As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Treinar um modelo
Nesta etapa, você escolhe um algoritmo de treinamento e executa um trabalho de treinamento para o modelo. O Amazon SageMaker Python SDK
Escolha do algoritmo de treinamento
Para escolher o algoritmo certo para seu conjunto de dados, você normalmente precisa avaliar modelos diferentes para encontrar os modelos mais adequados aos seus dados. Para simplificar, o algoritmo Algoritmo XGBoost com Amazon AI SageMaker integrado de SageMaker IA é usado ao longo deste tutorial sem a pré-avaliação dos modelos.
dica
Se você quiser que a SageMaker IA encontre um modelo apropriado para seu conjunto de dados tabular, use o Amazon SageMaker Autopilot, que automatiza uma solução de aprendizado de máquina. Para obter mais informações, consulte SageMaker Piloto automático.
Criar e executar um trabalho de treinamento
Depois de descobrir qual modelo usar, comece a criar um estimador de SageMaker IA para treinamento. Este tutorial usa o algoritmo incorporado XGBoost para o estimador genérico SageMaker AI.
Como executar uma tarefa de treinamento de modelo
-
Importe o SDK do Amazon SageMaker Python
e comece recuperando as informações básicas da sua sessão atual de IA. SageMaker import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))Isso retorna as informações a seguir:
-
region— A AWS região atual em que a instância do notebook SageMaker AI está sendo executada. -
role: o perfil do IAM usada pela instância de caderno.
nota
Verifique a versão do SDK do SageMaker Python executando.
sagemaker.__version__Este tutorial é baseado emsagemaker>=2.20. Se o SDK estiver desatualizado, instale a versão mais recente executando o seguinte comando:! pip install -qU sagemakerSe você executar essa instalação nas instâncias existentes do SageMaker Studio ou do notebook, precisará atualizar manualmente o kernel para concluir a aplicação da atualização da versão.
-
-
Crie um estimador XGBoost usando a classe
sagemaker.estimator.Estimator. No código de exemplo a seguir, o estimador XGBoost é nomeadoxgb_model.from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )Para construir o estimador de SageMaker IA, especifique os seguintes parâmetros:
-
image_uri: especifique o URI da imagem de contêiner de treinamento. Neste exemplo, o SageMaker URI do contêiner de treinamento AI XGBoost é especificado usando.sagemaker.image_uris.retrieve -
role— A função AWS Identity and Access Management (IAM) que a SageMaker IA usa para realizar tarefas em seu nome (por exemplo, ler resultados de treinamento, chamar artefatos de modelos do Amazon S3 e gravar resultados de treinamento no Amazon S3). -
instance_counteinstance_type: o tipo e o número de instâncias de computação ML do Amazon EC2 a serem usadas no treinamento de modelo. Para este exercício de treinamento, você usa uma única instânciaml.m4.xlarge, que tem 4 CPUs, 16 GB de memória, um armazenamento Amazon Elastic Block Store (Amazon EBS) e um alto desempenho de rede. Para obter mais informações sobre os tipos de instância de computação EC2, consulte Tipos de instância do Amazon EC2. Para obter mais informações sobre faturamento, consulte os SageMaker preços da Amazon . -
volume_size: o tamanho, em GB, do volume de armazenamento do EBS para anexar à instância de treinamento. Ela deve ser grande o suficiente para armazenar dados de treinamento se você usar o modoFile(o modoFileestá ligado por padrão). Se você não especificar esse parâmetro, o seu valor será 30 por padrão. -
output_path— O caminho para o bucket S3, onde a SageMaker IA armazena o artefato do modelo e os resultados do treinamento. -
sagemaker_session— O objeto de sessão que gerencia as interações com as operações SageMaker da API e outros AWS serviços que o trabalho de treinamento usa. -
rules— Especifique uma lista de regras integradas do SageMaker Debugger. Neste exemplo, acreate_xgboost_report()regra cria um relatório do XGBoost que fornece insights sobre o progresso e os resultados do treinamento, e a regraProfilerReport()cria um relatório sobre a utilização de recursos de computação do EC2. Para obter mais informações, consulte SageMaker Relatório interativo do depurador para o XGBoost.
dica
Se você quiser executar um treinamento distribuído de modelos de aprendizado profundo de grande porte, como modelos de redes neurais convolucionais (CNN) e de processamento de linguagem natural (NLP), use o SageMaker AI Distributed para paralelismo de dados ou paralelismo de modelos. Para obter mais informações, consulte Treinamento distribuído na Amazon SageMaker AI.
-
-
Defina os hiperparâmetros para o algoritmo XGBoost chamando o método
set_hyperparametersdo estimador. Para obter uma lista completa de hiperparâmetros do XGBoost, consulte Hiperparâmetros do XGBoost.xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )dica
Você também pode ajustar os hiperparâmetros usando o recurso de otimização de hiperparâmetros de SageMaker IA. Para obter mais informações, consulte Ajuste automático do modelo com SageMaker IA.
-
Use a classe
TrainingInputpara configurar um fluxo de entrada de dados para treinamento. O código de exemplo a seguir mostra como configurar objetosTrainingInputpara usar os conjuntos de dados de treinamento e validação que você enviou para o Amazon S3 na seção Divida o conjunto de dados em treinamento, validação e teste.from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
Para iniciar o treinamento do modelo, chame o método
fitdo estimador com os conjuntos de dados de treinamento e validação. Ao configurarwait=True, o métodofitexibe os logs de progresso e aguarda o treinamento ser concluído para retornar os resultados.xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)Para obter mais informações sobre treinamento de modelo, consulte Treine um modelo com a Amazon SageMaker. Esse trabalho de treinamento tutorial pode levar até 10 minutos.
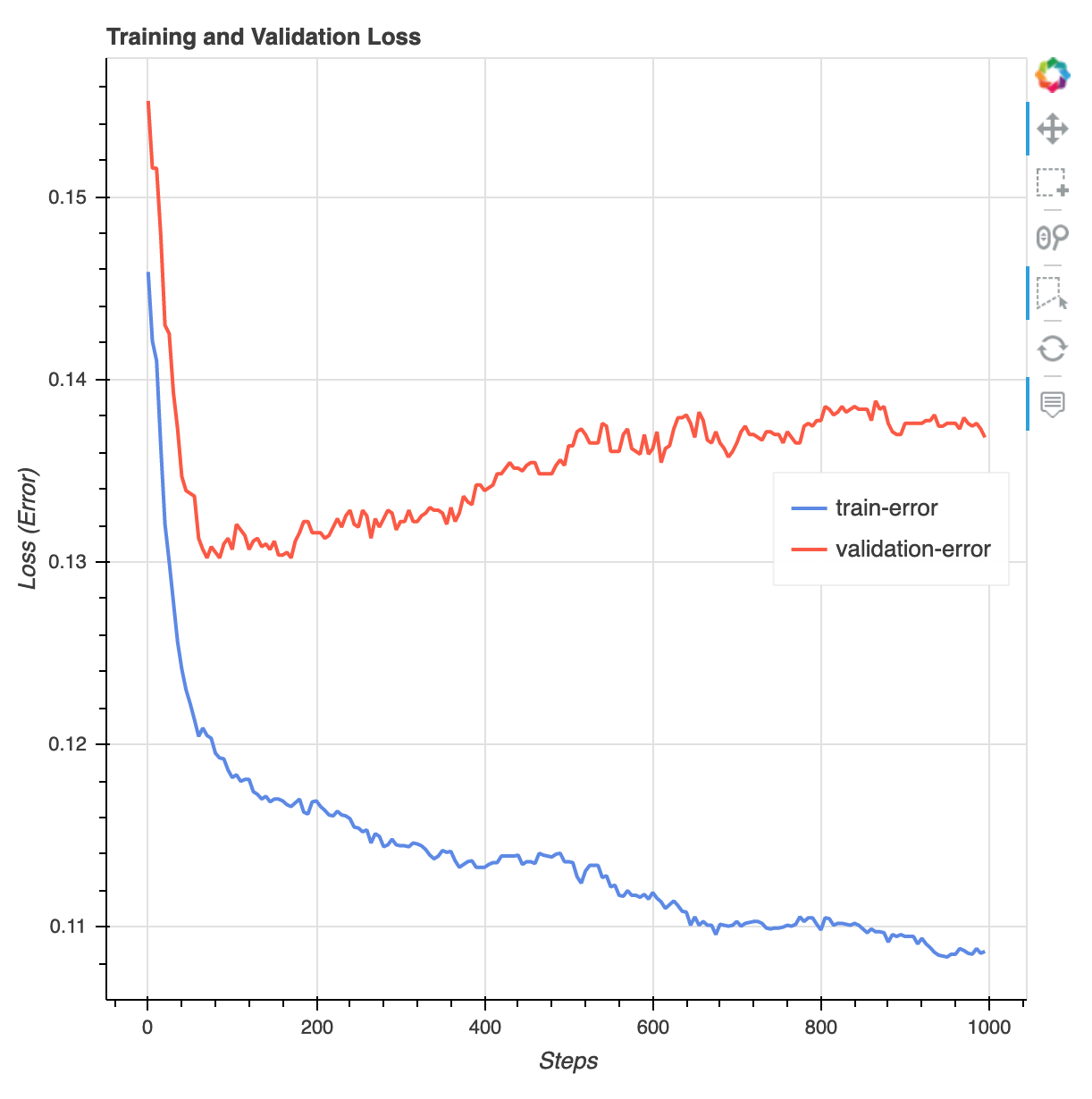
Após a conclusão do trabalho de treinamento, você pode baixar um relatório de treinamento do XGBoost e um relatório de criação de perfil gerado pelo Debugger. SageMaker O relatório de treinamento do XGBoost oferece insights sobre o progresso e os resultados do treinamento, como a função de perda em relação à iteração, importância do atributo, matriz de confusão, curvas de precisão e outros resultados estatísticos do treinamento. Por exemplo, você pode encontrar a seguinte curva de perda no relatório de treinamento do XGBoost, que indica claramente que há um problema de ajuste excessivo:
Execute o código a seguir para especificar o URI do bucket do S3 em que os relatórios de treinamento do Depurador são gerados e verifique se os relatórios existem.
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveFaça o download dos relatórios de treinamento e criação de perfil do Depurador do XGBoost para o espaço de trabalho atual:
! aws s3 cp {rule_output_path} ./ --recursiveExecute o seguinte script do IPython para obter o link do arquivo do relatório de treinamento do XGBoost:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))O script IPython a seguir retorna o link do arquivo do relatório de criação de perfil do Depurador, que mostra resumos e detalhes da utilização de recursos da instância EC2, dos resultados da detecção de gargalos do sistema e dos resultados da criação de perfil da operação do python:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))dica
Se os relatórios HTML não renderizarem gráficos na JupyterLab exibição, você deverá escolher Confiar em HTML na parte superior dos relatórios.
Para identificar problemas de treinamento, como sobreajuste, redução de gradientes e outros problemas que impedem a convergência do modelo, use o SageMaker Debugger e execute ações automatizadas ao criar protótipos e treinar seus modelos de ML. Para obter mais informações, consulte SageMaker Depurador Amazon. Para encontrar uma análise completa dos parâmetros do modelo, consulte o caderno de exemplo de explicabilidade com o Amazon SageMaker Debugger
.
Agora você tem um modelo XGBoost treinado. SageMaker A IA armazena o artefato do modelo em seu bucket do S3. Para encontrar a localização do artefato do modelo, execute o código a seguir para imprimir o atributo model_data do estimador xgb_model:
xgb_model.model_data
dica
Para medir os vieses que podem ocorrer durante cada estágio do ciclo de vida do ML (coleta de dados, treinamento e ajuste de modelos e monitoramento de modelos de ML implantados para previsão), use o Clarify. SageMaker Para obter mais informações, consulte Explicabilidade do modelo. Para ver um exemplo completo, consulte o caderno de exemplos de Imparcialidade e Explicabilidade
