Usar o machine learning do Amazon Aurora com o Aurora MySQL
Ao usar o machine learning do Amazon Aurora com o cluster de banco de dados do Aurora MySQL, é possível usar o Amazon Bedrock, o Amazon Comprehend, ou o Amazon SageMaker AI, dependendo das suas necessidades. Eles oferecem compatibilidade com casos de uso de machine learning diferentes.
Sumário
Requisitos para usar o machine learning do Aurora com o Aurora MySQL
Recursos compatíveis e limitações do machine learning do Aurora com o MySQL
Configurar o cluster de banco de dados do Aurora MySQL para usar machine learning do Aurora
Configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Bedrock
Configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Comprehend
Configuração do cluster de banco de dados do Aurora MySQL para usar o SageMaker AI
Conceder aos usuários de banco de dados acesso ao machine learning do Aurora
Usar o Amazon Bedrock com o cluster de banco de dados do Aurora MySQL
Usar o Amazon Comprehend com seu cluster de banco de dados do Aurora MySQL
Uso do SageMaker AI com o cluster de banco de dados do Aurora MySQL
Considerações de performance para usar o machine learning do Aurora com o Aurora MySQL
Requisitos para usar o machine learning do Aurora com o Aurora MySQL
AWSOs serviços do Machine Learning são serviços gerenciados que são configurados e executados em seus próprios ambientes de produção. O machine learning do Aurora é compatível com a integração ao Amazon Bedrock, ao Amazon Comprehend e ao SageMaker AI. Antes de tentar configurar seu cluster de banco de dados Aurora MySQL para usar o machine learning do Aurora, entenda os requisitos e pré-requisitos a seguir.
-
Os serviços de machine learning devem ser executados na mesma Região da AWS do cluster de banco de dados do Aurora MySQL. Não é possível usar os serviços de machine learning de um cluster de banco de dados do Aurora MySQL em uma região diferente.
-
Se o cluster de banco de dados do Aurora MySQL estiver em uma nuvem pública virtual (VPC) do serviço Amazon Bedrock, Amazon Comprehend ou SageMaker AI, o grupo de segurança da VPC precisará permitir conexões de saída com o serviço de machine learning de destino do Aurora. Para obter mais informações, consulte Controlar o tráfego para seus recursos da AWS usando grupos de segurança no Guia do usuário da Amazon VPC.
-
Você pode fazer upgrade de um cluster do Aurora que executa uma versão inferior do Aurora MySQL para uma versão superior para usar o machine learning do Aurora com esse cluster. Para obter mais informações, consulte Atualizações do mecanismo de banco de dados Amazon Aurora MySQL.
-
O cluster de banco de dados do Aurora MySQL deve usar um grupo de parâmetros de cluster de banco de dados personalizado. Ao final do processo de configuração de cada serviço de machine learning do Aurora que você deseja usar, adicione o nome do recurso da Amazon (ARN) do perfil do IAM associado que foi criado para o serviço. Recomendamos criar um grupo de parâmetros de cluster de banco de dados personalizado para seu Aurora MySQL com antecedência e configurar seu cluster de banco de dados Aurora MySQL para usá-lo de forma que esteja pronto para ser modificado no final do processo de configuração.
-
Para o SageMaker AI:
-
Os componentes de machine learning que você deseja usar para inferências devem estar configurados e prontos para uso. Durante o processo de configuração do cluster de banco de dados do Aurora MySQL, é necessário ter o ARN do endpoint do SageMaker AI disponível. Os cientistas de dados de sua equipe provavelmente estão mais aptos a trabalhar com o SageMaker AI para preparar os modelos e realizar outras tarefas desse tipo. Para começar a usar o Amazon SageMaker AI, consulte Comece a usar o Amazon SageMaker AI. Para obter mais informações sobre inferências e endpoints, consulte Real-time Inference.
-
Para usar o SageMaker AI com seus próprios dados de treinamento, é necessário configurar um bucket do Amazon S3 como parte da configuração do Aurora MySQL para o machine learning do Aurora. Para fazer isso, siga o mesmo processo geral de configuração da integração com o SageMaker AI. Para obter um resumo desse processo de configuração opcional, consulte Configuração do cluster de banco de dados do Aurora MySQL para usar o Amazon S3 para SageMaker AI (opcional).
-
-
Para bancos de dados globais do Aurora, configure os serviços de machine learning do Aurora que deseja usar em todas as Regiões da AWS que compõem seu banco de dados global do Aurora. Por exemplo, se quiser usar o machine learning do Aurora com o SageMaker AI para o banco de dados global do Aurora, faça o seguinte para cada cluster de banco de dados do Aurora MySQL em cada Região da AWS:
-
Configure os serviços do Amazon SageMaker AI com os mesmos modelos de treinamento e endpoints do SageMaker AI. Eles também devem usar os mesmos nomes.
-
Crie os perfis do IAM conforme detalhado em Configurar o cluster de banco de dados do Aurora MySQL para usar machine learning do Aurora.
-
Adicione o ARN do perfil do IAM ao grupo de parâmetros do cluster de banco de dados personalizado para cada cluster de banco de dados Aurora MySQL em cada Região da AWS.
Essas tarefas exigem que o machine learning do Aurora esteja disponível para sua versão do Aurora MySQL em todas as Regiões da AWS que compõem seu banco de dados global do Aurora.
-
Disponibilidade de regiões e versões
A disponibilidade e a compatibilidade de recursos variam entre versões específicas de cada mecanismo de banco de dados do Aurora e entre Regiões da AWS.
-
Para obter informações sobre a disponibilidade de versões e regiões do Amazon Comprehend e do Amazon SageMaker AI com o Aurora MySQL, consulte Machine learning do Aurora com o MySQL.
-
O Amazon Bedrock é compatível somente com o Aurora MySQL versão 3.06 e posterior.
Consulte informações sobre a disponibilidade de regiões do Amazon Bedrock em Model support by Região da AWS no Guia do usuário do Amazon Bedrock.
Recursos compatíveis e limitações do machine learning do Aurora com o MySQL
Ao usar o Aurora MySQL com o machine learning do Aurora, as seguintes limitações se aplicam:
-
A extensão de machine learning do Aurora não é compatível com interfaces de vetor.
-
As integrações de machine learning do Aurora não são compatíveis quando usadas em um gatilho.
As funções de machine learning do Aurora não são compatíveis com a replicação de log binário (binlog).
-
A configuração
--binlog-format=STATEMENTlança uma exceção para chamadas a funções do machine learning do Aurora. -
As funções do machine learning do Aurora não determinísticas e funções armazenadas não determinísticas não são compatíveis com o formato de binlog.
Consulte mais informações em Binary Logging Formats
na documentação do MySQL. -
-
Não há suporte para funções armazenadas que chamam tabelas com colunas sempre geradas. Isso se aplica a qualquer função armazenada do Aurora MySQL. Para saber mais sobre esse tipo de coluna, consulte CREATE TABLE and Generated Columns
(CREATE TABLE e colunas geradas) na documentação do MySQL. -
As funções do Amazon Bedrock não são compatíveis com
RETURNS JSON. É possível usarCONVERTouCASTpara converter deTEXTparaJSON, se necessário. -
O Amazon Bedrock não é compatível com solicitações em lote.
-
O Aurora MySQL é compatível com qualquer endpoint do SageMaker AI que leia e grave no formado de valores separados por vírgulas (CSV) por um
ContentTypedetext/csv. Esse formato é aceito pelos seguintes algoritmos integrados do SageMaker AI:-
Aprendizagem linear
-
Random Cut Forest
-
XGBoost
Para saber mais sobre esses algoritmos, consulte Selecionar um algoritmo no Guia do desenvolvedor do Amazon SageMaker AI.
-
Configurar o cluster de banco de dados do Aurora MySQL para usar machine learning do Aurora
Nos tópicos a seguir, você pode encontrar procedimentos de configuração separados para cada um desses serviços de machine learning do Aurora.
Tópicos
Configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Bedrock
Configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Comprehend
Configuração do cluster de banco de dados do Aurora MySQL para usar o SageMaker AI
Conceder aos usuários de banco de dados acesso ao machine learning do Aurora
Configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Bedrock
O machine learning do Aurora Machine depende de políticas e perfis do AWS Identity and Access Management (IAM) para permitir que o cluster de banco de dados do Aurora MySQL acesse e use os serviços do Amazon Bedrock. Os procedimentos a seguir criam uma política e um perfil de permissão do IAM para que o cluster de banco de dados possa se integrar ao Amazon Bedrock.
Para criar a política do IAM
Faça login no AWS Management Console e abra o console do IAM em https://console.aws.amazon.com/iam/
. -
Selecione Políticas no painel de navegação.
-
Escolha Create a policy (Criar uma política).
-
Na página Especificar permissões, em Selecionar um serviço, escolha Bedrock.
As permissões do Amazon Bedrock são exibidas.
-
Expanda Leitura e selecione InvokeModel.
-
Em Recursos, selecione Tudo.
A página Especificar permissões deve ser semelhante à figura a seguir.

-
Escolha Próximo.
-
Na página Revisar e criar, insira um nome para a política, por exemplo,
BedrockInvokeModel. -
Analise a política e escolha Criar política.
Depois, crie o perfil do IAM que usa a política de permissão do Amazon Bedrock.
Para criar perfil do IAM
Faça login no AWS Management Console e abra o console do IAM em https://console.aws.amazon.com/iam/
. -
Selecione Roles (Funções) no painel de navegação.
-
Selecione Criar perfil.
-
Na página Selecionar entidade confiável, para Caso de uso, selecione RDS.
-
Selecione RDS: adicionar perfil ao banco de dados e escolha Próximo.
-
Na página Adicionar permissões, em Políticas de permissões, selecione a política do IAM que você criou e escolha Próximo.
-
Na página Nomear, revisar e criar, insira um nome para o perfil, por exemplo,
ams-bedrock-invoke-model-role.O perfil deve se parecer com a figura a seguir.
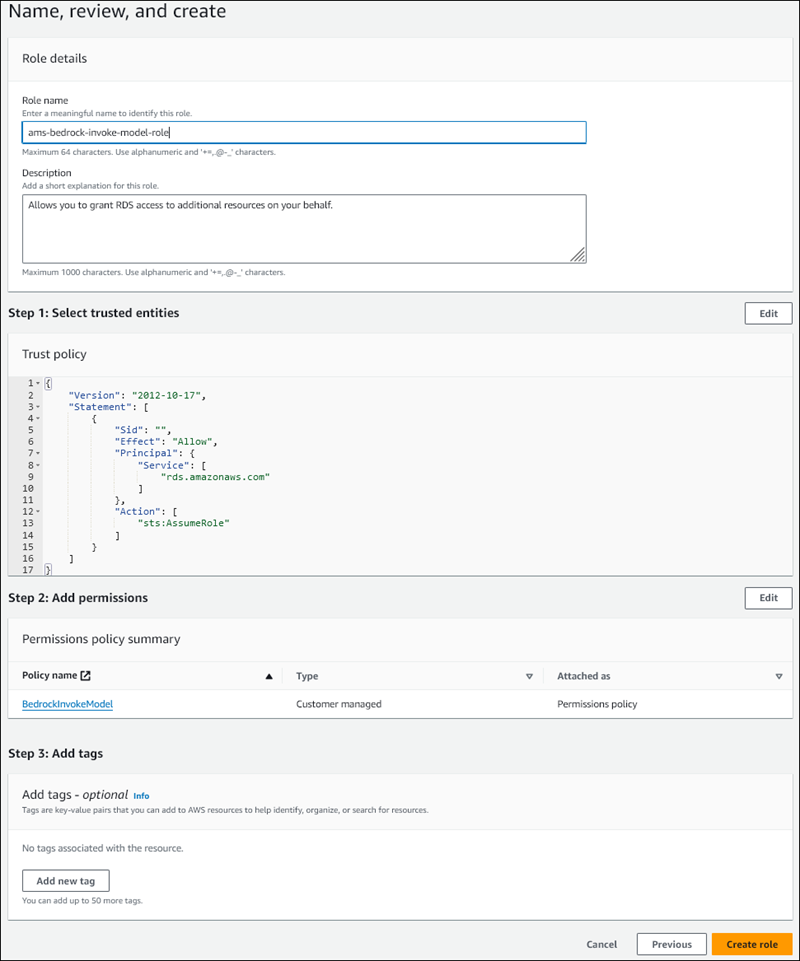
-
Revise o perfil e selecione Criar perfil.
Depois, associe o perfil do IAM do Amazon Bedrock ao cluster de banco de dados.
Como associar o perfil do IAM ao cluster de banco de dados
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha Databases (Bancos de dados) no painel de navegação.
-
Selecione o cluster de banco de dados do Aurora MySQL que você deseja conectar aos serviços do Amazon Bedrock.
-
Escolha a guia Connectivity & security (Conectividade e segurança).
-
Na seção Gerenciar perfis do IAM, escolha Selecionar os perfis do IAM a serem adicionadas a esse cluster.
-
Escolha o perfil do IAM que você criou e selecione Adicionar perfil.
O perfil do IAM está associado ao cluster de banco de dados, primeiro com o status Pendente e, depois, Ativo. Quando o processo for concluído, você poderá encontrar o perfil na lista Current IAM roles for this cluster (Perfis atuais do IAM para esse cluster).

É necessário adicionar o ARN desse perfil do IAM ao parâmetro aws_default_bedrock_role do grupo de parâmetros do cluster de banco de dados personalizado associado ao cluster de banco de dados do Aurora MySQL. Se seu cluster de banco de dados do Aurora MySQL não usa um grupo de parâmetros de cluster de banco de dados personalizado, será necessário criar um para ser usado com seu cluster de banco de dados do Aurora MySQL a fim de concluir a integração. Para obter mais informações, consulte Grupos de parâmetros do cluster de banco de dados para clusters de banco de dados do Amazon Aurora.
Como configurar o parâmetro de cluster de banco de dados
-
No console do Amazon RDS, abra a guia Configuration (Configuração) de seu cluster de banco de dados do Aurora MySQL.
-
Localize o grupo de parâmetros de cluster de banco de dados configurado para o cluster. Selecione o link para abrir o grupo de parâmetros de cluster de banco de dados personalizado e escolha Editar.
-
Encontre o parâmetro
aws_default_bedrock_roleem seu grupo de parâmetros de cluster de banco de dados personalizado. -
No campo Valor, insira o ARN do perfil do IAM.
-
Selecione Save changes (Salvar alterações) para salvar a configuração.
-
Reinicialize a instância primária de seu cluster de banco de dados do Aurora MySQL para que essa configuração de parâmetro entre em vigor.
A integração do IAM com o Amazon Bedrock está concluída. Continue configurando o cluster de banco de dados do Aurora MySQL para trabalhar com o Amazon Bedrock de acordo com Conceder aos usuários de banco de dados acesso ao machine learning do Aurora.
Configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Comprehend
O Aurora Machine Learning depende de políticas e perfis do AWS Identity and Access Management para permitir que seu cluster de banco de dados do Aurora MySQL acesse e use os serviços do Amazon Comprehend. O procedimento a seguir cria automaticamente um perfil e uma política do IAM para seu cluster para que ele possa usar o Amazon Comprehend.
Como configurar o cluster de banco de dados do Aurora MySQL para usar o Amazon Comprehend
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha Databases (Bancos de dados) no painel de navegação.
-
Selecione o cluster de banco de dados do Aurora MySQL que você deseja conectar aos serviços do Amazon Comprehend.
-
Escolha a guia Connectivity & security (Conectividade e segurança).
-
Na seção Gerenciar perfis do IAM, selecione Selecionar um serviço para se conectar a esse cluster.
-
Selecione Amazon Comprehend no menu e escolha Conectar serviço.
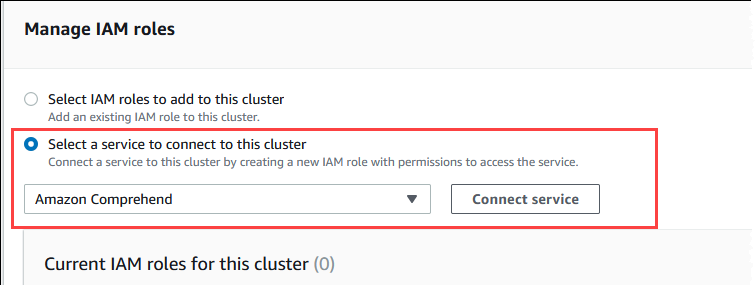
A caixa de diálogo Connect cluster to Amazon Comprehend (Conectar cluster ao Amazon Comprehend) não exige nenhuma informação adicional. No entanto, você pode ver uma mensagem notificando que a integração entre o Aurora e o Amazon Comprehend está atualmente em visualização prévia. Não deixe de ler a mensagem antes de continuar. Selecione Cancelar se preferir não continuar.
Selecione Connect service (Conectar serviço) para concluir o processo de integração.
O Aurora cria o perfil do IAM. Ele também cria a política que permite que o cluster de banco de dados do Aurora MySQL use os serviços do Amazon Comprehend e anexa a política ao perfil. Quando o processo for concluído, você poderá encontrar o perfil na lista Current IAM roles for this cluster (Perfis atuais do IAM para esse cluster), conforme mostrado na imagem a seguir.

É necessário adicionar o ARN desse perfil do IAM ao parâmetro
aws_default_comprehend_roledo grupo de parâmetros do cluster de banco de dados personalizado associado ao cluster de banco de dados do Aurora MySQL. Se seu cluster de banco de dados do Aurora MySQL não usa um grupo de parâmetros de cluster de banco de dados personalizado, será necessário criar um para ser usado com seu cluster de banco de dados do Aurora MySQL a fim de concluir a integração. Para obter mais informações, consulte Grupos de parâmetros do cluster de banco de dados para clusters de banco de dados do Amazon Aurora.Depois de criar seu grupo de parâmetros de cluster de banco de dados personalizado e associá-lo ao seu cluster de banco de dados do Aurora MySQL, você poderá continuar seguindo estas etapas.
Se o cluster usa um grupo de parâmetros de cluster de banco de dados personalizado, faça o seguinte.
No console do Amazon RDS, abra a guia Configuration (Configuração) de seu cluster de banco de dados do Aurora MySQL.
-
Localize o grupo de parâmetros de cluster de banco de dados configurado para o cluster. Selecione o link para abrir o grupo de parâmetros de cluster de banco de dados personalizado e escolha Editar.
Encontre o parâmetro
aws_default_comprehend_roleem seu grupo de parâmetros de cluster de banco de dados personalizado.No campo Valor, insira o ARN do perfil do IAM.
Selecione Save changes (Salvar alterações) para salvar a configuração. Na imagem a seguir, é fornecido um exemplo.
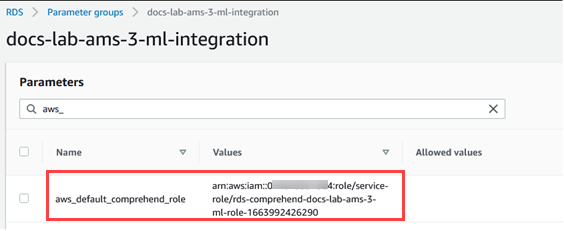
Reinicialize a instância primária de seu cluster de banco de dados do Aurora MySQL para que essa configuração de parâmetro entre em vigor.
A integração do IAM com o Amazon Comprehend está concluída. Continue configurando seu cluster de banco de dados do Aurora MySQL para trabalhar com o Amazon Comprehend concedendo acesso aos usuários apropriados do banco de dados.
Configuração do cluster de banco de dados do Aurora MySQL para usar o SageMaker AI
O procedimento a seguir cria automaticamente o perfil e uma política do IAM para seu cluster de banco de dados do Aurora MySQL para que ele possa usar o SageMaker AI. Antes de tentar seguir esse procedimento, é necessário que o endpoint do SageMaker AI esteja disponível para poder inseri-lo quando necessário. Normalmente, os cientistas de dados de sua equipe trabalham para produzir um endpoint que você possa usá-lo em seu cluster de banco de dados do Aurora MySQL. Você pode encontrar esses endpoints no console do SageMaker AI

Como configurar o cluster de banco de dados do Aurora MySQL para usar o SageMaker AI
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Selecione Bancos de dados no menu de navegação do Amazon RDS e depois o cluster de banco de dados do Aurora MySQL que deseja conectar aos serviços do SageMaker AI.
-
Escolha a guia Connectivity & security (Conectividade e segurança).
-
Role a página para a seção Manage IAM roles (Gerenciar perfis do IAM) e depois Select a service to connect to this cluster (Selecionar um serviço para se conectar a esse cluster). Selecione SageMaker AI no seletor.
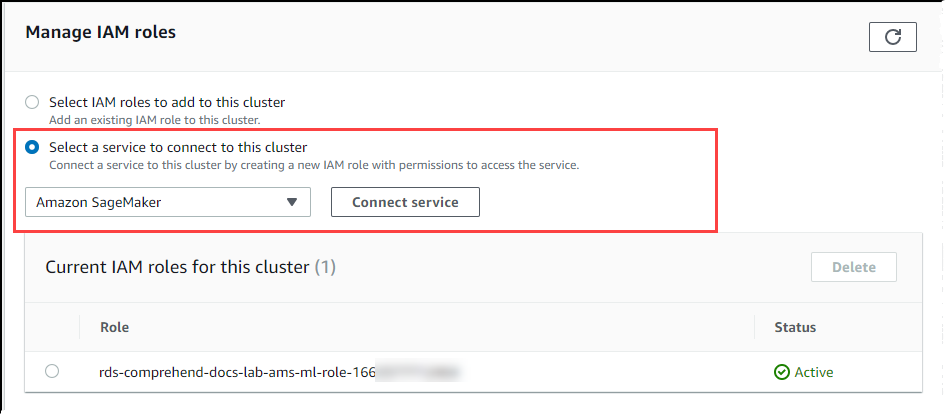
Escolha Connect service (Conectar serviço).
Na caixa de diálogo Conectar cluster ao SageMaker AI, insira o ARN do endpoint do SageMaker AI.
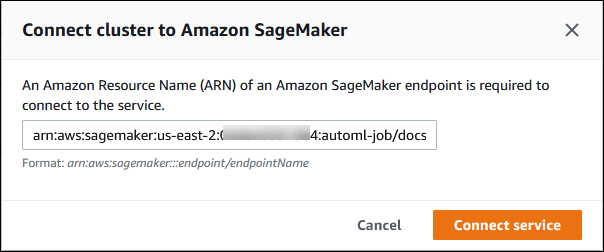
-
O Aurora cria o perfil do IAM. Ele também cria a política que permite que o cluster de banco de dados do Aurora MySQL use os serviços do SageMaker AI e anexa a política ao perfil. Quando o processo for concluído, você poderá encontrar o perfil na lista Current IAM roles for this cluster (Perfis atuais do IAM para esse cluster).
Abra o console do IAM em https://console.aws.amazon.com/iam/
. Selecione Roles (Perfis) na seção Access management (Gerenciamento de acesso) do menu de navegação do AWS Identity and Access Management.
Encontre o perfil dentre os listados. Seu nome usa o padrão a seguir.
rds-sagemaker-your-cluster-name-role-auto-generated-digitsAbra a página de resumo da função e localize o ARN. Anote o ARN ou copie-o usando o widget de cópia.
Abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. Selecione o cluster de banco de dados do Aurora MySQL e depois a guia Configuration (Configuração).
Localize o grupo de parâmetros de cluster de banco de dados e depois clique no link para abrir o grupo de parâmetros de cluster de banco de dados personalizado. Encontre o parâmetro
aws_default_sagemaker_rolee insira o ARN do perfil do IAM no campo Value (Valor) e salve a configuração.Reinicialize a instância primária de seu cluster de banco de dados do Aurora MySQL para que essa configuração de parâmetro entre em vigor.
Agora a configuração do IAM está concluída. Continue configurando seu cluster de banco de dados do Aurora MySQL para trabalhar com o SageMaker AI concedendo acesso aos usuários apropriados do banco de dados.
Se você quiser usar seus modelos do SageMaker AI para treinamento em vez de usar componentes pré-criados do SageMaker AI, também precisará adicionar o bucket do Amazon S3 ao seu cluster de banco de dados do Aurora MySQL, conforme descrito no Configuração do cluster de banco de dados do Aurora MySQL para usar o Amazon S3 para SageMaker AI (opcional) a seguir.
Configuração do cluster de banco de dados do Aurora MySQL para usar o Amazon S3 para SageMaker AI (opcional)
Para usar o SageMaker AI com seus próprios modelos em vez de usar componentes pré-criados fornecidos pelo SageMaker AI, é necessário configurar um bucket do Amazon S3 para o cluster de banco de dados do Aurora MySQL usar. Para obter mais informações sobre como criar um bucket do Amazon S3, consulte Criação de um bucket, no Guia do usuário do Amazon Simple Storage Service.
Como configurar o cluster de banco de dados do Aurora MySQL para usar um bucket do Amazon S3 para SageMaker AI
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Selecione Bancos de dados no menu de navegação do Amazon RDS e depois o cluster de banco de dados do Aurora MySQL que deseja conectar aos serviços do SageMaker AI.
-
Escolha a guia Connectivity & security (Conectividade e segurança).
-
Role a página para a seção Manage IAM roles (Gerenciar perfis do IAM) e, depois, Select a service to connect to this cluster (Selecionar um serviço para se conectar a esse cluster). Selecione Amazon S3 no seletor.

Escolha Connect service (Conectar serviço).
Na caixa de diálogo Conectar cluster ao Amazon S3, insira o ARN do bucket do Amazon S3, como mostrado na imagem a seguir.
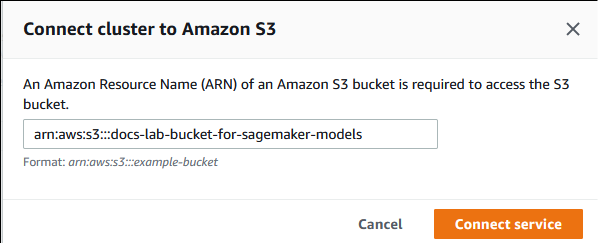
Selecione Connect service (Conectar serviço) para concluir o processo.
Para obter mais informações sobre o uso de buckets do Amazon S3 com o SageMaker AI, consulte Especificar um bucket do Amazon S3 para fazer upload de conjuntos de dados de treinamento e armazenar dados de saída no Guia do desenvolvedor do Amazon SageMaker AI. Para saber mais sobre como trabalhar com o SageMaker AI, consulte Começar a usar instâncias de notebook do Amazon SageMaker AI no Guia do desenvolvedor do Amazon SageMaker AI.
Conceder aos usuários de banco de dados acesso ao machine learning do Aurora
Os usuários do banco de dados devem receber permissão para invocar as funções de machine learning do Aurora. A forma como você concede a permissão depende da versão do MySQL que você usa para seu cluster de banco de dados do Aurora MySQL, conforme descrito a seguir. A forma como você faz isso depende da versão do MySQL que seu cluster de banco de dados do Aurora MySQL usa.
Para o Aurora MySQL versão 3 (compatível com o MySQL 8.0), os usuários do banco de dados devem receber o perfil de banco de dados apropriado. Consulte mais informações em Using Roles
no MySQL 8.0 Reference Manual. Para o Aurora MySQL versão 2 (compatível com o MySQL 5.7), os usuários do banco de dados recebem privilégios. Consulte mais informações em Access Control and Account Management
no MySQL 5.7 Reference Manual.
A tabela a seguir mostra os perfis e privilégios que os usuários do banco de dados precisam para trabalhar com funções de machine learning.
| Aurora MySQL versão 3 (perfil) | Aurora MySQL versão 2 (privilégio) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOCAR COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOCAR SAGEMAKER |
Conceder acesso às funções do Amazon Bedrock
Para conceder aos usuários do banco de dados acesso às funções do Amazon Bedrock, use a seguinte instrução SQL:
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Os usuários do banco de dados também precisam receber permissões EXECUTE para as funções criadas para trabalhar com o Amazon Bedrock:
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
Por fim, os usuários do banco de dados devem ter seus perfis definidos como AWS_BEDROCK_ACCESS:
SET ROLE AWS_BEDROCK_ACCESS;
As funções do Amazon Bedrock já estão disponíveis para uso.
Conceder acesso às funções do Amazon Comprehend
Para conceder aos usuários do banco de dados acesso às funções do Amazon Comprehend, use a declaração apropriada para sua versão do Aurora MySQL.
Aurora MySQL versão 3 (compatível com o MySQL 8.0)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL versão 2 (compatível com o MySQL 5.7)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
As funções do Amazon Comprehend agora estão disponíveis para uso. Para obter exemplos de uso, consulte Usar o Amazon Comprehend com seu cluster de banco de dados do Aurora MySQL.
Concessão de acesso às funções do SageMaker AI
Para conceder aos usuários do banco de dados acesso às funções do SageMaker AI, use a declaração apropriada para sua versão do Aurora MySQL.
Aurora MySQL versão 3 (compatível com o MySQL 8.0)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL versão 2 (compatível com o MySQL 5.7)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
Os usuários do banco de dados também precisam receber permissões EXECUTE para as funções criadas para trabalhar com o SageMaker AI. Suponha que você tenha criado duas funções, db1.anomoly_score e db2.company_forecasts, para invocar os serviços de seu endpoint do SageMaker AI. Você deve conceder privilégios de execução conforme mostrado no exemplo a seguir.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
As funções do SageMaker AI agora estão disponíveis para uso. Para obter exemplos de uso, consulte Uso do SageMaker AI com o cluster de banco de dados do Aurora MySQL.
Usar o Amazon Bedrock com o cluster de banco de dados do Aurora MySQL
Para usar o Amazon Bedrock, você cria uma função definida pelo usuário (UDF) no banco de dados do Aurora MySQL que invoca um modelo. Consulte mais informações em Supported models in Amazon Bedrock no Guia do usuário do Amazon Bedrock.
Uma UDF usa a seguinte sintaxe:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
As funções do Amazon Bedrock não são compatíveis com
RETURNS JSON. É possível usarCONVERTouCASTpara converter deTEXTparaJSON, se necessário. -
Se você não especificar
CONTENT_TYPEouACCEPT, o padrão seráapplication/json. -
Se você não especificar
TIMEOUT_MS, o valor deaurora_ml_inference_timeoutserá usado.
Por exemplo, a UDF a seguir invoca o modelo Amazon Titan Text Express:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
Para permitir que um usuário do banco de dados use essa função, use o seguinte comando do SQL:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
Depois, o usuário pode chamar invoke_titan como qualquer outra função, conforme mostrado no exemplo a seguir. Formate o corpo da solicitação de acordo com os modelos de texto do Amazon Titan.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
Para outros modelos que você usa, formate o corpo da solicitação de forma adequada para eles. Consulte mais informações em Inference parameters for foundation models no Guia do usuário do Amazon Bedrock.
Usar o Amazon Comprehend com seu cluster de banco de dados do Aurora MySQL
Para o Aurora MySQL, o machine learning do Aurora fornece as duas funções integradas a seguir para trabalhar com o Amazon Comprehend e seus dados de texto. Forneça o texto para analisar (input_data) e especifique o idioma (language_code).
- aws_comprehend_detect_sentiment
-
Essa função identifica uma postura emocional positiva, negativa, neutra ou mista no texto. A documentação de referência dessa função é a seguinte.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )Para saber mais, consulte Sentiment (Sentimento) no Amazon Comprehend Developer Guide (Guia do desenvolvedor do Amazon Comprehend).
- aws_comprehend_detect_sentiment_confidence
-
Essa função mede o nível de confiança do sentimento detectado em determinado texto. Ele retorna um valor (tipo,
double) que indica a confiança do sentimento atribuído pela função aws_comprehend_detect_sentiment ao texto. A confiança é uma métrica estatística entre 0 e 1. Quanto maior for o nível de confiança, mais peso você poderá atribuir ao resultado. Veja um resumo da documentação da função.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
Nas duas funções (aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment), o max_batch_size usa um valor padrão de 25 se nenhum for especificado. O tamanho do lote deve ser sempre maior que 0. Você pode usar max_batch_size para ajustar a performance das chamadas de função do Amazon Comprehend. Um lote grande troca performance mais alta por maior uso de memória no cluster de banco de dados do Aurora MySQL. Para obter mais informações, consulte Considerações de performance para usar o machine learning do Aurora com o Aurora MySQL.
Para obter mais informações sobre parâmetros e tipos de retorno para as funções de detecção de sentimentos no Amazon Comprehend, consulte DetectSentiment
exemplo Exemplo: uma consulta simples utilizando as funções do Amazon Comprehend
Veja um exemplo de uma consulta simples que invoca essas duas funções para ver o nível de satisfação de clientes com sua equipe de atendimento. Suponha que você tenha uma tabela de banco de dados (support) que armazene o feedback do cliente após cada solicitação de ajuda. Esta consulta de exemplo aplica as duas funções incorporadas ao texto na coluna feedback da tabela e gera os resultados. Os valores de confiança retornados pela função são duplos entre 0.0 e 1.0. Para obter uma saída mais legível, esta consulta arredonda os resultados para 6 pontos decimais. Para facilitar as comparações, ela também classifica primeiro os resultados em ordem decrescente, começando pelo resultado com o maior grau de confiança.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
exemplo Exemplo: determinar o sentimento médio para um texto acima de um nível de confiança específico
Uma típica consulta do Amazon Comprehend procura linhas em que o sentimento é um valor especificado, com um nível de confiança superior a um número especificado. Por exemplo, a consulta a seguir mostra como você pode determinar o sentimento médio de documentos em seu banco de dados. A consulta considera somente documentos em que a confiança da avaliação é superior a 80%.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Uso do SageMaker AI com o cluster de banco de dados do Aurora MySQL
Para usar a funcionalidade do SageMaker AI de seu cluster de banco de dados do Aurora MySQL, você precisa criar funções armazenadas que incorporem suas chamadas ao endpoint do SageMaker AI e seus recursos de inferência. Isso é feito usando CREATE FUNCTION do MySQL geralmente da mesma forma realizada para outras tarefas de processamento em seu cluster de banco de dados do Aurora MySQL.
Para usar modelos implantados no SageMaker AI para inferência, crie funções definidas pelo usuário usando as instruções da linguagem de definição de dados (DDL) do MySQL para funções armazenadas. Cada função armazenada representa o endpoint do SageMaker AI que hospeda o modelo. Ao definir tal função, especifique os parâmetros de entrada para o modelo, o endpoint do SageMaker AI específico a ser invocado e o tipo de retorno. A função retorna a inferência computada pelo endpoint do SageMaker AI após a aplicação do modelo com os parâmetros de entrada.
Todas as funções armazenadas de machine learning do Aurora retornam tipos numéricos ou VARCHAR. Você pode usar qualquer tipo numérico, exceto BIT. Outros tipos, como JSON, BLOB, TEXT e DATE, não são permitidos.
O exemplo a seguir mostra a sintaxe CREATE FUNCTION para trabalhar com o SageMaker AI.
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
Essa é uma extensão da declaração DDL CREATE FUNCTION regular. Na instrução CREATE FUNCTION que define a função do SageMaker AI, não especifique um corpo de função. Em vez disso, especifique a palavra-chave ALIAS no lugar geralmente usado para o corpo da função. No momento, o machine learning do Aurora apenas oferece suporte a aws_sagemaker_invoke_endpoint para essa sintaxe estendida. Você deve especificar o parâmetro endpoint_name. Um endpoint do SageMaker AI pode ter características diferentes para cada modelo.
nota
Para obter mais informações sobreCREATE FUNCTION, consulte CREATE PROCEDURE and CREATE FUNCTION Statements
O parâmetro max_batch_size é opcional. Por padrão, o tamanho máximo do lote é 10 mil. Você pode usar esse parâmetro em sua função para restringir o número máximo de entradas processadas em uma solicitação em lote para o SageMaker AI. O parâmetro max_batch_size pode ajudar a evitar um erro causado por entradas muito grandes, ou para fazer o SageMaker AI retornar uma resposta com mais rapidez. O parâmetro afeta o tamanho de um buffer interno usado para processamento de solicitações do SageMaker AI. Especificar um valor muito grande para max_batch_size pode causar sobrecarga substancial de memória em sua instância de banco de dados.
Recomendamos manter a configuração MANIFEST em seu valor padrão de OFF. Embora seja possível usar a opção MANIFEST ON, alguns recursos do SageMaker AI não podem usar diretamente o CSV exportado com essa opção. O formato do manifesto não é compatível com o formato de manifesto esperado do SageMaker AI.
Crie uma função armazenada separada para cada um de seus modelos do SageMaker AI. Esse mapeamento de funções para modelos é necessário pois um endpoint está associado a um modelo específico e cada modelo aceita parâmetros diferentes. Uso de tipos de SQL para as entradas do modelo e o tipo de saída do modelo ajuda a evitar erros de conversão de tipos ao movimentar dados entre serviços da AWS. É possível controlar quem pode aplicar o modelo. Você também pode controlar as características do tempo de execução especificando um parâmetro que representa o tamanho máximo do lote.
No momento, as funções de machine learning do Aurora têm a propriedade NOT DETERMINISTIC. Se você não especificar essa propriedade explicitamente, o Aurora definirá NOT DETERMINISTIC automaticamente. Esse requisito se deve ao fato de ser possível alterar o modelo do SageMaker AI sem nenhuma notificação ao banco de dados. Se isso acontecer, as chamadas para uma função de machine learning do Aurora talvez retornem resultados diferentes para a mesma entrada em uma única transação.
Não é possível usar as características CONTAINS SQL, NO SQL, READS SQL DATA e MODIFIES SQL DATA na instrução CREATE
FUNCTION.
Veja a seguir um exemplo de uso de invocação de um endpoint do SageMaker AI para detectar anomalias. Há um endpoint random-cut-forest-model do SageMaker AI. O modelo correspondente já foi treinado pelo algoritmo random-cut-forest. Para cada entrada, o modelo retorna uma pontuação de anomalia. Este exemplo mostra os pontos de dados cuja pontuação é maior do que 3 desvios padrão (aproximadamente o percentil 99,9) da pontuação média.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
Requisito de conjunto de caracteres para funções do SageMaker AI que retornam strings
Recomenda-se especificar um conjunto de caracteres de utf8mb4 como tipo de retorno para as funções do SageMaker AI que retornam valores de string. Se isso não for prático, use um comprimento de string grande o suficiente para que o tipo de retorno mantenha um valor representado no conjunto de caracteres utf8mb4. A exemplo a seguir mostra como declarar o conjunto de caracteres utf8mb4 para a função.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...Atualmente, cada função do SageMaker AI que retorna uma string usa o conjunto de caracteres utf8mb4 para o valor de retorno. O valor de retorno usa esse conjunto de caracteres mesmo que a sua função do SageMaker AI declare um conjunto de caracteres diferente para o tipo de retorno, de forma implícita ou explícita. Se a sua função de do SageMaker AI declarar um conjunto de caracteres diferente para o valor de retorno, os dados retornados poderão ser truncados silenciosamente se forem armazenados em uma coluna de tabela que não tenha o comprimento suficiente. Por exemplo, uma consulta com uma cláusula DISTINCT cria uma tabela temporária. Assim, o resultado da função do SageMaker AI poderá ser truncado devido à maneira como as strings são tratadas internamente durante uma consulta.
Exportar dados ao Amazon S3 para treinamento de modelos do SageMaker AI (avançado)
Recomendamos que você comece a usar o machine learning do Aurora e o SageMaker AI usando alguns dos algoritmos fornecidos e que os cientistas de dados de sua equipe forneçam os endpoints do SageMaker AI que você pode usar com seu código SQL. A seguir, você encontrará informações mínimas sobre como usar seu próprio bucket do Amazon S3 com seus próprios modelos do SageMaker AI e o cluster de banco de dados do Aurora MySQL.
O machine learning consiste em duas etapas principais: treinamento e inferência. Para treinar modelos do SageMaker AI, exporte os dados para um bucket do Amazon S3. O bucket do Amazon S3 é usado por uma instância de bloco de anotações Jupyter do SageMaker AI para treinar o modelo antes de ser implantado. Você pode usar a instrução SELECT INTO OUTFILE S3 para consultar dados de um cluster de banco de dados Aurora MySQL e salvá-los diretamente em arquivos de texto armazenados em um bucket do Amazon S3. Depois, a instância de bloco de anotações consumirá os dados do bucket do Amazon S3 para treinamento.
O machine learning do Aurora estende a sintaxe SELECT INTO OUTFILE existente no Aurora MySQL para exportar dados no formato CSV. O arquivo CSV gerado pode ser consumido diretamente por modelos que precisam desse formato para fins de treinamento.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;A extensão oferece suporte ao formato CSV padrão.
-
O formato
TEXTé igual ao formato de exportação do MySQL existente. Esse é o formato padrão. -
O formato
CSVé um formato recém-apresentado que segue a especificação em RFC-4180. -
Se você especificar a palavra-chave opcional
HEADER, o arquivo de saída conterá uma linha de cabeçalho. Os rótulos na linha de cabeçalho correspondem aos nomes de coluna da instruçãoSELECT. -
Você ainda pode usar as palavras-chave
CSVeHEADERcomo identificadores.
A sintaxe estendida e a gramática de SELECT INTO agora tem a seguinte estrutura:
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Considerações de performance para usar o machine learning do Aurora com o Aurora MySQL
Os serviços do Amazon Bedrock, do Amazon Comprehend e do SageMaker AI fazem a maior parte do trabalho quando invocados por uma função de machine learning do Aurora. Isso significa que você pode escalar esses recursos conforme necessário, de forma independente. Para seu cluster de banco de dados do Aurora MySQL, você pode tornar suas chamadas de função o mais eficientes possível. A seguir, você encontrará algumas considerações de performance a serem observadas ao trabalhar com o machine learning do Aurora.
Modelo e prompt
O desempenho ao usar o Amazon Bedrock depende muito do modelo e do prompt que você usa. Selecione um modelo e um prompt que sejam ideais para seu caso de uso.
Cache de consultas
O cache de consulta do Aurora MySQL não funciona para funções do machine learning do Aurora. O Aurora MySQL não armazena resultados de consultas no cache de consultas para nenhuma declaração de SQL que chame funções do machine learning do Aurora.
Otimização em lotes para chamadas de função do machine learning do Aurora
O principal aspecto de performance do machine learning do Aurora que pode ser influenciado no seu cluster do Aurora é a configuração do modo em lotes para chamadas às funções armazenadas do machine learning do Aurora. As funções de machine learning geralmente exigem sobrecarga substancial, o que torna impraticável chamar um serviço externo separadamente para cada linha. O machine learning do Aurora é capaz de minimizar essa sobrecarga, combinando as chamadas para o serviço de machine learning do Aurora externo para diversas linhas em um único lote. O machine learning do Aurora obtêm as respostas para todas as linhas de entrada e retorna essas respostas, uma linha por vez, à consulta durante a sua execução. Essa otimização melhora a taxa de transferência e a latência de suas consultas do Aurora, sem alterar os resultados.
Ao criar uma função armazenada do Aurora que está conectada a um endpoint do SageMaker AI, defina o parâmetro de tamanho do lote. Esse parâmetro influencia quantas linhas são transferidas ao SageMaker AI para cada chamada subjacente. Para consultas que processam grandes quantidades de linhas, a sobrecarga para realizar uma chamada do SageMaker AI separada para cada linha pode ser substancial. Quanto maior for o conjunto de dados processado pelo procedimento armazenado, maior poderá ser o tamanho do lote.
Se houver a possibilidade de aplicar a otimização do modo em lote a uma função do SageMaker AI, isso poderá ser determinado ao verificar o plano de consulta produzido pela instrução EXPLAIN PLAN. Nesse caso, a coluna extra no plano de execução inclui Batched machine learning. O exemplo a seguir mostra uma chamada para uma função do SageMaker AI que usa o modo em lote.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
Ao chamar uma das funções integradas do Amazon Comprehend, você pode controlar o tamanho do lote especificando o parâmetro max_batch_size opcional. Esse parâmetro restringe o número máximo de valores input_text processados em cada lote. Ao enviar vários itens por vez, ele reduz o número de percursos de ida e volta entre o Aurora e o Amazon Comprehend. Limitar o tamanho do lote é útil em situações, como uma consulta com uma cláusula LIMIT. Usando um valor pequeno para max_batch_size, é possível evitar a invocação do Amazon Comprehend mais vezes do que a quantidade de textos de entrada.
A otimização em lotes para avaliar funções do machine learning do Aurora é aplicável nos seguintes casos:
-
Chamadas de funções dentro da lista de seleção ou da cláusula
WHEREde instruçõesSELECT -
Chamadas de funções na lista
VALUESde instruçõesINSERTeREPLACE -
Funções do SageMaker AI nos valores
SETem instruçõesUPDATE:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Monitorar o machine learning do Aurora
É possível monitorar as operações em lote de machine learning do Aurora consultando diversas variáveis globais, conforme mostrado no exemplo a seguir.
show status like 'Aurora_ml%';
É possível redefinir as variáveis de status usando uma declaração FLUSH STATUS. Assim, todas as quantidades representam totais, médias e assim por diante, desde a última vez em que a variável foi redefinida.
Aurora_ml_logical_request_cnt-
O número de solicitações lógicas que a instância de banco de dados avaliou para serem enviadas aos serviços de machine learning do Aurora desde a última redefinição de status. Dependendo se o lote foi ou não usado, esse valor pode ser maior que
Aurora_ml_actual_request_cnt. Aurora_ml_logical_response_cnt-
A contagem agregada de respostas que o Aurora MySQL recebe dos serviços de machine learning do Aurora entre todas as consultas executadas por usuários da instância de banco de dados.
Aurora_ml_actual_request_cnt-
A contagem agregada de solicitações que o Aurora MySQL faz nos serviços de machine learning do Aurora entre todas as consultas executadas por usuários da instância de banco de dados.
Aurora_ml_actual_response_cnt-
A contagem agregada de respostas que o Aurora MySQL recebe dos serviços de machine learning do Aurora entre todas as consultas executadas por usuários da instância de banco de dados.
Aurora_ml_cache_hit_cnt-
A contagem agregada de acertos do cache interno que o Aurora MySQL recebe dos serviços de machine learning do Aurora entre todas as consultas executadas por usuários da instância de banco de dados.
Aurora_ml_retry_request_cnt-
O número de novas solicitações que a instância de banco de dados enviou aos serviços de machine learning do Aurora desde a última redefinição de status.
Aurora_ml_single_request_cnt-
A contagem agregada de funções do machine learning do Aurora que são avaliadas pelo modo que não seja em lote entre todas as consultas executadas por usuários da instância de banco de dados.
Para obter informações sobre como monitorar a performance das operações do SageMaker AI chamadas a partir de funções do machine learning do Aurora, consulte o tópico sobre como Monitorar o Amazon SageMaker AI.
