本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
配置和自定义查询与响应生成
您可以配置和自定义检索和响应生成,从而进一步提高响应的相关性。例如,您可以对文档元数据字段/属性应用筛选条件,以使用最近更新的文档或修改时间最近的文档。
除编排和生成外,以下所有配置仅适用于非结构化数据源。
要在控制台或中了解有关这些配置的更多信息API,请从以下主题中进行选择。
从亚马逊 Kendra GenAI 索引中检索
您可以查询使用 Amazon Kendra GenAI 索引的知识库,并且仅返回来自数据源的相关文本。对于此查询,请发送 Retrieve使用适用于 Amazon Bedrock 的代理运行时端点进行请求,就像使用标准知识库一样。
从带有 Amazon Kendra GenAI 索引的知识库返回的响应结构与标准相同。 KnowledgeBaseRetrievalResult但是,回复中还包括来自Amazon Kendra的其他几个字段。
下表描述了您可能在返回的响应中看到的 Amazon Kendra 字段。亚马逊 Bedrock 从亚马逊 Kendra 的回复中获得了这些字段。如果该响应不包含这些字段,那么 Amazon Bedrock 返回的查询结果也不会包含这些字段。
| 字段 |
描述 |
|
x-amz-kendra-document-标题
|
返回的文档的标题。
|
|
x-amz-kendra-score-信心
|
响应与查询的相关程度的相对排名。可能的值为 VERY _ HIGH HIGH、MEDIUM、LOW、和 NOT _ AVAILABLE。
|
|
x-amz-kendra-passage-id
|
返回的通道的 ID。
|
|
x-amz-kendra-document-id
|
返回的文档的 ID。
|
|
DocumentAttributes
|
来自 Amazon Kendra 的文档属性或元数据字段。知识库返回的查询结果将它们存储为元数据键值对。您可以使用 Amazon Bedrock 中的元数据筛选功能筛选结果。有关更多信息,请参阅 DocumentAttribute。
|
搜索类型定义了知识库中的数据来源的查询方式。可能的搜索类型如下:
要了解如何定义搜索类型,请选择首选方法的选项卡,然后按照以下步骤操作:
- Console
-
按照 利用查询和响应测试知识库 中的控制台步骤进行操作。打开配置窗格时,您将看到以下搜索类型选项:
-
默认:Amazon Bedrock 决定哪种搜索策略最适合您的向量存储配置。
-
混合:Amazon Bedrock 同时使用向量嵌入和原始文本来查询知识库。只有当您使用配置了可筛选文本字段的 Amazon OpenSearch Serverless 矢量存储时,此选项才可用。
-
语义:Amazon Bedrock 使用其向量嵌入来查询知识库。
- API
-
当你做一个 Retrieve 或 RetrieveAndGenerate请求,包括一个映射到KnowledgeBaseRetrievalConfiguration对象的retrievalConfiguration字段。要查看此字段的位置,请参阅 Retrieve 和 RetrieveAndGenerateAPI参考文献中的请求正文。
以下JSON对象显示了在KnowledgeBaseRetrievalConfiguration对象中设置搜索类型配置所需的最少字段:
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"overrideSearchType": "HYBRID | SEMANTIC"
}
}
在 overrideSearchType 字段中指定搜索类型。您有以下选项:
-
如果您没有指定值,Amazon Bedrock 会决定哪种搜索策略最适合您的向量存储配置。
-
HYBRID— Amazon Bedrock 同时使用矢量嵌入和原始文本来查询知识库。只有当您使用配置了可筛选文本字段的 Amazon OpenSearch Serverless 矢量存储时,此选项才可用。
-
SEMANTIC— Amazon Bedrock 使用其向量嵌入来查询知识库。
查询分解是一种用于将复杂查询分解为更小、更易于管理的子查询的技术。这种方法可以帮助检索更准确、更相关的信息,尤其是在初始查询涉及多个方面或过于宽泛的情况下。启用此选项可能会导致对您的知识库执行多个查询,这可能有助于获得更准确的最终响应。
例如,对于像 “谁在2022年FIFA世界杯上得分更高,阿根廷还是法国?” ,在生成最终答案之前,Amazon Bedrock 知识库可能会先生成以下子查询:
-
阿根廷在2022年FIFA世界杯决赛中打进了多少球?
-
法国在 FIFA 2022年世界杯决赛中打进了多少球?
- Console
-
-
创建和同步数据来源或使用现有知识库。
-
进入测试窗口并打开配置面板。
-
启用查询改写。
- API
-
POST /retrieveAndGenerate HTTP/1.1
Content-type: application/json
{
"input": {
"text": "string"
},
"retrieveAndGenerateConfiguration": {
"knowledgeBaseConfiguration": {
"orchestrationConfiguration": { // Query decomposition
"queryTransformationConfiguration": {
"type": "string" // enum of QUERY_DECOMPOSITION
}
},
...}
}
在基于信息检索生成响应时,您可以使用推理参数来更好地控制模型在推理期间的行为并影响模型的输出。
要了解如何修改推理参数,请选择首选方法的选项卡,然后按照以下步骤操作:
- Console
-
要在查询知识库时修改推理参数,请按照 利用查询和响应测试知识库 中的控制台步骤操作。在打开配置窗格时,您会看到推理参数部分。根据需要修改参数。
要在与您的文档交互时修改推理参数,请按照 无需配置知识库即可使用您的文档聊天 中的步骤操作。在配置窗格中,展开推理参数部分,并根据需要修改参数。
- API
-
您在调用时提供模型参数 RetrieveAndGenerateAPI。 您可以通过在(如果您查询知识库)或knowledgeBaseConfiguration(如果您与文档聊天)inferenceConfig字段中externalSourcesConfiguration提供推理参数来自定义模型。
inferenceConfig 字段中有一个包含以下参数的 textInferenceConfig 字段,您可以执行以下操作:
温度
topP
maxTokenCount
stopSequences
您可以通过在 externalSourcesConfiguration 和 knowledgeBaseConfiguration 的inferenceConfig 字段中使用以下参数来自定义模型:
温度
topP
maxTokenCount
stopSequences
有关每个参数的功能的详细说明,请参阅 利用推理参数影响响应生成。
此外,您可以通过 additionalModelRequestFields 映射提供 textInferenceConfig 不支持的自定义参数。您可以使用此参数提供特定模型所特有的参数,有关唯一参数的信息,请参阅 基础模型的推理请求参数和响应字段。
如果 textInferenceConfig 中省略了参数,则将使用默认值。textInferneceConfig 中未识别的所有参数都将被忽略,而 AdditionalModelRequestFields 中未识别的所有参数都将导致异常。
如果 additionalModelRequestFields 和 TextInferenceConfig 中有相同的参数,则会引发验证异常。
在中使用模型参数 RetrieveAndGenerate
以下是 RetrieveAndGenerate 请求正文中 generationConfiguration 下的 inferenceConfig 和 additionalModelRequestFields 结构示例:
"inferenceConfig": {
"textInferenceConfig": {
"temperature": 0.5,
"topP": 0.5,
"maxTokens": 2048,
"stopSequences": ["\nObservation"]
}
},
"additionalModelRequestFields": {
"top_k": 50
}
上面的示例将 a temperature 设置为 0.5,top_p为 0.5,maxTokens为 2048,如果在生成的响应中遇到字符串 “\nObservation”,则停止生成,并传递自定义top_k值 50。
当您查询知识库时,默认情况下,Amazon Bedrock 会在响应中返回最多五个结果。每个结果都对应一个来源块。
要修改要返回的最大结果数,请选择首选方法对应的选项卡,然后按照以下步骤操作:
- Console
-
按照 利用查询和响应测试知识库 中的控制台步骤进行操作。在配置窗格中,展开检索结果的最大数量。
- API
-
当你做一个 Retrieve 或 RetrieveAndGenerate请求,包括一个映射到KnowledgeBaseRetrievalConfiguration对象的retrievalConfiguration字段。要查看此字段的位置,请参阅 Retrieve 和 RetrieveAndGenerateAPI参考文献中的请求正文。
以下JSON对象显示了在KnowledgeBaseRetrievalConfiguration对象中设置要返回的最大结果数所需的最小字段:
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": number
}
}
指定要在numberOfResults字段中KnowledgeBaseRetrievalConfiguration返回的最大检索结果数(有关可接受值的范围,请参阅中的numberOfResults字段)。
您可以将筛选器应用于fields/attributes to help you further improve the relevancy of
responses. Your data sources can include document metadata attributes/fields要筛选的文档,也可以指定要在嵌入中包含哪些字段。例如,文档“epoch_modification_time”或文档在 1970 年 1 月 1 日最后一次更新之后经历的秒数。您可以通过将“epoch_modification_time”设置为大于某个数值,筛选出最新的数据。这些最新的文档可用于查询。
要在查询知识库时使用筛选条件,请检查您的知识库是否满足以下要求:
-
配置数据来源连接器时,大多数连接器都会抓取文档的主元数据字段。如果您使用 Amazon S3 存储桶作为数据源,则该存储桶必须至少fileName.extension.metadata.json包含与之关联的文件或文档的存储桶。有关配置元数据文件的连接配置更多信息,请参阅中的文档元数据字段。
-
如果知识库的向量索引位于 Amazon OpenSearch Serverless 矢量存储中,请检查该faiss引擎是否配置了矢量索引。如果向量索引是使用 nmslib 引擎配置,则您必须执行以下操作之一:
-
如果您要向 Amazon Aurora 数据库集群中的现有向量索引添加元数据,则在开始摄取之前,您必须为元数据文件中的每个元数据属性向表中添加一列。元数据属性值将写入这些列。
如果您的数据源中有PDF文档,并且使用 Amazon OpenSearch Serverless 作为矢量存储:Amazon Bedrock 知识库将生成文档页码并将其存储在名为-的元数据字段/属性中。x-amz-bedrock-kb document-page-number请注意,如果您为文档选择不分块,则不支持存储在元数据字段中的页码。
您可以使用以下筛选运算符在查询时筛选结果:
筛选运算符
| 运算符 |
控制台 |
API过滤器名称 |
支持的属性数据类型 |
筛选结果 |
| Equals |
= |
equals |
字符串、数字、布尔值 |
属性与您提供的值相匹配 |
| Not equals |
!= |
notEquals |
字符串、数字、布尔值 |
属性与您提供的值不匹配 |
| Greater than |
> |
greaterThan |
数字 |
属性大于您提供的值 |
| Greater than or equals |
>= |
greaterThanOr等于 |
数字 |
属性大于或等于您提供的值 |
| Less than |
< |
lessThan |
数字 |
属性小于您提供的值 |
| Less than or equals |
<= |
lessThanOr等于 |
数字 |
属性小于或等于您提供的值 |
| In |
: |
in |
字符串列表 |
属性在您提供的列表中(目前亚马逊 OpenSearch 无服务器矢量商店最受支持) |
| Not in |
!: |
notIn |
字符串列表 |
属性不在您提供的列表中(目前,Amazon OpenSearch Serverless 矢量存储最受支持) |
| 开始于 |
^ |
startsWith |
字符串 |
属性以您提供的字符串开头(目前最支持的是 Amazon OpenSearch Serverless 矢量存储) |
要组合筛选运算符,可以使用以下逻辑运算符:
逻辑运算符
| 运算符 |
控制台 |
API筛选字段名称 |
筛选结果 |
| 并且 |
以及 |
andAll |
结果满足组中的所有筛选表达式 |
| 或 |
或 |
orAll |
结果满足组中至少一个筛选表达式 |
要了解如何使用元数据筛选结果,请选择首选方法对应的选项卡,然后按照以下步骤操作:
- Console
-
按照 利用查询和响应测试知识库 中的控制台步骤进行操作。当你打开配置窗格时,你会看到筛选条件部分。以下过程介绍了不同的应用场景:
-
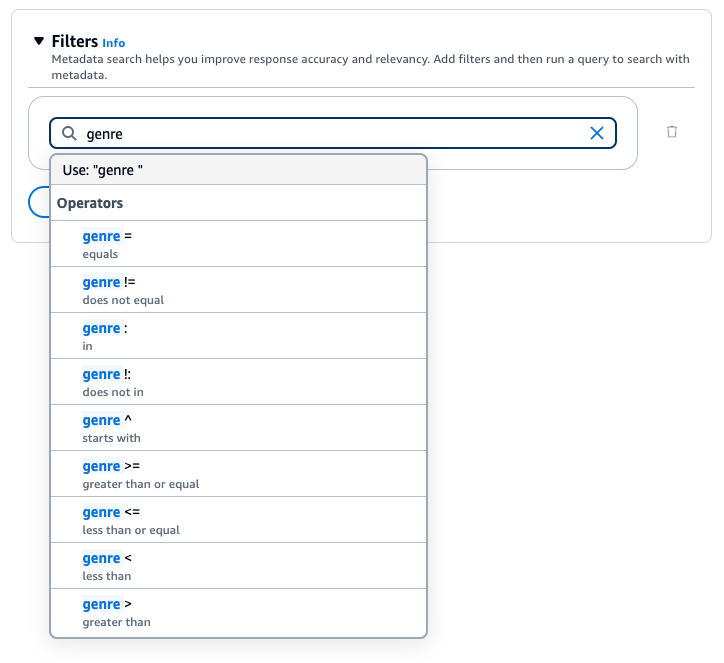
要添加筛选条件,请在框中输入元数据属性、筛选运算符和值来创建筛选表达式。用空格分隔表达式的每个部分。按 Enter 来添加筛选条件。
有关可接受的筛选运算符的列表,请参阅上面的筛选运算符表。在元数据属性后面添加空格时,您也可以看到筛选运算符列表。
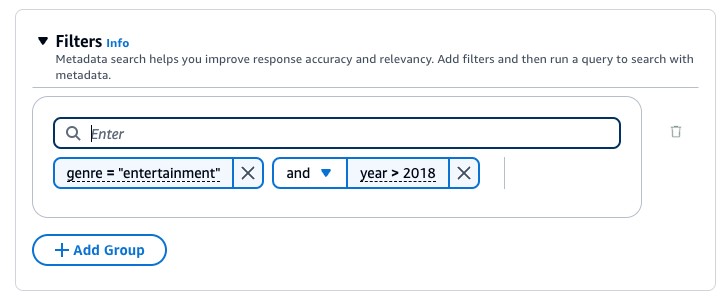
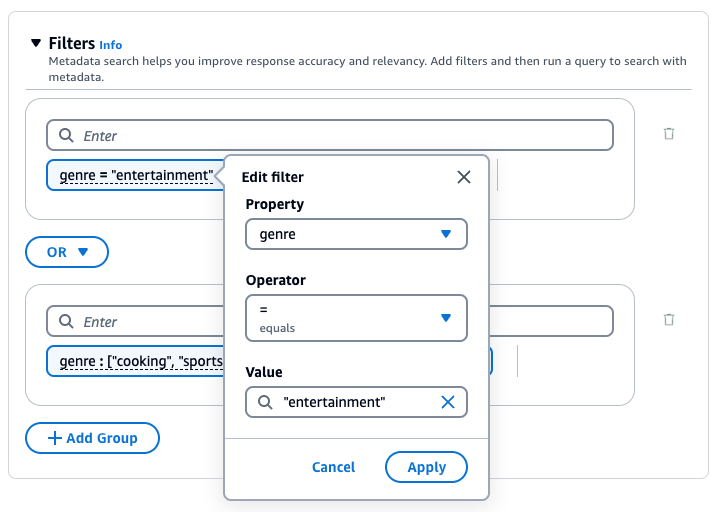
例如,您可以通过添加以下筛选条件从来源文档中筛选出包含值为 "entertainment" 的 genre 元数据属性的结果:genre = "entertainment"。
-
要添加其他筛选条件,请在框中输入另一个筛选表达式,然后按 Enter。您最多可以在组中添加 5 个筛选条件。
-
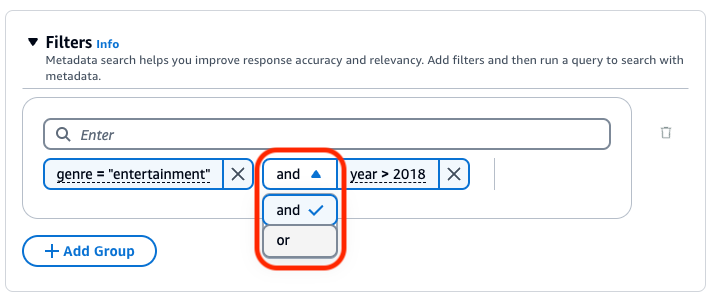
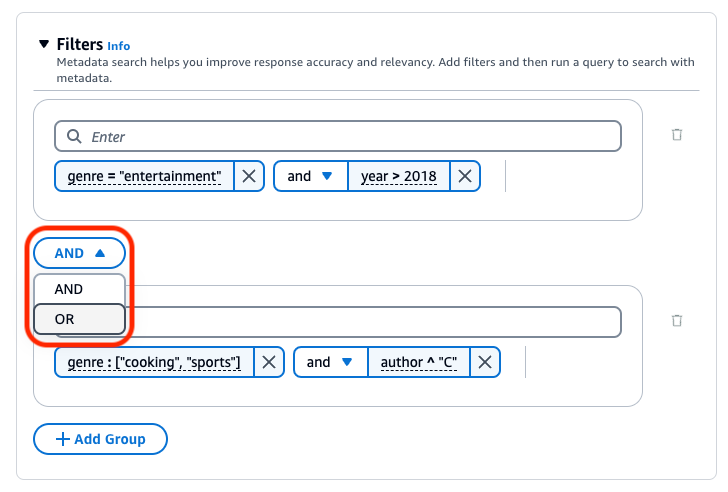
默认情况下,查询将返回满足您提供的所有筛选表达式的结果。要返回至少满足其中一个筛选表达式的结果,请在任意两个筛选操作之间选择和下拉菜单,然后选择或。
-
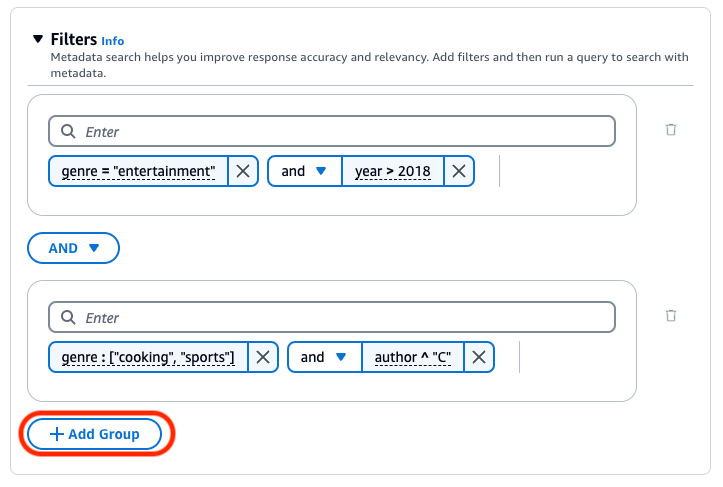
要组合不同的逻辑运算符,请选择 + 添加组以添加筛选条件组。在新组中输入筛选表达式。您可以添加最多 5 个组。
-
要更改所有筛选组之间使用的逻辑运算符,请在任意两个筛选组之间选择AND下拉菜单,然后选择或。
-
要编辑筛选条件,请将其选中,修改筛选操作,然后选择应用。
-
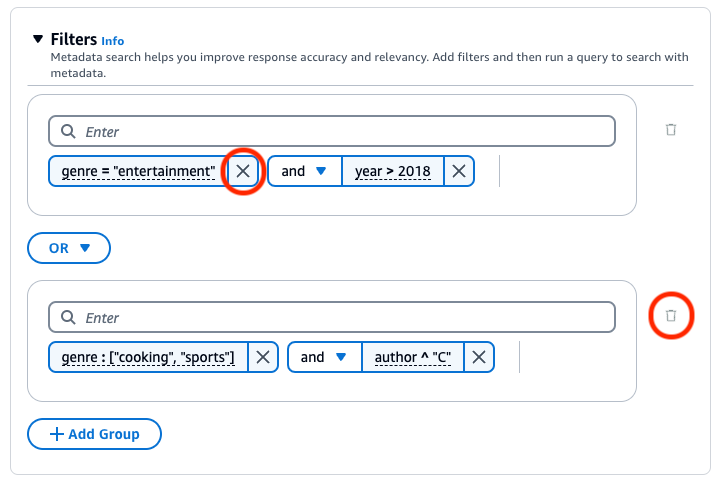
要移除筛选条件组,请选择相应组旁边的垃圾桶图标 (
 )。要移除筛选条件,请选择相应筛选条件旁边的删除图标 (
)。要移除筛选条件,请选择相应筛选条件旁边的删除图标 (
 )。
)。
下图显示了一个筛选条件配置示例,除了类型为 "cooking" 或 "sports" 且作者名字以 "C" 开头的文档外,该配置还返回了所有 2018 之后编写的类型为 "entertainment" 的文档。
- API
-
当你做一个 Retrieve 或 RetrieveAndGenerate请求,包括一个retrievalConfiguration字段,映射到一个KnowledgeBaseRetrievalConfiguration对象。要查看此字段的位置,请参阅 Retrieve 和 RetrieveAndGenerateAPI参考文献中的请求正文。
以下JSON对象显示了KnowledgeBaseRetrievalConfiguration对象中为不同用例设置过滤器所需的最少字段:
-
使用一个筛选运算符(请参阅上面的筛选运算符表)。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
}
}
}
-
使用逻辑运算符(请参阅上面的逻辑运算符表)最多可组合 5 个。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
}
}
}
-
使用逻辑运算符将最多 5 个筛选运算符组合到一个筛选条件组中,使用第二个逻辑运算符将该筛选条件组与其他筛选运算符组合。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
],
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
]
}
}
}
-
将最多 5 个筛选条件组嵌入到另一个逻辑运算符中,从而将它们组合。您可以创建一个嵌入级别。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
],
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
]
}
}
}
下表描述了您可以使用的筛选条件类型:
| 字段 |
支持的值数据类型 |
筛选结果 |
equals |
字符串、数字、布尔值 |
属性与您提供的值相匹配 |
notEquals |
字符串、数字、布尔值 |
属性与您提供的值不匹配 |
greaterThan |
数字 |
属性大于您提供的值 |
greaterThanOrEquals |
数字 |
属性大于或等于您提供的值 |
lessThan |
数字 |
属性小于您提供的值 |
lessThanOrEquals |
数字 |
属性小于或等于您提供的值 |
in |
字符串列表 |
属性在您提供的列表中 |
notIn |
字符串列表 |
属性不在您提供的列表中 |
startsWith |
字符串 |
属性以您提供的字符串开头(仅支持 Amazon OpenSearch Serverless 矢量存储) |
要组合筛选条件类型,您可以使用以下逻辑运算符之一:
| 字段 |
映射到 |
筛选结果 |
andAll |
最多 5 种筛选条件类型的列表 |
结果满足组中的所有筛选表达式 |
orAll |
最多 5 种筛选条件类型的列表 |
结果满足组中至少一个筛选表达式 |
有关示例,请参阅发送查询并包含筛选条件(检索)和发送查询并包含筛选条件(RetrieveAndGenerate)。
Amazon Bedrock 知识库根据用户查询和元数据架构生成并应用检索筛选器。
该功能目前仅适用于 Anthropic Claude 3.5 Sonnet.
在中vectorSearchConfiguration指定 implicitFilterConfiguration Retrieve请求正文。包括以下字段:
以下是您可以添加到数组中的metadataAttributes元数据架构的示例。
[
{
"key": "company",
"type": "STRING",
"description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc"
},
{
"key": "ticker",
"type": "STRING",
"description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL"
},
{
"key": "pe_ratio",
"type": "NUMBER",
"description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper."
},
{
"key": "is_us_company",
"type": "BOOLEAN",
"description": "Indicates whether the company is a US company."
},
{
"key": "tags",
"type": "STRING_LIST",
"description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc"
}
]
当您查询知识库并请求生成响应时,Amazon Bedrock 使用将说明和上下文与用户查询相结合的提示模板来构造发送到模型以生成响应的生成提示。您还可以自定义编排提示,它将用户的提示转换为搜索查询。您可以使用以下工具设计提示模板:
-
提示占位符:Amazon Bedrock 知识库中的预定义变量,这些变量在知识库查询期间在运行时动态填充。在系统提示中,您将看到这些占位符两边都有 $ 符号。以下列表介绍了可以使用的占位符:
| 变量 |
提示模板 |
已替换为 |
模型 |
必填? |
| $query$ |
编排、生成 |
发送到知识库的用户查询。 |
Anthropic Claude Instant, Anthropic Claude v2.x |
Yes |
| Anthropic Claude 3 Sonnet |
否(自动包含在模型输入中) |
| $search_results$ |
生成 |
针对用户查询的检索到的结果。 |
全部 |
Yes |
| $output_format_instructions$ |
编排 |
用于格式化响应生成和引文的底层指令。因模型而异。如果您定义了自己的格式化指令,建议您删除此占位符。如果没有这个占位符,响应将不包含引文。 |
全部 |
否 |
| $current_time$ |
编排、生成 |
当前时间。 |
全部 |
否 |
-
XML标签 — Anthropic 模型支持使用XML标签来构造和描绘您的提示。请使用描述性标签名称以获得最佳结果。例如,在默认的系统提示中,您将看到用于描述先前询问过的相关数据库的 <database> 标签)。有关更多信息,请参阅中的使用XML标签 Anthropic 用户指南。
有关提示工程的一般性准则,请参阅 提示工程概念。
选择您首选方法的选项卡,然后按照以下步骤操作:
- Console
-
按照 利用查询和响应测试知识库 中的控制台步骤进行操作。在测试窗口中,打开生成响应。然后,在配置窗格中,展开知识库提示模板部分。
-
选择编辑。
-
在文本编辑器中编辑系统提示,包括必要的提示占位符和XML标签。要恢复到默认提示模板,请选择重置为默认值。
-
编辑完成后,选择保存更改。要在不保存系统提示的情况下退出,请选择放弃更改。
- API
-
当你做一个 RetrieveAndGenerate请求,包括一个generationConfiguration字段,映射到一个GenerationConfiguration对象。要查看此字段的位置,请参阅 RetrieveAndGenerateAPI参考文献中的请求正文。
以下JSON对象显示了在GenerationConfiguration对象中设置要返回的最大检索结果数所需的最小字段:
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": "string"
}
}
在textPromptTemplate字段中输入您的自定义提示模板,包括必要的提示占位符和XML标签。有关系统提示符中允许的最大字符数,请参阅中的textPromptTemplate字段GenerationConfiguration。
您可以基于自己的应用场景和负责任的人工智能政策为知识库实施防护机制。您可以创建针对不同应用场景量身定制的多个防护机制,并跨多个请求和响应条件应用它们,从而在整个知识库中提供一致的用户体验并标准化安全控制。您可以将拒绝的主题配置为禁止不受欢迎的主题,将内容筛选条件配置为屏蔽模型输入和响应中的有害内容。有关更多信息,请参阅 使用 Amazon Bedrock 防护机制阻止模型中的有害内容。
Claude 3 Sonnet 和 Haiku 目前不支持针对知识库应用具有上下文基础的防护机制。
有关提示工程的一般性准则,请参阅 提示工程概念。
选择您首选方法的选项卡,然后按照以下步骤操作:
- Console
-
按照 利用查询和响应测试知识库 中的控制台步骤进行操作。在测试窗口中,打开生成响应。然后,在配置窗格中,展开防护机制部分。
-
在防护机制部分,选择防护机制的名称和版本。如果您想查看所选防护机制和版本的详细信息,请选择查看。
或者,您可以通过选择防护机制链接来创建一个新的机制。
-
编辑完成后,选择保存更改。要退出而不保存更改,请选择放弃更改。
- API
-
当你做一个 RetrieveAndGenerate请求,请在请求中包含generationConfiguration要使用护栏的guardrailConfiguration字段。要查看此字段的位置,请参阅 RetrieveAndGenerateAPI参考文献中的请求正文。
以下JSON对象显示了在中设置所需的最少字段guardrailConfiguration:GenerationConfiguration
"generationConfiguration": {
"guardrailConfiguration": {
"guardrailId": "string",
"guardrailVersion": "string"
}
}
指定所选防护机制的 guardrailVersion 和 guardrailId。