기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
권장 결과
개별 Inference Recommender 작업 결과에는 컨테이너의 지연 시간 및 처리량 개선을 위해 조정된 환경 변수 파라미터인 InstanceType, InitialInstanceCount, EnvironmentParameters이(가) 포함됩니다. 결과에는 MaxInvocations, ModelLatency, CostPerHour, CostPerInference, CpuUtilization, MemoryUtilization 같은 성능 및 비용 지표도 포함됩니다.
아래 표에 이 지표에 대한 설명이 있습니다. 이 지표로 검색 범위를 좁혀 사용 사례에 가장 적합한 엔드포인트 구성을 찾을 수 있습니다. 예를 들어, 처리량에 중점을 둔 전반적인 가격 대비 성능이 동기라면 CostPerInference에 집중해야 합니다.
| 지표 | 설명 | 사용 사례 |
|---|---|---|
|
|
SageMaker AI에서 볼 때 모델이 응답하는 데 걸리는 시간 간격입니다. 이 간격에는 요청을 전송하고 모델의 컨테이너에서 응답을 가져오는 데 걸리는 로컬 통신 시간과 컨테이너에서 추론을 완료하는 데 걸리는 시간도 포함됩니다. 단위: 밀리초 |
광고 게재, 의료 진단 등 지연 시간에 민감한 워크로드 |
|
|
1분 간 모델 엔드포인트로 전송된 최대 단위: 없음 |
비디오 처리, 일괄 추론 등 처리량 중심의 워크로드 |
|
|
실시간 엔드포인트의 시간당 예상 비용. 단위: 미국 달러 |
지연 기한이 없는 비용에 민감한 워크로드 |
|
|
실시간 엔드포인트의 추론 호출당 예상 비용. 단위: 미국 달러 |
처리량을 중심으로 전반적인 가격 대비 성능을 극대화합니다. |
|
|
엔드포인트 인스턴스의 분당 최대 간접 호출 시 예상 CPU 사용률. 단위: 백분율 |
인스턴스의 코어 CPU 사용률을 파악하여 벤치마킹 중에 인스턴스 상태를 파악합니다. |
|
|
엔드포인트 인스턴스의 분당 최대 간접 호출 시 예상 메모리 사용률. 단위: 백분율 |
인스턴스의 코어 메모리 사용률을 파악하여 벤치마킹 중에 인스턴스 상태를 파악합니다. |
경우에 따라와 같은 다른 SageMaker AI 엔드포인트 호출 지표를 탐색할 수 있습니다CPUUtilization. 모든 Inference Recommender 작업 결과에는 부하 테스트 중에 구동된 엔드포인트의 이름이 포함됩니다. CloudWatch를 사용하면 이러한 엔드포인트가 삭제된 후에도 로그를 검토할 수 있습니다.
다음 이미지는 권장 사항 결과에서 단일 엔드포인트에 대해 검토할 수 있는 CloudWatch 지표 및 차트의 예입니다. 이 권장 사항 결과는 기본 작업에서 도출된 것입니다. 권장 사항 결과의 스칼라 값을 해석하는 방법은 간접 호출 그래프가 처음으로 평준화되기 시작하는 시점을 기준으로 계산하는 것입니다. 예를 들어, 보고된 ModelLatency 값은 03:00:31 부근에서 정체기가 시작됩니다.
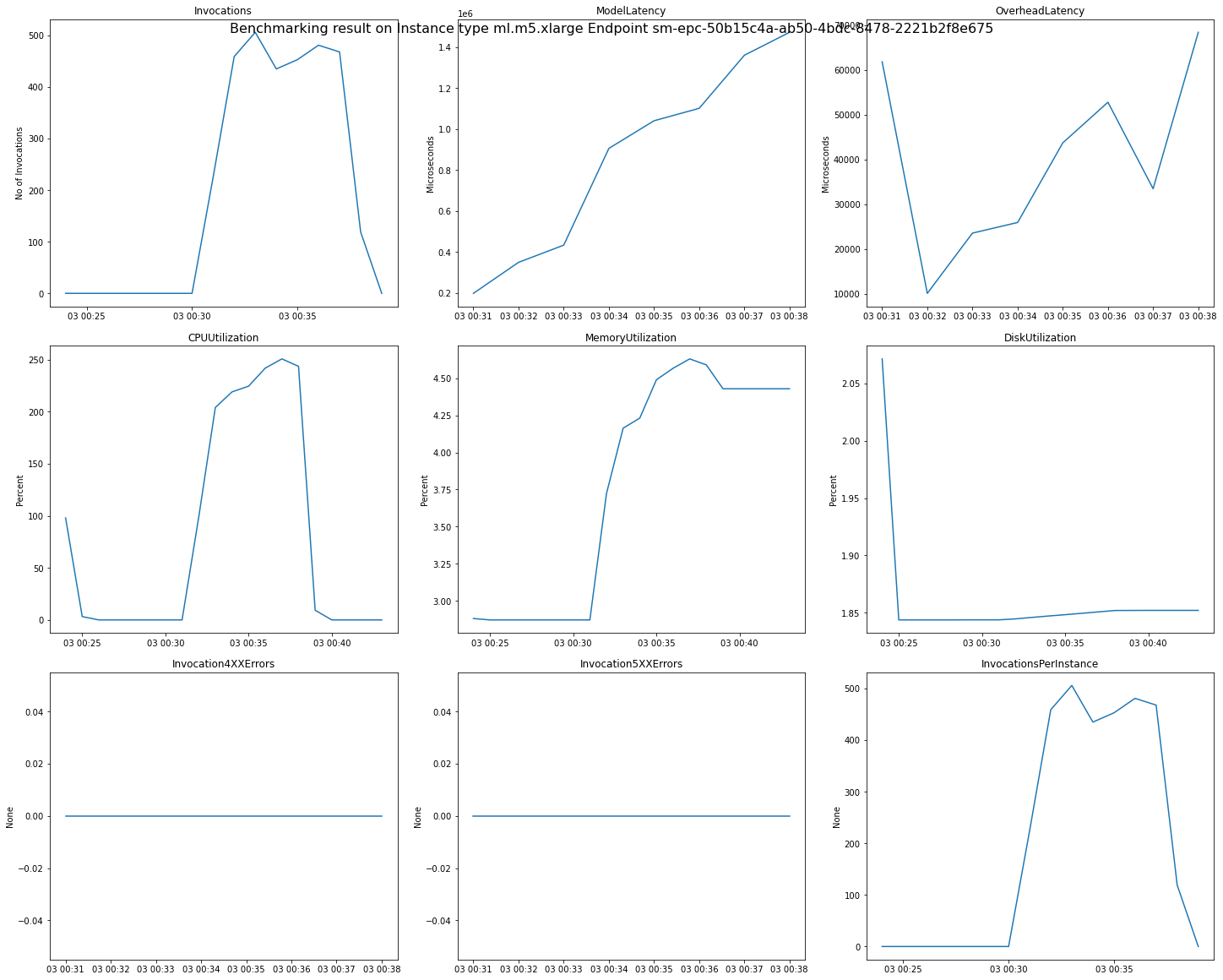
이전 차트에 사용된 CloudWatch 지표에 대한 전체 설명은 SageMaker AI 엔드포인트 호출 지표를 참조하세요.
ClientInvocations, NumberOfUsers 등 Inference Recommender에서 게시한 성능 지표는 /aws/sagemaker/InferenceRecommendationsJobs 네임스페이스에서도 볼 수 있습니다. Inference Recommender에서 게시한 지표와 설명 전체 목록은 SageMaker 추론 추천 작업 지표에서 확인하세요.
AWS SDK for Python(Boto3)을 사용하여 엔드포인트에 대한 CloudWatch 지표를 탐색하는 방법의 예는 amazon-sagemaker-examples Github 리포지토리의 Amazon SageMaker Inference Recommender - CloudWatch
