기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
검색 증강 생성
파운데이션 모델은 일반적으로 오프라인에서 훈련되므로 모델을 훈련한 후 생성되는 모든 데이터에 구애받지 않고 모델을 훈련할 수 있습니다. 또한 파운데이션 모델은 매우 일반적인 도메인 코퍼스를 대상으로 훈련되므로 도메인별 작업에서는 효율성이 떨어집니다. Retrieval Augmented Generation(RAG)을 사용하여 파운데이션 모델 외부에서 데이터를 검색하고 컨텍스트에 관련 검색 데이터를 추가하여 프롬프트를 보강할 수 있습니다. RAG 모델 아키텍처에 대한 자세한 내용은 지식 집약적 NLP 태스크에 대한 검색 증강 생성을 참조하세요
를 사용하면 프롬프트RAG를 보강하는 데 사용되는 외부 데이터는 문서 리포지토리, 데이터베이스 또는 와 같은 여러 데이터 소스에서 가져올 수 있습니다APIs. 첫 번째 단계는 관련성 검색을 수행하기 위해 문서와 사용자 쿼리를 호환 가능한 형식으로 변환하는 것입니다. 형식이 호환되도록 하기 위해 문서 컬렉션 또는 지식 라이브러리와 사용자가 제출한 쿼리를 임베딩 언어 모델을 사용하여 수치 표현으로 변환합니다. 임베딩은 텍스트를 벡터 공간에 숫자로 표현하는 프로세스입니다. RAG 모델 아키텍처는 지식 라이브러리의 벡터 내에서 사용자 쿼리의 임베딩을 비교합니다. 그런 다음 원본 사용자 프롬프트에 지식 라이브러리 내 유사한 문서의 관련 컨텍스트가 추가됩니다. 그러면 이 증강 프롬프트가 파운데이션 모델로 전송됩니다. 지식 라이브러리 및 관련 임베딩을 비동기적으로 업데이트할 수 있습니다.
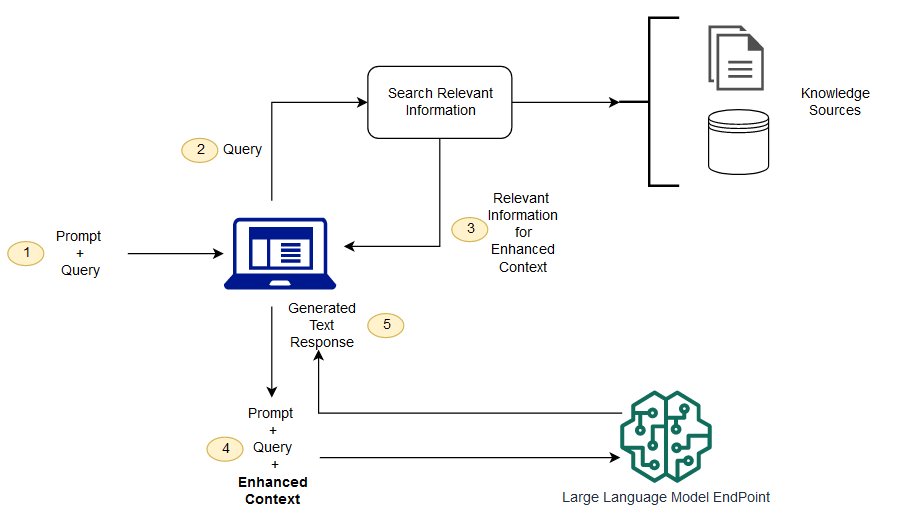
검색된 문서는 프롬프트를 보강하는 데 도움이 되는 유용한 컨텍스트를 포함할 만큼 충분히 커야 하지만 프롬프트의 최대 시퀀스 길이에 맞게 충분히 작아야 합니다. 의 일반 텍스트 임베딩(GTE) JumpStart 모델과 같은 태스크별 모델을 사용할 수 있습니다.Hugging Face: 프롬프트 및 지식 라이브러리 문서에 대한 임베딩을 제공합니다. 프롬프트와 문서 임베딩을 비교하여 가장 관련성이 높은 문서를 찾은 후 보충 컨텍스트를 사용하여 새 프롬프트를 구성합니다. 그런 다음 증강 프롬프트를 선택한 텍스트 생성 모델에 전달합니다.
예제 노트북
RAG 파운데이션 모델 솔루션에 대한 자세한 내용은 다음 예제 노트북을 참조하세요.
-
Retrieval-Augmented Generation: 및 Cohere의 에서 모델 생성 및 임베딩을 사용한 LangChain 질문 응답 SageMaker JumpStart
-
Retrieval-Augmented Generation: LLama-2, Pinecone 및 Custom Dataset을 사용한 질문 응답
-
Retrieval-Augmented Generation: 오픈 소스 LangChain 라이브러리가 있는 사용자 지정 데이터 세트를 기반으로 한 질문 응답
-
Retrieval-Augmented Generation: Llama-2 및 텍스트 임베딩 모델을 사용한 질문 응답
Amazon SageMaker 예제 리포지토리
