Trabalhos de transmissão de ETL no AWS Glue
É possível criar trabalhos de extração, transformação e carregamento (ETL) de transmissão que sejam executados continuamente e que consumam dados de fontes de transmissão, como o Amazon Kinesis Data Streams, Apache Kafka e Amazon Managed Streaming for Apache Kafka (Amazon MSK). Os trabalhos limpam e transformam os dados e, em seguida, carregam os resultados em data lakes do Amazon S3 ou armazenamentos de dados JDBC.
Além disso, você pode produzir dados para streams do Amazon Kinesis Data Streams. Esse atributo só está disponível ao escrever AWS Glue scripts. Para ter mais informações, consulte Conexões do Kinesis.
Por padrão, o AWS Glue processa e grava dados em janelas de 100 segundos. Isso permite que os dados sejam processados de forma eficiente e que as agregações sejam realizadas em dados que chegam mais tarde do que o esperado. É possível modificar esse tamanho da janela para aumentar a pontualidade ou a precisão da agregação. Trabalhos de transmissão do AWS Glue usam pontos de verificação em vez de marcadores de trabalho para rastrear os dados que foram lidos.
nota
O AWS Glue cobra por hora por trabalhos de ETL de transmissão enquanto eles estão em execução.
Este vídeo discute os desafios de custo de ETL de streaming e os atributos de economia de custos do AWS Glue.
A criação de um trabalho de ETL de streaming envolve as seguintes etapas:
-
Para uma fonte de transmissão Apache Kafka, crie um conexão do AWS Glue com a origem do Kafka ou o cluster do Amazon MSK.
-
Crie manualmente uma tabela do Data Catalog para a fonte de transmissão.
-
Crie um trabalho de ETL para a fonte de dados de streaming. Defina propriedades de trabalho específicas de streaming e forneça seu próprio script ou, opcionalmente, modifique o script gerado.
Para ter mais informações, consulte ETL de streaming no AWS Glue.
Ao criar um trabalho de ETL de transmissão para o Amazon Kinesis Data Streams, você não precisa criar uma conexão do AWS Glue. No entanto, se houver uma conexão anexada ao trabalho de ETL de transmissão do AWS Glue que tenha o Kinesis Data Streams como origem, será necessário um endpoint de nuvem privada virtual (VPC) para o Kinesis. Para obter mais informações, consulte Criar um endpoint de interface no Guia do usuário da Amazon VPC. Ao especificar uma transmissão do Amazon Kinesis Data Streams em outra conta, você deve configurar as funções e políticas para permitir o acesso entre contas. Para obter mais informações, consulte Exemplo: Ler de uma transmissão do Kinesis em outra conta.
Os trabalhos de ETL do AWS Glue podem detectar automaticamente dados compactados, descompactar de forma transparente os dados de fluxo, realizar as transformações usuais na fonte de entrada e carregar no armazenamento de saída.
O AWS Glue oferece suporte à descompactação automática para os seguintes tipos de compactação, considerando o formato de entrada:
| Tipo de compactação | Arquivo Avro | Dado Avro | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | Sim | Sim | Sim | Sim | Sim |
| GZIP | Não | Sim | Sim | Sim | Sim |
| SNAPPY | Sim (Snappy bruto) | Sim (Snappy com enquadramento) | Sim (Snappy com enquadramento) | Sim (Snappy com enquadramento) | Sim (Snappy com enquadramento) |
| XZ | Sim | Sim | Sim | Sim | Sim |
| ZSTD | Sim | Não | Não | Não | Não |
| DEFLATE | Sim | Sim | Sim | Sim | Sim |
Tópicos
- Criar uma conexão do AWS Glue para um fluxo de dados do Apache Kafka
- Criar uma tabela do Data Catalog para uma fonte de transmissão
- Notas e restrições para fontes de transmissão Avro
- Aplicar padrões grok a fontes de transmissão
- Definir propriedades de trabalho para um trabalho de ETL de transmissão
- Notas e restrições sobre ETL de transmissão
Criar uma conexão do AWS Glue para um fluxo de dados do Apache Kafka
Para ler a partir de um stream do Apache Kafka, é necessário criar uma conexão do AWS Glue.
Como criar uma conexão do AWS Glue para uma fonte do Kafka (console)
Abra o console do AWS Glue em https://console.aws.amazon.com/glue/
. -
No painel de navegação, em Data catalog (catálogo de dados), selecione Connections (Conexões).
-
Escolha Add connection (Adicionar conexão) e, na página Set up your connection’s properties (Configurar propriedades da conexão) insira um nome de conexão.
nota
Para obter mais informações sobre como especificar propriedades de conexão, consulte Propriedades de conexão do AWS Glue.
-
Em Tipo de conexão, escolha Kafka.
-
Para os URLs de servidores de bootstrap do Kafka, insira o host e o número da porta para o agente de bootstrap do cluster do Amazon MSK ou do Apache Kafka. Use somente endpoints de Transport Layer Security (TLS) para estabelecer a conexão inicial com o cluster do Kafka. Os endpoints plaintext não são compatíveis.
Veja a seguir um exemplo de lista de pares de nome de host e de números de porta para um cluster do Amazon MSK.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094Para mais informações sobre como obter as informações do agente de bootstrap, consulte Obter os agentes de bootstrap para um cluster do Amazon MSK no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
-
Se você quiser uma conexão segura com a origem dos dados do Kafka, selecione Require SSL connection (Exigir conexão SSL), e em Kafka private CA certificate location (Localização do certificado CA privado do Kafka), insira um caminho válido do Amazon S3 para um certificado SSL personalizado.
Para uma conexão SSL com o Kafka autogerenciado, o certificado personalizado é obrigatório. Ele é opcional para o Amazon MSK.
Para obter mais informações sobre como especificar um certificado personalizado para o Kafka, consulte Propriedades de conexão SSL do AWS Glue.
-
Use o AWS Glue Studio ou a AWS CLI para especificar um método de autenticação de cliente do Kafka. Para acessar o AWS Glue Studio, selecione AWS Glue no menu ETL no painel de navegação esquerdo.
Para obter mais informações sobre métodos de autenticação do cliente Kafka, consulte Propriedades de conexão do AWS Glue Kafka para autenticação do cliente .
-
Opcionalmente, insira uma descrição e, em seguida, escolha Next (Próximo).
-
Para um cluster do Amazon MSK, especifique sua nuvem privada virtual (VPC), sub-rede e grupo de segurança. As informações da VPC são opcionais para o Kafka autogerenciado.
-
Selecione Next (Próximo) para rever todas as propriedades de conexão e, em seguida, escolha Finish (Finalizar).
Para obter mais informações sobre conexões do AWS Glue, consulte Conectar a dados.
Propriedades de conexão do AWS Glue Kafka para autenticação do cliente
- Autenticação SASL/GSSAPI (Kerberos)
-
Escolher esse método de autenticação permitirá que você especifique propriedades Kerberos.
- Kerberos Keytab
-
Escolha o local do arquivo keytab. Um keytab armazena chaves de longo prazo para um ou mais principais. Para obter mais informações, consulte Documentação do MIT Kerberos: Keytab
. - Arquivo Kerberos krb5.conf
-
Escolha o arquivo krb5.conf. Ele contém o realm padrão (uma rede lógica, semelhante a um domínio, que define um grupo de sistemas sob o mesmo KDC) e a localização do servidor KDC. Para obter mais informações, consulte Documentação do MIT Kerberos: krb5.conf
. - Entidade principal do Kerberos e nome do serviço Kerberos
-
Insira a entidade principal do Kerberos e nome do serviço. Para obter mais informações, consulte Documentação do MIT Kerberos: entidade principal do Kerberos
. - Autenticação SASL/SCRAM-SHA-512
-
Escolher esse método de autenticação permitirá que você especifique credenciais de autenticação.
- AWS Secrets Manager
-
Pesquise seu token na caixa Pesquisar digitando o nome ou o ARN.
- Nome de usuário e senha do provedor diretamente
-
Pesquise seu token na caixa Pesquisar digitando o nome ou o ARN.
- Autenticação de cliente SSL
-
Escolher esse método de autenticação permite que você selecione o local do keystore do cliente Kafka ao navegar no Amazon S3. Opcionalmente, você pode inserir a senha do keystore do cliente Kafka e a senha da chave do cliente Kafka.
- Autenticação do IAM
-
O método de autenticação não requer especificações adicionais e só é aplicável quando a fonte do streaming é o MSK Kafka.
- Autenticação SASL/PLAIN
-
Escolher esse método de autenticação permite a você especificar credenciais de autenticação.
Criar uma tabela do Data Catalog para uma fonte de transmissão
É possível criar manualmente uma tabela do Data Catalog que especifique as propriedades do fluxo de dados da fonte, incluindo o esquema de dados. Essa tabela é usada como fonte de dados para o trabalho de ETL de streaming.
Se você não souber o esquema dos dados no fluxo de dados de origem, poderá criar a tabela sem um esquema. Em seguida, quando você cria o trabalho ETL de transmissão, pode ativar a função de detecção de esquema do AWS Glue. O AWS Glue determina o esquema dos dados de transmissão.
Use o console do AWS Glue
nota
Não é possível usar o console do AWS Lake Formation para criar a tabela; é necessário usar o console do AWS Glue.
Considere também as seguintes informações para fontes de transmissão no formato Avro ou para dados de log aos quais você pode aplicar padrões Grok.
Tópicos
Fonte de dados do Kinesis
Ao criar a tabela, defina as seguintes propriedades de ETL de transmissão (console).
- Tipo de fonte
-
Kinesis
- Para uma fonte do Kinesis na mesma conta:
-
- Região
-
A região da AWS onde reside o serviço do Amazon Kinesis Data Streams. O nome da transmissão do Kinesis e da região são traduzidos juntos para um ARN de transmissão.
Exemplo: https://kinesis.us-east-1.amazonaws.com
- Nome da transmissão do Kinesis
-
Nome do stream conforme descrito em Criar um stream no Guia do desenvolvedor do Amazon Kinesis Data Streams.
- Para obter uma fonte do Kinesis em outra conta, consulte este exemplo para configurar as funções e políticas a fim de permitir o acesso entre contas. Defina estas configurações:
-
- ARN da transmissão
-
O ARN do fluxo de dados do Kinesis no qual o consumidor está registrado. Para obter mais informações, consulte Nomes de recursos da Amazon (ARNs) e namespaces de serviço da AWS no Referência geral da AWS.
- ARN da função assumida
-
O nome do recurso da Amazon (ARN) da função a ser assumida.
- Nome da sessão (opcional)
-
Um identificador para a sessão de função assumida.
Use o nome da sessão de função para identificar exclusivamente uma sessão quando a mesma função for assumida por outras entidades principais ou por motivos diferentes. Em cenários entre contas, o nome da sessão de função fica visível e pode ser acessado pela conta que possui a função. O nome da sessão de função também é usado no ARN da entidade principal da função assumida. Isso significa que solicitações subsequentes de API entre contas que usam as credenciais de segurança temporárias vão expor o nome da sessão de função à conta externa em seus logs do AWS CloudTrail.
Para definir propriedades de ETL de transmissão para o Amazon Kinesis Data Streams (API do AWS Glue ou AWS CLI)
-
Para configurar as propriedades de ETL de transmissão para uma fonte do Kinesis na mesma conta, especifique os parâmetros
streamNameeendpointUrlna estruturaStorageDescriptorda operação da APICreateTableou do comando da CLIcreate_table."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }Ou especifique o
streamARN."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
Para configurar as propriedades de ETL de transmissão para uma fonte do Kinesis na mesma conta, especifique os parâmetros
streamARN,awsSTSRoleARNeawsSTSSessionName(opcional) na estruturaStorageDescriptorda operação da APICreateTableou do comando da CLIcreate_table."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Fonte de dados do Kafka
Ao criar a tabela, defina as seguintes propriedades de ETL de transmissão (console).
- Tipo de fonte
-
Kafka
- Para uma fonte do Kafka:
-
- Nome do tópico
-
Nome do tópico conforme especificado no Kafka.
- Conexão
-
Uma conexão do AWS Glue que faz referência a uma fonte do Kafka, conforme descrito em Criar uma conexão do AWS Glue para um fluxo de dados do Apache Kafka.
Fonte da tabela do registro de esquemas do AWS Glue
Para usar o registro de esquemas do AWS Glue para trabalhos de transmissão, siga as instruções em Caso de uso: AWS Glue Data Catalog para criar ou atualizar uma tabela de registro de esquemas.
Atualmente, a transmissão do AWS Glue oferece suporte somente ao formato Avro de registro do esquemas do Glue com inferência de esquema definida como false.
Notas e restrições para fontes de transmissão Avro
As seguintes notas e restrições se aplicam a fontes de transmissão no formato Avro:
-
Quando a detecção de esquema está ativada, o esquema Avro deve ser incluído na carga útil. Quando desligado, a carga útil deve conter apenas dados.
-
Alguns tipos de dados Avro não são suportados em quadros dinâmicos. Você não pode especificar esses tipos de dados ao definir o esquema com a página Define a schema (Definir um esquema) no assistente de criação de tabela no console do AWS Glue. Durante a detecção de esquema, os tipos não suportados no esquema Avro são convertidos para tipos suportados da seguinte forma:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
Se você definir o esquema de tabela usando a página Define a schema (Definir um esquema) no console, o tipo de elemento raiz implícito para o esquema será
record. Se você quiser um tipo de elemento raiz diferente derecord, por exemplo,arrayoumap, não deve especificar o esquema usando a página Define a schema (Definir um esquema). Em vez disso, você deve ignorar essa página e especificar o esquema como uma propriedade de tabela ou dentro do script de ETL.-
Para especificar o esquema nas propriedades da tabela, conclua o assistente de criação de tabela, edite os detalhes da tabela e adicione um novo par de chave-valor em Table properties (Propriedades da tabela). Use a chave
avroSchemae insira um objeto JSON de esquema para o valor, conforme mostrado na captura de tela a seguir.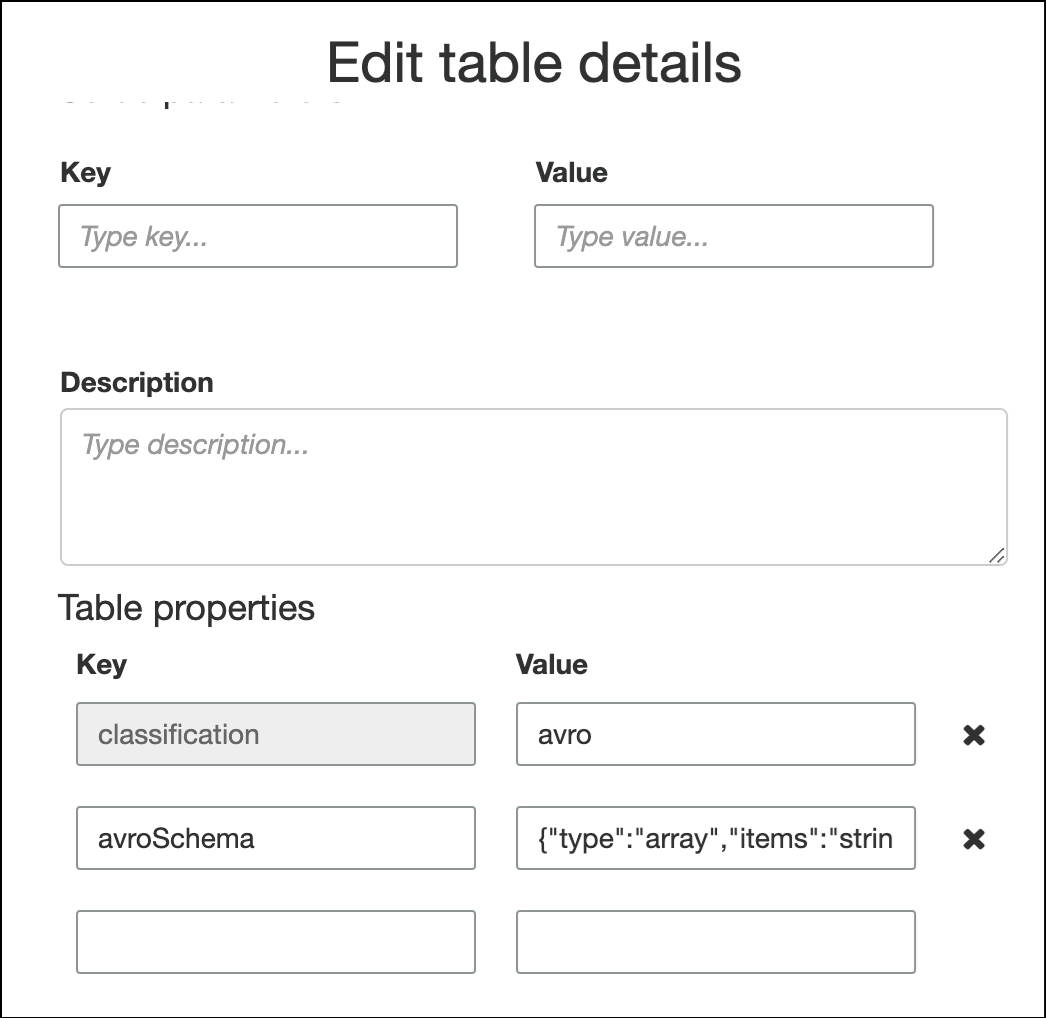
-
Para especificar o esquema no script de ETL, modifique a instrução de atribuição
datasource0e adicione a chaveavroSchemaao argumentoadditional_options, conforme mostrado nos exemplos de Python e Scala a seguir.
-
Aplicar padrões grok a fontes de transmissão
Você pode criar um trabalho de ETL de transmissão para uma fonte dos dados de log e usar padrões Grok para converter os logs em dados estruturados. Em seguida, o trabalho de ETL processa os dados como uma fonte de dados estruturada. Você especifica os padrões Grok a serem aplicados ao criar a tabela do Data Catalog para a fonte de transmissão.
Para obter informações sobre padrões Grok e valores de string padrão personalizados, consulte Gravar classificadores grok personalizados.
Para adicionar padrões grok à tabela do Data Catalog (console)
-
Use o assistente de criação de tabela e a crie com os parâmetros especificados em Criar uma tabela do Data Catalog para uma fonte de transmissão. Especifique o formato de dados como Grok, preencha o campo Grok pattern (Padrão Grok) e, opcionalmente, adicione padrões personalizados em Custom patterns (optional) (Padrões personalizados [opcional]).
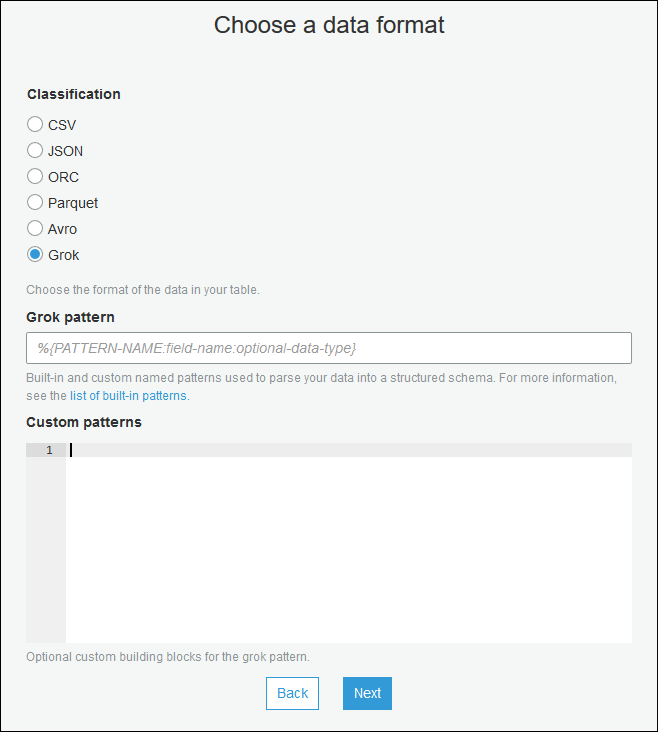
Pressione Enter após cada padrão personalizado.
Para adicionar padrões grok à tabela do Data Catalog (API do AWS Glue ou AWS CLI)
-
Adicionar o parâmetro
GrokPatterne, opcionalmente, o parâmetroCustomPatternsà operação da APICreateTableou comando da CLIcreate_table."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },Expresse
grokCustomPatternscomo uma string e use “\n” como o separador entre padrões.Veja a seguir um exemplo desses parâmetros em um arquivo.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
Definir propriedades de trabalho para um trabalho de ETL de transmissão
Ao definir um trabalho de ETL de transmissão no console do AWS Glue, forneça as seguintes propriedades específicas de transmissão. Para descrições de propriedades de trabalhos adicionais, consulte Definir propriedades de trabalho para trabalhos do Spark.
- Perfil do IAM
-
Especifique a função do AWS Identity and Access Management (IAM) usada para a autorização dos recursos necessários para executar o trabalho, acessar fontes de transmissão e armazenamentos de dados de destino.
Para obter acesso ao Amazon Kinesis Data Streams, associe a política
AmazonKinesisFullAccessgerenciada pela AWS à função ou associe uma política do IAM semelhante que permita um acesso mais granular. Para ver políticas de exemplo, consulte Controlar o acesso aos recursos do Amazon Kinesis Data Streams usando o IAM.Para obter mais informações sobre permissões de execução de trabalho no AWS Glue, consulte Gerenciamento de identidade e acesso do AWS Glue.
- Tipo
-
Escolha Spark streaming (Streaming do Spark).
- Versão do AWS Glue
-
A versão do AWS Glue determina as versões do Apache Spark, e Python ou Scala, que estão disponíveis para o trabalho. Escolha uma seleção que especifique a versão do Python ou do Scala disponível para o trabalho. O AWS Glue Versão 2.0 com suporte a Python 3 é o padrão para trabalhos de ETL de transmissão.
- Janela de manutenção
-
Especifica uma janela na qual um trabalho de streaming pode ser reiniciado. Consulte Janelas de manutenção do AWS Glue Streaming.
- Tempo limite de trabalho
-
Opcionalmente, informe uma duração em minutos. O valor padrão é em branco.
Os trabalhos de streaming devem ter valores de tempo limite inferiores a 7 dias ou 10.080 minutos.
Quando o valor for deixado em branco, o trabalho será reiniciado após 7 dias caso você não tenha configurado uma janela de manutenção. Se você tiver uma janela de manutenção configurada, o trabalho será reiniciado durante a janela de manutenção após 7 dias.
- Fonte de dados
-
Remova a tabela criada em Criar uma tabela do Data Catalog para uma fonte de transmissão.
- Destino de dados
-
Execute um destes procedimentos:
-
Escolha Create tables in your data target (Criar tabelas no destino de dados) e especifique as propriedades do destino de dados a seguir.
- Datastore
-
Escolha Amazon S3 ou JDBC.
- Formato
-
Escolha qualquer formato. Todos são compatíveis com streaming.
-
Escolha Use tables in the data catalog and update your data target (Usar tabelas no catálogo de dados e atualizar seu destino de dados) e escolha uma tabela para um datastore JDBC.
-
- Definição do esquema de saída
-
Execute um destes procedimentos:
-
Escolha Automatically detect schema of each record (Detectar automaticamente o esquema de cada registro) para ativar a detecção de esquemas. O AWS Glue determina o esquema dos dados de transmissão.
-
Escolha Specify output schema for all records (Especificar esquema de saída para todos os registros) para usar a transformação Apply Mapping (Aplicar mapeamento) e definir o esquema de saída.
-
- Script
-
Opcionalmente, forneça seu próprio script ou modifique o script gerado para executar operações compatíveis com o mecanismo do Apache Spark Structured Streaming. Para obter informações sobre as operações disponíveis, consulte Operações em streaming de DataFrames/conjuntos de dados
.
Notas e restrições sobre ETL de transmissão
Tenha em mente as seguintes notas e restrições:
-
A descompactação automática para trabalhos de ETL de fluxo do AWS Glue só está disponível para os tipos de compactação compatíveis. Observe o seguinte:
Snappy com enquadramento refere-se ao formato de enquadramento
oficial para o Snappy. Deflate é compatível com o Glue versão 3.0, mas não com o Glue versão 2.0.
-
Ao usar a detecção de esquema, você não pode realizar junções de dados de transmissão.
-
Os trabalhos de ETL de transmissão do AWS Glue não são compatíveis com o tipo de dados Union para registro de esquema do AWS Glue com o formato Avro.
-
Seu script de ETL pode usar as transformações nativas do AWS Glue e as transformações nativas do Apache Spark Structured Streaming. Para obter mais informações, consulte Operations on streaming DataFrames/Datasets
(Operações em transmissão de dataframes/conjuntos de dados) no website do Apache Spark ou Referência de transformações PySpark do AWS Glue. -
Os trabalhos de ETL de transmissão do AWS Glue usam pontos de verificação para acompanhar os dados que foram lidos. Portanto, um trabalho interrompido e reiniciado é retomado de onde parou no streaming. Se desejar reprocessar dados, você poderá excluir a pasta de ponto de verificação indicada no script.
-
Marcadores de trabalho não são compatíveis.
-
Para usar o atributo de distribuição avançada de fluxo de dados do Kinesis no trabalho, consulte Usar distribuição avançada nas tarefas de streaming do Kinesis.
-
Se você usar uma tabela de catálogo de dados criada a partir do registro de esquemas do AWS Glue, quando uma nova versão do esquema se tornar disponível, para refletir o novo esquema, você precisará fazer o seguinte:
-
Pare os trabalhos associados à tabela.
-
Atualize o esquema para a tabela do catálogo de dados.
-
Reinicie os trabalhos associados à tabela.
-
