기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 레이블 지정 자동화
선택한 경우 Amazon SageMaker Ground Truth는 활성 학습을 사용하여 특정 기본 제공 작업 유형에 대한 입력 데이터의 레이블 지정을 자동화할 수 있습니다. 능동 학습(Active learning)은 작업자가 레이블을 지정해야 하는 데이터를 식별하는 기계 학습 기법입니다. Ground Truth에서는 이 기능을 자동 데이터 레이블 지정이라고 합니다. 자동 데이터 레이블 지정을 사용하면 인간 작업자만 작업할 때보다 데이터 세트에 레이블을 지정하는 데 걸리는 비용 및 시간을 줄일 수 있습니다. 자동 레이블 지정을 사용하면 SageMaker 훈련 및 추론 비용이 발생합니다.
능동 학습에 사용되는 신경망에는 모든 새 데이터 세트에 대해 많은 양의 데이터가 필요하기 때문에 대규모 데이터 세트의 경우 자동 데이터 레이블 지정을 사용하는 것이 좋습니다. 일반적으로 많은 데이터가 제공될수록 예측의 정확도가 높아집니다. 자동 레이블 지정 모델에 사용된 신경망이 높은 수준의 정확도를 얻을 수 있는 경우에만 데이터에 자동 레이블이 지정됩니다. 따라서 대규모 데이터 세트의 경우 신경망이 자동 레이블 지정에 대해 높은 정확도를 얻을 수 있기 때문에 데이터에 자동으로 레이블을 지정할 가능성이 더 큽니다. 자동 데이터 레이블 지정은 수천 개의 데이터 객체가 있을 때 가장 적합합니다. 자동 데이터 레이블 지정에 허용되는 최소 객체 수는 1,250개이지만 최소 5,000개의 객체를 제공하는 것이 좋습니다.
자동 데이터 레이블 지정은 다음과 같은 Ground Truth 기본 제공 작업 유형에서만 사용할 수 있습니다.
스트리밍 레이블 지정 작업은 자동 데이터 레이블 지정을 지원하지 않습니다.
자체 모델을 사용하여 사용자 지정 능동적 학습 워크플로를 생성하는 방법을 알아보려면 자체 모델을 사용하여 능동적 학습 워크플로를 설정하세요 섹션을 참조하세요.
자동 레이블 지정 작업에 입력 데이터 할당량이 적용됩니다. 데이터 세트 크기, 입력 데이터 크기, 해상도 제한에 대한 자세한 내용은 입력 데이터 할당량을/를 참조하세요.
참고
프로덕션 환경에서 자동 레이블 지정 모델을 사용하기 전에 해당 모델을 미세 조정 또는 테스트하거나 둘 다 수행해야 합니다. 모델의 아키텍처 및 하이퍼파라미터를 최적화하기 위해 레이블 지정 작업으로 생성된 데이터 세트에서 모델을 미세 조정하거나 다른 감독 모델을 생성 및 조정할 수 있습니다. 미세 조정 없이 추론에 모델을 사용하기로 결정한 경우 Ground Truth로 레이블이 지정된 데이터 세트의 대표(예: 무작위로 선택된) 서브셋에 대한 정확도를 평가하고 예상과 일치하는지 확인하는 것이 좋습니다.
작동 방식
레이블 지정 작업을 생성할 때 자동 데이터 레이블 지정을 활성화합니다. 작동 방법은 다음과 같습니다.
-
Ground Truth가 자동 데이터 레이블 지정 작업을 시작할 때 이는 입력 데이터 객체의 임의 샘플을 선택하여 이를 인간 작업자에게 보냅니다. 이러한 데이터 객체 중 10% 이상이 실패하면 레이블 지정 작업이 실패합니다. 레이블 지정 작업이 실패할 경우 Ground Truth가 반환하는 오류 메시지를 검토하는 것 외에도 입력 데이터가 작업자 UI에 올바르게 표시되는지, 지침이 명확한지, 작업자에게 작업을 완료할 시간을 충분히 주었는지 확인합니다.
-
레이블 지정 데이터가 반환되면 이는 훈련 세트와 검증 세트를 생성하는 데 사용됩니다. Ground Truth는 이러한 데이터 세트를 사용하여 자동 레이블 지정에 사용되는 모델을 훈련하고 검증합니다.
-
Ground Truth는 검증 데이터에 대한 추론을 위해 검증된 모델을 사용하여 배치 변환 작업을 실행합니다. 배치 추론은 검증 데이터의 각 객체에 대한 신뢰도 점수 및 품질 지표를 생성합니다.
-
자동 레이블 지정 구성 요소는 이러한 품질 지표 및 신뢰도 점수를 사용하여 품질 레이블을 보장하는 신뢰도 점수 임계값을 생성합니다.
-
Ground Truth는 추론에 대해 동일한 검증 모델을 사용하여 데이터 세트의 레이블이 지정되지 않은 데이터에 대해 배치 변환 작업을 실행합니다. 그러면 각 객체에 대한 신뢰도 점수가 생성됩니다.
-
Ground Truth 자동 레이블 지정 구성 요소는 각 객체에 대해 5단계에서 생성된 신뢰도 점수가 4단계에서 결정된 필수 임계값을 충족하는지 여부를 결정합니다. 신뢰도 점수가 임계값을 충족하는 경우, 자동 레이블 지정에 대한 예상 품질이 요청된 정확도 수준을 초과한 것이기 때문에 해당 객체는 자동으로 레이블이 지정된 것으로 간주됩니다.
-
6단계에서는 신뢰도 점수가 있는 레이블이 지정되지 않은 데이터로 이루어진 데이터 세트를 생성합니다. Ground Truth는 이 데이터 세트에서 신뢰도 점수가 낮은 데이터 포인트를 선택하여 이들을 인간 작업자에게 보냅니다.
-
Ground Truth는 기존에 인간 작업자가 레이블을 지정한 데이터와 인간 작업자가 추가로 레이블을 지정한 이 데이터를 사용하여 새 모델을 업데이트합니다.
-
이 프로세스는 데이터 세트에 모두 레이블이 지정되거나 다른 중지 조건이 충족될 때까지 반복됩니다. 예를 들어, 인간 주석 예산에 도달하면 자동 레이블 지정이 중지됩니다.
앞의 단계들이 반복해서 수행됩니다. 다음 표의 각 탭을 선택하면 객체 감지 자동 레이블 지정 작업에서 반복해서 발생하는 프로세스의 예를 볼 수 있습니다. 이 이미지의 특정 단계에서 사용된 데이터 객체 수(예: 200개)는 이 예시에만 해당됩니다. 레이블을 지정할 객체가 5,000개 미만인 경우 검증 세트 크기는 전체 데이터 세트의 20% 입니다. 입력 데이터 세트에 5,000개가 넘는 객체가 있는 경우 검증 세트 크기는 전체 데이터 세트의 10%입니다. API 작업 사용 MaxConcurrentTaskCount 시 값을 변경하여 활성 학습 반복당 수집된 인적 레이블 수를 제어할 수 있습니다CreateLabelingJob. 콘솔을 사용하여 레이블 지정 작업을 생성할 경우 이 값은 1,000으로 설정됩니다. 능동 학습 탭에 표시된 능동 학습 흐름에서 이 값은 200으로 설정됩니다.
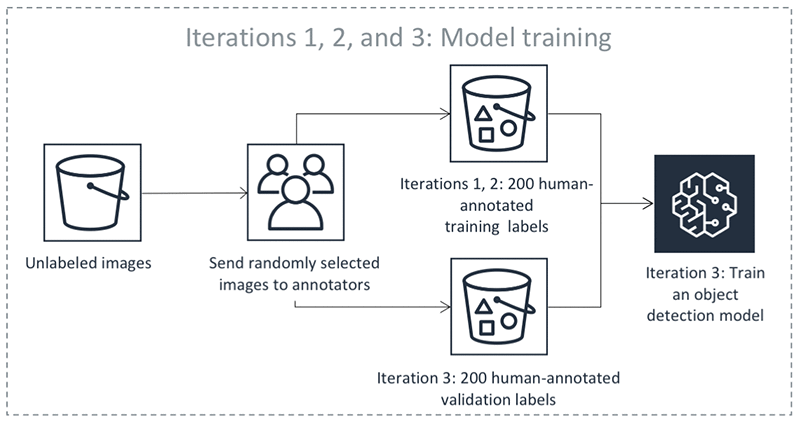
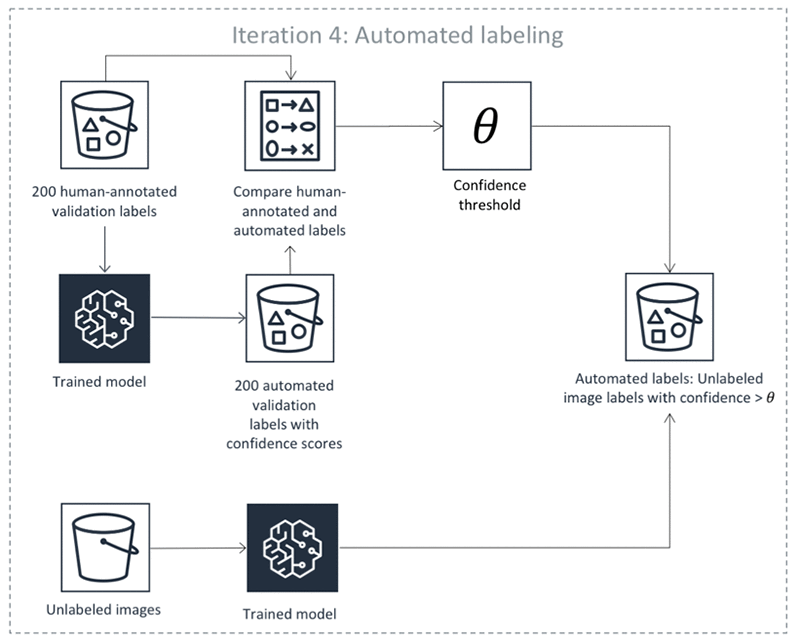
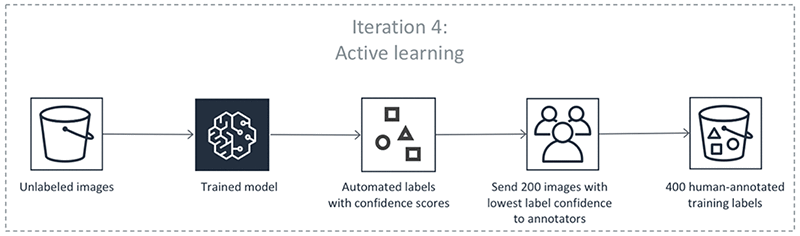
자동 레이블의 정확도
정확도의 정의는 자동 레이블 지정과 함께 사용하는 기본 제공 작업 유형에 따라 달라집니다. 모든 작업 유형에 대해 이러한 정확도 요구 사항은 Ground Truth에서 미리 결정하며 수동으로 구성할 수 없습니다.
-
이미지 분류 및 텍스트 분류의 경우 Ground Truth는 논리를 사용하여 레이블 정확도 95% 이상에 해당하는 레이블 예측 신뢰 수준을 추구합니다. 즉, Ground Truth는 자동 레이블의 정확도가 인간 레이블 지정자가 해당 예제에 제공하는 레이블과 비교할 때 최소 95%가 될 것으로 예상합니다.
-
경계 상자의 경우 자동으로 레이블이 지정된 이미지의 예상 평균 IOU(Intersection Over Union)
은 0.6입니다. 평균 IOU를 찾기 위해 Ground Truth는 모든 클래스의 이미지에 대해 예측 및 결측된 상자의 평균 IOU를 계산한 다음, 여러 클래스에 대해 이 값의 평균을 구합니다. -
의미 체계 분할의 경우 자동으로 레이블이 지정된 영상의 예상 평균 IOU는 0.7입니다. 평균 IoU를 구하기 위해 Ground Truth는 이미지 내 모든 클래스(배경 제외)의 IoU 값의 평균합니다.
능동 학습을 반복할 때마다 (위 목록의 3-6단계), 자동으로 레이블이 지정된 객체의 예상 정확도가 사전 정의된 특정 정확도 요구 사항을 충족하도록 사람이 주석을 추가한 검증 세트를 사용하여 신뢰도 임계값을 찾습니다.
자동 데이터 레이블 지정 작업 생성(콘솔)
SageMaker 콘솔에서 자동 레이블 지정을 사용하는 레이블 지정 작업을 생성하려면 다음 절차를 사용합니다.
자동 데이터 레이블 지정 작업을 생성하려면 (콘솔)
-
콘솔의 Ground Truth 레이블 지정 작업 섹션 을 SageMaker 엽니다https://console.aws.amazon.com/sagemaker/groundtruth
. -
레이블 지정 작업 생성(콘솔) 섹션을 참조하여 Job overview(작업 개요) 및 Task type(작업 유형) 섹션을 완료합니다. 사용자 작업 유형에 대해서는 자동 레이블 지정이 지원되지 않습니다.
-
Workers(작업자)에서 작업 인력 유형을 선택합니다.
-
같은 섹션에서 Enable automated data labeling(자동 데이터 레이블 지정 사용)을 선택합니다.
-
를 가이드경계 상자 도구 구성로 사용하여 섹션에서 작업자 지침을 생성합니다.
Task Type레이블 지정 도구 . 예를 들어, 레이블 지정 작업 유형으로 Semantic segmentation(의미 체계 분할)을 선택한 경우 이 섹션의 제목은 Semantic segmentation labeling tool(의미 체계 분할 레이블 지정 도구)이 됩니다. -
작업자 지침 및 대시보드를 미리 보려면 Preview(미리 보기)를 선택합니다.
-
Create(생성)을 선택합니다. 이렇게 하면 레이블 지정 작업 및 자동 레이블 지정 프로세스가 생성 및 시작됩니다.
SageMaker 콘솔의 레이블 지정 작업 섹션에 레이블 지정 작업이 표시되는 것을 볼 수 있습니다. 출력 데이터는 레이블 지정 작업을 생성할 때 지정한 Amazon S3 버킷에 나타납니다. 레이블 지정 작업 출력 데이터의 형식 및 파일 구조에 대한 자세한 내용은 작업 출력 데이터 레이블 지정 섹션을 참조하세요.
자동 데이터 레이블 지정 작업 생성(API)
를 사용하여 자동 데이터 레이블 지정 작업을 생성하려면 CreateLabelingJob 작업의 LabelingJobAlgorithmsConfig 파라미터를 SageMaker API사용합니다. CreateLabelingJob 작업을 사용하여 레이블 지정 작업을 시작하는 방법을 알아보려면 레이블 지정 작업 생성(API) 섹션을 참조하세요.
LabelingJobAlgorithmSpecificationArn 파라미터에서 자동 데이터 레이블 지정에 사용하는 알고리즘의 Amazon 리소스 이름(ARN)을 지정합니다. 자동 레이블 지정을 지원하는 네 가지 Ground Truth 기본 제공 알고리즘 중 하나를 선택합니다.
자동 데이터 레이블 지정 작업이 완료되면 Ground Truth는 자동 데이터 레이블 지정 작업에 사용된 ARN 모델의 를 반환합니다. InitialActiveLearningModelArn 파라미터에 ARN문자열 형식으로 를 제공하여 이 모델을 유사한 자동 레이블 지정 작업 유형의 시작 모델로 사용합니다. 모델의 를 검색하려면 다음과 유사한 AWS Command Line Interface (AWS CLI) 명령을 ARN사용합니다.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
자동 레이블 지정에 사용되는 ML 컴퓨팅 인스턴스(들)에 연결된 스토리지 볼륨의 데이터를 암호화하려면 VolumeKmsKeyId 파라미터에 AWS Key Management Service (AWS KMS) 키를 포함합니다. 키에 대한 AWS KMS 자세한 내용은 AWS 키 관리 서비스 개발자 안내서의 키 관리 서비스란 무엇입니까?를 참조하세요. AWS
CreateLabelingJob 작업을 사용하여 자동 데이터 레이블 지정 작업을 생성하는 예제는 SageMaker 노트북 인스턴스의 SageMaker 예제 , Ground Truth 레이블 지정 작업 섹션에서 object_detection_tutorial 예제를 참조하세요. 노트북 인스턴스를 생성하고 여는 방법은 Amazon SageMaker 노트북 인스턴스 생성 섹션을 참조하세요. SageMaker 예제 노트북에 액세스하는 방법을 알아보려면 섹션을 참조하세요예제 노트북 액세스.
자동 데이터 레이블 지정에 필요한 Amazon EC2 인스턴스
다음 표에는 훈련 및 배치 추론 작업을 위해 자동 데이터 레이블 지정을 실행하는 데 필요한 Amazon Elastic Compute Cloud(AmazonEC2) 인스턴스가 나열되어 있습니다.
| 자동 데이터 레이블 지정 작업 유형 | 훈련 인스턴스 유형 | 추론 인스턴스 유형 |
|---|---|---|
|
이미지 분류 |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
객체 감지 (경계 상자) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
텍스트 분류 |
ml.c5.2xlarge |
ml.m4.xlarge |
|
의미 체계 분할 |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* 아시아 태평양(뭄바이) 리전(ap-South-1)에서는 대신 ml.p2.8xlarge를 사용하세요.
Ground Truth는 자동 데이터 레이블 지정 작업에 사용하는 인스턴스를 관리합니다. 작업을 수행하는 데 필요한 경우 인스턴스를 생성, 구성 및 종료합니다. 이러한 인스턴스는 Amazon EC2 인스턴스 대시보드에 표시되지 않습니다.
자체 모델을 사용하여 능동적 학습 워크플로를 설정하세요
자체 알고리즘을 사용하여 능동적 학습 워크플로를 생성하여 해당 워크플로우에서 훈련 및 추론을 실행하여 데이터에 자동으로 레이블을 지정할 수 있습니다. 노트북 bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning .ipynb는 SageMaker 내장 알고리즘인 를 사용하여 이를 보여줍니다BlazingText. 이 노트북은 를 사용하여 이 워크플로를 실행하는 데 사용할 수 있는 AWS CloudFormation 스택을 제공합니다 AWS Step Functions. 이 GitHub 리포지토리
SageMaker 예제 리포지토리에서 이 노트북을 찾을 수도 있습니다. Amazon 예제 노트북을 찾는 방법을 알아보려면 예제 노트북 사용을 참조하세요. SageMaker
