Criando um cluster de banco de dados Aurora dedicado em uma região secundária
Embora um Aurora Global Database exija pelo menos um cluster de banco de dados Aurora secundário em uma Região da AWS diferente da principal, você pode usar uma configuração dedicada para o cluster secundário. Um cluster de banco de dados secundário dedicado do Aurora é aquele que não tem uma instância de banco de dados. Esse tipo de configuração pode reduzir as despesas para um banco de dados globalAurora. Em um cluster de bancos de dados Aurora, a computação e o armazenamento são desacoplados. Sem a instância de banco de dados, você não será cobrado pela computação, apenas pelo armazenamento. Se estiver configurado corretamente, o volume de armazenamento de um secundário dedicado será mantido em sincronia com o cluster de banco de dados primário.Aurora.
Você adiciona o cluster secundário como normalmente faz ao criar um banco de dados globalAurora. Se você estiver criando todos os clusters no banco de dados global, siga o procedimento em Criar um banco de dados global do Amazon Aurora. Se você já tiver um cluster de banco de dados a ser usado como cluster primário, siga o procedimento em Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Depois que o cluster de banco de dados primário do Aurora iniciar a replicação para o secundário, você deve excluir a instância de banco de dados somente leitura do Aurora do cluster de banco de dados secundário do Aurora. Esse cluster secundário agora é considerado “dedicado” porque não tem mais uma instância de banco de dados. Mesmo sem nenhuma instância de banco de dados no cluster primário, o Aurora mantém o volume de armazenamento em sincronia com o cluster de banco de dados primário do Aurora.
Atenção
Com o Aurora PostgreSQL, para criar um cluster dedicado em uma Região da AWS secundária, use a AWS CLI ou a API do RDS para adicionar a Região da AWS secundária. Ignore a etapa para criar a instância de banco de dados do leitor para o cluster secundário. Atualmente, a criação de um cluster dedicado não é compatível com o console do RDS. Para obter os procedimentos da CLI e da API a serem usados, consulte Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Se o banco de dados global estiver usando uma versão de mecanismo do Aurora PostgreSQL inferior a 13.4, 12.8 ou 11.13, criar uma instância de banco de dados de leitor em uma região secundária e, posteriormente, excluí-la pode causar um problema de vácuo do Aurora PostgreSQL na instância de banco de dados de gravador da região primária. Se você encontrar esse problema, reinicie a instância de banco de dados do gravador da região primária depois de excluir a instância de banco de dados do leitor da região secundária.
Para adicionar um cluster de banco de dados Aurora secundário dedicado ao seu banco de dados global Aurora
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação do Console de gerenciamento da AWS, escolha Databases (Bancos de dados).
-
Escolha o banco de dados Aurora global que precisa de um cluster de bancos de dados Aurora secundário. Certifique-se de que o cluster de bancos de dados Aurora primário seja
Available. -
Em Ações, selecione Adicionar região da AWS.
-
Na página Add a region (Adicionar uma região), escolha a Região da AWS secundária.
Não é possível escolher uma Região da AWS que já tenha um cluster de banco de dados Aurora secundário para o mesmo Aurora Global Database. Além disso, não pode ser a mesma região que o cluster de banco de dados primário do Aurora.
-
Preencha os campos restantes do cluster secundário do Aurora na nova Região da AWS. Essas são as mesmas opções de configuração que para qualquer instância de cluster de banco de dados deAurora.
Para um banco de dados global Aurora baseado no Aurora MySQL, desconsidere a opção Enable read replica write forwarding (Ativar encaminhamento de gravação de réplica de leitura). Esta opção não terá nenhuma função depois que você excluir a instância do leitor.
Escolha Adicionar região da AWS. Ao terminar de adicionar a região ao seu banco de dados global do Aurora, você poderá visualizá-la na lista Databases (Bancos de dados) no Console de gerenciamento da AWS, como mostrado na captura de tela.

Verifique o status do cluster de banco de dados secundário do Aurora e sua instância do leitor antes de continuar, usando o Console de gerenciamento da AWS ou a AWS CLI. Por exemplo:
$aws rds describe-db-clusters --db-cluster-identifiersecondary-cluster-id--query '*[].[Status]' --output textPode levar vários minutos para que o status de um cluster de banco de dados secundário do Aurora recém-adicionado mude de
creatingparaavailable. Quando o cluster de bancos de dados Aurora estiver disponível, você pode excluir a instância do leitor.Selecione a instância do leitor no cluster de banco de dados secundário do Aurora e escolha Delete (Excluir).

Depois de excluir a instância do leitor, o cluster secundário permanece parte do banco de dados global Aurora. Não tem nenhuma instância associada a ele, como mostrado a seguir.
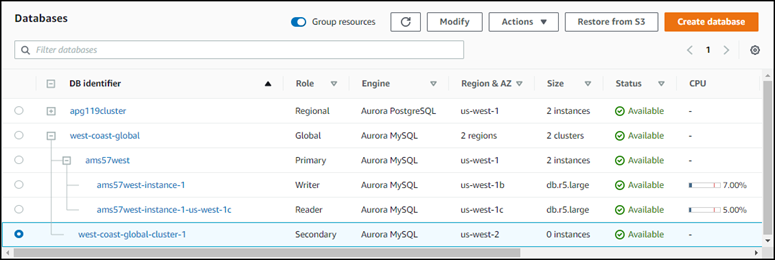
Você pode usar esse cluster de banco de dados Aurora secundário dedicado para recuperar manualmente seu Amazon Aurora Global Database de uma interrupção não planejada na Região da AWS principal, se tal interrupção ocorrer.
