기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
이제 Amazon SageMaker AI를 사용하여 모델을 훈련하고 배포했으므로 모델을 평가하여 새 데이터에 대한 정확한 예측을 생성하는지 확인합니다. 모델 평가를 위해 데이터세트 준비에서 생성한 테스트 데이터 집합을 사용합니다.
SageMaker AI 호스팅 서비스에 배포된 모델 평가
모델을 평가하고 프로덕션 환경에서 사용하려면 테스트 데이터 집합으로 엔드포인트를 호출하고, 얻은 추론이 달성하려는 목표 정확도를 반환하는지 확인하세요.
모델을 평가하려면
-
다음 함수를 설정하여 테스트 집합의 각 라인을 예측하세요. 다음 예제 코드에서
rows인수는 한 번에 예측할 줄 수를 지정하는 것입니다. 사용자는 인스턴스의 하드웨어 리소스를 완전히 활용하는 배치 추론을 수행하도록 값을 변경할 수 있습니다.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
다음 코드를 실행하여 테스트 데이터세트를 예측하고 히스토그램을 플로팅합니다. 실제 값인 0번째 열을 제외하고 테스트 데이터세트의 특성 열만 가져오면 됩니다.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()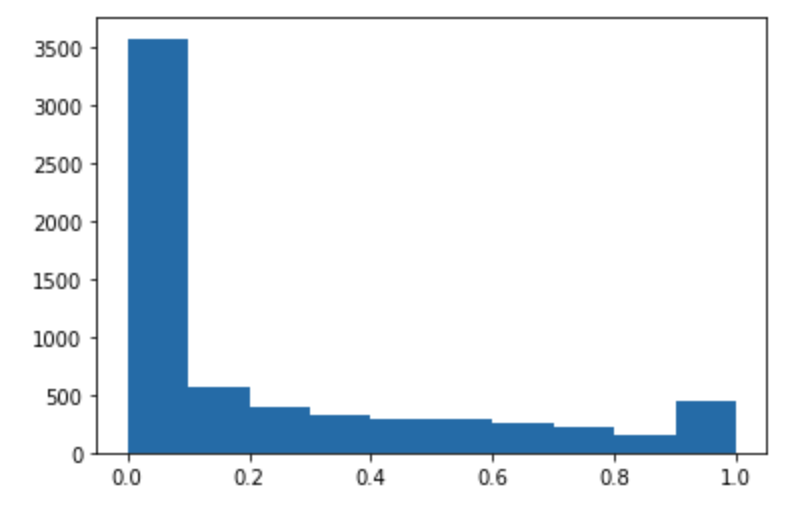
-
예측값은 부동 유형입니다. 부동 소수점 값을 기준으로
True또는False를 결정하려면 컷오프 값을 설정해야 합니다. 다음 예제 코드와 같이 Scikit-learn 라이브러리를 사용하여 컷오프가 0.5인 출력 오차 지표 및 분류 보고서를 반환합니다.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))그러면 다음과 같은 오차 행렬이 반환됩니다.
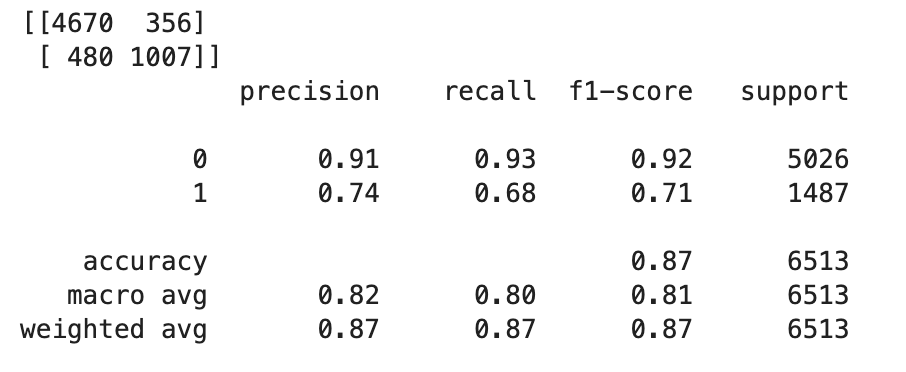
-
주어진 테스트 세트에서 최적의 컷오프를 찾으려면 로지스틱 회귀의 로그 손실 함수를 계산하세요. 로그 손실 함수는 실측 레이블에 대한 예측 확률을 반환하는 로지스틱 모델의 음수 로그 가능성으로 정의됩니다. 다음 예제 코드는 로그 손실 값(
-(y*log(p)+(1-y)log(1-p))을 수치적이고 반복적으로 계산합니다.여기서y는 실제 레이블이고p는 해당 테스트 표본의 확률 추정값입니다. 이는 로그 손실 대 컷오프 그래프를 반환합니다.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()그러면 다음과 같은 로그 손실 곡선이 반환됩니다.
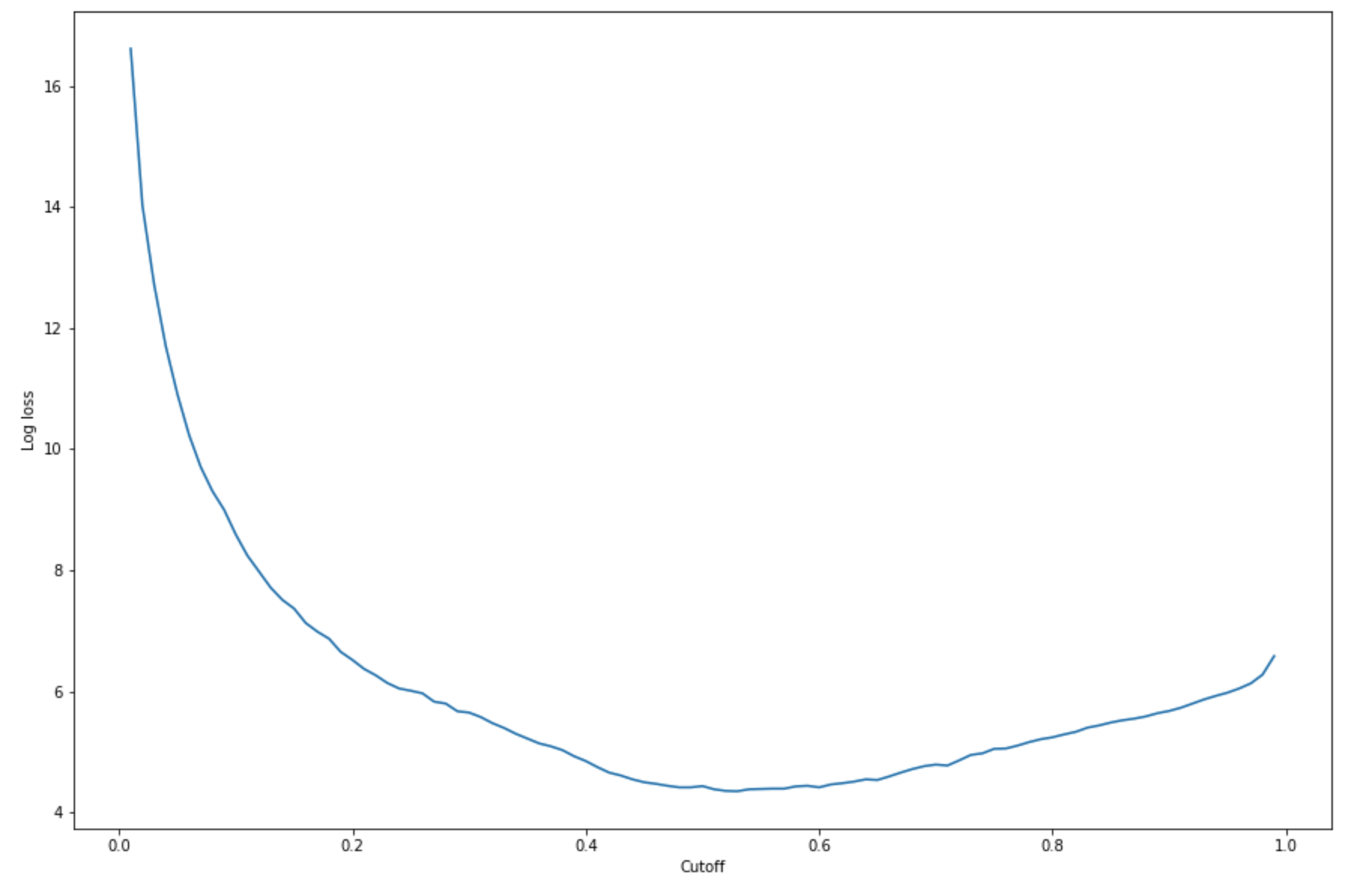
-
NumPy
argmin및min함수를 사용하여 오류 곡선의 최소점을 찾습니다.print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )그러면
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897이 반환되어야 합니다.로그 손실 함수를 계산하고 최소화하는 대신 대안으로 비용 함수를 추정할 수 있습니다. 예를 들어 고객 이탈 예측 문제와 같은 비즈니스 문제에 대해 바이너리 분류를 수행하도록 모델을 훈련시키려는 경우, 오차 행렬의 요소에 가중치를 설정하고 그에 따라 비용 함수를 계산할 수 있습니다.
이제 SageMaker AI에서 첫 번째 모델을 훈련, 배포 및 평가했습니다.
작은 정보
모델 품질, 데이터 품질 및 편향 드리프트를 모니터링하려면 Amazon SageMaker Model Monitor 및 SageMaker AI Clarify를 사용합니다. 자세한 내용은 Amazon SageMaker Model Monitor, 데이터 품질 모니터링, 모델 품질 모니터링, 편향 드리프트 모니터링 및기능 귀속 드리프트 모니터링을 참조하세요.
작은 정보
신뢰도가 낮은 ML 예측 또는 무작위 예측 샘플에 대한 인적 검토를 받으려면 Amazon Augmented AI 인적 검토 워크플로를 사용하세요. 자세한 내용은 인적 검토를 위한 Amazon Augmented AI 사용을 참조하세요.
