本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
匯入
您可以使用 Amazon SageMaker Data Wrangler 從下列資料來源匯入資料:Amazon Simple Storage Service (Amazon S3)、Amazon Athena 、Amazon Redshift 和 Snowflake。您匯入的資料集最多可包含 1000 個資料欄。
主題
某些資料來源可讓您新增多個資料連線:
-
您可以連線到多個 Amazon Redshift 叢集。每個叢集都會變成資料來源。
-
您可以查詢帳戶中的任何 Athena 資料庫,以便從該資料庫匯入資料。
從資料來源匯入資料集時,資料集會顯示在資料流量中。Data Wrangler 會自動推斷資料集中每個資料欄中的資料類型。若要修改這些類型,請選取資料類型步驟並選取編輯資料類型。
當您從 Athena 或 Amazon Redshift 匯入資料時,匯入的資料會自動儲存在您使用 Studio Classic 之 AWS 區域的預設 SageMaker S3 儲存貯體中。此外,Athena 也會儲存您在此儲存貯體的 Data Wrangler 中預覽的資料。如需進一步了解,請參閱 匯入資料儲存。
重要
預設 Amazon S3 儲存貯體可能沒有最低寬鬆的安全設定,例如儲存貯體政策和伺服器端加密 (SSE)。強烈建議您新增儲存貯體政策,以限制對匯入至 Data Wrangler 資料集的存取。
重要
此外,如果您使用 的 受管政策 SageMaker,強烈建議您將其範圍縮小至可讓您執行使用案例的最嚴格政策。如需詳細資訊,請參閱授予IAM角色許可以使用 Data Wrangler。
除了 Amazon Simple Storage Service (Amazon S3) 之外,所有資料來源都需要您指定SQL查詢以匯入資料。針對每個查詣,您必須指定下列項目:
-
資料型錄
-
資料庫
-
資料表
您可以在下拉式功能表或查詢中指定資料庫或資料型錄的名稱。範例查詢如下:
-
select * from– 查詢不會使用在使用者介面 (UI) 的下拉式功能表中指定的任何項目來執行。它會在example-data-catalog-name.example-database-name.example-table-nameexample-data-catalog-name內的example-database-name中查詢example-table-name。 -
select * from– 查詢會使用您在資料型錄下拉式功能表中指定的資料型錄來執行。它會在您指定的資料型錄內的example-database-name.example-table-nameexample-database-name中查詢example-table-name。 -
select * from– 查詢要求您為資料型錄和資料庫名稱下拉式功能表選取欄位。它會在您指定的資料庫和資料型錄內的資料型錄中查詢example-table-nameexample-table-name。
Data Wrangler 和資料來源之間的連結為連線。您可以使用連線從資料來源匯入資料。
有以下類型的連線:
-
直接
-
分類
Data Wrangler 一律會以直接連線存取最近期的資料。如果資料來源中的資料已更新,您可以使用連線來匯入資料。例如,如果有人將檔案新增到您的其中一個 Amazon S3 儲存貯體,您可以匯入檔案。
分類的連線是資料傳輸的結果。分類的連線中的資料不一定具有最近的資料。例如,您可以設定 Salesforce 和 Amazon S3 之間的資料傳輸。如果 Salesforce 資料有更新,您必須再次傳輸資料。您可以自動化傳輸資料的流程。如需資料傳輸的詳細資訊,請參閱從軟體即服務 (SaaS) 平台匯入資料。
從 Amazon S3 匯入資料
您可以使用 Amazon Simple Storage Service (Amazon S3) 隨時從網路任何地方儲存和擷取任意資料量。您可以使用 來完成這些任務 AWS Management Console,這是簡單且直覺的 Web 介面,以及 Amazon S3API。如果您已將資料集儲存在本機,建議您將資料集新增至 S3 儲存貯體,以匯入至 Data Wrangler。如需指示說明,請參閱 Amazon Simple Storage Service 使用者指南中的上傳物件至儲存貯體。
Data Wrangler 使用 S3 選取
重要
如果您計劃匯出資料流程並啟動 Data Wrangler 任務、將資料擷取至 SageMaker特徵存放區或建立 SageMaker 管道,請注意這些整合需要 Amazon S3 輸入資料位於相同 AWS 區域。
重要
如果您要匯入CSV檔案,請確定檔案符合下列需求:
-
資料集中的記錄不可超過一行。
-
反斜線、
\是唯一有效的逸出字元。 -
您的資料集必須使用下列其中的一個分隔符號:
-
逗號 –
, -
冒號 –
: -
分號 –
; -
管道 –
| -
索引標籤 –
[TAB]
-
若要節省空間,您可以匯入壓縮CSV檔案。
Data Wrangler 賦予您匯入整個資料集或取樣部分資料集的能力。對於 Amazon S3,它提供了下列取樣選項:
-
無 – 匯入整個資料集。
-
前 K 列 – 取樣資料集的前 K 列,其中 K 是您指定的整數。
-
隨機化 – 取得您指定大小的隨機範例。
-
分層 – 採取分層隨機範例。分層範例可以保留資料欄中值的比例。
匯入資料之後,您還可以使用取樣轉換器以從整個資料集取得一或多個範例。如需有關取樣轉換器的詳資訊,請參閱抽樣。
您可以使用下列其中一個資源識別符來匯入資料:
-
URI 使用 Amazon S3 Amazon S3儲存貯體或 Amazon S3 存取點的 Amazon S3
-
Amazon S3 Access Points 別名
-
使用 Amazon S3 存取點或 Amazon S3 儲存貯體的 Amazon Resource Name (ARN)
Amazon S3 Access Points 被命名為連接到儲存貯體的網路端點。每個存取點都有您可以設定的不同許可和網路控制。如需有關存取點的詳細資訊,請參閱使用 Amazon S3 Access Points 來管理資料存取。
重要
如果您使用 Amazon Resource Name (ARN) 來匯入資料,則其必須針對位於您用來存取 Amazon SageMaker Studio Classic AWS 區域 相同位置的資源。
您可以將單一檔案或多個檔案匯入為資料集。如果資料集分割為個別檔案,則可以使用多檔案匯入操作。它會從 Amazon S3 目錄擷取所有檔案,並將其匯入為單一資料集。如需有關可匯入的檔案類型及匯入方式的資訊,請參閱下列各節。
您也可以使用參數匯入符合模式的檔案子集。參數可協助您更有選擇地挑選要匯入的檔案。若要開始使用參數,請編輯資料來源,並將其套用至您用來匯入資料的路徑。如需詳細資訊,請參閱重複使用不同資料集的資料流量。
從 Athena 匯入資料
使用 Amazon Athena 將資料從 Amazon Simple Storage Service (Amazon S3) 匯入 Data Wrangler。在 Athena 中,您會撰寫標準SQL查詢,以選取您要從 Amazon S3 匯入的資料。如需詳細資訊,請參閱什麼是 Amazon Athena?
您可以使用 AWS Management Console 來設定 Amazon Athena 。在您可以開始執行查詢之前,您必須在 Athena 中至少建立一個資料庫。如需有關 Athena 入門的詳細資訊,請參閱入門。
Athena 與 Data Wrangler 直接整合。您可以撰寫 Athena 查詢,而不必離開 Data Wrangler 使用者介面。
除了在 Data Wrangler 中撰寫簡單的 Athena 查詢之外,您還可以使用:
在 Data Wrangler 內查詢 Athena
注意
Data Wrangler 不支援聯合查詢。
如果您 AWS Lake Formation 搭配 Athena 使用 ,請確定 Lake Formation IAM許可不會覆寫資料庫 的IAM許可sagemaker_data_wrangler。
Data Wrangler 賦予您匯入整個資料集或取樣部分資料集的能力。對於 Athena,它提供了下列取樣選項:
-
無 – 匯入整個資料集。
-
前 K 列 – 取樣資料集的前 K 列,其中 K 是您指定的整數。
-
隨機化 – 取得您指定大小的隨機範例。
-
分層 – 採取分層隨機範例。分層範例可以保留資料欄中值的比例。
以下程序說明如何將資料集從 Athena 匯入 Data Wrangler。
從 Athena 將資料集匯入 Data Wrangler
-
登入 Amazon SageMaker 主控台
。 -
選擇 Studio。
-
選擇啟動應用程式。
-
從下拉式清單中選取 Studio。
-
選擇首頁圖示。
-
選擇資料。
-
選擇 Data Wrangler。
-
選擇匯入資料。
-
在可用之下,選擇 Amazon Athena。
-
對於資料型錄,請選擇資料型錄。
-
使用資料庫下拉式清單來選取您要查詢的資料庫。當您選取資料庫時,您可以使用詳細資訊下列出的資料表來預覽資料庫中的所有資料表。
-
(選用) 選擇進階組態。
-
選擇工作群組。
-
如果您的工作群組尚未強制執行 Amazon S3 輸出位置,或者您不使用工作群組,請指定查詢結果的 Amazon S3 位置值。
-
(選用) 對於資料保留期,請選取核取方塊以設定資料保留期間,並指定資料刪除前的儲存天數。
-
(選用) 根據預設,Data Wrangler 會儲存連線。您可以選擇取消選取核取方塊,而不儲存連線。
-
-
對於取樣,請選擇一種取樣方法。選擇無以關閉取樣。
-
在查詢編輯器中輸入查詢,然後使用執行按鈕執行查詢。成功查詢後,您可以在編輯器下預覽結果。
注意
Salesforce 資料使用
timestamptz類型。如果您要查詢從 Salesforce 匯入至 Athena 的時間戳記欄,請將資料欄中的資料轉換為timestamp類型。下列查詢會將時間戳記欄轉換為正確的類型。# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
若要匯入查詢結果,請選取匯入。
完成上述程序之後,您查詢並匯入的資料集就會出現在 Data Wrangler 流程中。
根據預設, Data Wrangler 會將連線設定儲存為新的連線。匯入資料時,您已指定的查詢會顯示為新連線。儲存的連線會儲存您正在使用的 Athena 工作群組和 Amazon S3 儲存貯體的相關資訊。當您再次連線至資料來源時,您可以選擇已儲存的連線。
管理查詢結果
Data Wrangler 支援使用 Athena 工作群組來管理 AWS 帳戶內的查詢結果。您可以為每個工作群組指定 Amazon S3 輸出位置。您也可以指定查詢的輸出是否可以移至不同的 Amazon S3 位置。如需詳細資訊,請參閱使用工作群組來控制查詢存取和成本。
您的工作群組可能已設定為強制執行 Amazon S3 查詢輸出位置。您無法變更這些工作群組查詢結果的輸出位置。
如果您不使用工作群組或為查詢指定輸出位置,Data Wrangler 會在 Studio Classic 執行個體所在的相同 AWS 區域中使用預設 Amazon S3 儲存貯體來儲存 Athena 查詢結果。它會在此資料庫中建立暫時資料表,以將查詢輸出移至此 Amazon S3 儲存貯體。它會在資料匯入後刪除這些資料表;但是資料庫 sagemaker_data_wrangler仍會存在。如需進一步了解,請參閱 匯入資料儲存。
若要使用 Athena 工作群組,請設定允許存取工作群組IAM的政策。如果您使用的是 SageMaker-Execution-Role,建議將政策新增至角色。如需工作群組IAM政策的詳細資訊,請參閱IAM存取工作群組的政策。如需工作群組政策範例,請參閱工作群組範例政策。
設定資料保留期
Data Wrangler 會自動設定查詢結果的資料保留期。結果會在保留期過後刪除。例如,預設的保留期為五天。查詢結果會在五天後刪除。此設定是為了協助您清除不再使用的資料而設計。清除您的資料可防止未經授權的使用者取得存取權。還有助於控制在 Amazon S3 上儲存資料的成本。
如果您未設定保留期,Amazon S3 生命週期組態會決定物件的儲存持續時間。您為生命週期組態指定的資料保留政策會移除任何早於您指定的生命週期組態的查詢結果。如需詳細資訊,請參閱在儲存貯體上設定生命週期組態。
Data Wrangler 使用 Amazon S3 生命週期組態來管理資料保留和到期。您必須授予 Amazon SageMaker Studio Classic IAM執行角色許可,才能管理儲存貯體生命週期組態。使用下列程序以授予許可權。
要授予許可權給管理生命週期組態,請執行以下操作。
-
登入 AWS Management Console 並在 開啟IAM主控台https://console.aws.amazon.com/iam/
。 -
選擇角色。
-
在搜尋列中,指定 Amazon SageMaker Studio Classic 正在使用的 Amazon SageMaker 執行角色。
-
選擇角色。
-
選擇新增許可。
-
選擇建立內嵌政策。
-
對於服務,請指定 S3 並選擇它。
-
在讀取區段下,選擇 GetLifecycleConfiguration。
-
在寫入區段下,選擇 PutLifecycleConfiguration。
-
針對資源,請選擇特定。
-
針對動作,選取許可管理旁邊的箭頭圖示。
-
選擇 PutResourcePolicy。
-
針對資源,請選擇特定。
-
選擇此帳戶中任何旁邊的核取方塊。
-
選擇檢閱政策。
-
針對名稱,請指定一個名稱。
-
選擇 建立政策。
從 Amazon Redshift 匯入資料。
Amazon Redshift 是一種在雲端中完全受管的 PB 級資料倉儲服務。建立資料倉儲服務的第一個步驟是啟動一組節點,稱為 Amazon Redshift 叢集。佈建您的叢集之後,您可以上傳您的資料集,然後執行資料分析查詢。
您可以在 Data Wrangler 中連線到並查詢一或多個 Amazon Redshift 叢集。若要使用此匯入選項,您必須在 Amazon Redshift 中建立至少一個叢集。要了解如何操作,請參閱開始使用 Amazon Redshift。
您可以在下列其中一個位置輸出 Amazon Redshift 查詢的結果:
-
預設 Amazon S3 儲存貯體
-
您指定的 Amazon S3 輸出位置
您可以匯入整個資料集,也可以對其中的一部分進行抽樣。對於 Amazon Redshift,它提供了下列取樣選項:
-
無 – 匯入整個資料集。
-
前 K 列 – 取樣資料集的前 K 列,其中 K 是您指定的整數。
-
隨機化 – 取得您指定大小的隨機範例。
-
分層 – 採取分層隨機範例。分層範例可以保留資料欄中值的比例。
預設 Amazon S3 儲存貯體位於 Studio Classic 執行個體存放 Amazon Redshift 查詢結果所在的相同 AWS 區域。如需詳細資訊,請參閱匯入資料儲存。
對於預設 Amazon S3 儲存貯體或您指定的儲存貯體,您可以使用下列加密選項:
-
使用 Amazon S3 受管金鑰 (SSE-S3) 的預設 AWS 服務端加密
-
您指定的 AWS Key Management Service (AWS KMS) 金鑰
AWS KMS 金鑰是您建立和管理的加密金鑰。如需KMS金鑰的詳細資訊,請參閱 AWS Key Management Service。
您可以使用 AWS KMS 金鑰ARN或 AWS 帳戶的 ARN來指定金鑰。
如果您使用 IAM 受管政策 AmazonSageMakerFullAccess來授予角色許可,以在 Studio Classic 中使用 Data Wrangler,您的資料庫使用者名稱必須具有字首 sagemaker_access。
使用下列程序以了解如何新增新叢集。
注意
Data Wrangler 使用 Amazon Redshift Data API搭配臨時憑證。若要進一步了解此 API,請參閱 Amazon Redshift 管理指南中的使用 Amazon Redshift 資料API。
若要連線至 Amazon Redshift 叢集
-
登入 Amazon SageMaker 主控台
。 -
選擇 Studio。
-
選擇啟動應用程式。
-
從下拉式清單中選取 Studio。
-
選擇首頁圖示。
-
選擇資料。
-
選擇 Data Wrangler。
-
選擇匯入資料。
-
在可用之下,選擇 Amazon Athena。
-
選擇 Amazon RedShift。
-
針對類型 選擇暫時憑證 (IAM)。
-
輸入連線名稱。這是 Data Wrangler 用來識別此連線的名稱。
-
輸入叢集識別符以指定要連線的叢集。注意:只能輸入叢集識別符,而不要輸入 Amazon Redshift 叢集的完整端點。
-
將資料集的資料庫名稱輸入到您想要連線的位置。
-
輸入資料庫使用者以識別要用來連線資料庫的使用者。
-
針對UNLOADIAM角色 ,輸入 Amazon Redshift 叢集應擔任ARN的角色IAM,以將資料移動和寫入 Amazon S3。如需此角色的詳細資訊,請參閱 Amazon Redshift 管理指南中的授權 Amazon Redshift AWS 代表您存取其他服務。
-
選擇連線。
-
(選用) 針對 Amazon S3 輸出位置 ,指定 S3 URI以存放查詢結果。
-
(選用) 針對KMS金鑰 ID ,指定金鑰或別名ARN的 AWS KMS 。下列影像顯示您可以在 AWS Management Console中找到任一金鑰的位置。
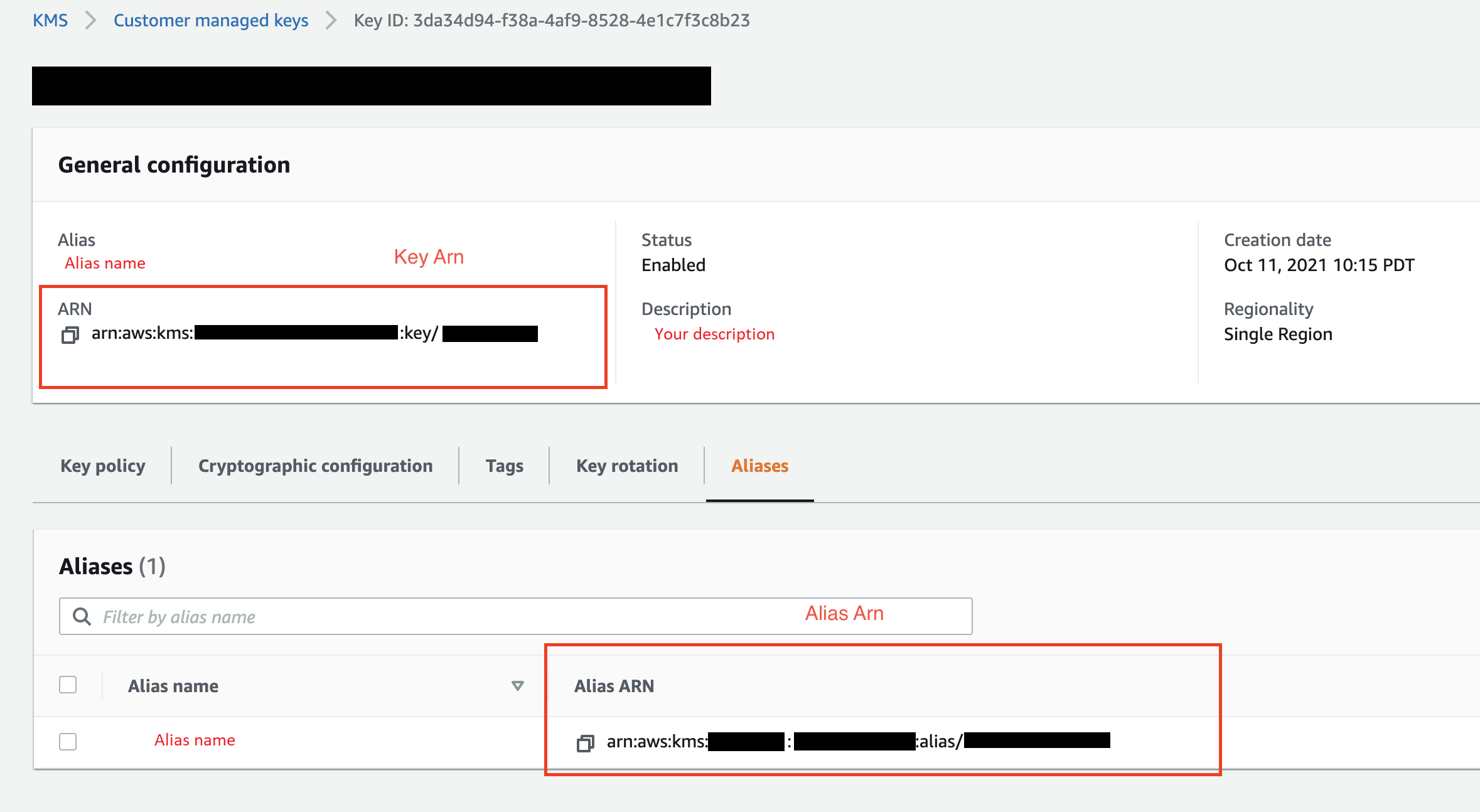
下列影像顯示前述程序的所有欄位。
成功建立連線後,它會在資料匯入下顯示為資料來源。選取此資料來源以查詢資料庫並匯入資料。
若要從 Amazon Redshift 查詢和匯入資料。
-
選取您要從資料來源查詢的連線。
-
選取結構描述。若要進一步了解 Amazon Redshift 結構描述,請參閱 Amazon Redshift 資料庫開發人員指南中的結構描述。
-
(選用) 在進階組態下,指定您要使用的取樣方法。
-
在查詢編輯器中輸入您的查詢,然後選擇執行以執行查詢。成功查詢後,您可以在編輯器下預覽結果。
-
選取匯入資料集以匯入已查詢的資料集。
-
輸入資料集名稱。如果您要新增包含空格的資料集名稱,則在匯入資料集時,這些空格會用底線取代。
-
選擇新增。
若要編輯資料集,請執行以下操作。
-
導覽至您的 Data Wrangler 流程。
-
選擇來源 - 取樣旁邊的 +。
-
變更您匯入的資料。
-
選擇套用
從 Amazon 匯入資料 EMR
您可以使用 Amazon EMR 作為 Amazon SageMaker Data Wrangler 流程的資料來源。Amazon EMR 是受管叢集平台,您可以使用 程序和分析大量資料。如需 Amazon 的詳細資訊EMR,請參閱什麼是 Amazon EMR? 若要從 匯入資料集EMR,您可以連線至資料集並加以查詢。
重要
您必須符合下列先決條件才能連線至 Amazon EMR叢集:
必要條件
-
網路組態
-
您在用來啟動 Amazon SageMaker Studio Classic 和 Amazon VPC的區域中有 AmazonEMR。
-
Amazon EMR和 Amazon SageMaker Studio Classic 都必須在私有子網路中啟動。它們可以位於相同或不同的子網路中。
-
Amazon SageMaker Studio Classic 必須處於VPC僅限 的模式。
如需建立 的詳細資訊VPC,請參閱建立 VPC。
如需建立 的詳細資訊VPC,請參閱 中的將 SageMaker Studio Classic Notebooks VPC 連接至外部資源 。
-
您正在執行的 Amazon EMR叢集必須位於相同的 Amazon 中VPC。
-
Amazon EMR叢集和 Amazon VPC 必須位於相同的 AWS 帳戶中。
-
您的 Amazon EMR叢集正在執行 Hive 或 Presto。
-
Hive 叢集必須允許來自連接埠 10000 上 Studio Classic 安全群組的傳入流量。
-
Presto 叢集必須允許來自連接埠 8889 上 Studio Classic 安全群組的傳入流量。
注意
使用 IAM角色的 Amazon EMR叢集的連接埠號碼不同。如需詳細資訊,請導覽至先決條件區段的結尾。
-
-
-
SageMaker Studio Classic
-
Amazon SageMaker Studio Classic 必須執行 Jupyter Lab 第 3 版。如需更新 Jupyter Lab 版本的相關資訊,請參閱從主控台檢視和更新應用程式的 JupyterLab 版本。
-
Amazon SageMaker Studio Classic 具有控制使用者存取IAM的角色。您用來執行 Amazon SageMaker Studio Classic 的預設IAM角色沒有可讓您存取 Amazon EMR叢集的政策。您必須將授予許可的政策附加至IAM角色。如需詳細資訊,請參閱設定列出 Amazon EMR叢集。
-
此IAM角色也必須附加下列政策
secretsmanager:PutResourcePolicy。 -
如果您使用的是已建立的 Studio Classic 網域,請確定其
AppNetworkAccessType處於 VPC僅 模式。如需更新網域以使用 VPC-only 模式的相關資訊,請參閱 關閉並更新 SageMaker Studio Classic。
-
-
Amazon EMR叢集
-
您必須在叢集上安裝 Hive 或 Presto。
-
Amazon EMR版本必須是 5.5.0 版或更新版本。
注意
Amazon EMR支援自動終止。自動終止會阻止閒置的叢集執行,並阻止您產生成本。以下是支援自動終止的版本:
-
對於 6.x 版本,則為 6.1.0 或更新版本。
-
對於 5.x 版本,則為 5.30.0 或更新版本。
-
-
-
使用IAM執行期角色的 Amazon EMR叢集
-
使用下列頁面來設定 Amazon EMR叢集的IAM執行期角色。當您使用執行期角色時,您必須啟用傳輸中加密:
-
您必須將 Lake Formation 作為資料庫中資料的控管工具。您也必須使用外部資料篩選來進行存取控制。
-
如需 Lake Formation 的詳細資訊,請參閱什麼是 AWS Lake Formation?
-
如需將 Lake Formation 整合到 Amazon 的詳細資訊EMR,請參閱將第三方服務與 Lake Formation 整合。
-
-
您叢集的版本必須為 6.9.0 或更新版本。
-
存取 AWS Secrets Manager。如需有關 Secrets Manager 的詳細資訊,請參閱 AWS Secrets Manager是什麼?
-
Hive 叢集必須允許來自連接埠 10000 上 Studio Classic 安全群組的傳入流量。
-
Amazon VPC是邏輯上與 AWS 雲端上的其他網路隔離的虛擬網路。Amazon SageMaker Studio Classic 和您的 Amazon EMR叢集僅存在於 Amazon 內VPC。
使用下列程序在 Amazon 中啟動 Amazon SageMaker Studio ClassicVPC。
若要在 中啟動 Studio ClassicVPC,請執行下列動作。
-
在 導覽至 SageMaker 主控台https://console.aws.amazon.com/sagemaker/
。 -
選擇啟動 SageMaker Studio Classic 。
-
選擇標準設定。
-
對於預設執行角色 ,選擇要設定 Studio Classic IAM的角色。
-
選擇VPC您已啟動 Amazon EMR叢集的 。
-
針對子網路,請選擇私有子網路。
-
針對安全群組 (Security group),指定您用來控制 之間的安全群組VPC。
-
VPC 僅選擇 。
-
(選用) AWS 使用預設加密金鑰。您可以指定加密資料的 AWS Key Management Service 金鑰。
-
選擇下一步。
-
在 Studio 設定下,選擇最適合您的組態。
-
選擇下一步略過 SageMaker Canvas 設定。
-
選擇下一步略過RStudio設定。
如果您沒有準備好 Amazon EMR叢集,您可以使用下列程序來建立叢集。如需 Amazon 的詳細資訊EMR,請參閱什麼是 Amazon EMR?
若要建立叢集,請執行以下操作。
-
導覽至 AWS Management Console。
-
在搜尋列中,指定
Amazon EMR。 -
選擇建立叢集。
-
針對 叢集名稱,請指定您叢集的名稱。
-
對於發行,請選取叢集的發行版本。
注意
Amazon EMR支援下列版本的自動終止:
-
對於 6.x 發行版本,為 6.1.0 或更新版本。
-
對於 5.x 發行版本,為 5.30.0 或更新版本。
自動終止會阻止閒置的叢集執行,並阻止您產生成本。
-
-
(選用) 對於應用程式,請選擇 Presto。
-
選擇您在叢集上執行的應用程式。
-
在網路下,對硬體組態指定硬體組態設定。
重要
針對網路 ,選擇執行 Amazon SageMaker Studio Classic VPC的 ,然後選擇私有子網路。
-
在安全和存取下,指定安全設定。
-
選擇 Create (建立)。
如需建立 Amazon EMR叢集的教學課程,請參閱 Amazon 入門EMR。如需設定叢集的最佳實務的相關資訊,請參閱考量事項和最佳實務。
注意
為了安全最佳實務,Data Wrangler 只能在私有子網路VPCs上連線至 。除非您將 AWS Systems Manager 用於 Amazon EMR執行個體,否則無法連線至主節點。如需詳細資訊,請參閱使用 保護EMR對叢集的存取 AWS Systems Manager
您目前可以使用下列方法來存取 Amazon EMR叢集:
-
無身分驗證
-
輕量型目錄存取通訊協定 (LDAP)
-
IAM (執行期角色)
不使用身分驗證或使用 LDAP 可能需要您建立多個叢集和 Amazon EC2執行個體設定檔。如果您是系統管理員,您可能需要為使用者群組提供不同層級的資料存取權限。這些方法可能會導致額外的管理負擔,使管理使用者變得更加困難。
我們建議使用IAM執行期角色,讓多個使用者能夠連線到相同的 Amazon EMR叢集。執行期角色是您可以指派給連線至 Amazon EMR叢集之使用者IAM的角色。您可以設定執行期IAM角色,以取得每個使用者群組特有的許可。
使用下列區段建立LDAP已啟用 的 Presto 或 Hive Amazon EMR叢集。
使用下列各節,針對您已建立的 Amazon EMR叢集使用LDAP身分驗證。
使用以下程序以從叢集匯入資料。
若要從叢集匯入資料,請執行以下操作。
-
開啟 Data Wrangler 流程。
-
選擇建立連線。
-
選擇 Amazon EMR。
-
執行下列其中一項操作。
-
(選用) 針對秘密 ARN,指定叢集內資料庫的 Amazon Resource Number (ARN)。機密能提供額外的安全性。如需秘密的詳細資訊,請參閱什麼是 AWS Secrets Manager? 如需有關為您的叢集建立資料機密的詳細資訊,請參閱為您的叢集建立 AWS Secrets Manager 秘密。
重要
如果您使用IAM執行階段角色進行身分驗證,則必須指定秘密。
-
從下拉式資料表中選擇一個叢集。
-
-
選擇 Next (下一步)。
-
對於選取 的端點
example-cluster-name叢集 ,選擇查詢引擎。 -
(選用) 選取儲存連線。
-
選擇下一步,選擇登入,然後選擇以下其中一個規則:
-
無身分驗證
-
LDAP
-
IAM
-
-
登入
example-cluster-name叢集 ,指定叢集的使用者名稱和密碼。 -
選擇連線。
-
在查詢編輯器中指定SQL查詢。
-
選擇執行。
-
選擇匯入。
為您的叢集建立 AWS Secrets Manager 秘密
如果您使用IAM執行期角色來存取 Amazon EMR叢集,則必須儲存您用來存取 Amazon 的憑證EMR,做為 Secrets Manager 秘密。您可以儲存用來存取機密內叢集的所有憑證。
您必須在機密中儲存下列資訊:
-
JDBC 端點 –
jdbc:hive2:// -
DNS name – Amazon EMR叢集DNS的名稱。它是主要節點的端點或主機名稱。
-
連接埠 –
8446
您也可以在機密中儲存下列其他資訊:
-
IAM 角色 – 您用來存取叢集IAM的角色。Data Wrangler 預設會使用 SageMaker 執行角色。
-
信任庫路徑 – 根據預設,Data Wrangler 會為您建立一個信任庫路徑。您也可以使用您自己的信任庫路徑。如需信任存放區路徑的詳細資訊,請參閱 HiveServer2 中的傳輸中加密。
-
信任庫密碼 – 根據預設,Data Wrangler 會為您建立一個信任庫密碼。您也可以使用您自己的信任庫路徑。如需信任存放區路徑的詳細資訊,請參閱 HiveServer2 中的傳輸中加密。
使用下列程序將憑證儲存在 Secrets Manager 機密中。
要將憑證儲存為機密,請執行以下操作。
-
導覽至 AWS Management Console。
-
在搜尋列中,指定 Secrets Manager。
-
選擇 AWS Secrets Manager。
-
選擇存放新的機密。
-
針對機密類型,選擇其他類型的機密。
-
在鍵/值對下,選取純文字。
-
對於執行 Hive 的叢集,您可以使用下列範本進行IAM身分驗證。
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}注意
匯入資料之後,您可以將轉換套用至這些資料上。然後,您可以將已轉換的資料匯出到特定位置。如果您使用 Jupyter 筆記本將轉換後的資料匯出到 Amazon S3,則必須使用上述範例中指定的信任庫路徑。
Secrets Manager 秘密會將 Amazon EMR叢集JDBCURL的 儲存為秘密。使用機密比直接輸入憑證更安全。
使用下列程序將 儲存JDBCURL為秘密。
若要將 儲存JDBCURL為秘密,請執行下列動作。
-
導覽至 AWS Management Console。
-
在搜尋列中,指定 Secrets Manager。
-
選擇 AWS Secrets Manager。
-
選擇存放新的機密。
-
針對機密類型,選擇其他類型的機密。
-
針對金鑰/值對 ,指定
jdbcURL為金鑰,而有效 JDBCURL為值。有效格式JDBCURL取決於您是否使用身分驗證,以及您是否使用 Hive 或 Presto 作為查詢引擎。下列清單顯示不同可能組態的有效JBDCURL格式。
-
Hive,無身分驗證 –
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive、LDAP身分驗證 –
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
對於SSL啟用 的 Hive,JDBCURL格式取決於您是否使用 Java Keystore 檔案進行TLS組態。Java Keystore 檔案有助於驗證 Amazon EMR叢集主節點的身分。若要使用 Java Keystore 檔案,請在EMR叢集上產生該檔案,並將其上傳至 Data Wrangler。若要產生檔案,請在 Amazon EMR叢集 上使用下列命令
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks。如需在 Amazon EMR叢集上執行命令的相關資訊,請參閱使用 保護對EMR叢集的存取 AWS Systems Manager。若要上傳檔案,請選擇 Data Wrangler 使用者介面左側導覽列上的向上箭頭。 以下是SSL啟用 Hive 的有效JDBCURL格式:
-
沒有 Java Keystore File –
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
有 Java Keystore File –
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Presto,無身分驗證 – jdbc:presto://
emr-cluster-master-public-dns:8889/; -
對於具有LDAP身分驗證並SSL啟用的 Presto,JDBCURL格式取決於您是否使用 Java Keystore 檔案進行TLS組態。Java Keystore 檔案有助於驗證 Amazon EMR叢集主節點的身分。若要使用 Java Keystore 檔案,請在EMR叢集上產生該檔案,並將其上傳至 Data Wrangler。若要上傳檔案,請選擇 Data Wrangler 使用者介面左側導覽列上的向上箭頭。如需為 Presto 建立 Java Keystore 檔案的相關資訊,請參閱適用於 的 Java Keystore 檔案TLS
。如需在 Amazon EMR叢集上執行命令的相關資訊,請參閱使用 保護對EMR叢集的存取 AWS Systems Manager 。 -
沒有 Java Keystore File –
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
有 Java Keystore File –
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
從 Amazon EMR叢集匯入資料的整個過程中,您可能會遇到問題。如需有關上述問題的疑難排資訊,請參閱對 Amazon 的問題進行故障診斷 EMR。
從 Databricks 匯入資料 (JDBC)
您可以使用 Databricks 作為 Amazon SageMaker Data Wrangler 流程的資料來源。若要從 Databricks 匯入資料集,請使用 JDBC(Java Database Connectivity) 匯入功能來存取 Databricks 資料庫。存取資料庫後,請指定SQL查詢以取得資料並匯入。
我們假設您有一個執行中的 Databricks 叢集,並且已將JDBC驅動程式設定為該叢集。如需詳細資訊,請參閱下列 Databricks 文件頁:
Data Wrangler 會將您的 存放在 JDBCURL中 AWS Secrets Manager。您必須授予 Amazon SageMaker Studio Classic IAM執行角色許可才能使用 Secrets Manager。使用下列程序以授予許可權。
若要授與 Secrets Manager 許可權,請執行以下操作。
-
登入 AWS Management Console 並在 開啟IAM主控台https://console.aws.amazon.com/iam/
。 -
選擇角色。
-
在搜尋列中,指定 Amazon SageMaker Studio Classic 正在使用的 Amazon SageMaker 執行角色。
-
選擇角色。
-
選擇新增許可。
-
選擇建立內嵌政策。
-
對於服務,請指定 Secrets Manager 並選擇它。
-
針對動作,選取許可管理旁邊的箭頭圖示。
-
選擇 PutResourcePolicy。
-
針對資源,請選擇特定。
-
選擇此帳戶中任何旁邊的核取方塊。
-
選擇檢閱政策。
-
針對名稱,請指定一個名稱。
-
選擇 建立政策。
您可以使用分割區更快速地匯入資料。分割區讓 Data Wrangler 能夠平行處理資料。根據預設,Data Wrangler 會使用 2 個分割區。對於大多數的使用案例,2 個分割區可為您提供近乎最佳的資料處理速度。
如果您選擇指定 2 個以上的分割區,您也可以指定一個資料欄來分割資料。資料欄中值的類型必須是數字或日期。
我們建議您只在瞭解資料結構及其處理方式時,才使用分割區。
您可以匯入整個資料集,也可以對其中的一部分進行抽樣。對於 Databricks 資料庫,它提供了下列取樣選項:
-
無 – 匯入整個資料集。
-
前 K 列 – 取樣資料集的前 K 列,其中 K 是您指定的整數。
-
隨機化 – 取得您指定大小的隨機範例。
-
分層 – 採取分層隨機範例。分層範例可以保留資料欄中值的比例。
使用下列程序從 Databricks 資料庫匯入資料。
若要從 Databricks 匯入資料,請執行以下操作。
-
登入 Amazon SageMaker 主控台
。 -
選擇 Studio。
-
選擇啟動應用程式。
-
從下拉式清單中選取 Studio。
-
從 Data Wrangler 流程的匯入資料索引標籤,選擇 Databricks。
-
指定下列欄位:
-
資料集名稱 – 您想要在 Data Wrangler 流程中使用的資料集名稱。
-
驅動程式 – com.simba.spark.jdbc.Driver。
-
JDBC URL – Databricks 資料庫URL的 。Databricks 執行個體之間的URL格式可能會有所不同。如需尋找 URL及其內指定參數的資訊,請參閱JDBC組態和連線參數
。以下是URL如何格式化 的範例:jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID= token;PWD=personal-access-token.注意
您可以指定包含 ARN的秘密,JDBCURL而不是指定JDBCURL本身。機密必須包含具有下列格式的鍵值組:
jdbcURL:。如需詳細資訊,請參閱什麼是 Secrets Manager?。JDBC-URL
-
-
指定SQLSELECT陳述式。
注意
Data Wrangler 不支援查詢內的 Common Table Expressions (CTE) 或暫存資料表。
-
對於取樣,請選擇一種取樣方法。
-
選擇執行。
-
(選用) 針對 PREVIEW,選擇齒輪以開啟分割區設定 。
-
指定分割區數。如果您指定分割區數目,則可以按欄進行分割:
-
輸入分割區數目 – 指定大於 2 的值。
-
(選用) 依欄分割 – 指定下列欄位。如果您已指定輸入分割區數目的值,才能依欄進行分割。
-
選取欄 – 選取要用於資料分割區的欄。資料欄的資料類型必須是數字或日期。
-
上限 – 對於您指定資料欄中的值,上限是您在分區中使用的值。您指定的值不會變更您要匯入的資料。它只會影響匯入的速度。為了獲得最佳效能,請指定接近資料欄最大值的上限。
-
下限 – 對於您指定資料欄中的值,下限是您在分區中使用的值。您指定的值不會變更您要匯入的資料。它只會影響匯入的速度。為了獲得最佳效能,請指定接近資料欄最小值的下限。
-
-
-
-
選擇匯入。
從 Salesforce 資料雲端匯入資料。
您可以使用 Salesforce Data Cloud 作為 Amazon SageMaker Data Wrangler 中的資料來源,以準備 Salesforce Data Cloud 中的資料進行機器學習。
使用 Salesforce 資料雲端做為 Data Wrangler 中的資料來源,讓您可以快速連線到 Salesforce 資料,而無需撰寫任何一行程式碼。您可以將 Salesforce 資料與 Data Wrangler 中任何其他資料來源的資料聯結。
連線到資料雲端後,您可以執行以下操作:
-
使用內建視覺效果視覺化您的資料
-
了解資料並識別潛在錯誤和極端價值
-
透過 300 多種內建轉換來轉換資料
-
匯出已轉換的資料
管理員設定
重要
開始之前,請確定您的使用者執行的是 Amazon SageMaker Studio Classic 1.3.0 版或更新版本。如需有關檢查 Studio Classic 版本並更新版本的資訊,請參閱 使用 Amazon Data Wrangler 準備 ML SageMaker 資料。
當您設定 Salesforce 資料雲端的存取權時,必須完成以下工作:
-
取得 Salesforce 網域 URL。Salesforce 也將網域URL稱為組織的 URL。
-
從 Salesforce 取得OAuth憑證。
-
取得 Salesforce 網域URL的授權URL和權杖。
-
使用 OAuth 組態建立 AWS Secrets Manager 秘密。
-
建立生命週期組態,讓 Data Wrangler 讀取機密的憑證。
-
授予 Data Wrangler 讀取機密的許可權。
在您執行上述任務之後,您的使用者可以使用 登入 Salesforce Data CloudOAuth。
注意
設定完所有項目後,使用者可能會遇到問題。如需有關疑難排解的資訊,請參閱Salesforce 的 故障診斷。
使用下列程序取得網域 URL。
-
導覽至 Salesforce 登入頁面。
-
對於快速尋找,請指定我的網域。
-
將目前我的網域URL的值複製到文字檔案。
-
https://新增至 的開頭URL。
取得 Salesforce 網域 後URL,您可以使用下列程序從 Salesforce 取得登入憑證,並允許 Data Wrangler 存取您的 Salesforce 資料。
若要從 Salesforce 取得登入憑證,並提供 Data Wrangler 的存取權,請執行以下操作。
-
導覽至 Salesforce 網域URL並登入您的帳戶。
-
選擇齒輪圖示。
-
在出現的搜尋列中,指定應用程式管理員。
-
選取新增連線的應用程式。
-
指定下列欄位:
-
已連線的應用程式名稱 – 您可以指定任何名稱,但我們建議您選擇包含 Data Wrangler 的名稱。例如,您可以指定 Salesforce 資料雲端 Data Wrangler 整合。
-
API name – 使用預設值。
-
聯絡人電子郵件 – 指定您的電子郵件地址。
-
在API標題 (啟用OAuth設定) 下,選取核取方塊以啟用OAuth設定。
-
對於回撥URL,請指定 Amazon SageMaker Studio Classic URL。若要取得適用於 Studio Classic URL 的 ,請從 存取它 AWS Management Console 並複製 URL。
-
-
在選取的OAuth範圍 下,將下列項目從可用OAuth範圍移至選取的OAuth範圍 :
-
透過 APIs(
api) 管理使用者資料 -
隨時執行要求 (
refresh_token、offline_access) -
在 Salesforce Data Cloud 資料 (
cdp_query_api) 上執行ANSISQL查詢 -
管理 Salesforce 客戶資料平台設定檔資料 (
cdp_profile_api)
-
-
選擇儲存。儲存變更後,Salesforce 會開啟新頁面。
-
選擇繼續
-
導覽至消費者金鑰和機密。
-
選擇管理消費者詳細資訊。Salesforce 會將您重新導向至可能必須通過雙因素驗證才能前往的新頁面。
-
重要
將消費者金鑰和消費者機密複製到文字編輯器。您需要這些資訊才能將資料雲端連線到 Data Wrangler。
-
導覽回管理連線的應用程式。
-
導覽至連線應用程式名稱和應用程式的名稱。
-
選擇管理。
-
選取編輯政策。
-
將放寬 IP變更為放寬 IP 限制。
-
選擇 Save (儲存)。
-
在提供 Salesforce 資料雲端的存取權後,您需要為使用者提供許可權。使用下列程序以提供他們許可權。
若要為您的使用者提供許可權,請執行以下操作。
-
導覽到設定首頁。
-
在左側的導覽中,搜尋使用者,然後選擇使用者功能表項目。
-
使用您的使用者名稱選擇超連結。
-
導覽至許可集指派。
-
選擇編輯指派資料。
-
新增下列許可:
-
客戶資料平台管理員
-
客戶資料平台資料感知專家
-
-
選擇 Save (儲存)。
取得 Salesforce 網域的資訊後,您必須取得所建立URL AWS Secrets Manager 秘密的授權URL和權杖。
使用下列程序取得授權URL和權杖 URL。
若要取得授權URL和權杖 URL
-
導覽至您的 Salesforce 網域 URL。
-
使用下列其中一種方法來取得 URLs。如果您使用的是安裝有
curl和jq的 Linux 發行版本,我們建議您使用僅適用於 Linux 的方法。-
(僅適用 Linux) 在終端機中指定以下命令。
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
導覽至
example-org-URL/.well-known/openid-configuration -
將
authorization_endpoint和token_endpoint複製到文字編輯器。 -
建立下列JSON物件:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
建立OAuth組態物件後,您可以建立存放該物件的 AWS Secrets Manager 秘密。請使用下列步驟建立上述機密。
若要建立密碼,請執行以下操作。
-
選擇儲存新機密。
-
選取其他機密類型。
-
在鍵/值對下,選取純文字。
-
將空白 取代JSON為下列組態設定。
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
選擇 Next (下一步)。
-
在機密名稱中,指定機密的名稱。
-
在標籤下,選擇新增。
-
對於金鑰,請指定 sagemaker:partner。對於值,我們建議您指定可能對您的使用案例有用的值。不過,您可以指定任意值。
重要
您必須建立金鑰。如果您未建立金鑰,就無法從 Salesforce 匯入資料。
-
-
選擇 Next (下一步)。
-
選擇儲存。
-
選擇您已建立的機密。
-
記下以下欄位:
-
秘密的 Amazon Resource Number (ARN)
-
機密的名稱。
-
建立機密之後,您必須新增許可權,讓 Data Wrangler 讀取機密。使用下列程序以新增許可權。
若要新增 Data Wrangler 的讀取許可,請執行以下操作。
-
導覽至 Amazon SageMaker 主控台
。 -
選擇網域 。
-
選擇您用來存取 Data Wrangler 的網域。
-
選擇您的使用者設定檔。
-
在詳細資訊下,尋找執行角色。ARN 其格式如下:
arn:aws:iam::111122223333:role/。記下 SageMaker 執行角色。在 中ARN,它是 之後的一切example-rolerole/。 -
導覽至 IAM主控台
。 -
在搜尋IAM搜尋列中,指定 SageMaker 執行角色的名稱。
-
選擇角色。
-
選擇新增許可。
-
選擇建立內嵌政策。
-
選擇 JSON 索引標籤。
-
在編輯器中指定下列政策。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:PutSecretValue" ], "Resource": "arn:aws:secretsmanager:*:*:secret:*", "Condition": { "ForAnyValue:StringLike": { "aws:ResourceTag/sagemaker:partner": "*" } } }, { "Effect": "Allow", "Action": [ "secretsmanager:UpdateSecret" ], "Resource": "arn:aws:secretsmanager:*:*:secret:AmazonSageMaker-*" } ] } -
選擇檢閱政策。
-
針對名稱,請指定一個名稱。
-
選擇 建立政策。
授予 Data Wrangler 讀取秘密的許可後,您必須將使用 Secrets Manager 秘密的生命週期組態新增至 Amazon SageMaker Studio Classic 使用者設定檔。
使用下列程序建立生命週期組態,並將其新增至 Studio Classic 設定檔。
若要建立生命週期組態並將其新增至 Studio Classic 設定檔,請執行下列動作。
-
導覽至 Amazon SageMaker 主控台 。
-
選擇網域 。
-
選擇您用來存取 Data Wrangler 的網域。
-
選擇您的使用者設定檔。
-
如果您看到下列應用程式,請將其刪除:
-
KernelGateway
-
JupyterKernel
注意
刪除應用程式會更新 Studio Classic。更新可能需要一段時間才能發生。
-
-
等待更新發生時,請選擇生命週期組態。
-
確保您所在的頁面顯示 Studio Classic Lifecycle 組態 。
-
選擇建立組態。
-
確保已選擇 Jupyter 伺服器應用程式。
-
選擇 Next (下一步)。
-
對於名稱,請指定組態的名稱。
-
對於指令碼,請指定下列指令碼:
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
選擇提交。
-
在左側導覽上,選擇網域 。
-
選擇您的網域。
-
選擇環境。
-
在個人 Studio Classic 應用程式的生命週期組態下,選擇連接 。
-
選取現有組態。
-
在 Studio Classic Lifecycle 組態下,選取您已建立的生命週期組態。
-
選擇連接至網域。
-
選取您所連接的生命週期組態旁的核取方塊。
-
選取設定為預設值。
設定生命週期組態時,可能會遇到問題。如需有關對其偵錯詳細資訊,請參閱生命週期組態偵錯。
資料科學家指南
使用下列步驟連接 Salesforce 資料雲端,並在 Data Wrangler 中存取您的資料。
重要
您的管理員必須使用前面區段中的資訊來設定 Salesforce 資料雲端。如果您遇到問題,請聯絡他們以取得疑難排解協助。
若要開啟 Studio Classic 並檢查其版本,請參閱下列程序。
-
使用 中的步驟必要條件透過 Amazon SageMaker Studio Classic 存取 Data Wrangler。
-
在您要用來啟動 Studio Classic 的使用者旁邊,選取啟動應用程式 。
-
選擇 Studio。
使用來自 Salesforce 資料雲端的資料在 Data Wrangler 中建立資料集
-
登入 Amazon SageMaker 主控台
。 -
選擇 Studio。
-
選擇啟動應用程式。
-
從下拉式清單中選取 Studio。
-
選擇首頁圖示。
-
選擇資料。
-
選擇 Data Wrangler。
-
選擇匯入資料。
-
在可用性下,選擇 Salesforce 資料雲端。
-
針對連線名稱,指定連線至 Salesforce 資料雲端的名稱。
-
對於組織 URL,在您的 URL Salesforce 帳戶中指定組織。您可以從URL管理員取得 。
-
選擇連線。
-
指定您的憑證以登入 Salesforce。
您可以在連線到資料集後,使用 Salesforce 資料雲端中的資料開始建立資料集。
選取資料表之後,您可以撰寫查詢並加以執行。查詢的輸出會顯示在查詢結果下。
在您確定查詢的輸出之後,接著就可以將查詢的輸出匯入 Data Wrangler 流程,以執行資料轉換。
建立資料集之後,導覽至資料流量畫面以開始轉換資料。
從 Snowflake 匯入資料
您可以在 SageMaker Data Wrangler 中使用 Snowflake 作為資料來源,以準備 Snowflake 中的資料進行機器學習。
使用 Snowflake 作為 Data Wrangler 中的資料來源,您可以快速連線到 Snowflake,而無需撰寫任何一行程式碼。您可以將 Snowflake 中的資料與 Data Wrangler 中任何其他資料來源的資料聯結。
連線之後,您可以互動查詢 Snowflake 中儲存的資料、以超過300 個預先設定的資料轉換資料、使用一組健全的預先設定視覺化範本來了解資料並識別潛在錯誤和極端值、快速識別資料準備工作流程中的不一致情況,以及在模型部署到生產環境之前診斷問題。最後,您可以將資料準備工作流程匯出至 Amazon S3,以便與其他 SageMaker 功能搭配使用,例如 Amazon SageMaker Autopilot、Amazon SageMaker Feature Store 和 Amazon SageMaker Pipelines。
您可以使用您建立的 AWS Key Management Service 金鑰來加密查詢的輸出。如需 的詳細資訊 AWS KMS,請參閱 AWS Key Management Service。
管理員指南
重要
若要進一步了解精細存取控制和最佳實務,請參閱安全存取控制
本節適用於在 SageMaker Data Wrangler 內設定 Snowflake 存取權的 Snowflake 管理員。
重要
由您負責管理與監控 Snowflake 內的存取控制。Data Wrangler 不會新增與 Snowflake 相關的存取控制層。
存取控制包括下列項目:
-
使用者存取的資料
-
(選用) 提供 Snowflake 撰寫查詢結果給 Amazon S3 儲存貯體能力的儲存整合
-
使用者可以執行的查詢
(選用) 設定 Snowflake 資料匯入許可權
根據預設, Data Wrangler 會在 Snowflake 中查詢資料,而不會在 Amazon S3 位置建立資料副本。如果您要設定 Snowflake 與儲存整合,請使用下列資訊。您的使用者可以使用儲存整合將查詢結果儲存在 Amazon S3 的位置。
您的使用者可能擁有不同層級的敏感資料存取權限。為了達到資料安全最佳化,請為每位使用者提供自己的儲存整合。每個儲存整合都應該有自己的資料管理政策。
這個功能目前無法在選擇加入區域使用。
Snowflake 需要下列 S3 儲存貯體和目錄的許可權才能存取目錄中的檔案:
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
建立IAM政策
您必須建立IAM政策來設定 Snowflake 的存取許可,以便從 Amazon S3 儲存貯體載入和卸載資料。
以下是您用來建立JSON政策的政策文件:
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
如需使用政策文件建立政策的相關資訊和程序,請參閱建立IAM政策。
如需提供搭配 Snowflake 使用IAM許可概觀的文件,請參閱下列資源:
若要將資料科學家的 Snowflake 角色使用許可權授與儲存整合,您必須執行 GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;。
-
integration_name是儲存整合的名稱。 -
snowflake_role是指定給資料科學家使用者的預設 Snowflake 角色名稱。
設定 Snowflake OAuth 存取
您可以讓使用者使用身分提供者存取 Snowflake,而不是讓他們直接將其憑證輸入 Data Wrangler。以下是 Data Wrangler 支援的身分提供者的 Snowflake 文件連結。
使用前面連結中的說明文件來設定身分提供者的存取權限。本區段中的資訊和程序可協助您了解如何正確使用文件來存取 Data Wraangler 內的 Snowflake。
您的身分提供者需要將 Data Wrangler 識別為應用程式。使用下列程序,將 Data Wrangler 註冊為身分提供者內的應用程式:
-
選取啟動將 Data Wrangler 註冊為應用程式程序的組態。
-
提供身分提供者內的使用者存取 Data Wrangler。
-
將OAuth用戶端憑證儲存為 AWS Secrets Manager 秘密,以開啟用戶端身分驗證。
-
URL 使用下列格式指定重新導向:https://
domain-ID.studio。AWS 區域.sagemaker.aws/jupyter/default/lab重要
您正在指定 Amazon SageMaker 網域 ID AWS 區域 ,且您正在用來執行 Data Wrangler。
重要
您必須URL為每個 Amazon SageMaker 網域以及執行 Data Wrangler AWS 區域 的位置註冊 。來自網域 AWS 區域 且沒有為其URLs設定重新導向的使用者將無法向身分提供者驗證存取 Snowflake 連線。
-
請確定 Data Wrangler 應用程式允許授權碼和重新整理權杖授予類型。
在身分提供者中,您必須設定伺服器,將OAuth權杖傳送至使用者層級的 Data Wrangler。伺服器以 Snowflake 做為對象傳送權杖。
Snowflake 使用角色的概念,這些角色是 中使用的角色的不同IAM角色 AWS。您必須將身分提供者設定為使用任何角色,才能使用與 Snowflake 帳戶相關聯的預設角色。例如,如果使用者在其 Snowflake 設定檔中具有 systems administrator預設角色,則從 Data Wrangler 到 Snowflake 的連線會使用 systems administrator做為該角色。
使用下列程序來設定伺服器。
若要設定伺服器,請執行以下操作。除了最後一個之外,您的所有步驟都會在 Snowflake 中處理。
-
開始設定伺服器或 API。
-
設定授權伺服器以使用授權碼並重新整理權杖授予類型。
-
指定存取權杖的存留期。
-
設定重新整理權杖閒置逾時。閒置逾時是若未使用重新整理權杖的到期時間。
注意
如果您要在 Data Wrangler 中排程任務,建議您將閒置逾時時間設定為大於處理任務的頻率。否則,某些處理任務可能會失敗,因為重新整理權杖在執行之前已過期。當重新整理權杖到期時,使用者必須透過 Data Wrangler 存取他們對 Snowflake 建立的連線來重新進行身分驗證。
-
指定
session:role-any做為新範圍。注意
對於 Azure AD,請複製該範圍的唯一識別碼。Data Wrangler 要求您向其提供識別符。
-
重要
在 Snowflake 的外部OAuth安全整合中,啟用
external_oauth_any_role_mode。
重要
Data Wrangler 不支援輪換重新整理權杖。使用輪換重新整理權杖可能會導致存取失敗或使用者需要經常登入。
重要
如果重新整理權杖過期,您的使用者必須透過 Data Wrangler 存取他們對 Snowflake 建立的連線進行重覆身分驗證。
設定OAuth提供者之後,您會提供 Data Wrangler 連線至提供者所需的資訊。您可以使用來自身分提供者的文件來取得下列欄位的值:
-
權杖 URL – 身分提供者傳送給 Data Wrangler URL的權杖的 。
-
授權 URL – 身分提供者URL的授權伺服器的 。
-
用戶端 ID – 身分提供者的 ID。
-
用戶端秘密 – 只有授權伺服器或 API辨識的秘密。
-
(僅限 Azure AD) 您已複製OAuth的範圍憑證。
您可以將欄位和值存放在 AWS Secrets Manager 秘密中,並將其新增至您用於 Data Wrangler 的 Amazon SageMaker Studio Classic 生命週期組態。生命週期組態是 Shell 指令碼。使用它讓 Data Wrangler 存取秘密的 Amazon Resource Name (ARN)。如需建立秘密的相關資訊,請參閱將硬式編碼秘密移至 AWS Secrets Manager。如需有關在 Studio Classic 中使用生命週期組態的資訊,請參閱 使用生命週期組態來自訂 Studio Classic。
重要
建立 Secrets Manager 秘密之前,請確定您用於 Amazon SageMaker Studio Classic 的 SageMaker 執行角色具有在 Secrets Manager 中建立和更新秘密的許可。如需有關新增許可的詳細資訊,請參閱範例:建立機密的許可。
對於 Okta 和 Ping Federate,以下為機密格式:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
對於 Azure AD,以下為機密格式:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
您必須擁有使用您所建立的 Secrets Manager 機密的生命週期組態。您可以建立生命週期組態,也可以修改已建立的生命週期組態。組態必須使用下列指令碼。
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
如需設定生命週期組態的資訊,請參閱建立並關聯生命週期組態。當您進行設定程序時,請執行以下操作:
-
將組態的應用程式類型設定為
Jupyter Server。 -
將組態連接至具有您使用者的 Amazon SageMaker 網域。
-
依預設執行組態。每次使用者登入 Studio Classic 時都必須執行。否則,當您的使用者使用 Data Wrangler 時,將無法使用儲存在組態中的憑證。
-
生命週期組態會在使用者的主資料夾中建立
snowflake_identity_provider_oauth_config名稱的檔案。檔案包含 Secrets Manager 機密。每次初始化 Jupyter 伺服器執行個體時,請確定它位於使用者的主資料夾中。
Data Wrangler 與 Snowflake 之間的私有連線,透過 AWS PrivateLink
本節說明如何 AWS PrivateLink 使用 在 Data Wrangler 和 Snowflake 之間建立私有連線。下列區段會說明所有步驟。
建立 VPC
如果您沒有VPC設定,請遵循建立新VPC指示來建立。
選定VPC您要用來建立私有連線的 之後,請提供下列憑證給 Snowflake 管理員以啟用 AWS PrivateLink:
-
VPC ID
-
AWS 帳戶 ID
-
URL 您用來存取 Snowflake 的對應帳戶
重要
如 Snowflake 的文件所述,啟用 Snowflake 帳戶最多可能需要兩個工作天。
設定 Snowflake AWS PrivateLink 整合
AWS PrivateLink 啟用 後,在 Snowflake 工作表中執行下列命令,以擷取您區域的 AWS PrivateLink 組態。登入您的 Snowflake 主控台,然後在工作表下輸入以下內容:select
SYSTEM$GET_PRIVATELINK_CONFIG();
-
從
privatelink_ocsp-url產生的JSON物件擷取下列項目的值:privatelink-account-name、privatelink-account-url、privatelink_ocsp-url和 。每個值的範例顯示在下列程式碼片段中。儲存這些值供之後使用。privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
切換至您的 AWS 主控台並導覽至VPC選單。
-
從左側面板中,選擇端點連結以導覽至VPC端點設定。
在那裡,選擇建立端點。
-
選擇依名稱尋找服務的選項按鈕,如下列螢幕擷取畫面所示。
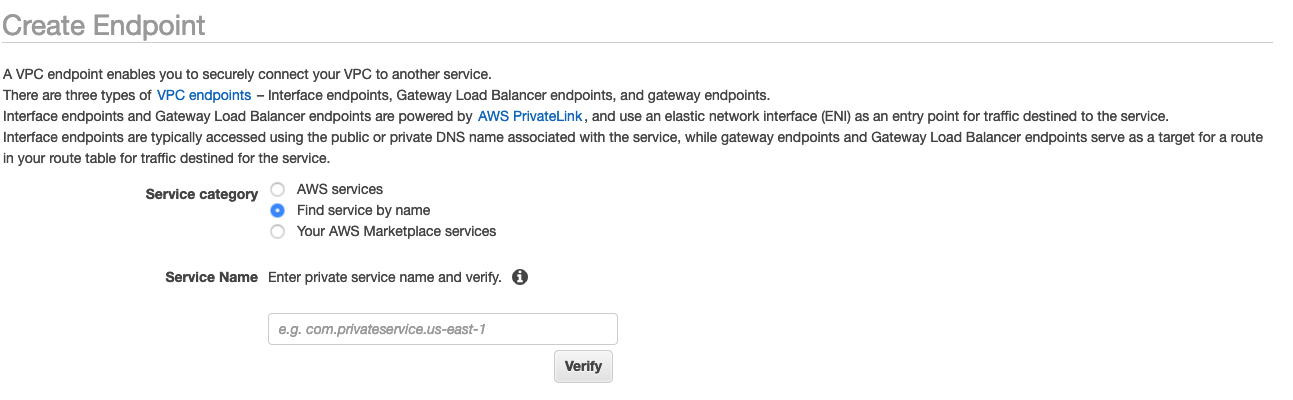
-
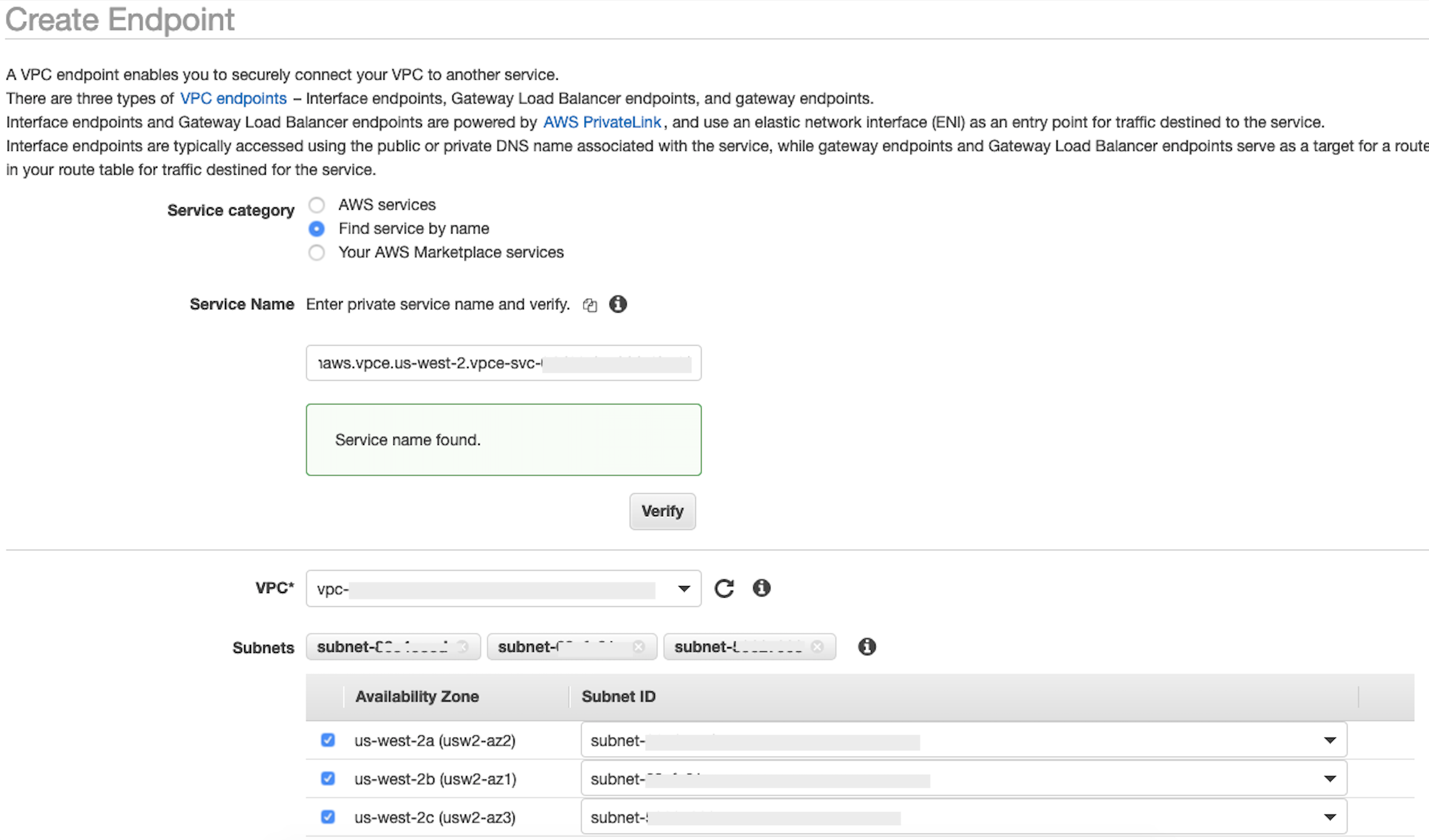
在服務名稱欄位中,貼上您在上一個步驟中擷取的
privatelink-vpce-id值中,然後選擇驗證。如果連線成功,畫面上會顯示綠色警示,指出找到的服務名稱,且 VPC和子網路選項會自動展開,如下列螢幕擷取畫面所示。視您目標區域而定,產生的畫面可能會顯示另一個 AWS 區域名稱。
-
從VPC下拉式清單中選取您傳送至 Snowflake 的相同 VPC ID。
-
如果您尚未建立子網路,請執行下列有關建立子網路的指示集。
-
從VPC下拉式清單中選取子網路。然後選取建立子網路,然後依照提示在 中建立子集VPC。請務必選取您傳送的 Snowflake VPC ID。
-
在安全群組組態下,選取建立新的安全群組,以在新索引標籤中開啟預設的安全群組畫面。在這個新的索引標籤中,選擇建立安全群組。
-
提供新的安全群組的名稱 (如
datawrangler-doc-snowflake-privatelink-connection) 和描述。請務必選取您在先前步驟中使用的 VPC ID。 -
新增兩個規則,以允許從 內部的流量VPC到此VPC端點。
在個別索引標籤中導覽至您的 VPCs VPC下,並擷取您 的CIDR區塊VPC。然後在傳入規則區段中,選擇新增規則。選取
HTTPS類型,在表單中將來源保留為自訂,然後貼上從前面describe-vpcs呼叫擷取的值 (例如10.0.0.0/16)。 -
選擇建立安全群組。從新建立的安全群組 (例如
sg-xxxxxxxxxxxxxxxxx) 擷取安全群組 ID。 -
在VPC端點組態畫面中,移除預設安全群組。在搜尋欄位中貼上安全群組 ID,然後選取核取方塊。
-
選取建立端點。
-
如果端點建立成功,您會看到一個頁面,其中包含 VPC ID 指定的VPC端點組態連結。選取連結以完整檢視組態。
擷取DNS名稱清單中最上方的記錄。這可以與其他DNS名稱區別,因為它只包含區域名稱 (例如
us-west-2),而且沒有可用區域字母符號 (例如us-west-2a)。儲存此資訊以供之後使用。
在 中DNS為 Snowflake 端點設定 VPC
本節說明如何在 中DNS設定 Snowflake 端點VPC。這可讓您VPC解析對 Snowflake AWS PrivateLink 端點的請求。
-
導覽至 AWS 主控台中的 Route 53 選單
。 -
選取託管區域選項 (如有需要,請展開左側功能表以尋找此選項)。
-
選擇建立託管區域。
-
在網域名稱欄位中,參照前面步驟
privatelink-account-url中儲存的值。在此欄位中,您的 Snowflake 帳戶 ID 會從DNS名稱中移除,且僅使用以區域識別符開頭的值。稍後也會為子網域建立資源記錄集,例如region.privatelink.snowflakecomputing.com。 -
在類型區段中,選取私有託管區域的選項按鈕。您的區域代碼可能不是
us-west-2。參考 Snowflake 傳回給您DNS的名稱。
-
在VPCs要與託管區域建立關聯的 區段中,選取您的 VPC 所在的區域,以及先前步驟中使用的 VPC ID。
-
選擇建立託管區域。
-
-
接下來,建立兩個記錄,一個用於
privatelink-account-url,另一個則用於privatelink_ocsp-url。-
在託管區域選單中,選擇建立記錄集。
-
在記錄名稱下,僅輸入您的 Snowflake 帳戶 ID (
privatelink-account-url中的前 8 個字元)。 -
在記錄類型 下,選取 CNAME。
-
在值 下,輸入您在設定 Snowflake AWS PrivateLink 整合區段最後一個步驟中擷取的區域VPC端點DNS名稱。
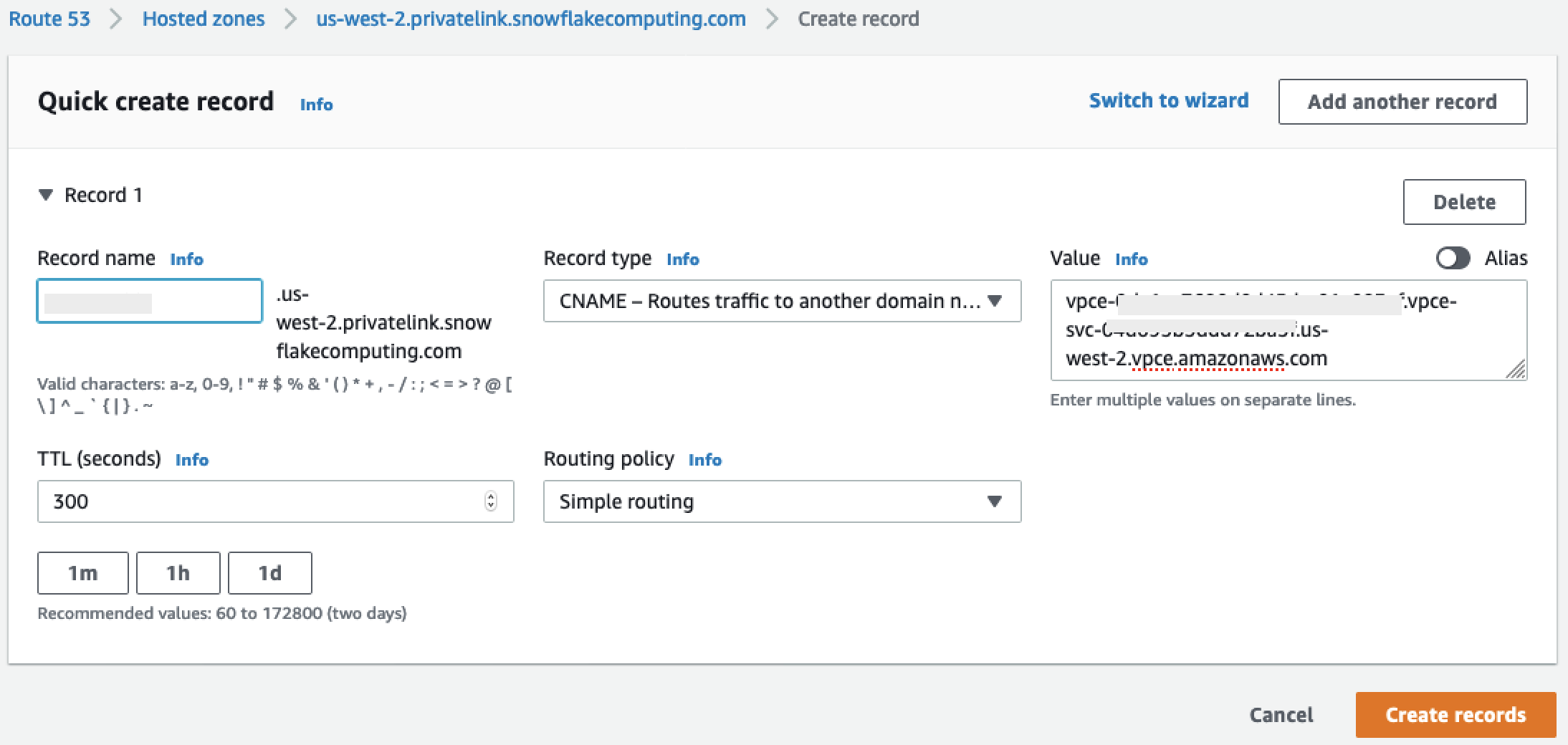
-
選擇建立記錄。
-
針對我們標記為 OCSP的記錄重複上述步驟
privatelink-ocsp-url,從記錄名稱的ocsp8 個字元 Snowflake ID 開始 (例如ocsp.xxxxxxxx)。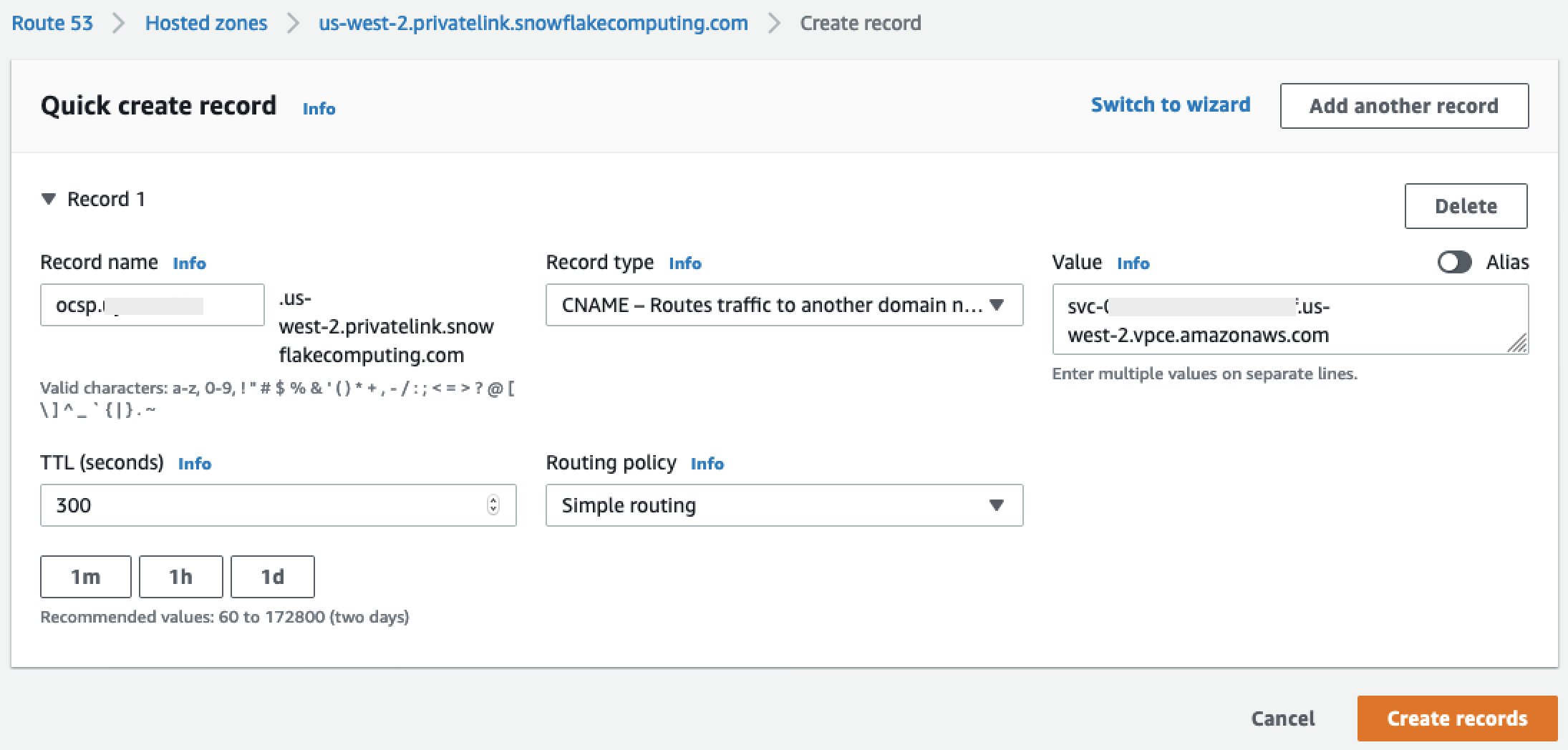
-
-
為您的 設定 Route 53 Resolver 傳入端點 VPC
本節說明如何為您的 設定 Route 53 解析程式傳入端點VPC。
-
導覽至 AWS 主控台中的 Route 53 選單
。 -
在安全區段的左側面板中,選取安全群組選項。
-
-
選擇建立安全群組。
-
提供安全群組的名稱 (如
datawranger-doc-route53-resolver-sg) 和描述。 -
選取先前步驟中使用的 VPC ID。
-
建立規則,允許UDPTCP在 VPC CIDR 區塊內進行DNS往返。

-
選擇建立安全群組。請注意安全群組 ID,因為 新增規則以允許流量到VPC端點安全群組。
-
-
導覽至 AWS 主控台中的 Route 53 選單
。 -
在解析程式區段中,選取傳入端點選項。
-
-
選擇建立傳入端點。
-
提供端點名稱。
-
從VPC區域下拉式清單中的 中,選取您在先前所有步驟中使用的 VPC ID。
-
在此端點的安全群組下拉式清單中,從本區段的步驟 2 選取安全群組 ID。
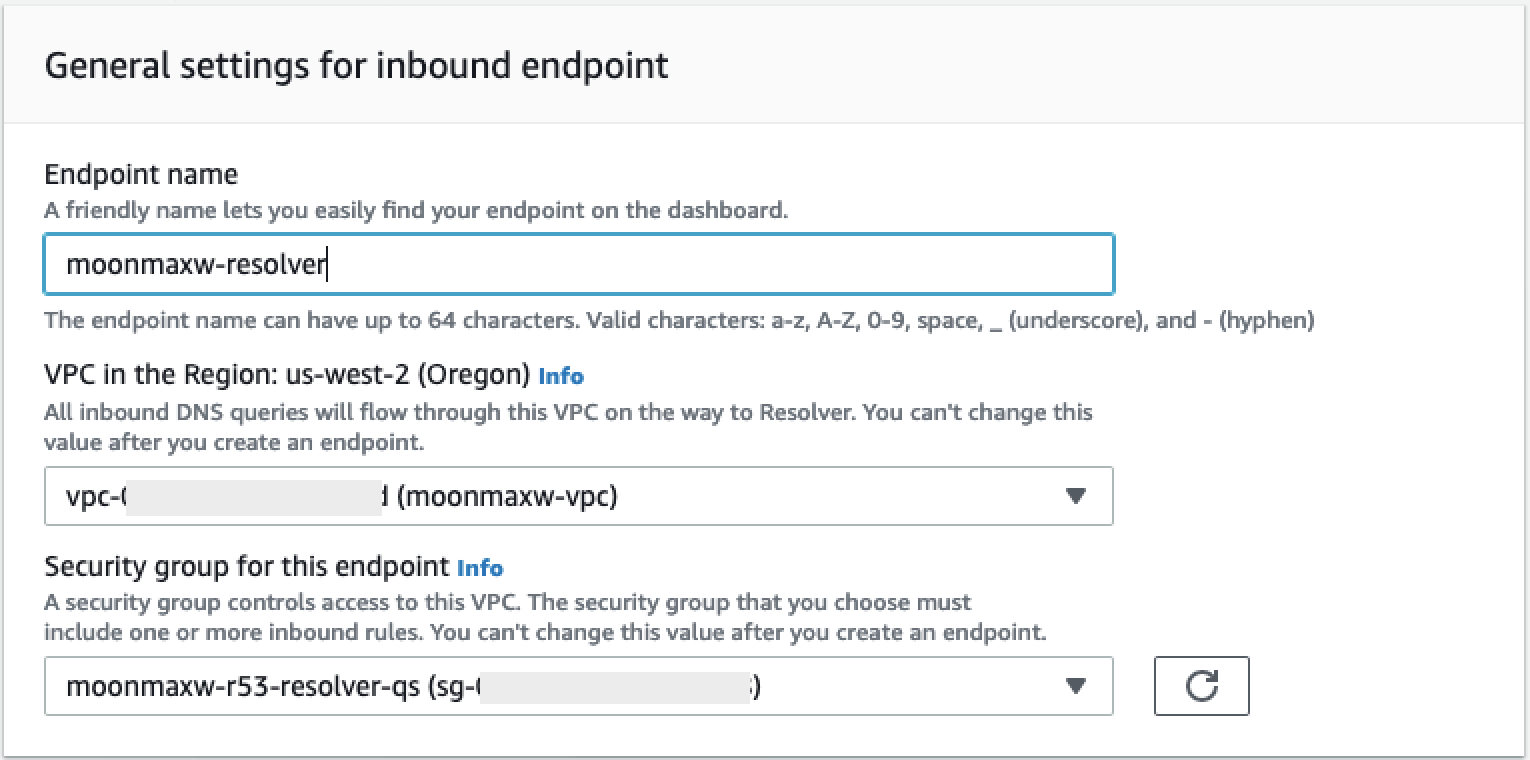
-
在 IP 地址區段中,選取可用區域、選取一個子網路,然後將無線電選擇器保留為每個所選 IP 位址所使用自動選擇的 IP 地址。
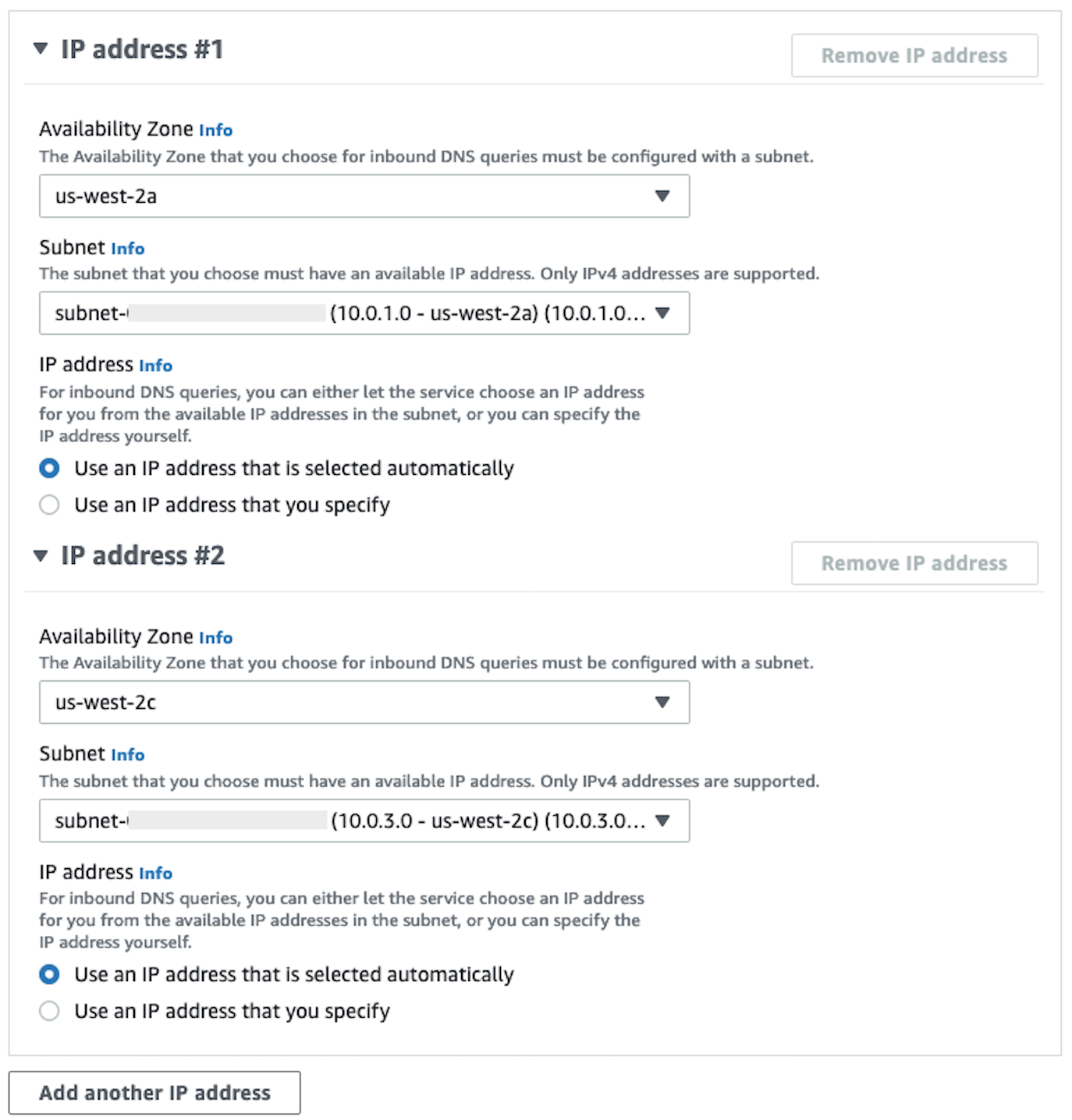
-
選擇提交。
-
-
在傳入端點建立之後加以選取。
-
建立傳入端點後,請記下解析程式的兩個 IP 地址。

SageMaker VPC 端點
本節說明如何為下列項目建立VPC端點:Amazon SageMaker Studio Classic、 SageMaker 筆記本、、 SageMaker API SageMaker 執行期和 Amazon SageMaker Feature Store 執行期。
建立套用至所有端點的安全群組。
-
導覽至 AWS 主控台中的EC2選單
。 -
在網路與安全區段中,選取安全群組選項。
-
選擇建立安全群組。
-
提供安全群組的名稱和描述 (如
datawrangler-doc-sagemaker-vpce-sg)。稍後會新增規則,以允許HTTPS流量從 轉移到 SageMaker 此群組。
建立端點
-
導覽至 AWS 主控台中的VPC選單
。 -
選取端點選項。
-
選擇建立端點。
-
在搜尋欄位中輸入服務的名稱來搜尋服務。
-
從VPC下拉式清單中,選取 VPC Snowflake AWS PrivateLink 連線所在的 。
-
在子網路區段中,選取可存取 Snowflake PrivateLink 連線的子網路。
-
勾選啟用DNS名稱核取方塊。
-
在安全群組區段中,選取您在前一區段中建立的安全群組。
-
選擇建立端點。
設定 Studio Classic 和 Data Wrangler
本節說明如何設定 Studio Classic 和 Data Wrangler。
-
設定安全群組。
-
導覽至 AWS 主控台中的 Amazon EC2選單。
-
在網路與安全區段中,選取安全群組選項。
-
選擇建立安全群組。
-
提供安全群組的名稱和描述 (如
datawrangler-doc-sagemaker-studio)。 -
建立下列傳入規則。
-
與您在設定 Snowflake PrivateLink 整合步驟中建立的 Snowflake PrivateLink 連線所佈建HTTPS的安全群組連線。
-
您在設定 Snowflake PrivateLink 整合步驟 中為 Snowflake PrivateLink 連線佈建的安全群組HTTP連線。
-
您在為 設定 Route 53 Resolver 傳入端點的步驟 2 中建立TCP的 Route 53 Resolver 傳入端點安全群組的 UDP和 DNS(連接埠 53)。 Route 53 VPC
-
-
選擇右下角的建立安全群組按鈕。
-
-
設定 Studio Classic。
-
導覽至 AWS 主控台中的 SageMaker 選單。
-
從左側主控台中,選取 SageMaker Studio Classic 選項。
-
如果您沒有設定任何網域組態,就會出現開始使用功能表。
-
從開始使用功能表中選取 標準設定選項。
-
在身分驗證方法 下,選取AWS 身分和存取管理 (IAM)。
-
從許可權功能表中,您可以建立新角色或使用預先存在的角色,視您的使用案例而定。
-
如果您選擇建立新角色,系統會顯示選項,以提供 S3 儲存貯體名稱以及為您產生的政策。
-
如果您已經擁有一個角色,該角色具備您需要存取的 S3 儲存貯體的許可權,則可從下拉式清單選取該角色。此角色應已連接到
AmazonSageMakerFullAccess政策。
-
-
選取 Network and Storage 下拉式清單,以設定 、VPC安全性和子網路 SageMaker使用。
-
在 下VPC,選取 VPC Snowflake PrivateLink 連線所在的 。
-
在子網路 (Subnet) 下,選取可存取 Snowflake PrivateLink 連線的子網路。
-
在 Studio Classic 的網路存取下,選取VPC僅限 。
-
在安全群組下,選取您在步驟 1 中建立的安全群組。
-
-
選擇提交。
-
-
編輯 SageMaker 安全群組。
-
建立下列傳入規則:
-
步驟 2 SageMaker 中由 自動建立的傳入和傳出NFS安全群組的連接埠 2049 (安全群組名稱包含 Studio Classic 網域 ID)。
-
存取本身的所有TCP連接埠 (VPC僅限 SageMaker需要)。
-
-
-
編輯 VPC Endpoint Security 群組:
-
導覽至 AWS 主控台中的 Amazon EC2選單。
-
尋找您在前面步驟中建立的安全群組。
-
新增傳入規則,允許來自步驟 1 中建立之安全群組的HTTPS流量。
-
-
建立使用者設定檔。
-
從 SageMaker Studio Classic 控制面板 中,選擇新增使用者 。
-
提供使用者名稱。
-
對於執行角色,選擇建立新角色或使用預先存在的角色。
-
如果您選擇建立新角色,系統會顯示選項,以提供 Amazon S3 儲存貯體名稱以及為您產生的政策。
-
如果您已經擁有一個角色,該角色具備您需要存取的 Amazon S3 儲存貯體的許可權,則可從下拉式清單選取該角色。此角色應已連接到
AmazonSageMakerFullAccess政策。
-
-
選擇提交。
-
-
建立資料流量 (請遵循上一區段所述的資料科學家指南)。
-
新增 Snowflake 連線時,請在 Snowflake 帳戶名稱
privatelink-account-name(英數字元) 欄位中輸入 (從設定 Snowflake PrivateLink 整合步驟) 的值,而不是純 Snowflake 帳戶名稱。 其他一切都保持不變。
-
提供資訊給資料科學家
提供資料科學家從 Amazon SageMaker Data Wrangler 存取 Snowflake 所需的資訊。
重要
您的使用者需要執行 Amazon SageMaker Studio Classic 1.3.0 版或更新版本。如需有關檢查 Studio Classic 版本並更新版本的資訊,請參閱 使用 Amazon Data Wrangler 準備 ML SageMaker 資料。
-
若要讓您的資料科學家從 SageMaker Data Wrangler 存取 Snowflake,請提供下列其中一項:
-
對於基本身分驗證,提供 Snowflake 帳戶名稱、使用者名稱和密碼。
-
對於 OAuth,身分提供者中的使用者名稱和密碼。
-
對於 ARN,Secrets Manager 會秘密 Amazon Resource Name (ARN)。
-
使用 AWS Secrets Manager 和秘密ARN的 建立的秘密。如果您選擇此選項,請使用下列程序來建立 Snowflake 的機密。
重要
如果您的資料科學家使用 Snowflake 憑證 (使用者名稱和密碼) 選項連線到 Snowflake,您可以使用 Secret Manager 將憑證儲存在機密中。Secrets Manager 會輪換秘密,當作最佳實務安全計劃的一部分。只有在設定 Studio Classic 使用者設定檔時所設定的 Studio Classic 角色,才能存取在 Secrets Manager 中建立的秘密。這需要您將此許可 新增至連接到 Studio Classic 角色
secretsmanager:PutResourcePolicy的政策。我們強烈建議您設定角色政策的範圍,以針對不同的 Studio Classic 使用者群組使用不同的角色。您可以為 Secrets Manager 新增其他資源型的許可權。請參閱管理機密政策以了解您可以使用的條件索引鍵。
如需有關建立機密的資訊,請參閱建立機密。我們會向您收取您建立機密的費用。
-
-
(選用) 提供資料科學家您使用下列程序在 Snowflake 中建立雲端儲存整合
所建立的儲存整合名稱。這是新整合的名稱,並在您執行的 CREATE INTEGRATIONSQL命令integration_name中呼叫 ,如下列程式碼片段所示:CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
資料科學家指南
使用下列步驟連接 Snowflake,並在 Data Wrangler 中存取您的資料。
重要
您的管理員必須使用前面區段中的資訊來設定 Snowflake。如果您遇到問題,請聯絡他們以取得疑難排解協助。
您可透過以下任一種方式來連線 Snowflake。
-
在 Data Wrangler 中指定您的 Snowflake 憑證 (帳戶名稱、使用者名稱和密碼)。
-
提供包含憑證之秘密的 Amazon Resource Name (ARN)。
-
使用開放標準進行存取委派 (OAuth) 提供者,以連線至 Snowflake。您的管理員可以讓您存取下列其中一個OAuth提供者:
請洽詢您的系統管理員,了解連線至 Snowflake 所需的方法。
以下各區段包含如何使用上述方法連線到 Snowflake 的資訊。
您可以在連線至 Snowflake 之後開始匯入資料的程序。
在 Data Wrangler 中,您可以檢視資料倉儲、資料庫和結構描述,以及可用來預覽資料表的眼睛圖示。選取預覽資料表圖示後,即會產生該資料表的結構描述預覽。您必須先選取倉庫,才能預覽資料表。
重要
如果您要匯入的資料集包含 TIMESTAMP_TZ或 TIMESTAMP_LTZ的資料欄類型,請新增 ::string至查詢的資料欄名稱。如需詳細資訊,請參閱如何:將 TIMESTAMP_TZ 和 TIMESTAMP_LTZ 資料卸載至 Parquet 檔案
選取資料倉儲、資料庫和結構描述之後,您現在可以撰寫查詢並加以執行。查詢的輸出會顯示在查詢結果下。
在您確定查詢的輸出之後,接著就可以將查詢的輸出匯入 Data Wrangler 流程,以執行資料轉換。
匯入資料之後,導覽至 Data Wrangler 流程並開始向其新增轉換。如需可用的轉換清單,請參閱轉換資料。
從軟體即服務 (SaaS) 平台匯入資料
您可以使用 Data Wrangler 從 40 多個軟體即服務 (SaaS) 平台匯入資料。若要從 SaaS 平台匯入資料,您或您的管理員必須使用 Amazon 將資料從平台 AppFlow 傳輸至 Amazon S3 或 Amazon Redshift。如需 Amazon 的詳細資訊 AppFlow,請參閱什麼是 Amazon AppFlow? 如果您不需要使用 Amazon Redshift,我們建議您將資料傳輸到 Amazon S3 以進行更簡單的程序。
Data Wrangler 支援來自以下 SaaS 平台的傳輸資料:
上述清單包含有關設定資料來源的詳細資訊的連結。閱讀下列資訊後,您或您的管理員就可以參考前面的連結。
當您導覽至 Data Wrangler 流程的匯入索引標籤時,您會在下列各區段下看到資料來源:
-
可用性
-
設定資料來源
您可以連線到可用性下的資料來源,不需其他設定。您可以選擇資料來源並匯入您的資料。
設定資料來源 下的資料來源,需要您或您的管理員使用 Amazon 將資料從 SaaS 平台 AppFlow 傳輸到 Amazon S3 或 Amazon Redshift。如需執行傳輸的相關資訊,請參閱使用 Amazon AppFlow 傳輸您的資料。
執行資料傳輸後,SaaS 平台會顯示為可用性下的資料來源。您可以選擇它,然後將已傳輸的資料匯入 Data Wrangler。您傳輸的資料會顯示為您可以查詢的資料表。
使用 Amazon AppFlow 傳輸您的資料
Amazon AppFlow 是一個平台,您可以用來將資料從 SaaS 平台傳輸到 Amazon S3 或 Amazon Redshift,而不必撰寫任何程式碼。若要執行資料傳輸,請使用 AWS Management Console。
重要
您必須確定已設定執行資料傳輸的許可權。如需詳細資訊,請參閱Amazon AppFlow 許可。
新增許可後,即可以傳輸資料。在 Amazon 中 AppFlow,您可以建立流程來傳輸資料。流程是一系列的組態。您可以使用它來指定依排程執行的資料傳輸,或是將資料分割為單獨的檔案。設定流程後,您可以執行流程以傳輸資料。
如需建立流程的相關資訊,請參閱在 Amazon 中建立流程 AppFlow。如需執行流程的相關資訊,請參閱啟用 Amazon AppFlow 流程 。
資料傳輸完畢後,請使用下列程序存取 Data Wrangler 中的資料。
重要
在您嘗試存取資料之前,請確定您的IAM角色具有下列政策:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "glue:SearchTables", "Resource": [ "arn:aws:glue:*:*:table/*/*", "arn:aws:glue:*:*:database/*", "arn:aws:glue:*:*:catalog" ] } ] }
根據預設,您用來存取 Data Wrangler IAM的角色是 SageMakerExecutionRole。如需新增政策的詳細資訊,請參閱新增IAM身分許可 (主控台)。
若要連線到資料來源,請執行以下操作。
-
登入 Amazon SageMaker 主控台
。 -
選擇 Studio。
-
選擇啟動應用程式。
-
從下拉式清單中選取 Studio。
-
選擇首頁圖示。
-
選擇資料。
-
選擇 Data Wrangler。
-
選擇匯入資料。
-
在可用性下,選擇資料來源。
-
在名稱 欄位中,指定連線的名稱。
-
(選用) 選擇進階組態。
-
選擇工作群組。
-
如果您的工作群組尚未強制執行 Amazon S3 輸出位置,或者您不使用工作群組,請指定查詢結果的 Amazon S3 位置值。
-
(選用) 對於資料保留期,請選取核取方塊以設定資料保留期間,並指定資料刪除前的儲存天數。
-
(選用) 根據預設,Data Wrangler 會儲存連線。您可以選擇取消選取核取方塊,而不儲存連線。
-
-
選擇連線。
-
指定查詢。
注意
若要協助您指定查詢,您可以在左側導覽面板中選擇一個資料表。Data Wrangler 顯示資料表名稱和資料表的預覽。選擇資料表名稱旁的圖示以複製名稱。您可以在查詢中使用資料表名稱。
-
選擇執行。
-
選擇匯入查詢。
-
對於資料集名稱,請指定資料集名稱。
-
選擇新增。
當您導覽至匯入資料畫面時,您可以看到已建立的連線。您可以透過連線匯入更多資料。
匯入資料儲存
重要
我們強烈建議您遵循最佳安全實務,來遵守保護 Amazon S3 儲存貯體的最佳實務。
當您從 Amazon Athena 或 Amazon Redshift 查詢資料時,查詢的資料集會自動儲存在 Amazon S3 中。資料會儲存在您使用 Studio Classic 之 AWS 區域的預設 SageMaker S3 儲存貯體中。
預設 S3 儲存貯體具有下列命名慣例:sagemaker-。例如,如果您的帳號為 111122223333,且您在 中使用 Studio Classicregion-account
numberus-east-1,則匯入的資料集會儲存在 sagemaker-us-east-1-111122223333 中。
Data Wrangler 流程取決於此 Amazon S3 資料集位置,因此在使用相依流程時,不應在 Amazon S3 中修改此資料集。如果您堅持修改此 S3 位置,並且想要繼續使用資料流量,則必須移除 .flow 檔案內 trained_parameters中的所有物件。若要執行此操作,請從 Studio Classic 下載 .flow 檔案trained_parameters,並針對每個 執行個體刪除所有項目。完成後, trained_parameters 應為空JSON物件:
"trained_parameters": {}
匯出並使用資料流量處理資料時,您匯出的 .flow 檔案會參考 Amazon S3 中的上述資料集。使用以下區段以進一步了解。
Amazon Redshift 匯入儲存
Data Wrangler 會將查詢產生的資料集儲存在預設 SageMaker S3 儲存貯體的 Parquet 檔案中。
此檔案存放在下列字首 (目錄) 下:redshift/uuid/data/,其中 uuid 是為每個查詢建立的唯一識別符。
例如,如果您的預設儲存貯體為 sagemaker-us-east-1-111122223333,從 Amazon Redshift 查詢的單一資料集位於 s3://sagemaker-us-east-1-111122223333/redshift/uuid/data/。
Amazon Athena 匯入儲存
當您查詢 Athena 資料庫並匯入資料集時,Data Wrangler 會將該資料集以及該資料集的一個子集或預覽檔案儲存在 Amazon S3 中。
您透過選取匯入資料集匯入的資料集會以 Parquet 格式儲存在 Amazon S3 中。
當您在 Athena 匯入畫面上選取執行時,預覽檔案會以 CSV 格式寫入,並從查詢的資料集中包含最多 100 列。
您查詢的資料集位於字首 (目錄) 下方:athena/uuid/data/,其中 uuid 是為每個查詢建立的唯一識別符。
例如,如果您的預設儲存貯體是 sagemaker-us-east-1-111122223333,則從 Athena 查詢的單一資料集位於 s3://sagemaker-us-east-1-111122223333/athena/uuid/資料/example_dataset.parquet.
被儲存在 Data Wrangler 預覽資料框資料集的子集,會儲存在 athena/ 字首下。
