本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Export (匯出)
在 Data Wrangler 流程中,您可以匯出您所做的資料處理管道部分或全部轉換。
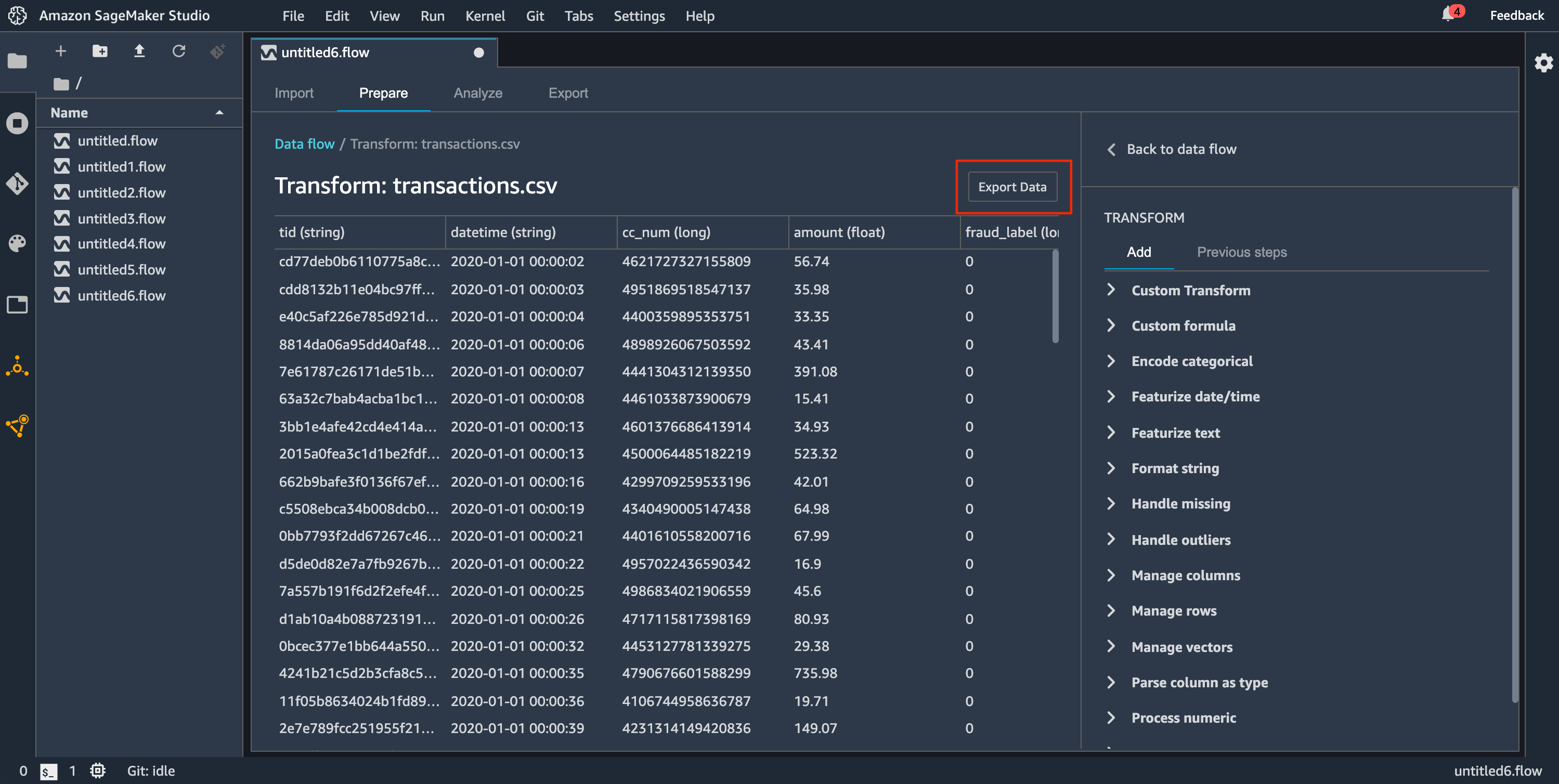
Data Wrangler 是您對資料執行的一系列資料準備步驟。在資料準備中,您可以對資料執行一次或多次轉換。每個轉換都是使用轉換步驟完成的。流程具有一系列節點,代表匯入資料以及您已執行的轉換。如需節點範例,請參閱下列影像。
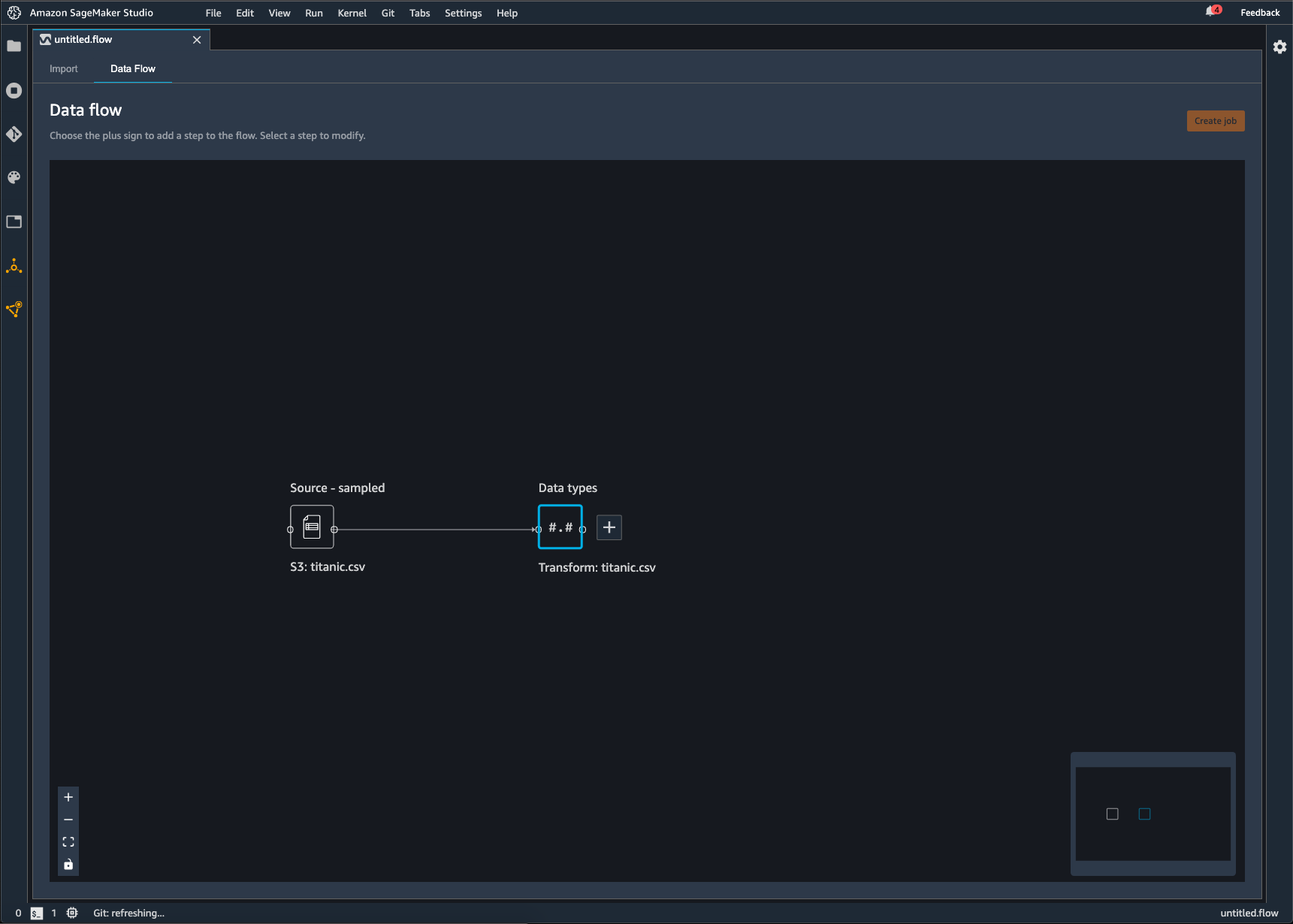
上圖顯示了具有兩個節點的 Data Wrangler 流程。來源 - 取樣節點會顯示您已從中匯入資料的資料來源。資料類型節點表示 Data Wrangler 已執行轉換,將資料集轉換成可用的格式。
您新增至 Data Wrangler 流程的每個轉換都會顯示為額外節點。關於您可以新增的轉和,請參閱轉換資料。下列影像顯示 Data Wrangler 流程,該流程具有可變更資料集中資料欄名稱的重新命名資料欄節點。
您可以將資料轉換匯出為以下功能:
-
Amazon S3
-
管道
-
Amazon SageMaker Feature Store
-
Python 程式碼
重要
我們建議您使用 IAM AmazonSageMakerFullAccess受管政策來授予使用 Data Wrangler 的 AWS 許可。如果您不使用受管政策,則可以使用 IAM 政策,讓 Data Wrangler 存取 Amazon S3 儲存貯體。如需關於政策的詳細資訊,請參閱安全與許可。
匯出資料流程時,您需要支付所使用的 AWS 資源費用。您可以使用成本分配標籤來組織和管理這些資源的成本。您可以針對使用者設定檔建立這些標籤,Data Wrangler 會自動將這些標籤套用至用於匯出資料流程的資源。如需詳細資訊,請參閱使用成本分配標籤。
匯出至 Amazon S3
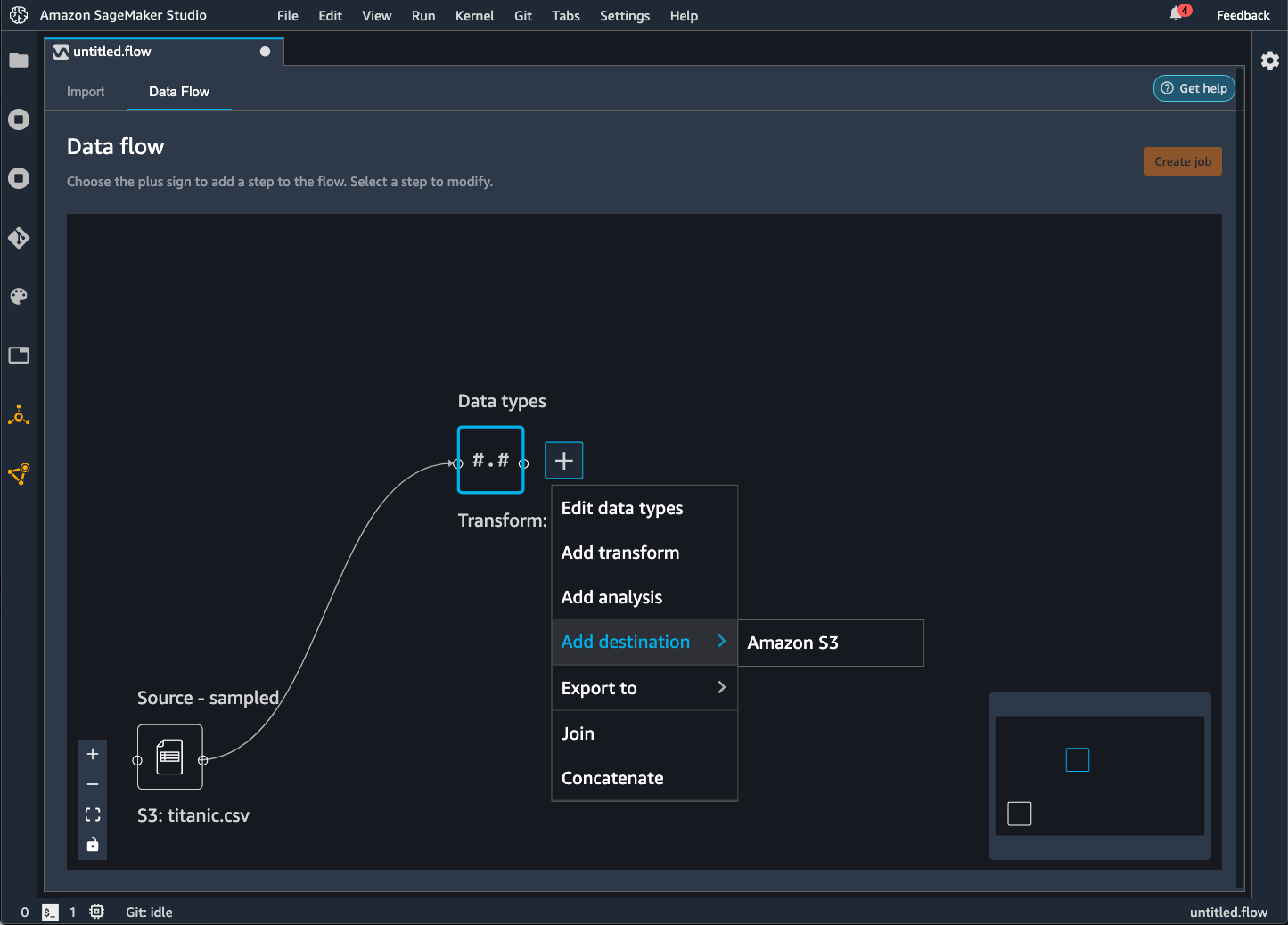
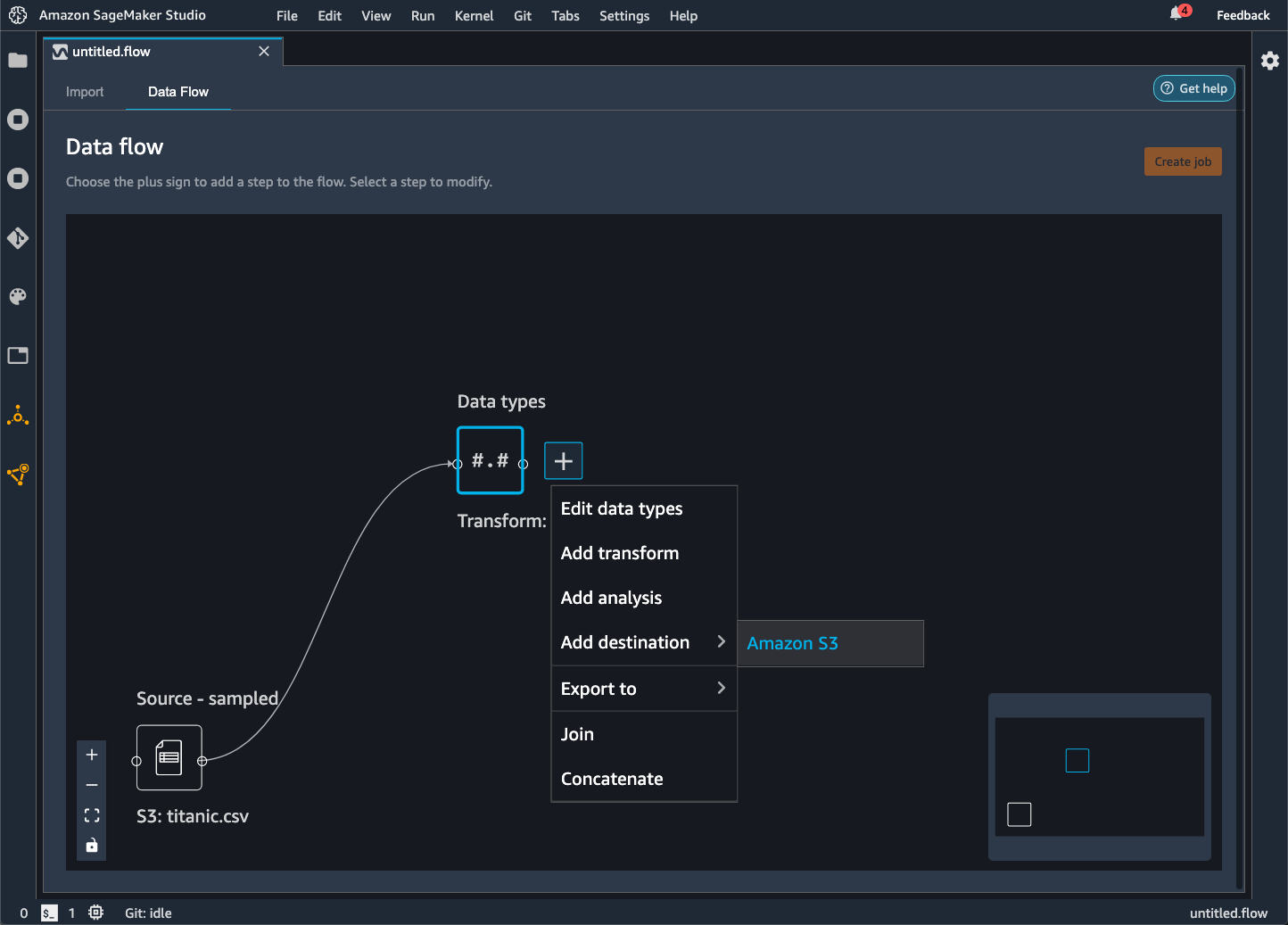
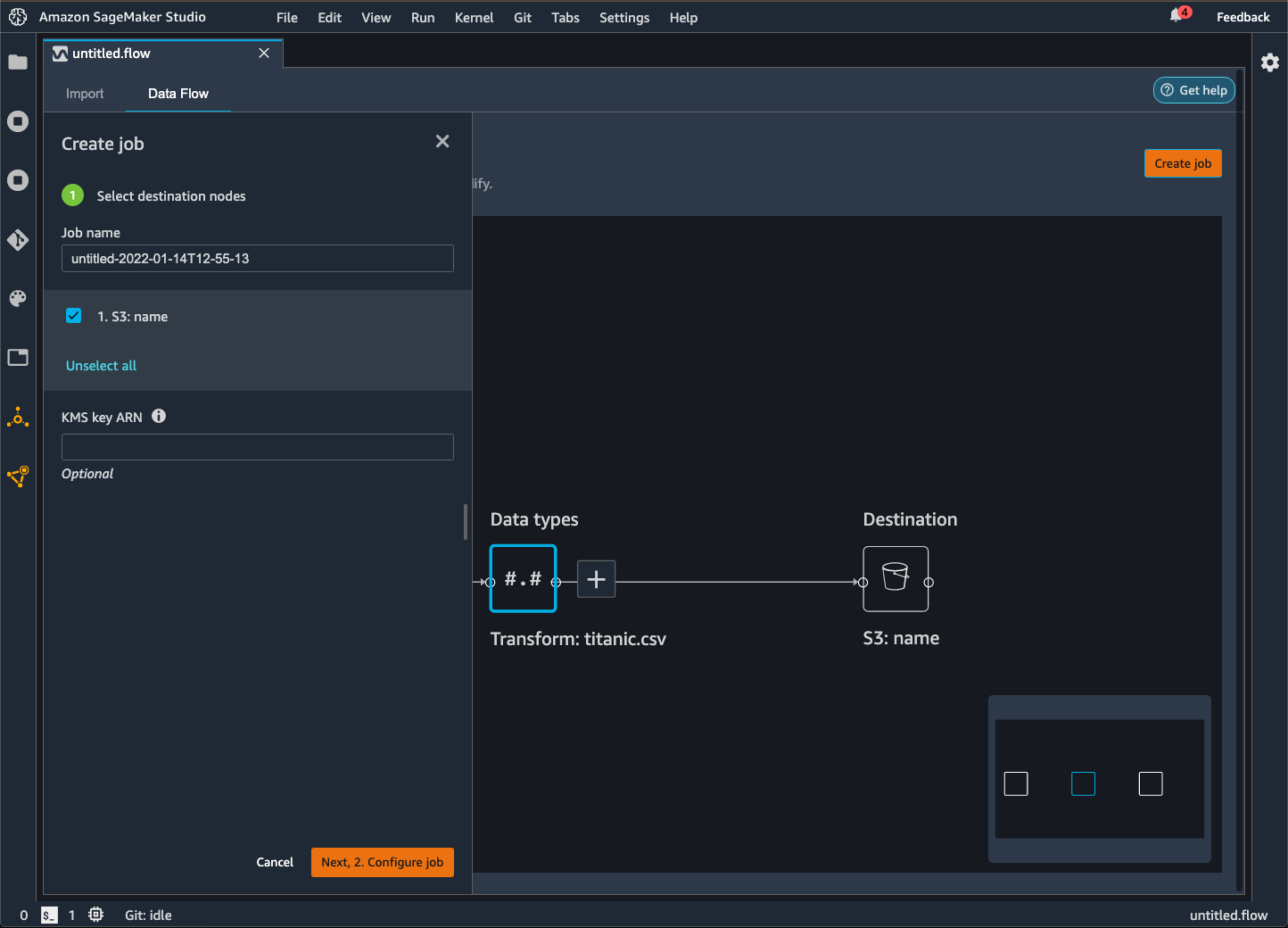
Data Wrangler 可讓您將資料匯出到 Amazon S3 儲存貯體中的某個位置。您可以使用下列其中一種方法指定位置:
-
目的地節點 — Data Wrangler 在處理資料之後儲存資料的位置。
-
匯出至 — 將轉換產生的資料匯出到 Amazon S3。
-
匯出資料 — 針對小型資料集,可以快速匯出已轉換的資料。
閱讀下列各節來進一步瞭解這些方法。


將資料流程匯出到 Amazon S3 儲存貯體時,Data Wrangler 會將流程檔案的副本儲存在 S3 儲存貯體中。它會將流程檔案儲存為包含 data_wrangler_flows 的字首。如果您使用預設的 Amazon S3 儲存貯體來存放流程檔案,則其會使用下列命名慣例:sagemaker-。例如,如果您的帳戶號碼是 111122223333,而您在 us-east-1 中使用 Studio Classic,則匯入的資料集會存放在 region-account
numbersagemaker-us-east-1-111122223333 中。在此範例中,您在 us-east-1 中建立的 .flow 檔案會儲存在 s3://sagemaker- 中。region-account
number/data_wrangler_flows/
匯出至 Pipelines
當您想要建立和部署大規模的機器學習 (ML) 工作流程時,可以使用 Pipelines 來建立能管理和部署 SageMaker AI 任務的工作流程。您可以使用 Pipelines 建立工作流程,以管理 SageMaker AI 資料準備、模型訓練和模型部署任務。您可以使用 Pipelines 來利用 SageMaker AI 提供的第一方演算法。如需 Pipelines 的詳細資訊,請參閱 SageMaker Pipelines。
當您將資料流程中的一或多個步驟匯出至 Pipelines 時,Data Wrangler 會建立 Jupyter 筆記本,您可以使用該筆記本來定義、具現化、執行和管理管道。
使用 Jupyter 筆記本建立管道
使用下列程序建立 Jupyter 筆記本,以將 Data Wrangler 流程匯出至 Pipelines。
使用下列程序產生 Jupyter 筆記本並執行,以將 Data Wrangler 流程匯出至 Pipelines。
-
選擇欲匯出的節點旁的 + 號。
-
選擇匯出至。
-
選擇 Pipelines (透過 Jupyter 筆記本)。
-
執行 Jupyter 筆記本。
您可以使用 Data Wrangler 產生的 Jupyter 筆記本來定義管道。管道包括 Data Wrangler 流程所定義的資料處理步驟。
您可以將步驟新增至筆記本中下列程式碼的 steps 清單,以將其他步驟新增至管道:
pipeline = Pipeline( name=pipeline_name, parameters=[instance_type, instance_count], steps=[step_process], #Add more steps to this list to run in your Pipeline )
如需定義管道的詳細資訊,請參閱定義 SageMaker AI Pipeline。
匯出至推論端點
透過從 Data Wrangler 流程建立 SageMaker AI 序列推論管道,使用 Data Wrangler 流程在推論時處理資料。推論管道是一系列步驟,可讓經過訓練的模型對新資料進行預測。Data Wrangler 中的序列推論管道可轉換原始資料,並將其提供給機器學習模型以進行預測。您可以從 Studio Classic 內的 Jupyter 筆記本建立、執行和管理推論管道。如需存取筆記本的詳細資訊,請參閱使用 Jupyter 筆記本建立推論端點。
在筆記本中,您可以訓練機器學習模型,也可以指定您已經訓練過的模型。您可以使用 Amazon SageMaker Autopilot 或 XGBoost 來訓練模型,使用您在 Data Wrangler 流程中轉換的資料來訓練模型。
管道具有執行批次或即時推論的功能。您也可以將 Data Wrangler 流程新增至 SageMaker Model Registry。若要取得關於託管模型的詳細資訊,請參閱多模型端點。
重要
如果 Data Wrangler 流程具有下列轉換,則無法將其匯出至推論端點:
-
Join
-
串連
-
分組依據
如果您必須使用前述轉換來準備資料,請使用下列程序。
使用不支援的轉換準備資料以進行推論
-
建立 Data Wrangler 流程。
-
套用不支援的先前轉換。
-
將資料匯出至 Amazon S3 儲存貯體。
-
建立個別 Data Wrangler 流程。
-
匯入您從先前流程匯出的資料。
-
套用剩餘的轉換。
-
使用我們提供的 Jupyter 筆記本建立序列推論管道。
如需將資料匯出至 Amazon S3 儲存貯體的詳細資訊,請參閱匯出至 Amazon S3。如需開啟用來建立序列推論管道的 Jupyter 筆記本詳細資訊,請參閱使用 Jupyter 筆記本建立推論端點。
Data Wrangler 會忽略在推論時移除資料的轉換。例如,如果您使用刪除遺失的組態,則 Data Wrangler 會忽略 處理缺少值 轉換。
如果您已將重新調整整個資料集的轉換,則轉換會繼承至您的推論管道。例如,如果您使用中位數值來推算缺少的值,則重新調整轉換的中位數值會套用至您的推論請求。您可以在使用 Jupyter 筆記本或將資料匯出至推論管道時,重新調整 Data Wrangler 流程的轉換。如需關於重新調整轉換的詳細資訊,請參閱將轉換重新調整為整個資料集並導出。
序列推論管道支援輸入和輸出字串的下列資料類型。每種資料類型都有一組請求。
支援的資料類型
-
text/csv— CSV 字串的資料類型-
字串不能有標題。
-
用於推論管道的功能必須與訓練資料集中的功能順序相同。
-
功能之間必須有逗號分隔符號。
-
記錄必須以換行字元分隔。
以下範例是您可以在推論請求中提供的有效格式 CSV 字串。
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890 -
-
application/json— JSON 字串的資料類型-
用於推論管道中的資料集功能必須與訓練資料集中的功能順序相同。
-
資料必須具有特定的結構描述。您可以將結構描述定義為具有一組
features的單一instances物件。每個features物件都代表一個觀察。
以下範例是您可以在推論請求中提供的有效格式 JSON 字串。
{ "instances": [ { "features": ["abc", 0.0, "Doe, John", 12345] }, { "features": ["def", 1.1, "Doe, Jane", 67890] } ] } -
使用 Jupyter 筆記本建立推論端點
使用下列程序匯出 Data Wrangler 流程,以建立推論管道。
若要使用 Jupyter 筆記本建立推論管道,請執行下列動作。
-
選擇欲匯出節點旁的 +。
-
選擇匯出至。
-
選擇 SageMaker AI Inference Pipeline (透過 Jupyter 筆記本)。
-
執行 Jupyter 筆記本。
當您執行 Jupyter 筆記本時,它會建立推論流程成品。推論流程成品是 Data Wrangler 流程檔案,其中包含用於建立序列推論管道的其他中繼資料。您要匯出的節點會包含先前節點的所有轉換。
重要
Data Wrangler 需要推論流程成品才能執行推論管道。您無法使用自己的流程檔案做為成品。您必須使用上述程序來建立。
匯出為 Python 程式碼
若要將資料流程中的所有步驟匯出至可手動整合至任何資料處理工作流程的 Python 檔案,請使用下列程序。
使用下列程序產生 Jupyter 筆記本並執行它,將 Data Wrangler 流程匯出為 Python 程式碼。
-
選擇欲匯出節點旁的 +。
-
選擇匯出至。
-
選擇 Python 程式碼。
-
執行 Jupyter 筆記本。
您可能需要設定 Python 指令碼,使其在您的管道中執行。例如,如果您正在執行 Spark 環境,請確定您從有權存取 AWS 資源的環境執行指令碼。
匯出至 Amazon SageMaker Feature Store
您可以使用 Data Wrangler 將您建立的功能匯出至 Amazon SageMaker Feature Store。特徵是資料集中的資料欄。特徵商店是特徵及其關聯中繼資料的集中儲存區。您可以使用特徵商店為機器學習 (ML) 開發建立、共用和管理策劃的資料。集中式儲存可以您更輕易發掘資料且可重複使用。如需有關特徵商店的詳細資訊,請參閱 Amazon SageMaker Feature Store。
特徵商店的核心概念是一個特徵群組。特徵群組是特徵、其記錄 (觀察) 和關聯中繼資料的集合。它類似於資料庫中的資料表。
您可以使用 Data Wrangler 執行以下其中一項:
-
使用新記錄更新既有特徵群組。記錄是資料集中的觀察。
-
從 Data Wrangler 流程中的節點建立新特徵群組。Data Wrangler 將資料集中的觀察加入為特徵群組中的記錄。
如果您要更新現有的特徵群組,則資料集的結構定義必須與特徵群組的結構描述相符。特徵群組中的所有記錄都會被取代為資料集中的觀察。
您可以使用 Jupyter 筆記本或目標節點,用資料集中的觀察更新您的特徵群組。
如果具有 Iceberg 表格格式的特徵群組具有自訂的離線儲存加密金鑰,則請確保授與您用於 Amazon SageMaker Processing 任務的 IAM 權限,以使用該金鑰。您至少必須授予其權限,以便加密即將寫入 Amazon S3 的資料。若要授予權限,請讓 IAM 角色能夠使用 GenerateDataKey。如需授予 IAM 角色許可以使用 AWS KMS 金鑰的詳細資訊,請參閱 https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
筆記本使用這些組態來建立特徵群組、大規模處理資料,然後將處理的資料擷取至線上和離線特徵商店。若要進一步瞭解,請參閱資料來源和擷取。
將轉換重新調整為整個資料集並導出
當您匯入資料時,Data Wrangler 會使用資料樣本來套用編碼。Data Wrangler 會根據預設使用前 50,000 個資料列做為樣本,但您可以匯入整個資料集或使用不同的取樣方法。如需詳細資訊,請參閱Import (匯入)。
下列轉換會使用您的資料在資料集中建立資料欄:
如果您使用取樣匯入資料,則前述轉換只會使用樣本中的資料來建立資料欄。轉換可能不會使用所有相關資料。例如如果您使用分類編碼轉換,則整個資料集中可能有一個類別不存在於樣本中。
您可以使用目標節點或 Jupyter 筆記本來重新調整整個資料集的轉換。當 Data Wrangler 匯出流程中的轉換時,其會建立 SageMaker Processing 任務。處理任務完成後,Data Wrangler 會將下列檔案儲存在預設 Amazon S3 位置或您指定的 S3 位置:
-
指定重新調整為資料集之轉換的 Data Wrangler 流程檔案
-
套用重新調整轉換的資料集
您可以在 Data Wrangler 中開啟 Data Wrangler 流程檔案,然後將轉換套用至不同的資料集。例如,如果您已將轉換套用至訓練資料集,則可以開啟並使用 Data Wrangler 流程檔案,將轉換套用至用於推論的資料集。
如需有關使用目標節點重新調整轉換和匯出的資訊,請參閱下列頁面:
使用下列程序來執行 Jupyter 筆記本,重新調整轉換並匯出資料。
若要執行 Jupyter 筆記本,以重新調整轉換並匯出 Data Wrangler 流程,請執行下列步驟。
-
選擇欲匯出節點旁的 +。
-
選擇匯出至。
-
選擇要匯出資料的目標位置。
-
針對
refit_trained_params物件,將refit設定為True。 -
針對
output_flow欄位,請指定有重新調整轉換的輸出流程檔案名稱。 -
執行 Jupyter 筆記本。
建立自動處理新資料的排程
如果您要定期處理資料,則可以建立排程以自動執行處理任務。例如您可以建立排程,在獲得新資料時自動執行處理任務。如需處理任務的詳細資訊,請參閱匯出至 Amazon S3和匯出至 Amazon SageMaker Feature Store。
建立任務時,必須指定具有建立該任務授權的 IAM 角色。您用來存取 Data Wrangler 的 IAM 角色根據預設為 SageMakerExecutionRole。
下列權限允許 Data Wrangler 存取 EventBridge,並允許 EventBridge 執行處理任務:
-
將下列 AWS 受管政策新增至 Amazon SageMaker Studio Classic 執行角色,該角色提供 Data Wrangler 使用 EventBridge 的許可:
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccess如需有關該政策的詳細資訊,請參閱 AWS EventBridge 受管政策。
-
將下列政策新增至您在 Data Wrangler 中建立任務時指定的 IAM 角色:
如果您使用預設的 IAM 角色,則請將上述政策新增至 Amazon SageMaker Studio Classic 執行角色。
將下列信任政策新增至角色,以便 EventBridge 加以採用。
{ "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" }
重要
當您建立排程時,Data Wrangler 會在 EventBridge 中建立一個 eventRule。您建立的事件規則和用於執行處理任務的執行個體都會產生費用。
如需 EventBridge 定價的詳細資訊,請參閱 Amazon EventBridge 定價
您可以使用以下其中一個方法建立排程:
下列各節將說明了建立任務的程序。
您可以使用 Amazon SageMaker Studio Classic 檢視排程要執行的任務。您的處理任務會在 Pipelines 內執行。每個處理任務都有自己的管道。它的運作方式為管道內的處理步驟。您可以檢視您在管道中建立的排程。如需在檢視管道更多資訊,請參閱檢視管道的詳細資訊。
使用下列程序來檢視您已排定的任務。
若要檢視您已排定的任務,請執行下列操作。
-
開啟 Amazon SageMaker Studio Classic。
-
開啟管道
-
檢視您已建立之任務管道。
執行任務的管道字首會使用任務名稱。例如,如果您已建立名為
housing-data-feature-enginnering的任務,則管道的名稱為data-wrangler-housing-data-feature-engineering。 -
選擇包含任務的管道。
-
檢視管道的狀態。狀態為成功的管道表示已成功執行處理任務。
若要停止執行處理任務,請執行下列動作:
若要停止執行處理任務,請刪除指定排程的事件規則。刪除事件規則會停止執行與該排程相關聯的所有任務。如需刪除規則的相關資訊,請參閱停用或刪除 Amazon EventBridge 規則。
您也可以停止和刪除與排程相關聯的管道。如需停止管道的相關資訊,請參閱 StopPipelineExecution。如需刪除管道的相關資訊,請參閱 DeletePipeline。
