As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Logs e métricas de pipeline de inferência
O monitoramento é importante para manter a confiabilidade, a disponibilidade e o desempenho dos SageMaker recursos da Amazon. Para monitorar e solucionar problemas de desempenho do pipeline de inferência, use CloudWatch registros e mensagens de erro da Amazon. Para obter informações sobre as ferramentas de monitoramento que SageMaker fornece, consulteFerramentas para monitorar os AWS recursos provisionados ao usar a Amazon SageMaker.
Usar métricas para monitorar modelos de vários contêineres
Para monitorar os modelos de vários contêineres em Inference Pipelines, use a Amazon. CloudWatch CloudWatchcoleta dados brutos e os processa em métricas legíveis, quase em tempo real. SageMakertarefas de treinamento e endpoints gravam CloudWatch métricas e registros no AWS/SageMaker namespace.
A tabela a seguir lista as métricas e as dimensões para o seguinte:
-
Invocações de endpoint
-
Tarefas de treinamento, tarefas de transformação em lote e instâncias de endpoint
A dimensão é um par de nome-valor que identifica exclusivamente uma métrica. Você pode atribuir até 10 dimensões a uma métrica. Para obter mais informações sobre o monitoramento com CloudWatch, consulteMétricas para monitorar a Amazon SageMaker com a Amazon CloudWatch.
Métricas de invocação de endpoint
O namespace AWS/SageMaker inclui as seguintes métricas de solicitação de chamadas para InvokeEndpoint.
As métricas são relatadas em intervalos de 1 minuto.
| Métrica | Descrição |
|---|---|
Invocation4XXErrors |
O número de Unidades: nenhuma Estatística válida: |
Invocation5XXErrors |
O número de Unidades: nenhuma Estatística válida: |
Invocations |
As solicitações Para obter o número total de solicitações enviadas a um endpoint de modelo, use a estatística Unidades: nenhuma Estatística válida: |
InvocationsPerInstance |
O número de invocações de endpoint enviadas para um modelo, normalizado por in each. Unidades: nenhuma Estatística válida: |
ModelLatency |
O tempo que o modelo ou modelos levaram para responder. Isso inclui o tempo necessário para enviar a solicitação, buscar a resposta do contêiner do modelo e concluir a inferência no contêiner. ModelLatency é o tempo total gasto por todos os contêineres em um pipeline de inferência.Unidade: microssegundos Estatísticas válidas: |
OverheadLatency |
O tempo adicionado ao tempo gasto para responder a uma solicitação do cliente devido SageMaker à sobrecarga. Unidade: microssegundos Estatísticas válidas: |
ContainerLatency |
O tempo necessário para que um contêiner do Inference Pipelines respondesse conforme visualizado de. SageMaker ContainerLatencyinclui o tempo necessário para enviar a solicitação, buscar a resposta do contêiner do modelo e concluir a inferência no contêiner.Unidade: microssegundos Estatísticas válidas: |
Dimensões para métricas de invocação de endpoint
| Dimensão | Descrição |
|---|---|
EndpointName, VariantName, ContainerName |
Filtra as métricas de invocação do endpoint para um |
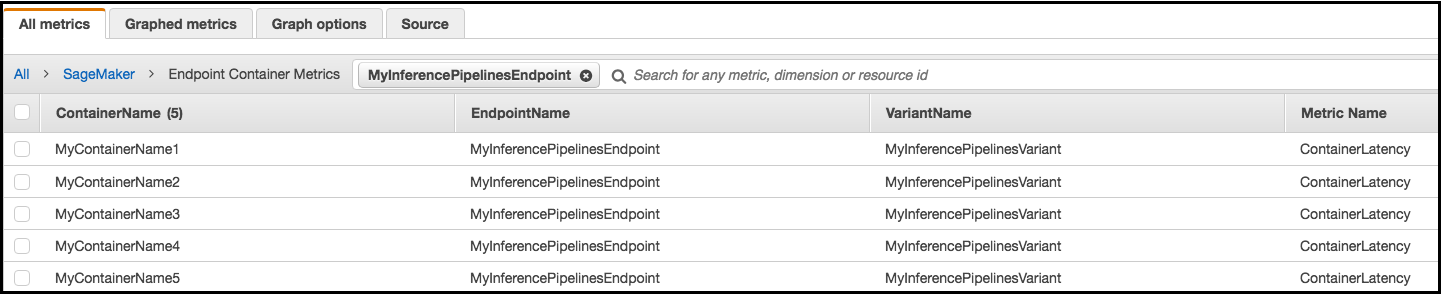
Para um endpoint de pipeline de inferência, CloudWatch lista as métricas de latência por contêiner em sua conta como Endpoint Container Metrics e Endpoint Variant Metrics no namespace, da seguinte forma. SageMaker A métrica ContainerLatency aparece apenas para pipelines de inferências.
Para cada endpoint e cada contêiner, as métricas de latência exibem nomes para o contêiner, o endpoint, a variante e a métrica.
Métricas de trabalho de treinamento, trabalho de transformação em lote e instância de endpoint
Os namespaces /aws/sagemaker/TrainingJobs, /aws/sagemaker/TransformJobs e /aws/sagemaker/Endpoints incluem as seguintes métricas para trabalhos de treinamento e instâncias de endpoint.
As métricas são relatadas em intervalos de 1 minuto.
| Métrica | Descrição |
|---|---|
CPUUtilization |
A porcentagem de CPU unidades usadas pelos contêineres em execução em uma instância. O valor varia de 0% a 100% e é multiplicado pelo número deCPUs. Por exemplo, se houver quatroCPUs, Para trabalhos de treinamento, Para trabalhos de transformação em lote, Para modelos de vários contêineres, Para variantes de endpoint, Unidades: percentual |
MemoryUtilization |
O percentual de memória usada pelos contêineres em execução em uma instância. Esse valor varia de 0% a 100%. Para tarefas de treinamento, Para tarefas de transformação em lote, MemoryUtilization é a soma da memória usada por todos os contêineres em execução na instância.Para variantes de endpoint, Unidades: percentual |
GPUUtilization |
A porcentagem de GPU unidades usadas pelos contêineres em execução em uma instância. Para trabalhos de treinamento, Para trabalhos de transformação em lote, Para modelos de vários contêineres, Para variantes de endpoint, Unidades: percentual |
GPUMemoryUtilization |
A porcentagem de GPU memória usada pelos contêineres em execução em uma instância. GPUMemoryUtilizationvaria de 0% a 100% e é multiplicado pelo número deGPUs. Por exemplo, se houver quatroGPUs, Para trabalhos de treinamento, Para trabalhos de transformação em lote, Para modelos de vários contêineres, Para variantes de endpoint, Unidades: percentual |
DiskUtilization |
A porcentagem do espaço em disco usado pelos contêineres em execução em uma instância. DiskUtilization varia de 0% a 100%. Essa métrica não oferece suporte para trabalhos de transformação em lote. Para tarefas de treinamento, Para variantes de endpoint, Unidades: percentual |
Dimensões para métricas de trabalho de treinamento, trabalho de transformação em lote e instância de endpoint
| Dimensão | Descrição |
|---|---|
Host |
Para tarefas de treinamento, Para tarefas de transformação em lote, Para endpoints, |
Para ajudá-lo a depurar suas tarefas de treinamento, endpoints e configurações de ciclo de vida de instâncias de notebooks, SageMaker também envia qualquer coisa que um contêiner de algoritmo, um contêiner de modelo ou uma configuração de ciclo de vida de instância de notebook envie para ou para o Amazon Logs. stdout stderr CloudWatch Você pode usar essas informações para depuração e para analisar o progresso.
Usar logs para monitorar um pipeline de inferência
A tabela a seguir lista os grupos e fluxos de log SageMaker. Envia para a Amazon CloudWatch
Stream de log é uma sequência de eventos de log que compartilham a mesma origem. Cada fonte separada de registros CloudWatch forma um fluxo de registros separado. Um grupo de logs é um grupo de fluxos de log que compartilham as mesmas configurações de retenção, monitoramento e controle de acesso.
Logs
| Nome do grupo de logs | Nome do fluxo de logs |
|---|---|
/aws/sagemaker/TrainingJobs |
|
/aws/sagemaker/Endpoints/[EndpointName] |
|
|
|
|
|
|
|
/aws/sagemaker/NotebookInstances |
|
/aws/sagemaker/TransformJobs |
|
|
|
|
|
|
nota
SageMakercria o grupo de /aws/sagemaker/NotebookInstances registros quando você cria uma instância de notebook com uma configuração de ciclo de vida. Para obter mais informações, consulte Personalização de uma instância de SageMaker notebook usando um script LCC.
Para obter mais informações sobre SageMaker registro em log, consulteGrupos de registros e streams que a Amazon SageMaker envia para o Amazon CloudWatch Logs.
