As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criação de imagens de algoritmo
Um algoritmo de SageMaker IA da Amazon exige que o comprador traga seus próprios dados para treinar antes de fazer previsões. Como AWS Marketplace vendedor, você pode usar a SageMaker IA para criar algoritmos e modelos de aprendizado de máquina (ML) que seus compradores possam implantar AWS. Nas seções a seguir, você aprenderá a criar imagens de algoritmo para AWS Marketplace. Isso inclui criar a imagem de treinamento do Docker para treinar seu algoritmo e a imagem de inferência que contém sua lógica de inferência. Tanto as imagens de treinamento quanto as de inferência são necessárias ao publicar um produto de algoritmo.
Tópicos
Visão geral
Um algoritmo inclui os seguintes componentes:
-
Uma imagem de treinamento armazenada no Amazon ECR
-
Uma imagem de inferência armazenada no Amazon Elastic Container Registry (Amazon ECR)
nota
Para produtos de algoritmo, o contêiner de treinamento gera artefatos de modelo que são carregados no contêiner de inferência na implantação do modelo.
O diagrama a seguir mostra um fluxo de trabalho para publicar e usar os produtos de algoritmo.
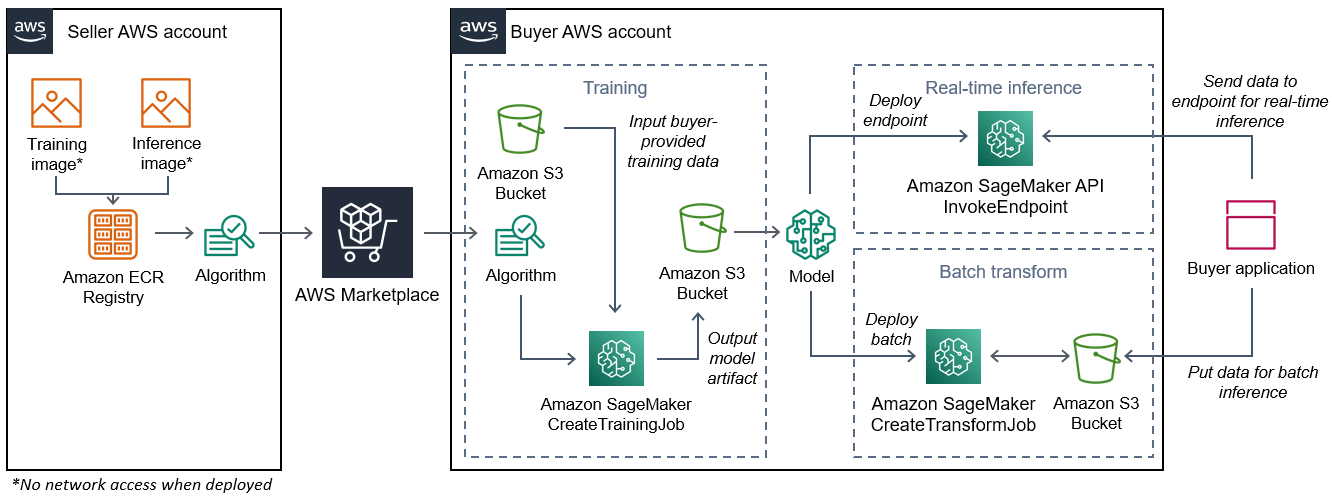
O fluxo de trabalho para criar um algoritmo de SageMaker IA AWS Marketplace inclui as seguintes etapas:
-
O vendedor cria uma imagem de treinamento e uma imagem de inferência (sem acesso à rede quando implantadas) e as envia para o Amazon ECR Registry.
-
Em seguida, o vendedor cria um recurso de algoritmo na Amazon SageMaker AI e publica seu produto de ML no AWS Marketplace.
-
O comprador assina o produto de ML.
-
O comprador cria um trabalho de treinamento com um conjunto de dados compatível e valores de hiperparâmetros apropriados. SageMaker A IA executa a imagem de treinamento e carrega os dados e hiperparâmetros de treinamento no contêiner de treinamento. Quando o trabalho de treinamento é concluído, os artefatos do modelo localizados em
/opt/ml/model/são compactados e copiados para o bucket do Amazon S3do comprador. -
O comprador cria um pacote de modelo com os artefatos do modelo do treinamento armazenados no Amazon S3 e implanta o modelo.
-
SageMaker A IA executa a imagem de inferência, extrai os artefatos do modelo compactado e carrega os arquivos no caminho do diretório do contêiner de inferência,
/opt/ml/model/onde são consumidos pelo código que serve para a inferência. -
Independentemente de o modelo ser implantado como um endpoint ou um trabalho de transformação em lote, a SageMaker IA passa os dados para inferência em nome do comprador para o contêiner por meio do endpoint HTTP do contêiner e retorna os resultados da previsão.
nota
Para obter mais informações, consulte Treinar modelos.
Criação de uma imagem de treinamento para algoritmos
Esta seção fornece um passo a passo para empacotar seu código de treinamento em uma imagem de treinamento. É necessária uma imagem de treinamento para criar um produto de algoritmo.
Uma imagem de treinamento é uma imagem do Docker contendo seu algoritmo de treinamento. O contêiner adere a uma estrutura de arquivo específica para permitir que a SageMaker IA copie dados de e para seu contêiner.
Tanto as imagens de treinamento quanto as de inferência são necessárias ao publicar um produto de algoritmo. Depois de criar sua imagem de treinamento, você deve criar uma imagem de inferência. As duas imagens podem ser combinadas em uma imagem ou permanecer como imagens separadas. Depende de você combinar as imagens ou separá-las. Normalmente, a inferência é mais simples do que o treinamento, e talvez você queira imagens separadas para ajudar no desempenho da inferência.
nota
Veja a seguir apenas um exemplo de código de empacotamento para uma imagem de treinamento. Para obter mais informações, consulte Use seus próprios algoritmos e modelos com os exemplos de IA AWS Marketplace e os exemplos de AWS Marketplace
SageMaker IA
Etapa 1: criar a imagem do contêiner
Para que a imagem de treinamento seja compatível com a Amazon SageMaker AI, ela deve seguir uma estrutura de arquivo específica para permitir que a SageMaker IA copie os dados de treinamento e as entradas de configuração para caminhos específicos em seu contêiner. Quando o treinamento é concluído, os artefatos do modelo gerado são armazenados em um caminho de diretório específico no contêiner de onde a SageMaker IA copia.
O seguinte usa a CLI do Docker instalada em um ambiente de desenvolvimento em uma distribuição Ubuntu do Linux.
Preparar o programa para ler as entradas de configuração
Se o programa de treinamento exigir alguma entrada de configuração fornecida pelo comprador, ela será copiada para aqui dentro do seu contêiner quando executada. Se necessário, seu programa deve ler esses caminhos de arquivo específicos.
-
/opt/ml/input/configé o diretório que contém informações que controlam como seu programa é executado.-
hyperparameters.jsoné um dicionário formatado em JSON de nomes e valores de hiperparâmetros. Os valores são strings, então talvez seja necessário convertê-los. -
resourceConfig.jsoné um arquivo formatado em JSON que descreve o layout de rede usado para treinamento distribuído. Se sua imagem de treinamento não suportar treinamento distribuído, você pode ignorar esse arquivo.
-
nota
Para obter mais informações sobre as entradas de configuração, consulte Como a Amazon SageMaker AI fornece informações de treinamento.
Preparar o programa para ler as entradas de dados
Os dados de treinamento podem ser passados para o contêiner em um dos dois modos a seguir. Seu programa de treinamento executado no contêiner digere os dados de treinamento em um desses dois modos.
Modo de arquivo
-
/opt/ml/input/data/<channel_name>/contém os dados de entrada desse canal. Os canais são criados com base na chamada para a operaçãoCreateTrainingJob, mas geralmente é importante que os canais correspondam ao que o algoritmo espera. Os arquivos de cada canal são copiados do Amazon S3para esse diretório, preservando a estrutura em árvore indicada pela estrutura de chaves do Amazon S3.
Modo de canal
-
/opt/ml/input/data/<channel_name>_<epoch_number>é o cachimbo de uma determinada época. As épocas começam em zero e aumentam em uma cada vez que você as lê. Não há limite para o número de épocas que podem ser executadas, mas você deve fechar cada canal antes de ler a próxima época.
Preparar o programa para escrever resultados de treinamento
A saída do treinamento é gravada nos seguintes diretórios de contêineres:
-
/opt/ml/model/é o diretório em que você escreve o modelo ou os artefatos do modelo que o algoritmo de treinamento gera. O modelo pode estar em qualquer formato que você quiser. Pode ser um único arquivo ou uma árvore de diretórios inteira. SageMaker O AI empacota todos os arquivos desse diretório em um arquivo compactado (.tar.gz). Esse arquivo está disponível no local do Amazon S3 retornado pela operação de APIDescribeTrainingJob. -
/opt/ml/output/é um diretório em que o algoritmo pode gravar um arquivofailureque descreve por que o trabalho falhou. O conteúdo desse arquivo é retornado no campoFailureReasondo resultadoDescribeTrainingJob. Para trabalhos bem-sucedidos, não há razão para escrever esse arquivo porque ele é ignorado.
Criar o script para a execução do contêiner
Crie um script de train shell que a SageMaker IA execute ao executar a imagem do contêiner Docker. Quando o treinamento for concluído e os artefatos do modelo forem gravados nos respectivos diretórios, saia do script.
./train
#!/bin/bash # Run your training program here # # # #
Criar a Dockerfile
Crie um Dockerfile no contexto de criação. Este exemplo usa o Ubuntu 18.04 como imagem base, mas você pode começar com qualquer imagem base que funcione para sua estrutura.
./Dockerfile
FROM ubuntu:18.04 # Add training dependencies and programs # # # # # # Add a script that SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /train /opt/program/train RUN chmod 755 /opt/program/train ENV PATH=/opt/program:${PATH}
O Dockerfile adiciona o script train criado anteriormente à imagem. O diretório do script é adicionado ao PATH para que ele possa ser executado quando o contêiner for executado.
No exemplo anterior, não há uma lógica de treinamento real. Para a imagem real de treinamento, adicione as dependências de treinamento ao Dockerfile e adicione a lógica para ler as entradas de treinamento para treinar e gerar os artefatos do modelo.
A imagem de treinamento deve conter todas as dependências necessárias porque não terá acesso à Internet.
Para obter mais informações, consulte Use seus próprios algoritmos e modelos com os exemplos de IA AWS Marketplace e os exemplos de AWS Marketplace
SageMaker IA
Etapa 2: criar e testar a imagem localmente
No contexto de criação, os seguintes arquivos agora existem:
-
./Dockerfile -
./train -
As dependências e a lógica de treinamento
Em seguida, você pode criar, executar e testar essa imagem de contêiner.
Criar a imagem
Execute o comando do Docker no contexto de criação para criar e marcar a imagem. Este exemplo usa a tag my-training-image.
sudo docker build --tag my-training-image ./
Depois de executar esse comando do Docker para criar a imagem, você deve ver a saída quando o Docker cria a imagem com base em cada linha do Dockerfile. Quando terminar, você deverá ver algo semelhante ao seguinte.
Successfully built abcdef123456
Successfully tagged my-training-image:latestExecutar o localmente
Depois de concluído, teste a imagem localmente conforme mostrado no exemplo a seguir.
sudo docker run \ --rm \ --volume '<path_to_input>:/opt/ml/input:ro' \ --volume '<path_to_model>:/opt/ml/model' \ --volume '<path_to_output>:/opt/ml/output' \ --name my-training-container \ my-training-image \ train
A seguir estão os detalhes do comando:
-
--rm: remova automaticamente o contêiner depois que ele parar. -
--volume '<path_to_input>:/opt/ml/input:ro': disponibilize o diretório de entrada de teste para o contêiner como somente leitura. -
--volume '<path_to_model>:/opt/ml/model': vincule o caminho em que os artefatos do modelo são armazenados na máquina host quando o teste de treinamento é concluído. -
--volume '<path_to_output>:/opt/ml/output': vincule o caminho em que o motivo da falha em um arquivofailureé gravado na máquina host. -
--name my-training-container: dê um nome a esse contêiner em execução. -
my-training-image: execute a imagem criada. -
train— Execute o mesmo script que a SageMaker IA executa ao executar o contêiner.
Depois de executar esse comando, o Docker cria um contêiner a partir da imagem de treinamento que você criou e o executa. O contêiner executa o script train, que inicia seu programa de treinamento.
Depois que seu programa de treinamento terminar e o contêiner sair, verifique se os artefatos do modelo de saída estão corretos. Além disso, verifique as saídas do log para confirmar se elas não estão produzindo logs que você não deseja e, ao mesmo tempo, garanta que informações suficientes sejam fornecidas sobre o trabalho de treinamento.
Isso conclui o empacotamento do código de treinamento para um produto de algoritmo. Como um produto de algoritmo também inclui uma imagem de inferência, continue na próxima seção, Criação de uma imagem de inferência para algoritmos.
Criação de uma imagem de inferência para algoritmos
Esta seção fornece um passo a passo para empacotar o código de inferência em uma imagem de inferência para o produto de algoritmo.
A imagem de inferência é uma imagem do Docker contendo a lógica de inferência. O contêiner em tempo de execução expõe endpoints HTTP para permitir que a SageMaker IA transmita dados de e para seu contêiner.
Tanto as imagens de treinamento quanto as de inferência são necessárias ao publicar um produto de algoritmo. Se ainda não tiver feito isso, veja a seção anterior sobre Criação de uma imagem de treinamento para algoritmos. As duas imagens podem ser combinadas em uma imagem ou permanecer como imagens separadas. Depende de você combinar as imagens ou separá-las. Normalmente, a inferência é mais simples do que o treinamento, e talvez você queira imagens separadas para ajudar no desempenho da inferência.
nota
Veja a seguir apenas um exemplo de código de empacotamento para uma imagem de inferência. Para obter mais informações, consulte Use seus próprios algoritmos e modelos com os exemplos de IA AWS Marketplace e os exemplos de AWS Marketplace
SageMaker IA
O exemplo a seguir usa um serviço da Web, o Flask
Etapa 1: criar a imagem de inferência
Para que a imagem de inferência seja compatível com a SageMaker IA, a imagem do Docker deve expor os endpoints HTTP. Enquanto seu contêiner está em execução, a SageMaker IA passa as entradas para inferência fornecidas pelo comprador para o endpoint HTTP do seu contêiner. O resultado da inferência é retornado no corpo da resposta de HTTP.
O seguinte usa a CLI do Docker instalada em um ambiente de desenvolvimento em uma distribuição Ubuntu do Linux.
Criar o script do servidor da Web
Este exemplo usa um servidor Python chamado Flask
nota
O Flask
Crie o script do servidor web Flask que serve os dois endpoints HTTP na porta TCP 8080 que a AI usa. SageMaker A seguir estão os dois endpoints esperados:
-
/ping— A SageMaker IA faz solicitações HTTP GET para esse endpoint para verificar se seu contêiner está pronto. Quando o contêiner estiver pronto, ele responderá às solicitações HTTP GET nesse endpoint com um código de resposta HTTP 200. -
/invocations— A SageMaker IA faz solicitações HTTP POST para esse endpoint para inferência. Os dados de entrada para inferência são enviados no corpo da solicitação. O tipo de conteúdo especificado pelo usuário é passado no cabeçalho HTTP. O corpo da resposta é a saída da inferência.
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code here. # # # # # # Add your inference code here. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
No exemplo anterior, não há uma lógica de inferência real. Para a imagem de inferência real, adicione a lógica de inferência ao aplicativo da Web para que ele processe a entrada e retorne a previsão.
A imagem de inferência deve conter todas as dependências necessárias porque não terá acesso à Internet.
Criar o script para a execução do contêiner
Crie um script chamado serve que a SageMaker IA executa ao executar a imagem do contêiner Docker. Nesse script, inicie o servidor da Web HTTP.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker AI flask run --host 0.0.0.0 --port 8080
Criar a Dockerfile
Crie um Dockerfile no contexto de criação. Este exemplo usa o Ubuntu 18.04, mas você pode começar a partir de qualquer imagem base que funcione para sua estrutura.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
O Dockerfile adiciona os dois scripts criados anteriormente à imagem. O diretório do script serve é adicionado ao CAMINHO para que ele possa ser executado quando o contêiner for executado.
Preparação do programa para carregar dinamicamente artefatos do modelo
Para produtos de algoritmo, o comprador usa seus próprios conjuntos de dados com a imagem de treinamento para gerar artefatos de modelo exclusivos. Quando o processo de treinamento é concluído, seu contêiner de treinamento envia artefatos do modelo para o diretório do contêiner.
/opt/ml/model/ SageMaker A IA comprime o conteúdo desse diretório em um arquivo.tar.gz e o armazena no endereço do comprador no Amazon S3. Conta da AWS
Quando o modelo é implantado, a SageMaker IA executa sua imagem de inferência, extrai os artefatos do modelo do arquivo .tar.gz armazenado na conta do comprador no Amazon S3 e os carrega no contêiner de inferência no diretório. /opt/ml/model/ Em runtime, o código de contêiner de inferência usa os dados do modelo.
nota
Para proteger a propriedade intelectual que possa estar nos arquivos de artefato de modelo, você pode optar por criptografar os arquivos antes de gerá-los. Para obter mais informações, consulte Segurança e propriedade intelectual com a Amazon SageMaker AI.
Etapa 2: criar e testar a imagem localmente
No contexto de criação, os seguintes arquivos agora existem:
-
./Dockerfile -
./web_app_serve.py -
./serve
Em seguida, você pode criar, executar e testar essa imagem de contêiner.
Criar a imagem
Execute o comando do Docker para criar e marcar a imagem. Este exemplo usa a tag my-inference-image.
sudo docker build --tag my-inference-image ./
Depois de executar esse comando do Docker para criar a imagem, você deve ver a saída quando o Docker cria a imagem com base em cada linha do Dockerfile. Quando terminar, você deverá ver algo semelhante ao seguinte.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestExecutar o localmente
Depois que a criação for concluída, você poderá testar a imagem localmente.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --volume '<path_to_model>:/opt/ml/model:ro' \ --detach \ --name my-inference-container \ my-inference-image \ serve
A seguir estão os detalhes do comando:
-
--rm: remova automaticamente o contêiner depois que ele parar. -
--publish 8080:8080/tcp— Exponha a porta 8080 para simular a porta para a qual o SageMaker AI envia solicitações HTTP. -
--volume '<path_to_model>:/opt/ml/model:ro': vincule e monte o caminho até onde os artefatos do modelo de teste são armazenados na máquina host como somente leitura para disponibilizá-los para seu código de inferência no contêiner. -
--detach: execute o contêiner em segundo plano. -
--name my-inference-container: dê um nome a esse contêiner em execução. -
my-inference-image: execute a imagem criada. -
serve— Execute o mesmo script que a SageMaker IA executa ao executar o contêiner.
Depois de executar esse comando, o Docker cria um contêiner a partir da imagem de inferência e o executa em segundo plano. O contêiner executa o script serve, que inicia seu servidor da Web para fins de teste.
Testar o endpoint HTTP de ping
Quando a SageMaker IA executa seu contêiner, ela efetua um ping periódico no endpoint. Quando o endpoint retorna uma resposta HTTP com o código de status 200, ele sinaliza para a SageMaker IA que o contêiner está pronto para inferência.
Execute o comando a seguir para testar o endpoint e incluir o cabeçalho de resposta.
curl --include http://127.0.0.1:8080/ping
O resultado de exemplo é mostrado no exemplo a seguir.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTTestar o endpoint HTTP de inferência
Quando o contêiner indica que está pronto retornando um código de status 200, a SageMaker IA passa os dados de inferência para o endpoint /invocations HTTP por meio de uma POST solicitação.
Execute o comando a seguir para testar o endpoint de inferência.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
O resultado de exemplo é mostrado no exemplo a seguir.
{"prediction": "a", "text": "hello world"}Com esses dois endpoints HTTP funcionando, a imagem de inferência agora é compatível com SageMaker a IA.
nota
O modelo do produto de algoritmo pode ser implantado de duas maneiras: em tempo real e em lote. Para ambas as implantações, a SageMaker IA usa os mesmos endpoints HTTP ao executar o contêiner Docker.
Para interromper o contêiner, execute o seguinte comando.
sudo docker container stop my-inference-container
Depois que as imagens de treinamento e inferência do produto de algoritmo estiverem prontas e testadas, continue para Faça upload das imagens para o Amazon Elastic Container Registry.
