As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Terminologia e conceitos do Amazon Kinesis Data Streams
Antes de começar a usar o Amazon Kinesis Data Streams, conheça sua arquitetura e terminologia.
Tópicos
Analisar a arquitetura de alto nível do Kinesis Data Streams
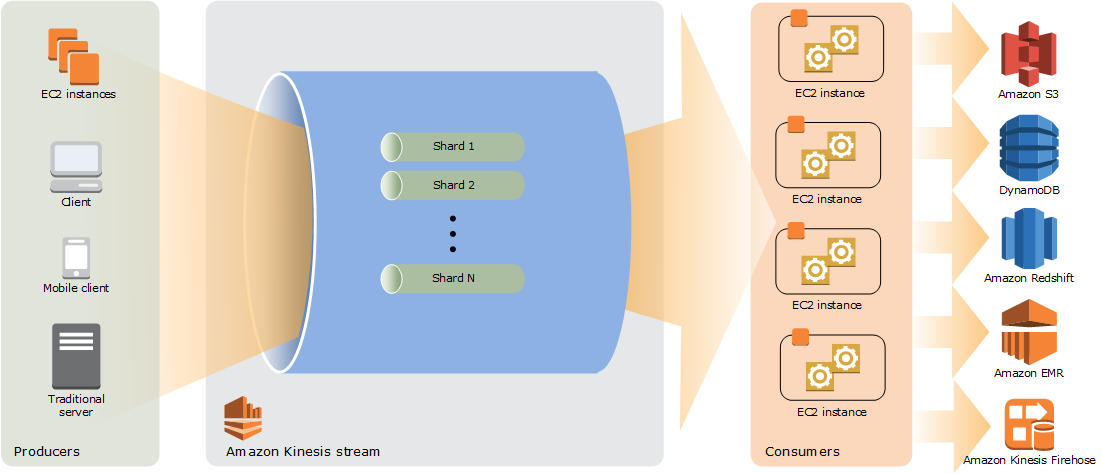
O diagrama a seguir ilustra a arquitetura de alto nível do Kinesis Data Streams. Os produtores enviam dados por push continuamente ao Kinesis Data Streams, que os consumidores processam em tempo real. Os consumidores (como um aplicativo personalizado executado no Amazon EC2 ou em um stream de entrega do Amazon Data Firehose) podem armazenar seus resultados usando um AWS serviço como Amazon DynamoDB, Amazon Redshift ou Amazon S3.
Familiarização com a terminologia do Kinesis Data Streams
Fluxo de dados do Kinesis
Um fluxo de dados do Kinesis é um conjunto de fragmentos. Cada fragmento tem uma sequência de registros de dados. Cada registro de dados tem um número de sequência atribuído pelo Kinesis Data Streams.
Registro de dados
Um registro de dados é a unidade de dados armazenada em um fluxo de dados do Kinesis. Os registros de dados são compostos de um número de sequência, uma chave de partição e um blob de dados, que é uma sequência de bytes imutável. O Kinesis Data Streams não inspeciona, interpreta nem altera dados no blob. Um blob de dados pode ter até 1 MB.
Modo de capacidade
O modo de capacidade de um fluxo de dados determina como a capacidade é gerenciada e como são geradas cobranças pelo seu uso. No Kinesis Data Streams você atualmente pode escolher entre o modo sob demanda e o modo provisionado para seus fluxos de dados. Para obter mais informações, consulte Escolha o modo certo para transmitir.
No modo sob demanda, o Kinesis Data Streams gerencia automaticamente os fragmentos para fornecer o throughput necessário. Apenas o throughput real usado é cobrado, e o Kinesis Data Streams acomoda automaticamente as necessidades de throughput das cargas de trabalho à medida que elas aumentam ou diminuem. Para obter mais informações, consulte Atributos e casos de uso do modo On-demand Standard.
No modo provisionado, é necessário especificar o número de fragmentos para o fluxo de dados. A capacidade total de um fluxo de dados é a soma das capacidades de seus fragmentos. É possível aumentar ou diminuir o número de fragmentos em um fluxo de dados conforme necessário e recebe uma cobrança pelo número de fragmentos a uma taxa horária. Para obter mais informações, consulte Casos de uso e atributos do modo provisionado.
Período de retenção
O período de retenção é o tempo em que os registros de dados permanecem acessíveis depois de serem adicionados ao fluxo. O período de retenção de um fluxo é definido para um padrão de 24 horas após a criação. Você pode aumentar o período de retenção em até 8760 horas (365 dias) usando a IncreaseStreamRetentionPeriodoperação e diminuir o período de retenção para um mínimo de 24 horas usando a DecreaseStreamRetentionPeriodoperação. Encargos adicionais incidem sobre streams com período de retenção definido acima de 24 horas. Para obter mais informações, consulte Definição de preço do Amazon Kinesis Data Streams
Produtor
Os produtores colocam registros no Amazon Kinesis Data Streams. Por exemplo, um servidor web que envia dados de log para um fluxo é um produtor.
Consumidor
Os consumidores obtêm registros do Amazon Kinesis Data Streams e os processam. Esses consumidores são conhecidos como Aplicativo do Amazon Kinesis Data Streams.
Aplicativo do Amazon Kinesis Data Streams
Uma aplicação do Amazon Kinesis Data Streams é um consumidor de fluxo normalmente executado em uma frota de instâncias do EC2.
Há dois tipos de consumidores que podem ser desenvolvidos: consumidores avançados compartilhados e consumidores avançados aprimorados. Para saber mais sobre as diferenças entre eles, e para ver como é possível criar cada tipo de consumidor, consulte Leitura de dados do Amazon Kinesis Data Streams.
A saída de uma aplicação do Kinesis Data Streams pode ser a entrada de outro fluxo, permitindo a criação de topologias complexas que processam dados em tempo real. Um aplicativo também pode enviar dados para vários outros AWS serviços. Pode haver vários aplicativos para um fluxo, e cada aplicativo pode consumir dados do fluxo de forma independente e simultaneamente.
Fragmento
Um fragmento é uma sequência de registros de dados identificada de forma exclusiva em um fluxo. Um fluxo é composto de um ou mais fragmentos, sendo que cada um deles fornece uma unidade fixa de capacidade. Cada fragmento é compatível com até 5 transações por segundo para leituras, até a taxa máxima total de leitura de dados de 2 MB por segundo, e até 1.000 registros por segundo para gravações, até a taxa máxima total de gravação de dados de 1 MB por segundo (incluindo chaves de partição). A capacidade de dados do seu fluxo é uma função do número de fragmentos especificados para o fluxo. A capacidade total do fluxo é a soma das capacidades de seus fragmentos.
Se a taxa de dados aumenta, é possível aumentar ou diminuir o número de fragmentos alocados para seu fluxo. Para obter mais informações, consulte Refragmentar um fluxo.
Chave de partição
A chave de partição é usada para agrupar os dados por fragmento dentro de um fluxo. O Kinesis Data Streams segrega os registros de dados pertencentes a um fluxo em vários fragmentos. Ele usa a chave de partição associada a cada registro de dados para determinar a qual fragmento um determinado registro de dados pertence. As chaves de partição são strings Unicode, com um limite de tamanho máximo de 256 caracteres para cada chave. Uma função de hash MD5 é usada para mapear chaves de partição para valores inteiros de 128 bits e para mapear registros de dados associados para fragmentos usando os intervalos de chaves de hash dos fragmentos. Quando um aplicativo insere dados em um fluxo, ele deve especificar uma chave de partição.
Número de sequência
Cada registro de dados tem um número de sequência exclusivo por chave de partição dentro do fragmento. O Kinesis Data Streams atribuirá o número de sequência depois que um registro é gravado no fluxo com client.putRecords ou client.putRecord. Geralmente, os números de sequência da mesma chave de partição aumentam ao longo do tempo. Quanto maior for o período entre as solicitações de gravação, maiores serão os números de sequência.
nota
Os números de sequência não podem ser usados como índices para conjuntos de dados dentro do mesmo fluxo. Para separar logicamente conjuntos de dados, use chaves de partição ou crie um fluxo separado para cada conjunto de dados.
Kinesis Client Library
A Kinesis Client Library é compilada em sua aplicação para permitir o consumo de dados tolerante a falhas do fluxo. A Kinesis Client Library garante que para cada fragmento haja um processador de registros em execução e processando o fragmento. A biblioteca também simplifica a leitura de dados do fluxo. A Kinesis Client Library usa tabelas do Amazon DynamoDB para armazenar metadados relacionados ao consumo de dados. Ela cria três tabelas para cada aplicação que esteja processando dados. Para obter mais informações, consulte Usar a Kinesis Client Library.
Nome da aplicação
O nome identifica uma aplicação do Amazon Kinesis Data Streams. Cada um dos seus aplicativos deve ter um nome exclusivo que tenha como escopo a AWS conta e a região usadas pelo aplicativo. Esse nome é usado como um nome para a tabela de controle no Amazon DynamoDB e o namespace para as métricas da Amazon. CloudWatch
Server-Side Criptografia
O Amazon Kinesis Data Streams pode criptografar automaticamente dados confidenciais à medida que um produtor os insere em um fluxo. O Kinesis Data Streams usa chaves mestras do AWS KMS para criptografia. Para obter mais informações, consulte Proteção de dados no Amazon Kinesis Data Streams.
nota
Para ler ou gravar um em um fluxo criptografado, aplicativos produtores e consumidores devem ter permissão para acessar a chave mestra. Para obter informações sobre a concessão de permissões para aplicativos produtores e consumidores, consulte Permissões para usar as chaves do KMS geradas pelo usuário.
nota
O uso da criptografia do lado do servidor incorre AWS Key Management Service em custos ().AWS KMS Para obter mais informações, consulte AWS Key Management Service Pricing
