기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon SageMaker AI RL은 환경을 사용하여 실제 시나리오를 모방합니다. 시뮬레이터는 환경의 현재 상태와 에이전트가 수행한 작업을 감안해 작업의 영향을 처리하고 다음 상태 및 보상을 반환합니다. 시뮬레이터는 실제로 에이전트를 훈련하는 것이 안전하지 않은 경우(예: 드론 날리기) 또는 RL 알고리즘이 수렴되는 데 시간이 오래 걸리는 경우(예: 체스를 두는 경우) 유용합니다.
다음 다이어그램은 카 레이싱 게임을 위한 시뮬레이터의 상호 작용의 예를 보여줍니다.
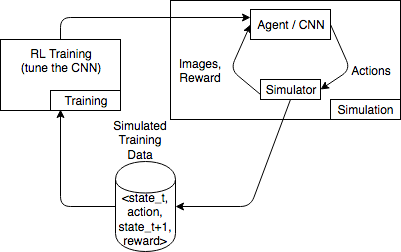
이 시뮬레이션 환경은 에이전트와 시뮬레이터로 구성되어 있습니다. 여기서, 컨볼루션 신경망(CNN)은 시뮬레이터의 이미지를 사용하여 게임 컨트롤러를 제어하기 위한 작업을 생성합니다. 이 환경에서는 여러 시뮬레이션을 사용하여 state_t, action, state_t+1 및 reward_t+1 형태의 훈련 데이터를 생성합니다. 보상 정의는 중요하며, RL 모델 품질에 영향을 미칩니다. 보상 함수의 몇 가지 예를 제공하되 사용자가 구성할 수 있도록 설정하고자 합니다.
SageMaker AI RL의 환경에 OpenAI Gym 인터페이스 사용
SageMaker AI RL에서 OpenAI Gym 환경을 사용하려면 다음 API 요소를 사용합니다. OpenAI Gym에 대한 추가 정보는 Gym 설명서
-
env.action_space- 에이전트가 취할 수 있는 작업을 정의하고, 각 작업이 연속적인지 또는 연속적인지 지정하고, 작업이 연속적인지 최소 및 최대값을 지정합니다. -
env.observation_space- 에이전트가 환경에서 받은 관측치와 더불어 연속 관측치에 대한 최소값 및 최대값을 정의합니다. -
env.reset()- 훈련 에피소드를 초기화합니다.reset()함수는 환경의 최초 상태를 반환하고, 에이전트는 최초 상태를 사용하여 첫 번째 작업을 수행합니다. 그런 다음 에피소드가 최종 상태에 도달할 때까지step()에 작업이 반복적으로 전송됩니다.step()에서done = True를 반환하면 에피소드가 종료된 것입니다. RL 도구 키트는reset()을 호출해 환경을 다시 초기화합니다. -
step()- 에이전트 액션을 입력으로 받아 환경의 다음 상태, 보상, 에피소드 종료 여부, 디버깅 정보를 전달하는info사전을 출력합니다. 입력 검증은 환경의 책임입니다. -
env.render()- 시각화가 적용된 환경에 사용됩니다. RL 도구 키트는 이 함수를 호출하여step()함수를 호출한 후 매번 환경의 시각화를 캡처합니다.
오픈 소스 환경 사용
자체 컨테이너를 구축하여 SageMaker AI RL에서 EnergyPlus 및 RoboSchool과 같은 오픈 소스 환경을 사용할 수 있습니다. EnergyPlus에 대한 추가 정보는 https://energyplus.net/
상용 환경 사용
자체 컨테이너를 구축하여 SageMaker AI RL에서 MATLAB 및 Simulink와 같은 상용 환경을 사용할 수 있습니다. 자체 라이선스를 관리해야 합니다.
