기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon SageMaker Pipelines을 사용하여 워크플로를 오케스트레이션하려면 JSON 파이프라인 정의 형태로 방향성 비순환 그래프(DAG)를 생성해야 합니다. DAG는 데이터 사전 처리, 모델 훈련, 모델 평가 및 모델 배포와 같은 ML 프로세스에 관련된 다양한 단계와 이러한 단계 간의 데이터 종속성 및 흐름을 지정합니다. 다음 주제에서는 파이프라인 정의를 생성하는 방법을 보여줍니다.
SageMaker Python SDK 또는 Amazon SageMaker Studio의 시각적 드래그 앤 드롭 파이프라인 디자이너 기능을 사용하여 JSON 파이프라인 정의를 생성할 수 있습니다. 다음 이미지는 이 자습서에서 만드는 파이프라인 DAG를 나타냅니다.
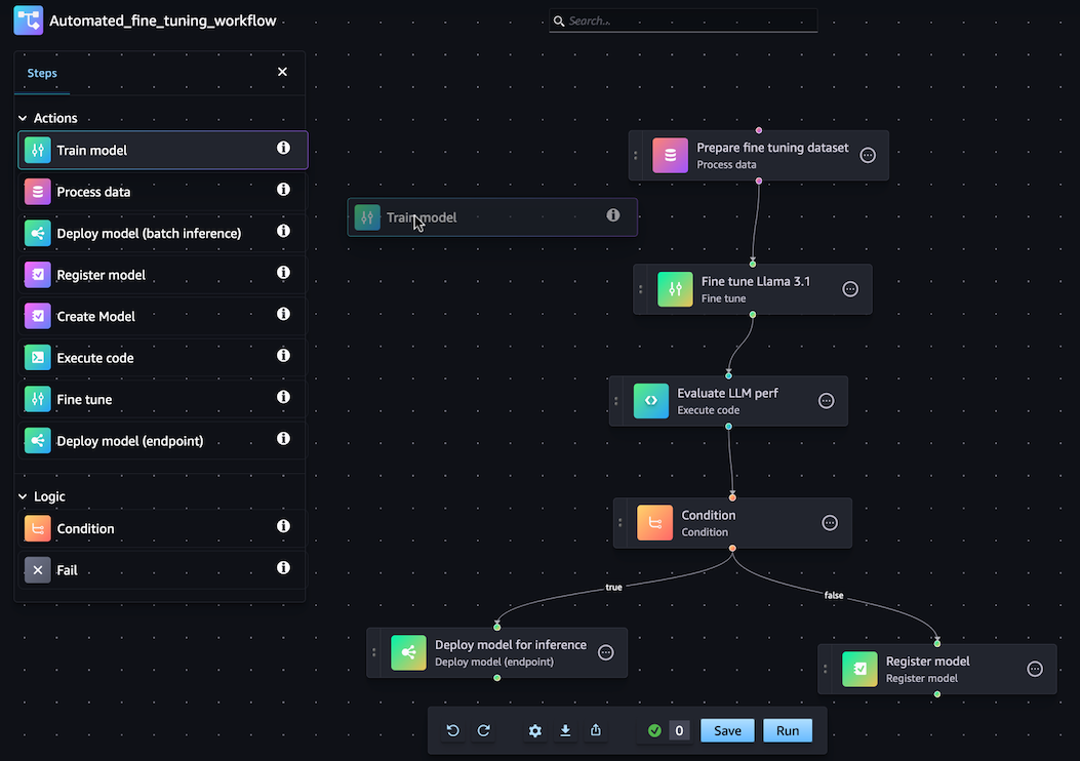
다음 섹션에서 정의하는 파이프라인은 회귀 문제를 해결하여 물리적 측정치를 기반으로 전복의 수명을 판단합니다. 이 자습서의 콘텐츠가 포함된 Jupyter Notebook은 Orchestrating Jobs with Amazon SageMaker Model Building Pipelines
참고
Github의 엔드 투 엔드 예시 CustomerChurn 파이프라인
주제
다음 연습에서는 드래그 앤 드롭 파이프라인 디자이너를 사용하여 베어본 파이프라인을 만드는 단계를 안내합니다. 언제든지 시각적 디자이너에서 파이프라인 편집 세션을 일시 중지하거나 종료해야 하는 경우 내보내기 옵션을 클릭합니다. 그러면 파이프라인의 현재 정의를 로컬 환경에 다운로드할 수 있습니다. 나중에 파이프라인 편집 프로세스를 재개하려는 경우 동일한 JSON 정의 파일을 시각적 디자이너로 가져올 수 있습니다.
처리 단계를 만드는 방법
데이터 처리 작업 단계를 만들려면 다음을 수행합니다.
-
Amazon SageMaker Studio 출시의 지침에 따라 Studio 콘솔을 엽니다.
-
왼쪽 탐색 창에서 파이프라인을 클릭합니다.
-
생성(Create)을 선택합니다.
-
비어 있음을 선택합니다.
-
왼쪽 사이드바에서 데이터 처리를 선택하고 캔버스로 드래그합니다.
-
캔버스에서 추가한 데이터 처리 단계를 선택합니다.
-
입력 데이터세트를 추가하려면 오른쪽 사이드바의 데이터(입력)에서 추가를 선택하고 데이터세트를 선택합니다.
-
출력 데이터세트를 저장할 위치를 추가하려면 오른쪽 사이드바의 데이터(출력)에서 추가를 선택하고 대상으로 이동합니다.
-
오른쪽 사이드바의 나머지 필드를 작성합니다. 이러한 탭의 필드에 대한 자세한 내용은 sagemaker.workflow.steps.ProcessingStep
을 참조하세요.
훈련 단계 만들기
모델 훈련 단계를 설정하려면 다음을 수행합니다.
-
왼쪽 사이드바에서 모델 훈련을 선택하고 캔버스로 드래그합니다.
-
캔버스에서 추가한 모델 훈련 단계를 선택합니다.
-
입력 데이터세트를 추가하려면 오른쪽 사이드바의 데이터(입력)에서 추가를 선택하고 데이터세트를 선택합니다.
-
모델 아티팩트를 저장할 위치를 선택하려면 위치(S3 URI) 필드에 Amazon S3 URI를 입력하거나 S3 찾아보기를 선택하여 대상 위치로 이동합니다.
-
오른쪽 사이드바의 나머지 필드를 작성합니다. 이러한 탭의 필드에 대한 자세한 내용은 sagemaker.workflow.steps.TrainingStep
을 참조하세요. -
이전 섹션에서 추가한 프로세스 데이터 단계에서 커서를 클릭하고 모델 훈련 단계로 드래그하여 두 단계를 연결하는 엣지를 만듭니다.
모델 등록 단계를 사용하여 모델 패키지 만들기
모델 등록 단계를 사용하여 모델 패키지를 만들려면 다음을 수행합니다.
-
왼쪽 사이드바에서 모델 등록을 선택하고 캔버스로 드래그합니다.
-
캔버스에서 추가한 모델 등록 단계를 선택합니다.
-
등록할 모델을 선택하려면 모델(입력)에서 추가를 선택합니다.
-
모델 그룹 만들기를 선택하여 모델을 새 모델 그룹에 추가합니다.
-
오른쪽 사이드바의 나머지 필드를 작성합니다. 이러한 탭의 필드에 대한 자세한 내용은 sagemaker.workflow.step_collections.RegisterModel
을 참조하세요. -
이전 섹션에서 추가한 모델 훈련 단계에서 커서를 클릭하고 모델 등록 단계로 드래그하여 두 단계를 연결하는 엣지를 만듭니다.
모델 배포(엔드포인트) 단계를 사용하여 엔드포인트에 모델 배포
모델 배포 단계를 사용하여 모델을 배포하려면 다음을 수행합니다.
-
왼쪽 사이드바에서 모델 배포(엔드포인트)를 선택하고 캔버스로 드래그합니다.
-
캔버스에서 추가한 모델 배포(엔드포인트) 단계를 선택합니다.
-
배포할 모델을 선택하려면 모델(입력)에서 추가를 선택합니다.
-
엔드포인트 만들기 라디오 버튼을 선택하여 새 엔드포인트를 만듭니다.
-
엔드포인트의 이름 및 설명을 입력합니다.
-
이전 섹션에서 추가한 모델 등록 단계에서 커서를 클릭하고 모델 배포(엔드포인트) 단계로 드래그하여 두 단계를 연결하는 엣지를 만듭니다.
-
오른쪽 사이드바의 나머지 필드를 작성합니다.
파이프라인 파라미터 정의
모든 실행에 대해 값을 업데이트할 수 있는 파이프라인 파라미터 세트를 구성할 수 있습니다. 파이프라인 파라미터를 정의하고 기본값을 설정하려면 시각적 디자이너 하단의 기어 아이콘을 클릭합니다.
파이프라인 저장
파이프라인을 만드는 데 필요한 모든 정보를 입력한 후 시각적 디자이너 하단의 저장을 클릭합니다. 그러면 런타임 시 파이프라인에 잠재적 오류가 있는지 검증하고 사용자에게 알립니다. 자동 유효성 검사로 플래그가 지정된 모든 오류를 해결할 때까지 저장 작업은 성공하지 않습니다. 나중에 편집을 재개하려면 진행 중인 파이프라인을 로컬 환경에서 JSON 정의로 저장할 수 있습니다. 시각적 디자이너 하단의 내보내기 버튼을 클릭하여 파이프라인을 JSON 정의 파일로 내보낼 수 있습니다. 나중에 파이프라인 업데이트를 재개하려면 가져오기 버튼을 클릭하여 해당 JSON 정의 파일을 업로드합니다.
사전 조건
다음 자습서를 실행하려면 다음을 수행해야 합니다.
-
노트북 인스턴스 생성에 설명된 대로 노트북 인스턴스를 설정합니다. 이렇게 하면 역할이 Amazon S3에 읽고 쓸 수 있는 권한을 부여하고 SageMaker AI에서 훈련, 배치 변환 및 처리 작업을 생성할 수 있습니다.
-
역할 권한 정책 수정에 표시된 대로 노트북에 자체 역할을 가져오고 전달할 수 있는 권한을 부여합니다. 다음 JSON 스니펫을 추가하여 이 정책을 역할에 연결합니다.
<your-role-arn>을 노트북 인스턴스를 생성하는 데 사용된 ARN으로 바꿉니다.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:GetRole", "iam:PassRole" ], "Resource": "<your-role-arn>" } ] } -
역할 신뢰 정책 수정의 단계에 따라 SageMaker AI 서비스 보안 주체를 신뢰합니다.https://docs.aws.amazon.com/IAM/latest/UserGuide/roles-managingrole-editing-cli.html#roles-managingrole_edit-trust-policy-cli 역할의 신뢰 관계에 다음 명령문 부분을 추가합니다.
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
환경을 설정합니다
다음 코드 블록을 사용하여 새 SageMaker AI 세션을 생성합니다. 그러면 세션의 역할 ARN이 반환됩니다.이 역할 ARN은 사전 요구 사항으로 설정한 실행 역할 ARN이어야 합니다.
import boto3
import sagemaker
import sagemaker.session
from sagemaker.workflow.pipeline_context import PipelineSession
region = boto3.Session().region_name
sagemaker_session = sagemaker.session.Session()
role = sagemaker.get_execution_role()
default_bucket = sagemaker_session.default_bucket()
pipeline_session = PipelineSession()
model_package_group_name = f"AbaloneModelPackageGroupName"파이프라인 생성
중요
Amazon SageMaker Studio 또는 Amazon SageMaker Studio Classic에서 Amazon SageMaker 리소스를 만들도록 허용하는 사용자 지정 IAM 정책은 해당 리소스에 태그를 추가할 수 있는 권한도 부여해야 합니다. Studio와 Studio Classic은 만드는 리소스에 태그를 자동으로 지정하기 때문에 리소스에 태그를 추가할 권한이 필요합니다. IAM 정책이 Studio 및 Studio Classic에서 리소스를 만들도록 허용하지만 태그 지정은 허용하지 않는 경우 리소스 만들기를 시도할 때 'AccessDenied' 오류가 발생할 수 있습니다. 자세한 내용은 SageMaker AI 리소스에 태그를 지정할 수 있는 권한 제공 섹션을 참조하세요.
SageMaker 리소스를 만들 수 있는 권한을 부여하는 AWS Amazon SageMaker AI에 대한 관리형 정책에는 해당 리소스를 만드는 동안 태그를 추가할 수 있는 권한이 이미 포함되어 있습니다.
SageMaker AI 노트북 인스턴스에서 다음 단계를 실행하여 다음 단계를 포함하는 파이프라인을 생성합니다.
-
사전 처리
-
학습
-
평가
-
조건부 평가
-
모델 등록
참고
ExecutionVariablesExecutionVariables이 확인됩니다. 예를 들어, ExecutionVariables.PIPELINE_EXECUTION_ID는 현재 실행의 ID로 확인되며, 이 ID는 여러 실행에서 고유한 식별자로 사용될 수 있습니다.
1단계: 데이터세트 다운로드
이 노트북은 UCI Machine Learning 전복 데이터세트를 사용합니다. 데이터세트에는 다음과 같은 기능이 있습니다.
-
length- 전복의 가장 긴 껍데기 치수입니다. -
diameter- 길이와 수직을 이루는 전복의 지름입니다. -
height- 껍데기의 살이 들어 있는 전복의 높이입니다. -
whole_weight- 전복 전체의 무게입니다. -
shucked_weight- 전복에서 꺼낸 살의 무게입니다. -
viscera_weight- 출혈 후 전복 내장의 무게입니다. -
shell_weight- 살을 제거하고 건조시킨 후의 전복 껍데기의 무게입니다. -
sex- 전복의 성별입니다. 'M', 'F', 'I' 중 하나이며, 여기서 'I'는 어린 전복입니다. -
rings- 전복 껍데기에 있는 고리 개수입니다.
다음 age=rings + 1.5공식을 사용하여 전복 껍데기에 있는 고리 개수로 전복 껍질의 나이에 대한 근사치를 구할 수 있습니다. 하지만 이 수를 구하려면 시간이 많이 걸립니다. 껍데기를 원추형으로 잘라서 단면에 얼룩을 묻힌 다음 현미경으로 고리 개수를 세어야 합니다. 그러나 다른 물리적 측정값을 더 쉽게 얻을 수 있습니다. 이 노트북은 데이터세트로 다른 물리적 측정값을 사용하여 가변 고리의 예측 모델을 구축합니다.
데이터세트를 다운로드하려면
-
계정의 기본 Amazon S3 버킷에 데이터세트를 다운로드합니다.
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
모델을 생성한 후 배치 변환을 위해 두 번째 데이터세트를 다운로드합니다.
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
2단계: 파이프라인 파라미터 정의
이 코드 블록은 파이프라인의 다음 파라미터를 정의합니다.
-
processing_instance_count- 처리 작업의 인스턴스 수입니다. -
input_data– 입력 데이터의 Amazon S3 위치입니다. -
batch_data- 배치 변환을 위한 입력 데이터의 Amazon S3 위치입니다. -
model_approval_status- 훈련된 모델을 CI/CD용으로 등록하기 위한 승인 상태입니다. 자세한 내용은 SageMaker 프로젝트를 통한 MLOps 자동화섹션을 참조하세요.
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterString,
)
processing_instance_count = ParameterInteger(
name="ProcessingInstanceCount",
default_value=1
)
model_approval_status = ParameterString(
name="ModelApprovalStatus",
default_value="PendingManualApproval"
)
input_data = ParameterString(
name="InputData",
default_value=input_data_uri,
)
batch_data = ParameterString(
name="BatchData",
default_value=batch_data_uri,
)3단계: 특성 엔지니어링을 위한 처리 단계 정의
이 섹션에서는 데이터세트에서 훈련에 사용할 데이터를 준비하는 처리 단계를 만드는 방법을 보여줍니다.
처리 단계를 만들려면
-
처리 스크립트를 위한 디렉토리를 생성합니다.
!mkdir -p abalone -
/abalone디렉터리에 다음 콘텐츠로preprocessing.py라는 파일을 생성합니다. 이 사전 처리 스크립트는 입력 데이터에 대한 실행을 위해 처리 단계로 전달됩니다. 그런 다음 훈련 단계에서는 사전 처리된 훈련 특성과 레이블을 사용하여 모델을 훈련합니다. 평가 단계에서는 훈련된 모델과 사전 처리된 테스트 특성 및 레이블을 사용하여 모델을 평가합니다. 이 스크립트는scikit-learn를 사용하여 다음을 수행할 수 있습니다.-
누락된
sex범주형 데이터를 채우고 훈련에 적합하도록 인코딩합니다. -
rings및sex을 제외한 모든 수치 필드를 조정하고 정규화합니다. -
데이터를 훈련, 테스트, 검증 데이터세트로 분할합니다.
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
SKLearnProcessor의 인스턴스를 만들어 처리 단계로 전달합니다.from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
처리 단계를 만들려면
SKLearnProcessor에서 이 단계는 입력 및 출력 채널, 생성된preprocessing.py스크립트를 가져옵니다. 이는 SageMaker AI Python SDK의 프로세서 인스턴스 방법과 매우 유사합니다run.ProcessingStep에 전달되는input_data파라미터는 단계 자체의 입력 데이터입니다. 이 입력 데이터는 프로세서 인스턴스가 실행될 때 사용됩니다.처리 작업의 출력 구성에 지정된
"train,"validation,"test"채널을 기록해 둡니다. 이러한Properties단계는 후속 단계에 사용될 수 있으며 런타임 시 해당 런타임 값으로 해결할 수 있습니다.from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
4단계: 훈련 단계 정의
이 섹션에서는 SageMaker AI XGBoost 알고리즘을 사용하여 처리 단계의 훈련 데이터 출력에 대한 모델을 훈련하는 방법을 보여줍니다.
훈련 단계를 정의하려면
-
훈련에서 가져온 모델을 저장할 모델 경로를 지정합니다.
model_path = f"s3://{default_bucket}/AbaloneTrain" -
XGBoost 알고리즘과 입력 데이터세트에 대한 예측기를 구성합니다. 훈련 인스턴스 유형이 예측기에 전달됩니다. 일반적인 훈련 스크립트:
-
입력 채널에서 데이터를 로드합니다.
-
하이퍼파라미터를 사용하여 훈련을 구성합니다.
-
모델을 훈련합니다.
-
나중에 호스팅할 수 있도록 모델을
model_dir에 저장합니다.
SageMaker AI는 훈련 작업 종료 시 모델을 Amazon S3에
model.tar.gz의 형태로 업로드합니다.from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
예측기 인스턴스와
ProcessingStep의 속성을 사용하여TrainingStep을 만듭니다."train"및"validation"출력 채널의S3Uri를TrainingStep에 전달합니다.from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
5단계: 모델 평가를 위한 처리 단계 정의
이 섹션에서는 모델의 정확도를 평가하기 위한 처리 단계를 생성하는 방법을 소개합니다. 이 모델 평가 결과는 조건 단계에서 어떤 실행 경로를 취할지 결정하는 데 사용됩니다.
모델 평가를 위한 처리 단계를 정의하려면
-
evaluation.py라는/abalone디렉터리에서 파일을 생성합니다. 이 스크립트는 모델 평가를 수행하는 처리 단계에서 사용됩니다. 훈련된 모델과 테스트 데이터세트를 입력으로 가져온 다음 분류 평가 지표가 포함된 JSON 파일을 생성합니다.%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
ProcessingStep을 생성하는 데 사용되는ScriptProcessor의 인스턴스를 생성합니다.from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
프로세서 인스턴스, 입력 및 출력 채널,
evaluation.py스크립트를 사용하여ProcessingStep을 만듭니다. 다음을 전달합니다.-
step_train훈련 단계의S3ModelArtifacts속성 -
step_process처리 단계의"test"출력 채널의S3Uri
이는 SageMaker AI Python SDK의 프로세서 인스턴스 방법과 매우 유사합니다
run.from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
6단계: 배치 변환을 위한 모델 만들기 단계 정의
중요
모델 단계을 사용하여 SageMaker Python SDK v2.90.0 이후 모델을 생성하는 것이 좋습니다. CreateModelStep은 이전 버전의 SageMaker Python SDK에서 계속 작동하지만 더 이상 적극적으로 지원되지는 않습니다.
이 섹션에서는 훈련 단계의 출력에서 SageMaker AI 모델을 생성하는 방법을 보여줍니다. 이 모델은 새 데이터세트의 배치 변환에 사용됩니다. 이 단계는 조건 단계로 전달되며 조건 단계가 true로 평가되는 경우에만 실행됩니다.
배치 변환을 위한 모델 생성 단계를 정의하려면
-
SageMaker AI 모델을 생성합니다.
step_train훈련 단계에서S3ModelArtifacts속성을 전달합니다.from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
SageMaker AI 모델의 모델 입력을 정의합니다.
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
정의한
CreateModelInput및 SageMaker AI 모델 인스턴스를CreateModelStep사용하여를 생성합니다.from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
7단계: 배치 변환을 수행할 변환 단계 정의
이 섹션에서는 모델을 훈련한 후 데이터세트에서 배치 변환을 수행하는 TransformStep을 만드는 방법을 보여줍니다. 이 단계는 조건 단계로 전달되며 조건 단계가 true로 평가되는 경우에만 실행됩니다.
배치 변환을 수행할 변환 단계를 정의하려면
-
적절한 컴퓨팅 인스턴스 유형, 인스턴스 수, 원하는 출력 Amazon S3 버킷 URI를 사용하여 트랜스포머 인스턴스를 생성합니다.
step_create_modelCreateModel훈련 단계에서ModelName속성을 전달합니다.from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
정의한 변환기 인스턴스와
batch_data파이프라인 파라미터를 사용하여TransformStep을 생성합니다.from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
8단계: 모델 패키지를 만들기 위한 모델 등록 단계 정의
중요
모델 단계을 사용하여 SageMaker Python SDK v2.90.0 이후 모델을 등록하는 것이 좋습니다. RegisterModel은 이전 버전의 SageMaker Python SDK에서 계속 작동하지만 더 이상 적극적으로 지원되지는 않습니다.
이 섹션에서는 RegisterModel의 인스턴스를 만드는 방법을 보여줍니다. 파이프라인에서 RegisterModel을 실행한 결과가 모델 패키지입니다. 모델 패키지는 추론에 필요한 모든 요소를 패키징하는 재사용 가능한 모델 아티팩트 추상화입니다. 이는 선택적 모델 가중치 위치와 함께 사용할 추론 이미지를 정의하는 추론 사양으로 구성됩니다. 모델 패키지 그룹은 모델 패키지 컬렉션입니다. Pipelines용 ModelPackageGroup을 사용하여 모든 파이프라인 실행에 대해 그룹에 새 버전 및 모델 패키지를 추가할 수 있습니다. 모델 레지스트리에 대한 자세한 내용은 Model Registry를 사용한 모델 등록 배포섹션을 참조하세요.
이 단계는 조건 단계로 전달되며 조건 단계가 true로 평가되는 경우에만 실행됩니다.
레지스터 모델 단계를 정의하여 모델 패키지를 만들려면
-
훈련 단계에서 사용한 예측기 인스턴스를 사용하여
RegisterModel단계를 생성합니다.step_train훈련 단계에서S3ModelArtifacts속성을 전달하고ModelPackageGroup을 지정합니다. Pipelines은 사용자를 위해ModelPackageGroup을 만듭니다.from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
9단계: 모델 정확도를 확인하기 위한 조건 단계 정의
ConditionStep을 사용하면 Pipelines이 단계 속성의 조건에 따라 파이프라인 DAG에서 조건부 실행을 지원할 수 있습니다. 이 경우 해당 모델의 정확도가 필요한 값을 초과하는 경우에만 모델 패키지를 등록하는 것이 좋습니다. 모델의 정확도는 모델 평가 단계에 따라 결정됩니다. 정확도가 필요한 값을 초과하는 경우 파이프라인은 SageMaker AI 모델도 생성하고 데이터 세트에서 배치 변환을 실행합니다. 이 섹션에서는 조건 단계를 정의하는 방법을 보여줍니다.
모델 정확도를 확인하기 위해 조건 단계를 정의하려면
-
모델 평가 처리 단계인
step_eval의 출력에 있는 정확도 값을 사용하여ConditionLessThanOrEqualTo조건을 정의합니다. 처리 단계에서 인덱싱한 속성 파일과 평균 제곱 오차 값"mse"의 각 JSONPath를 사용하여 이 출력을 가져옵니다.from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
ConditionStep을 생성합니다.ConditionEquals조건을 전달한 다음, 조건이 충족되면 모델 패키지 등록 및 배치 변환 단계를 다음 단계로 설정합니다.step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
10단계: 파이프라인 생성
이제 모든 단계를 생성했으니 단계를 하나의 파이프라인으로 결합합니다.
파이프라인을 만들려면
-
파이프라인에
name,parameters,steps을 정의합니다. 이름은(account, region)페어 내에서 고유해야 합니다.참고
단계는 파이프라인의 단계 목록 또는 조건 단계의 if/else 단계 목록에 한 번만 나타날 수 있습니다. 둘 다에 모두 나타날 수는 없습니다.
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
(선택 사항) JSON 파이프라인 정의를 검사하여 형식이 올바른지 확인합니다.
import json json.loads(pipeline.definition())
이 파이프라인 정의는 SageMaker AI에 제출할 준비가 되었습니다. 다음 자습서에서는이 파이프라인을 SageMaker AI에 제출하고 실행을 시작합니다.
Boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
다음 단계: 파이프라인 실행
