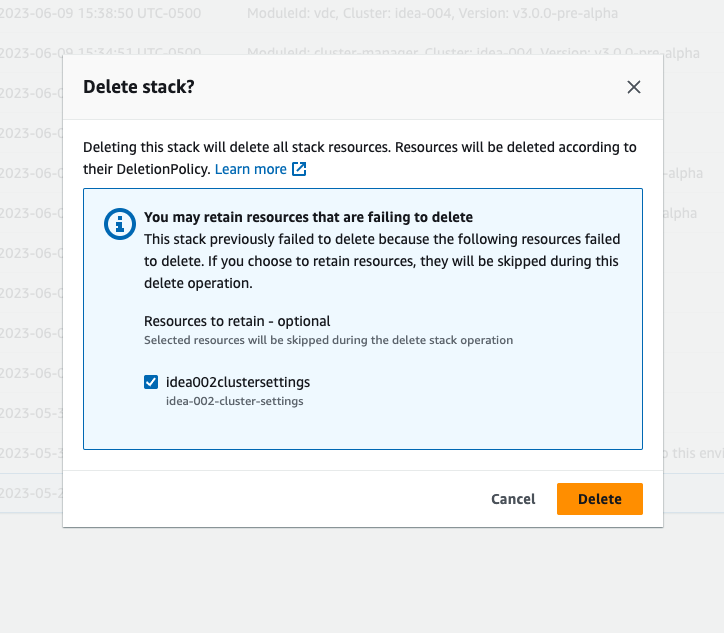
경우에 따라 필요한 스택 리소스를 모두 삭제하더라도 보존할 리소스를 선택하는 메시지가 계속 표시될 수 있습니다. 이 경우 모든 리소스를 "보존할 리소스"로 선택하고 삭제를 선택합니다.
다음과 같은 오류가 표시될 수 있습니다. Role: arn:aws:iam::... is Invalid or cannot be assumed
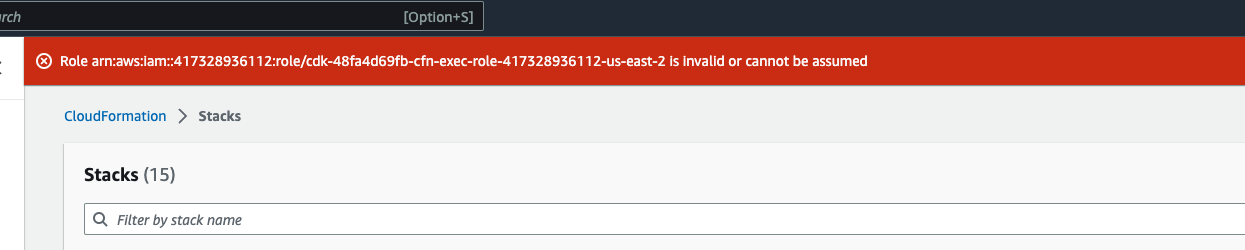
즉, 스택을 삭제하는 데 필요한 역할이 스택 전에 먼저 삭제됩니다. 이 문제를 해결하려면 역할 이름을 복사합니다. IAM 콘솔로 이동하여 다음과 같은 파라미터를 사용하여 해당 이름의 역할을 생성합니다.
-
신뢰할 수 있는 엔터티 유형에서 AWS 서비스를 선택합니다.
-
사용 사례에서를
Use cases for other AWS services선택합니다CloudFormation.
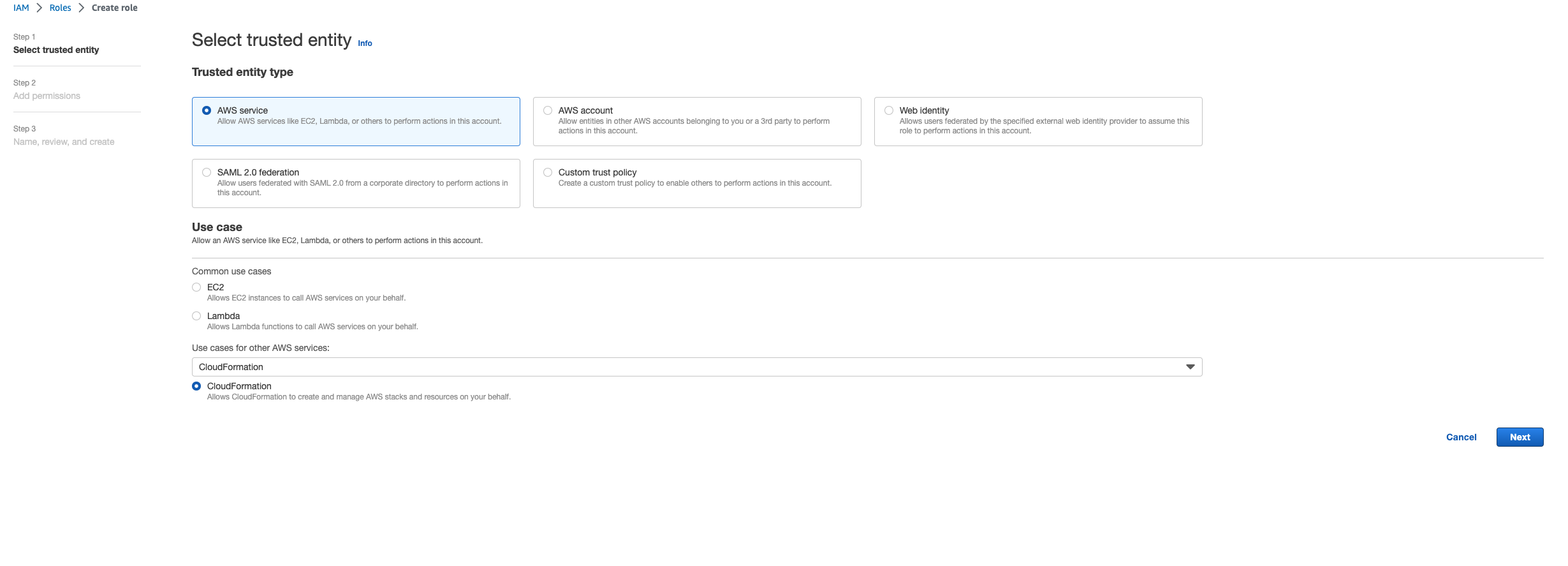
Next(다음)를 선택합니다. 역할 '' AWSCloudFormationFullAccess및 'AdministratorAccess' 권한을 부여해야 합니다. 검토 페이지는 다음과 같아야 합니다.
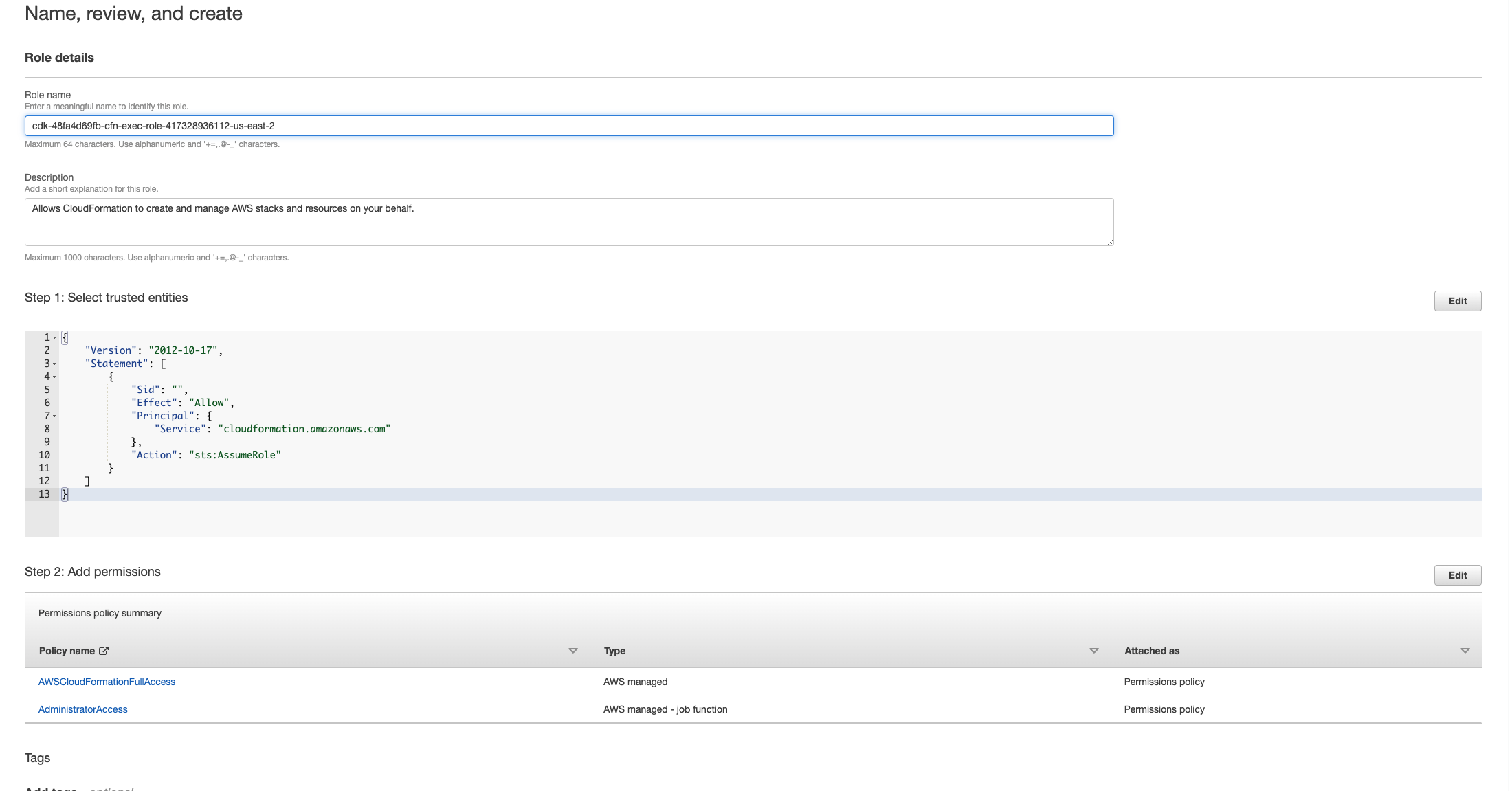
그런 다음 CloudFormation 콘솔로 돌아가 스택을 삭제합니다. 이제 역할을 생성한 이후 삭제할 수 있습니다. 마지막으로 IAM 콘솔로 이동하여 생성한 역할을 삭제합니다.
........................
로그 수집
EC2 콘솔에서 EC2 인스턴스에 로그인
인프라 호스트 로그 수집
-
클러스터 관리자: 다음 위치에서 클러스터 관리자에 대한 로그를 가져와 티켓에 연결합니다.
-
CloudWatch 로그 그룹의 모든 로그입니다
<env-name>/cluster-manager. -
<env-name>-cluster-managerEC2 인스턴스의/root/bootstrap/logs디렉터리에 있는 모든 로그입니다. 이 섹션의 시작 부분에 있는 "EC2 콘솔에서 EC2 인스턴스에 로그인"에서에 연결된 지침에 따라 인스턴스에 로그인합니다.
-
-
Vdc 컨트롤러: 다음 위치에서 vdc 컨트롤러에 대한 로그를 가져와 티켓에 연결합니다.
-
CloudWatch 로그 그룹의 모든 로그입니다
<env-name>/vdc-controller. -
<env-name>-vdc-controllerEC2 인스턴스의/root/bootstrap/logs디렉터리에 있는 모든 로그입니다. 이 섹션의 시작 부분에 있는 "EC2 콘솔에서 EC2 인스턴스에 로그인"에서에 연결된 지침에 따라 인스턴스에 로그인합니다.
-
로그를 쉽게 가져오는 방법 중 하나는 Linux EC2 인스턴스에서 로그 다운로드 섹션의 지침을 따르는 것입니다. 모듈 이름은 인스턴스 이름입니다.
VDI 로그 수집
- 해당 Amazon EC2 인스턴스 식별
-
사용자가 세션 이름이 인 VDI를 시작한 경우 Amazon EC2 콘솔에서 인스턴스의
VDI1해당 이름은 입니다<env-name>-VDI1-<user name>. - Linux VDI 로그 수집
-
이 섹션의 시작 부분에 있는 "Amazon EC2 콘솔에서 EC2 인스턴스에 로그인"에 연결된 지침에 따라 Amazon EC2 콘솔에서 해당 Amazon EC2 인스턴스에 로그인합니다. VDI Amazon EC2 인스턴스의
/root/bootstrap/logs및/var/log/dcv/디렉터리에서 모든 로그를 가져옵니다.로그를 가져오는 방법 중 하나는 s3에 업로드한 다음 거기에서 다운로드하는 것입니다. 이를 위해 다음 단계에 따라 하나의 디렉터리에서 모든 로그를 가져온 다음 업로드할 수 있습니다.
-
다음 단계에 따라
/root/bootstrap/logs디렉터리 아래에 dcv 로그를 복사합니다.sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
이제 다음 섹션 -에 나열된 단계에 따라 로그VDI 로그 다운로드를 다운로드합니다.
-
- Windows VDI 로그 수집
-
이 섹션의 시작 부분에 있는 "Amazon EC2 콘솔에서 EC2 인스턴스에 로그인"에 연결된 지침에 따라 Amazon EC2 콘솔에서 해당 Amazon EC2 인스턴스에 로그인합니다. VDI EC2 인스턴스의
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\디렉터리에 있는 모든 로그를 가져옵니다.로그를 가져오는 방법 중 하나는 S3에 로그를 업로드한 다음 거기서 다운로드하는 것입니다. 이렇게 하려면 다음 섹션 -에 나열된 단계를 따릅니다VDI 로그 다운로드.
........................
VDI 로그 다운로드
S3 액세스를 허용하도록 VDI EC2 인스턴스 IAM 역할을 업데이트합니다.
EC2 콘솔로 이동하여 VDI 인스턴스를 선택합니다.
사용 중인 IAM 역할을 선택합니다.
-
권한 추가 드롭다운 메뉴의 권한 정책 섹션에서 정책 연결을 선택한 다음 AmazonS3FullAccess 정책을 선택합니다.
권한 추가를 선택하여 해당 정책을 연결합니다.
-
그런 다음 VDI 유형에 따라 아래 나열된 단계에 따라 로그를 다운로드합니다. 모듈 이름은 인스턴스 이름입니다.
-
Linux EC2 인스턴스에서 로그 다운로드 Linux용
-
Windows EC2 인스턴스에서 로그 다운로드 Windows용.
-
-
마지막으로 역할을 편집하여
AmazonS3FullAccess정책을 제거합니다.
참고
모든 VDIs와 동일한 IAM 역할을 사용합니다. <env-name>-vdc-host-role-<region>
........................
Linux EC2 인스턴스에서 로그 다운로드
로그를 다운로드할 EC2 인스턴스에 로그인하고 다음 명령을 실행하여 모든 로그를 s3 버킷에 업로드합니다.
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
그런 다음 S3 콘솔로 이동하여 이름이 인 버킷을 선택하고 이전에 업로드한 <module_name>_logs.tar.gz 파일을 <environment_name>-cluster-<region>-<aws_account_number> 다운로드합니다.
........................
Windows EC2 인스턴스에서 로그 다운로드
로그를 다운로드할 EC2 인스턴스에 로그인하고 다음 명령을 실행하여 모든 로그를 S3 버킷에 업로드합니다.
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
그런 다음 S3 콘솔로 이동하여 이름이 인 버킷을 선택하고 이전에 업로드한 <module_name>_logs.zip 파일을 <environment_name>-cluster-<region>-<aws_account_number> 다운로드합니다.
........................
WaitCondition 오류에 대한 ECS 로그 수집
-
배포된 스택으로 이동하여 리소스 탭을 선택합니다.
-
배포 → ResearchAndEngineeringStudio → 설치 관리자 → 작업 → CreateTaskDef → CreateContainer → LogGroup을 확장하고 로그 그룹을 선택하여 CloudWatch 로그를 엽니다.
-
이 로그 그룹에서 최신 로그를 가져옵니다.
........................
데모 환경
........................
자격 증명 공급자에 대한 인증 요청을 처리할 때 데모 환경 로그인 오류
문제
로그인을 시도하고 '자격 증명 공급자에 대한 인증 요청을 처리할 때 예기치 않은 오류'가 발생하면 암호가 만료될 수 있습니다. 로그인하려는 사용자의 암호 또는 Active Directory 서비스 계정일 수 있습니다.
완화
-
디렉터리 서비스 콘솔
에서 사용자 및 서비스 계정 암호를 재설정합니다. -
위에 입력한 새 암호와 일치하도록 Secrets Manager
에서 서비스 계정 암호를 업데이트합니다. -
Keycloak 스택의 경우: PasswordSecret-...-RESExternal-...-DirectoryService-... 설명: Microsoft Active Directory의 암호
-
for RES: res-ServiceAccountPassword-... 설명: Active Directory 서비스 계정 암호
-
-
EC2 콘솔
로 이동하여 cluster-manager 인스턴스를 종료합니다. Auto Scaling 규칙은 새 인스턴스의 배포를 자동으로 트리거합니다.
........................
데모 스택 키클로크가 작동하지 않음
문제
키클로크 서버가 충돌하고 서버를 다시 시작할 때 인스턴스의 IP가 변경되면 키클로크가 중단될 수 있습니다. RES 포털의 로그인 페이지가 로드에 실패하거나 해결되지 않는 로드 상태로 멈춥니다.
완화
Keycloak을 정상 상태로 복원하려면 기존 인프라를 삭제하고 Keycloak 스택을 재배포해야 합니다. 다음 단계를 따릅니다.
-
Cloudformation으로 이동합니다. 여기에 두 개의 키클로크 관련 스택이 표시됩니다.
-
<env-name>-RESSsoKeycloak-<random characters><env-name>-RESSsoKeycloak-<random characters>-RESSsoKeycloak-*
-
-
Stack1을 삭제합니다. 중첩 스택을 삭제하라는 메시지가 표시되면 예를 선택하여 중첩 스택을 삭제합니다.
스택이 완전히 삭제되었는지 확인합니다.
-
여기에서 RES SSO Keycloak 스택 템플릿을 다운로드합니다
. -
삭제된 스택과 정확히 동일한 파라미터 값을 사용하여이 스택을 수동으로 배포합니다. 스택 생성 → 새 리소스 사용(표준) → 기존 템플릿 선택 → 템플릿 파일 업로드로 이동하여 CloudFormation 콘솔에서 배포합니다. 삭제된 스택과 동일한 입력을 사용하여 필요한 파라미터를 입력합니다. CloudFormation 콘솔에서 필터를 변경하고 파라미터 탭으로 이동하여 삭제된 스택에서 이러한 입력을 찾을 수 있습니다. 환경 이름, 키 페어 및 기타 파라미터가 원래 스택 파라미터와 일치하는지 확인합니다.
-
스택이 배포되면 환경을 다시 사용할 준비가 된 것입니다. 배포된 스택의 출력 탭에서 ApplicationUrl을 찾을 수 있습니다.
........................
