AWS Lake Formation 支持在 AWS Glue Data Catalog 中创建使用 Apache Parquet 数据格式的 Apache Iceberg 表,这些表的数据驻留在 Amazon S3 中。该数据目录中的表是表示数据存储中数据的元数据定义。默认情况下,Lake Formation 会创建 Iceberg v2 表。有关 v1 和 v2 表之间的区别,请参阅 Apache Iceberg 文档中的格式版本更改
Apache Iceberg
您可以使用 Lake Formation 控制台或 AWS Glue API 中的 CreateTable 操作在数据目录中创建 Iceberg 表。有关更多信息,请参阅 CreateTable 操作 (Python: create_table)。
在数据目录中创建 Iceberg 表时,您必须在 Amazon S3 中指定表格式和元数据文件路径,以便能够执行读取和写入操作。
当您向 AWS Lake Formation 注册 Amazon S3 数据位置时,您可以使用 Lake Formation 通过精细访问控制权限来保护 Iceberg 表。对于 Amazon S3 中的源数据和未向 Lake Formation 注册的元数据,访问权限由 Amazon S3 和 AWS Glue 操作的 IAM 权限策略决定。有关更多信息,请参阅 管理 Lake Formation 权限。
注意
数据目录不支持创建分区和添加 Iceberg 表属性。
先决条件
要在数据目录中创建 Iceberg 表并设置 Lake Formation 数据访问权限,您需要完成以下要求:
-
在没有向 Lake Formation 注册数据的情况下创建 Iceberg 表所需的权限。
除了在数据目录中创建表所需的权限外,表创建者还需要以下权限:
针对资源 arn:aws:s3:::{bucketName} 的
s3:PutObject-
针对资源 arn:aws:s3:::{bucketName} 的
s3:GetObject -
针对资源 arn:aws:s3:::{bucketName} 的
s3:DeleteObject
-
使用向 Lake Formation 注册的数据创建 Iceberg 表所需的权限:
要使用 Lake Formation 管理和保护数据湖中的数据,请向 Lake Formation 注册包含表数据的 Amazon S3 位置。这样,Lake Formation 就可以向 Athena、Redshift Spectrum 和 Amazon EMR 等 AWS 分析服务提供凭证以访问数据。有关注册 Amazon S3 位置的更多信息,请参阅向数据湖添加 Amazon S3 位置。
读取和写入向 Lake Formation 注册的基础数据的主体需要以下权限:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESS对某个位置具有数据位置权限的主体也对所有子位置具有位置权限。
有关数据位置权限的更多信息,请参阅基础数据访问控制。
-
要启用压缩,该服务需要代入有权更新数据目录中的表的 IAM 角色。有关详细信息,请参阅表优化先决条件。
创建 Iceberg 表
您可以使用 Lake Formation 控制台或 AWS Command Line Interface创建 Iceberg v1 和 v2 表,如本页所述。您也可以使用 AWS Glue 控制台或 AWS Glue 爬网程序创建 Iceberg 表。有关更多信息,请参阅《AWS Glue 开发人员指南》中的数据目录和爬网程序。
创建 Iceberg 表
登录 AWS Management Console,然后通过以下网址打开 Lake Formation 控制台:https://console.aws.amazon.com/lakeformation/
。 在数据目录下,选择表,然后使用创建表按钮指定以下属性:
-
表名称:输入表的唯一名称。如果您使用 Athena 访问表,请使用《Amazon Athena 用户指南》中的这些命名提示。
-
数据库:选择现有数据库或创建新数据库。
-
描述:表的描述。您可以编写描述以帮助您了解表的内容。
-
表格式:对于表格式,请选择 Apache Iceberg。
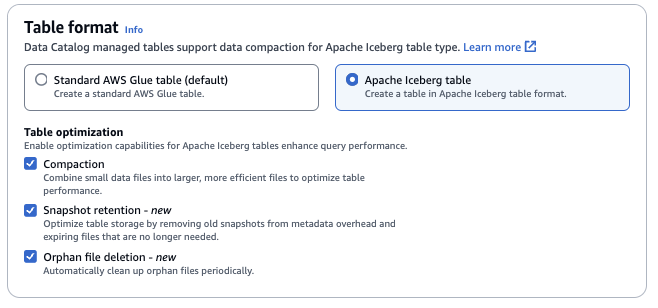
表优化
-
压缩 – 此功能会合并和重写数据文件以移除过时数据,并将碎片数据合并到更大、更高效的文件中。
快照保留 – 快照是带有时间戳的 Iceberg 表版本。借助快照保留配置,客户可以强制规定快照保留期限和要保留的快照数量。配置快照保留优化器可以移除不必要的旧快照及其相关底层文件,从而帮助管理存储开销。
孤立文件删除 – 孤立文件是指不再被 Iceberg 表元数据引用的文件。这些文件可能会逐渐堆积,尤其是在表删除或 ETL 任务失败等操作之后。启用孤立文件删除功能后,AWS Glue 会定期识别并移除这些不必要的文件,从而释放存储空间。
有关更多信息,请参阅优化 Iceberg 表。
-
-
IAM 角色:为了运行压缩,该服务会代表您代入一个 IAM 角色。您可以使用下拉列表选择一个 IAM 角色。确保该角色具有启用压缩所需的权限。
要了解有关所需权限的更多信息,请参阅表优化先决条件。
-
位置:指定 Amazon S3 中存储元数据表的文件夹的路径。Iceberg 需要数据目录中的元数据文件和位置才能执行读取和写入。
-
架构:选择添加列以添加列和列的数据类型。您可以选择创建一个空表,然后稍后更新架构。数据目录支持 Hive 数据类型。有关更多信息,请参阅 Hive 数据类型
。 Iceberg 允许您在创建表后演变架构和分区。您可以使用 Athena 查询更新表架构,使用 Spark 查询
更新分区。
-
