本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
AWS Lake Formation 支援建立 Apache Iceberg 資料表,該資料表使用 中的 Apache Parquet 資料格式 AWS Glue Data Catalog ,並保留在 Amazon S3 中的資料。Data Catalog 中的資料表是中繼資料定義,代表資料存放區中的資料。Lake Formation 預設會建立 Iceberg v2 資料表。有關 v1 和 v2 資料表之間的區別,請參閱 Apache Iceberg 文件中的格式版本變更
Apache Iceberg
您可以使用 Lake Formation AWS Glue API主控台或 中的 CreateTable 操作,在 Data Catalog 中建立 Iceberg 資料表。如需詳細資訊,請參閱CreateTable 動作 (Python:creat_table)。
當您在資料目錄中建立 Iceberg 資料表時,您必須在 Amazon S3 中指定資料表格式和中繼資料檔案路徑,才能執行讀取和寫入。
當您向 註冊 Amazon S3 資料位置時,您可以使用 Lake Formation 使用精細存取控制許可來保護 Iceberg 資料表 AWS Lake Formation。對於 Amazon S3 中的來源資料和未向 Lake Formation 註冊的中繼資料,存取權取決於 Amazon S3 和 AWS Glue 動作的IAM許可政策。如需詳細資訊,請參閱管理 Lake Formation 許可。
注意
Data Catalog 不支援建立分割區和新增 Iceberg 資料表屬性。
必要條件
若要在資料目錄中建立 Iceberg 資料表,並設定 Lake Formation 資料存取許可,您需要完成下列要求:
-
建立 Iceberg 資料表所需的許可,而沒有向 Lake Formation 註冊的資料。
除了在 Data Catalog 中建立資料表所需的許可之外,資料表建立器還需要下列許可:
s3:PutObject資源 arn:aws:s3::{bucketName}-
s3:GetObject資源 arn:aws:s3::{bucketName} -
s3:DeleteObject資源 arn:aws:s3::{bucketName}
-
使用向 Lake Formation 註冊的資料建立 Iceberg 資料表所需的許可:
若要使用 Lake Formation 來管理和保護資料湖中的資料,請使用 Lake Formation 註冊具有資料表資料的 Amazon S3 位置。這樣 Lake Formation 才能將憑證轉譯至 AWS 分析服務,例如 Athena、Redshift Spectrum 和 Amazon EMR來存取資料。如需註冊 Amazon S3 位置的詳細資訊,請參閱 將 Amazon S3 位置新增至您的資料湖。
讀取和寫入向 Lake Formation 註冊的基礎資料之主體需要下列許可:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESS在位置上具有資料位置許可的委託人在所有子位置上也具有位置許可。
如需資料位置許可的詳細資訊,請參閱 基礎資料存取控制。
-
若要啟用壓縮,服務需要擔任具有更新資料目錄中資料表許可IAM的角色。如需詳細資訊,請參閱資料表最佳化先決條件 。
建立 Iceberg 資料表
您可以使用 Lake Formation 主控台或本頁所記錄的方式建立 Iceberg v1 AWS Command Line Interface 和 v2 資料表。您也可以使用 AWS Glue 主控台或 建立 Iceberg 資料表 AWS Glue 編目程式。如需詳細資訊,請參閱 AWS Glue 開發人員指南中的資料目錄和爬蟲程式。
若要建立 Iceberg 資料表
登入 AWS Management Console,然後在 開啟 Lake Formation 主控台https://console.aws.amazon.com/lakeformation/
。 在資料目錄下,選擇資料表 ,然後使用建立資料表按鈕指定下列屬性:
-
資料表名稱 :輸入資料表的名稱。如果您使用 Athena 存取資料表,請使用 Amazon Athena 使用者指南中的這些命名提示。
-
資料庫 :選擇現有的資料庫或建立新的資料庫。
-
描述:資料表的描述。您可以撰寫說明,來協助您了解資料表的內容。
-
資料表格式 :針對資料表格式 ,選擇 Apache Iceberg。
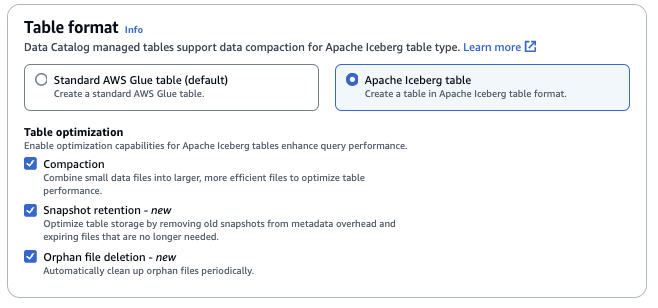
資料表最佳化
-
壓縮 – 合併資料檔案並重新寫入會移除過時的資料,並將分段的資料合併為更大、更有效率的檔案。
快照保留 – 快照是 Iceberg 資料表的時間戳記版本。快照保留組態可讓客戶強制執行保留快照的時間長度,以及要保留的快照數量。設定快照保留最佳化工具可以移除舊的、不必要的快照及其相關聯的基礎檔案,以協助管理儲存開銷。
孤立檔案刪除 – 孤立檔案是 Iceberg 資料表中繼資料不再參考的檔案。這些檔案會隨著時間累積,特別是在資料表刪除或ETL任務失敗等操作之後。啟用孤立檔案刪除 AWS Glue 允許定期識別和移除這些不必要的檔案,釋放儲存體。
如需詳細資訊,請參閱最佳化 Iceberg 資料表。
-
-
IAM 角色:若要執行壓縮,服務會代表您擔任 IAM角色。您可以使用下拉式清單選擇IAM角色。請確認角色具有啟用壓縮的必要權限。
若要進一步了解必要的許可,請參閱資料表最佳化先決條件 。
-
位置 :指定 Amazon S3 中存放中繼資料資料表之資料夾的路徑。Iceberg 需要資料目錄中的中繼資料檔案和位置,才能執行讀取和寫入。
-
結構描述 :選擇新增資料欄以新增資料欄和資料欄的資料類型。您可以選擇建立空白資料表,稍後再更新結構描述。Data Catalog 支援 Hive 資料類型。如需詳細資訊,請參閱 Hive 資料類型
。 Iceberg 可讓您在建立資料表之後,發展結構描述和分割區。您可以使用 Athena 查詢來更新資料表結構描述,以及更新分割區的 Spark 查詢
。
-
