기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
프로덕션 변형을 사용한 모델 테스트
프로덕션 ML 워크플로우에서 데이터 과학자와 엔지니어는 종종 SageMaker AI로 자동 모델 튜닝, 추가 데이터 또는 더 최근 데이터에서 훈련하고, 기능 선택을 개선하고, 더 나은 업데이트된 인스턴스를 사용하고, 컨테이너를 제공하는 등 다양한 방법을 사용하여 성능을 개선하기 위해 노력합니다. 프로덕션 변형을 사용하여 모델, 인스턴스 및 컨테이너를 비교하고 추론 요청에 응답할 가장 성능이 좋은 후보를 선택할 수 있습니다.
SageMaker AI의 다변형 엔드포인트를 사용하여 각 변형에 대한 트래픽 분배를 제공하여 여러 프로덕션 변형 전반에 엔드포인트 간접 호출 요청을 분산하거나 각 요청에 대해 특정 변형을 직접 호출할 수 있습니다. 이 항목에서는 ML 모델을 테스트하는 두 가지 방법을 모두 살펴봅니다.
트래픽 분배를 지정하여 모델 테스트
두 모델 간에 트래픽을 분배하여 여러 모델을 테스트하려면 엔드포인트 구성에서 각 프로덕션 변형에 대한 가중치를 지정하여 각 모델로 라우팅되는 트래픽의 백분율을 지정합니다. 자세한 내용은 CreateEndpointConfig를 참조하세요. 다음 다이어그램은 이것이 어떻게 작동하는지 자세히 보여줍니다.
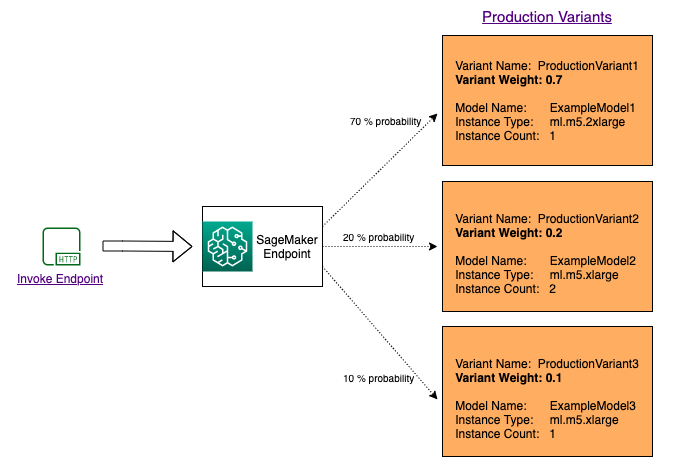
특정 변형을 호출하여 모델 테스트
각 요청에 대해 특정 모델을 호출하여 여러 모델을 테스트하려면 InvokeEndpoint를 호출할 때 TargetVariant 파라미터 값을 제공하여 호출하려는 모델의 특정 버전을 지정합니다. SageMaker AI는 사용자가 지정한 프로덕션 변형에 의해 요청이 처리되도록 합니다. 트래픽 분배를 이미 제공하고 TargetVariant 파라미터 값을 지정한 경우, 대상 지정 라우팅이 임의 트래픽 분배를 재정의합니다. 다음 다이어그램은 이것이 어떻게 작동하는지 자세히 보여줍니다.
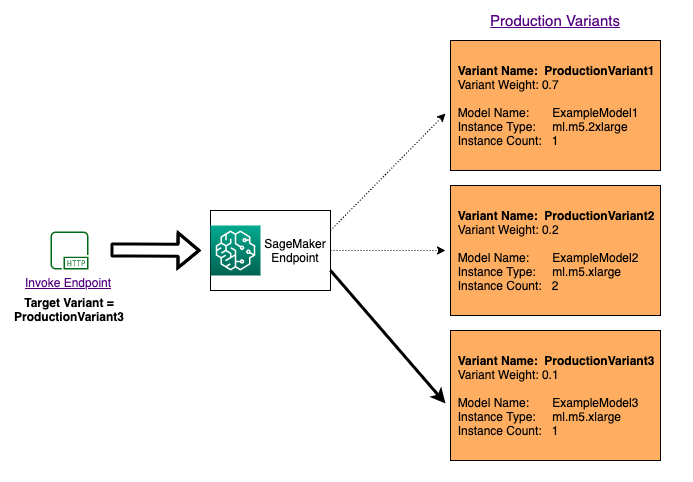
모델 A/B 테스트 예
프로덕션 트래픽을 이용해 새 모델과 이전 모델 간에 A/B 테스트를 수행하는 것은 새 모델의 검증 프로세스에서 효과적인 마지막 단계가 될 수 있습니다. A/B 테스트에서는 모델의 여러 변형을 테스트하고 각 변형의 성능을 비교합니다. 최신 버전의 모델이 이전 버전보다 더 나은 성능을 제공하는 경우 이전 버전의 모델을 프로덕션 환경의 새 버전으로 교체합니다.
다음의 예는 A/B 모델 테스트를 수행하는 방법을 보여줍니다. 이 예제를 구현하는 샘플 노트북은 프로덕션 환경의 A/B 테스트 ML 모델
1단계: 모델 생성 및 배포
먼저, Amazon S3에서 모델의 위치를 정의합니다. 이러한 위치는 후속 단계에서 모델을 배포할 때 사용됩니다.
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
다음으로, 이미지 및 모델 데이터를 이용해 모델 객체를 생성합니다. 이러한 모델 객체는 엔드포인트에 프로덕션 변형을 배포하는 데 사용됩니다. 다른 데이터세트, 다른 알고리즘 또는 ML 프레임워크 및 다른 하이퍼파라미터에 대한 ML 모델을 훈련함으로써 모델이 개발됩니다.
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
이제 자체 모델 및 리소스 요구 사항(인스턴스 유형 및 개수)이 서로 다른 두 가지 프로덕션 변형을 생성합니다. 이렇게 하면 서로 다른 인스턴스 유형에서 모델을 테스트할 수도 있습니다.
두 변형 모두에 대해 initial_weight를 1로 설정합니다. 즉, 요청의 50%가 Variant1로 이동하고 나머지 50%는 Variant2로 이동합니다. 두 변형의 가중치 합은 2이고 각 변형의 가중치 할당은 1입니다. 즉, 각 변형은 총 트래픽의 1/2 또는 50% 를 수신합니다.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
마지막으로 이러한 프로덕션 변형을 SageMaker AI 엔드포인트에 배포할 준비가 되었습니다.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
2단계: 배포된 모델 호출
이제 실시간으로 추론을 얻기 위해 이 엔드포인트에 요청을 전송합니다. 트래픽 분배와 직접 대상 지정을 모두 사용합니다.
먼저, 이전 단계에서 구성한 트래픽 분배를 사용합니다. 각 추론 응답에는 요청을 처리하는 프로덕션 변형의 이름이 포함되어 있으므로 두 프로덕션 변형에 대한 트래픽이 거의 동일하다는 것을 알 수 있습니다.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker AI는 Amazon CloudWatch의 각 변형에 대해 Latency 및 Invocations 등의 지표를 내보냅니다. SageMaker AI에서 내보내는 지표의 전체 목록은 Amazon CloudWatch의 Amazon SageMaker AI 지표 섹션을 참조하세요. 기본적으로 호출이 변형간에 분할되는 방법을 보여주기 위해 각 변형별 호출 수를 가져 오도록 CloudWatch에 대한 쿼리를 수행해 보겠습니다.
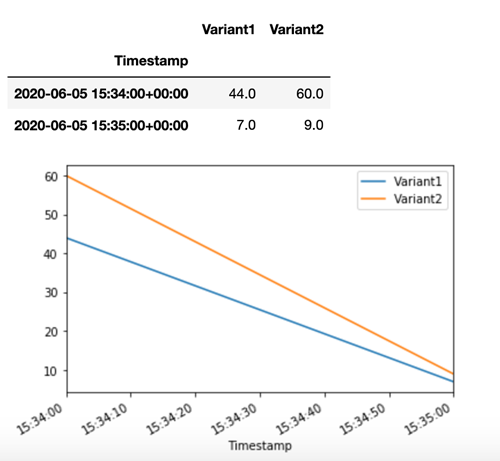
이제 호출의 TargetVariant로서 Variant1을 invoke_endpoint으로 지정하여 모델의 특정 버전을 호출해 보겠습니다.
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
모든 새로운 호출이 Variant1에서 처리되었는지 확인하기 위해 각 변형별 호출의 수를 얻기 위해 CloudWatch에 대해 쿼리를 수행할 수 있습니다. 지정한 대로 가장 최근의 호출(최신 타임스탬프)에서 모든 요청이 Variant1에 의해, 처리되었음을 알 수 있습니다. Variant2에 대한 수행된 호출이 없었습니다 .

3단계: 모델 성능 평가
어떤 모델 버전의 성능이 더 나은지 확인하기 위해 각 변형에 대한 곡선 아래의 정확도, 정밀도, 리콜, F1 점수 및 수신기 작동 특성/영역을 평가해 보겠습니다. 먼저 Variant1에 대한 다음 지표를 살펴보겠습니다 .

이제 Variant2에 대한 지표를 살펴보겠습니다 .
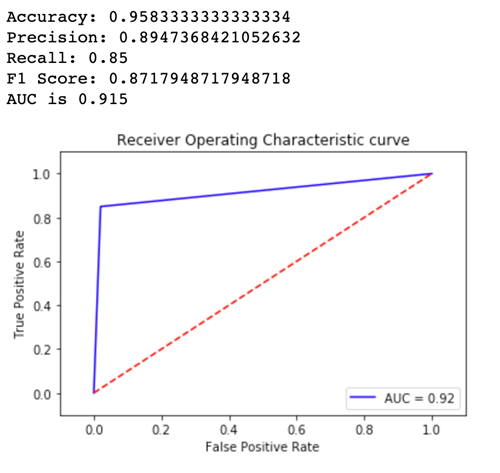
정의된 지표의 대부분에서 더 나은 성능을 보인다는 점에서 Variant2을 프로덕션 환경에서 사용하고 싶을 것입니다.
4단계: 최상의 모델로 트래픽 증가
Variant2이 Variant1보다 성능이 뛰어나다는 것을 확인했으면 여기로 더 많은 트래픽을 이동시킵니다. TargetVariant을 계속 사용해 특정 모델 변형을 호출할 수 있지만, 더 간단한 방법은 UpdateEndpointWeightsAndCapacities를 호출하여 각 변형에 할당된 가중치를 업데이트하는 것입니다. 이렇게 하면 엔드포인트를 업데이트할 필요 없이 프로덕션 변형으로 트래픽 분배가 변경됩니다. 설정 섹션에서 트래픽 50/50으로 분할하기 위한 변형 가중치를 설정했다는 점을 상기하세요. 아래의 각 변형에 대한 총 호출의 CloudWatch 지표는 각 변형에 대한 호출 패턴을 보여줍니다.
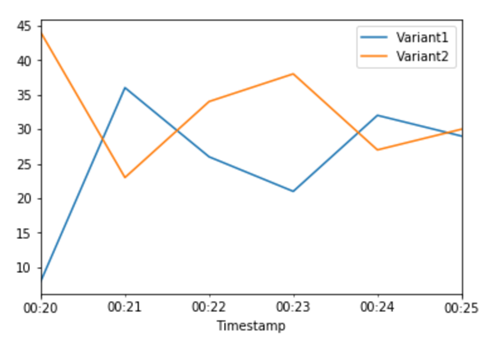
이제 UpdateEndpointWeightsAndCapacities를 사용하여 각 변형에 새 가중치를 할당하여 트래픽의 75%를 Variant2로 전환합니다. 이제 SageMaker AI는 추론 요청의 75%를 Variant2로 보내고 요청의 나머지 25%는 Variant1로 보냅니다.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
각 변형에 대한 총 호출의 CloudWatch 지표를 보면 Variant1보다 Variant2에서 더 많이 호출되었음을 알 수 있습니다.

계속해서 지표를 모니터링할 수 있으며, 변형의 성능에 만족하면 트래픽의 100%를 해당 변형으로 라우팅할 수 있습니다. 변형에 대한 트래픽 할당을 업데이트하는 데 UpdateEndpointWeightsAndCapacities을 사용합니다. Variant1의 가중치는 0으로 설정되어 있고 Variant2의 가중치는 1로 설정되어 있습니다. 이제 SageMaker AI는 모든 추론 요청의 100%를 Variant2로 보냅니다.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
각 변형에 대한 총 호출의 CloudWatch 지표는 모든 추론 요청이 Variant2에서 처리되고 있으며, Variant1에서 처리되는 추론 요청은 없다는 것을 보여줍니다.
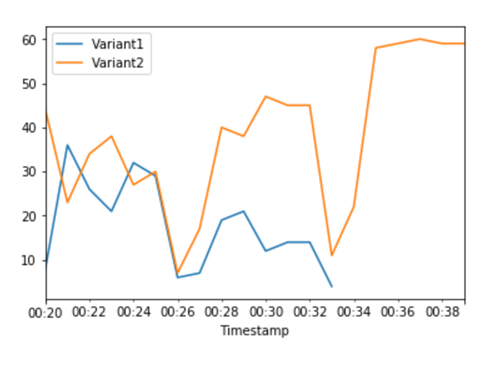
이제 엔드포인트를 안전하게 업데이트하고 엔드포인트에서 Variant1를 삭제할 수 있습니다. 엔드포인트에 새 변형을 추가하고 2 - 4단계를 수행하여 프로덕션 환경에서 새 모델을 계속 테스트할 수도 있습니다.
