REL10-BP01 将工作负载部署到多个位置
将工作负载数据和资源分布到多个可用区,或在必要时分布到多个 AWS 区域。
AWS 中服务设计的一个基本原则是避免单点故障,包括底层物理基础设施。AWS 在全球多个地理位置(称为 Regions)提供云计算资源和服务。每个区域在物理和逻辑上都是独立的,由三个或更多 Availability Zones (AZs) 组成。可用区在地理上彼此接近,但在物理上是分开和隔离的。当您将工作负载分布于各个可用区和区域之间时,可以降低火灾、洪水、与天气相关的灾难、地震和人为错误等威胁的风险。
制定位置策略,以提供适合您的工作负载的高可用性。
期望结果:生产工作负载分布于多个可用区(AZ)或区域之间,以实现容错和高可用性。
常见反模式:
-
您的生产工作负载只存在于单个可用区中。
-
您在多可用区架构满足业务要求时实施多区域架构。
-
您的部署或数据变得不同步,这会导致配置偏差或数据复制不足。
-
当应用程序组件之间的韧性和多位置要求不同时,您未考虑这些组件之间的依赖关系。
建立此最佳实践的好处:
-
您的工作负载更能抵御意外事件,例如电源或环境控制故障、自然灾害、上游服务故障或影响可用区或整个区域的网络问题。
-
在启动特定 EC2 实例类型时,您可以访问更广泛的 Amazon EC2 实例清单,并降低出现 InsufficientCapacityExceptions(ICE)的可能性。
在未建立这种最佳实践的情况下暴露的风险等级:高
实施指导
在区域的至少两个可用区(AZ)中部署和运行所有生产工作负载。
使用多个可用区
可用区是资源托管位置,它们在物理上彼此分开,以避免由于火灾、洪水和龙卷风等风险而导致的相关故障。每个可用区都有独立的物理基础设施,包括市电连接、备用电源、机修服务和网络连接。这种安排方式可将其中任何组件的故障限制在受影响的可用区内。例如,如果可用区范围的事件导致 EC2 实例在受影响的可用区中不可用,则您在其它可用区的实例仍保持可用。
尽管同一 AWS 区域中的可用区在物理上是分开的,但它们之间的距离足够近,可以提供高吞吐量、低延迟(个位数毫秒)的联网。您可以在可用区之间同步复制大多数工作负载的数据,而不会显著影响用户体验。这样一来,您便能以主动/主动或主动/备用配置使用区域中的可用区。
与工作负载关联的所有计算均应分布于多个可用区中。这包括 Amazon EC2
您还应该为工作负载复制数据,并使其在多个可用区中可用。某些 AWS 托管式数据服务,例如 Amazon S3
如果您使用的是自行管理的存储,例如 Amazon Elastic Block Store(EBS)
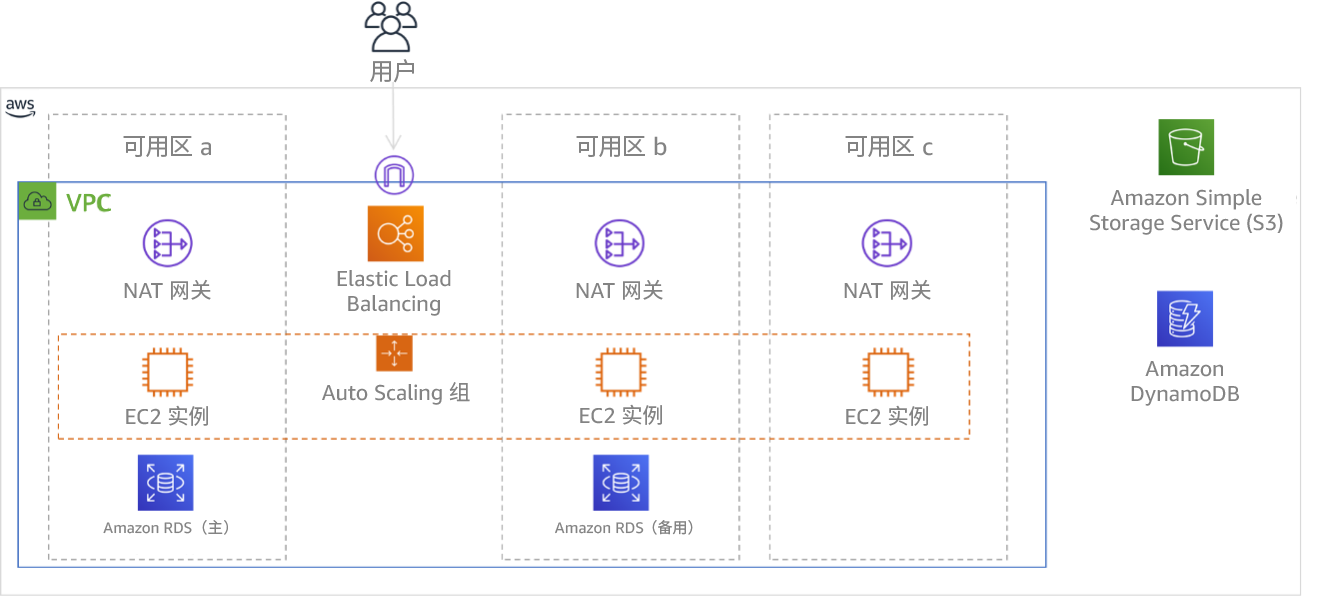
图 9:跨三个可用区部署的多层架构。请注意,Amazon S3 和 Amazon DynamoDB 始终会自动部署到多个可用区。而 ELB 也会被部署到所有三个区。
使用多个 AWS 区域
如果工作负载需要极高的韧性(如关键基础设施、与运行状况相关的应用程序或具有严格的客户或强制可用性要求的服务),您可能需要超出单个 AWS 区域所能提供的额外可用性。在这种情况下,您应该在至少两个 AWS 区域中部署和运行工作负载(假设数据驻留要求支持这么做)。
AWS 区域位于世界各地和多个大洲的不同地理区域。AWS 区域与单独的可用区相比,其物理分离和隔离程度甚至更高。除了少数例外情况,AWS 服务利用这种设计在不同区域之间完全独立运行(也称为区域服务)。AWS 区域服务的故障设计为不影响其它区域中的服务。
当您在多个区域中运行工作负载时,应考虑其它要求。由于不同区域中的资源彼此分开且独立,因此必须在每个区域中复制工作负载的组件。除计算服务和数据服务外,这还包括基本的基础设施,例如 VPC。
注意:在考虑多区域设计时,请验证工作负载能够在单个区域中运行。如果您在区域之间创建依赖关系,其中一个区域中的组件依赖于另一个区域中的服务或组件,则可能会增加故障风险并显著削弱可靠性状况。
为了简化多区域部署并保持一致性,AWS CloudFormation StackSets 可以跨多个区域复制整个 AWS 基础设施。AWS CloudFormation
您还必须跨您所选的每个区域复制数据。许多 AWS 托管式数据服务提供跨区域复制功能,包括 Amazon S3、Amazon DynamoDB、Amazon RDS、Amazon Aurora、Amazon Redshift、Amazon Elasticache 和 Amazon EFS。Amazon DynamoDB 全局表
AWS 还能够非常灵活地将请求流量路由到区域部署。例如,可以使用 Amazon Route 53
即使您选择不在多个区域中运行来实现高可用性,也可以将多个区域视为灾难恢复(DR)策略的一部分。如果可能,请在辅助区域中以热备用 或指示灯 配置来复制工作负载的基础设施组件和数据。在此设计中,您从主区域复制基准基础设施,如 VPC、自动扩缩组、容器编排工具和其它组件,但您将备用区域中的可变大小组件(如 EC2 实例和数据库副本的数量)配置为最小可操作大小。您还可以安排从主区域到备用区域的连续数据复制。如果发生事件,则可以横向扩展或增加备用区域中的资源,然后将其提升为主区域。
实施步骤
-
与业务利益相关者和数据驻留专家合作,来确定哪些 AWS 区域可用来托管您的资源和数据。
-
与业务和技术利益相关者合作,来评估您的工作负载,并确定其韧性需求是否可以通过多可用区方法(单个 AWS 区域)来满足,或者是否需要多区域方法(如果允许多个区域)。使用多个区域可以提高可用性,但可能会增加复杂性和成本。评估时考虑以下因素:
-
业务目标和客户要求:如果在可用区或区域中发生影响工作负载的事件,允许有多少停机时间? 评估恢复点目标,如 REL13-BP01 定义停机和数据丢失的恢复目标中所述。
-
灾难恢复(DR)要求:您想要确保自行抵御哪种潜在灾难? 考虑数据丢失或长期不可用的可能性,影响范围涉及单个可用区到整个区域。如果您跨可用区复制数据和资源,而单个可用区持续出现故障,则可以在另一个可用区中恢复服务。如果您跨区域复制数据和资源,则可以在另一个区域中恢复服务。
-
-
将计算资源部署到多个可用区中。
-
在 VPC 中,在不同的可用区中创建多个子网。将每个子网配置为足够大,以容纳处理工作负载所需的资源,即使在发生事件期间也是如此。有关更多详细信息,请参阅 REL02-BP03 确保 IP 子网分配考虑扩展和可用性。
-
如果您使用的是 Amazon EC2 实例,请使用 EC2 Auto Scaling
来管理实例。在创建自动扩缩组时,指定在上一步中选择的子网。 -
如果您正在对 Amazon ECS 或 Amazon EKS 使用 AWS Fargate 计算,请在创建 ECS 服务、启动 ECS 任务或为 EKS 创建 Fargate 配置文件时,选择您在第一步中选择的子网。
-
如果您使用的 AWS Lambda 函数需要在 VPC 中运行,请在创建 Lambda 函数时,选择您在第一步中选择的子网。对于任何没有 VPC 配置的函数,AWS Lambda 自动为您管理可用性。
-
将流量定向器(例如负载均衡器)放在计算资源之前。如果启用了跨区域负载均衡,AWS 应用程序负载均衡器和网络负载均衡器会检测何时由于可用区受损而无法访问 EC2 实例和容器等目标,并将流量重新路由到正常运行的可用区中的目标。如果您禁用跨区域负载均衡,请使用 Amazon 应用程序恢复控制器(ARC)来提供可用区转移功能。如果您使用的是第三方负载均衡器或已实施了自己的负载均衡器,请为它们配置跨不同可用区的多个前端。
-
-
跨多个可用区复制工作负载的数据。
-
如果您使用的是 AWS 托管式数据服务,例如 Amazon RDS、Amazon ElastiCache 或 Amazon FSx,请研读其用户指南以了解其数据复制和韧性功能。必要时启用跨可用区复制和失效转移。
-
如果您使用 AWS 托管式存储服务,例如 Amazon S3、Amazon EFS 和 Amazon FSx,请避免对需要高耐久性的数据使用单可用区或单区配置。对这些服务使用多可用区配置。查看相应服务的用户指南,以确定默认情况下是否启用了多可用区复制,或者是否必须启用它。
-
如果您运行的是自行管理的数据库、队列或其它存储服务,请根据应用程序的说明或最佳实践安排进行多可用区复制。熟悉应用程序的失效转移过程。
-
-
配置您的 DNS 服务以检测可用区受损,并将流量重新路由到运行状况正常的可用区。Amazon Route 53 与弹性负载均衡器结合使用时,可以自动执行此操作。还可以为 Route 53 配置失效转移记录,这些记录使用运行状况检查来响应仅具有正常运行的 IP 地址的查询。对于用于失效转移的任何 DNS 记录,请指定较短的生存时间(TTL)值(例如,60 秒或更短),以协助防止记录缓存阻碍恢复(Route 53 别名记录为您提供相应的 TTL)。
使用多个 AWS 区域时的额外步骤
-
跨所选区域复制工作负载使用的所有操作系统(OS)和应用程序代码。如有必要,可以使用 Amazon EC2 Image Builder 等解决方案复制 EC2 实例使用的亚马逊机器映像(AMI)。使用 Amazon ECR 跨区域复制等解决方案复制存储在注册表中的容器映像。为用于存储应用程序资源的任何 Amazon S3 存储桶启用区域复制。
-
将您的计算资源和配置元数据(例如,存储在 AWS Systems Manager Parameter Store 中的参数)部署到多个区域。使用前面步骤中介绍的相同过程,但请为您要用于工作负载的每个区域复制配置。使用 AWS CloudFormation 等基础设施即代码解决方案在区域之间统一复制配置。如果您在指示灯配置中使用辅助区域进行灾难恢复,您可以将计算资源的数量减少到最小值以节省成本,同时相应地增加恢复时间。
-
将数据从主区域复制到辅助区域。
-
Amazon DynamoDB 全局表提供数据的全局副本,可以从任何支持的区域写入这些副本。对于其它 AWS 托管式数据服务,例如 Amazon RDS、Amazon Aurora 和 Amazon Elasticache,您可以指定主(读/写)区域和副本(只读)区域。有关区域复制的详细信息,请参阅相应服务的用户和开发人员指南。
-
如果您运行的是自行管理的数据库,请根据应用程序的说明或最佳实践安排进行多区域复制。熟悉应用程序的失效转移过程。
-
如果工作负载使用 AWS EventBridge,则可能需要将选定的事件从主区域转发到辅助区域。为此,请将辅助区域中的事件总线指定为主区域中匹配事件的目标。
-
-
考虑是否以及在多大程度上希望跨区域使用相同的加密密钥。平衡安全性和易用性的典型方法是使用区域范围的密钥来处理区域本地数据和身份验证,并使用全球范围的密钥来对在不同区域间复制的数据进行加密。AWS Key Management Service(KMS)
支持 multi-region keys,以便安全地分发和保护跨区域共享的密钥。 -
考虑使用 AWS Global Accelerator,通过将流量定向到包含正常运行的端点的区域,来提高应用程序的可用性。
资源
相关最佳实践:
相关文档:
-
Amazon EC2 Auto Scaling: Example: Distribute instances across Availability Zones
-
Amazon Elasticache for Redis OSS: Replication across AWS 区域 using global datastores
-
Amazon Application Recovery Controller (ARC) Developer Guide
-
Sending and receiving Amazon EventBridge events between AWS 区域
-
Creating a Multi-Region Application with AWS Services
系列博客文章 -
Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
相关视频:
