本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
開始使用 Data Wrangler
Amazon SageMaker Data Wrangler 是 Amazon SageMaker Studio Classic 中的一項功能。您可以透過本章節了解如何存取並開始使用 Data Wrangler。請執行下列操作:
-
完成先決條件中的每個步驟。
-
按照存取 Data Wrangler中的程序開始使用 Data Wrangler。
先決條件
若要使用 Data Wrangler,您必須完成下列先決條件。
-
若要使用 Data Wrangler,您需要存取 Amazon Elastic Compute Cloud (Amazon EC2) 執行個體。如需使用適用於 Amazon EC2 執行個體的更多相關資訊,請參閱執行個體。要了解如何查看配額,並在必要時請求增加配額,請參閱AWS 服務配額。
-
設定安全與許可中描述的必要許可。
-
如果您的組織使用的防火牆會封鎖網際網路流量,您必須擁有下列 URL 的存取權:
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
若要使用 Data Wrangler,您需要一個作用中的 Studio Classic 執行個體。要瞭解如何啟動新執行個體,請參閱Amazon SageMaker AI 網域概觀。當您的 Studio Classic 執行個體備妥時,請使用存取 Data Wrangler中的指示。
存取 Data Wrangler
以下程序假設您已經完成 先決條件。
若要存取 Studio Classic 中的 Data Wrangler,請執行以下動作。
-
登入 Studio Classic。如需詳細資訊,請參閱Amazon SageMaker AI 網域概觀。
-
選擇Studio。
-
選擇啟動應用程式。
-
從下拉式清單中選取 Studio。
-
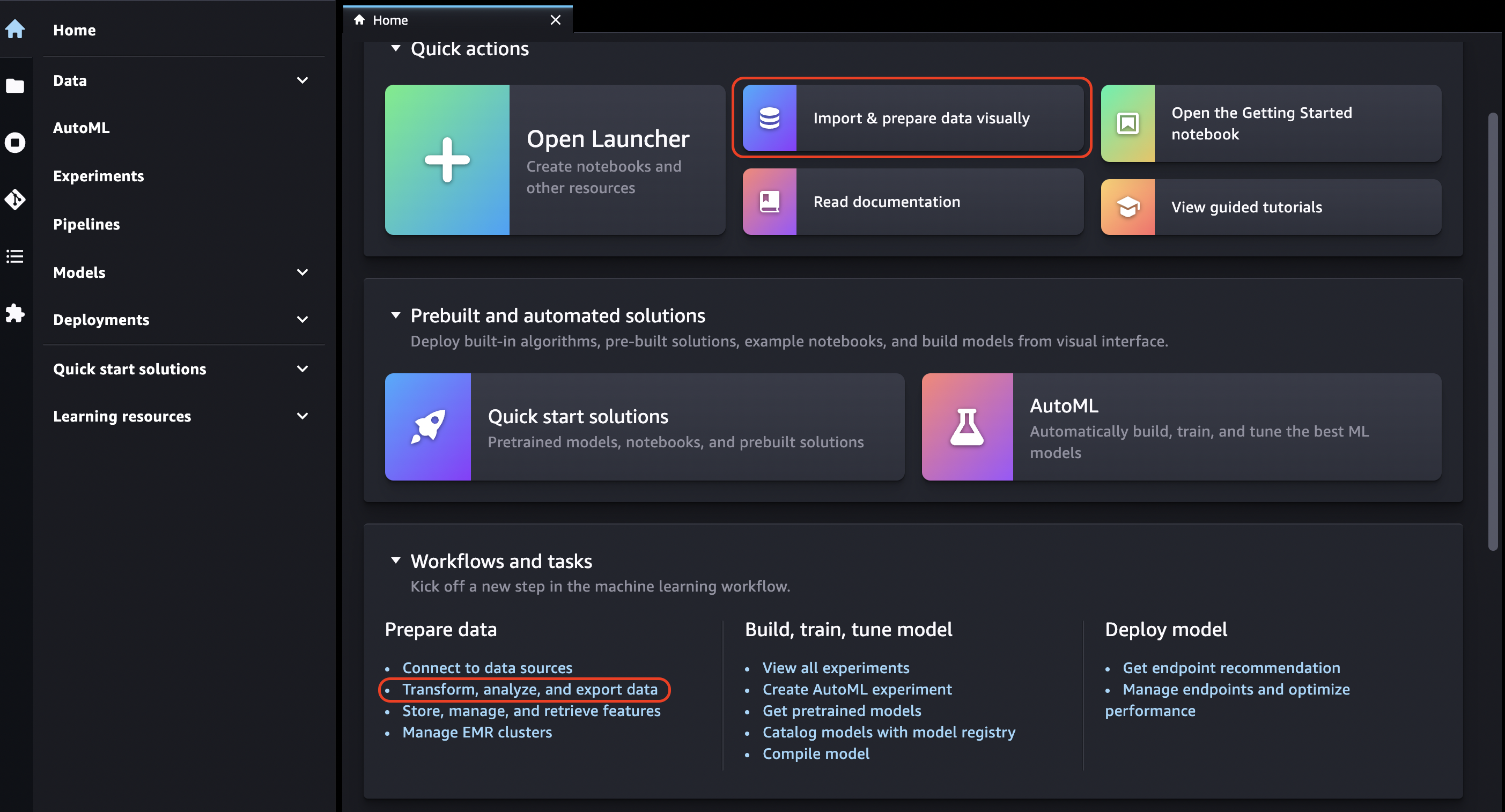
選擇首頁圖示。
-
選擇資料。
-
選擇 Data Wrangler。
-
您也可以執行下列動作來建立 Data Wrangler 流程。
-
在頂端導覽列中,選取 檔案。
-
選取新的。
-
選取Data Wrangler 流程。
-
-
(選用) 重新命名新目錄和 .flow 檔案。
-
當您在 Studio Classic 中建立新的 .flow 檔案時,您可能會看到向您介紹 Data Wrangler 的浮動切換。
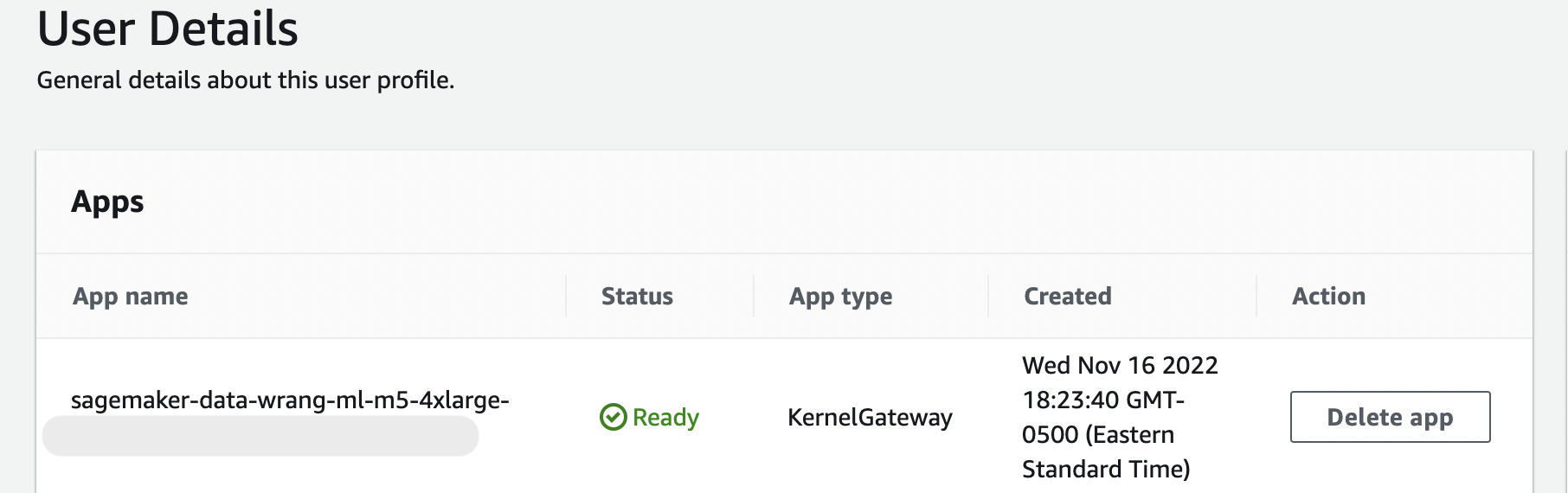
這可能需要幾分鐘的時間。
只要使用者詳細資訊頁面上的 KernelGateway 應用程式仍處於待處理狀態,此訊息就不會消失。若要查看此應用程式的狀態,請在 Amazon SageMaker Studio 頁面上的 SageMaker AI 主控台中,選取您用來存取 Studio Classic 的使用者名稱。在使用者詳細資訊頁面上,您會看到應用程式下方的 KernelGateway 應用程式。等到此應用程式狀態為就緒,開始使用 Data Wrangler。第一次啟動 Data Wrangler 時,大約需要 5 分鐘的時間。
-
若要開始使用,請選擇資料來源並使用它來匯入資料集。如需進一步了解,請參閱Import (匯入)。
匯入資料集時,資料集會顯示在資料流程中。如需詳細資訊,請參閱 建立和使用 Data Wrangler 流程。
-
匯入資料集之後,Data Wrangler 會自動推斷每個資料欄中的資料類型。選擇資料類型步驟旁的+,然後選取編輯資料類型。
重要
將轉換新增至資料類型步驟之後,您就無法使用更新類型批次更新資料欄類型。
-
若要匯出完整資料流量,請選擇匯出,然後選擇匯出選項。如需詳細資訊,請參閱 Export (匯出)。
-
最後,選擇 元件和登錄檔圖示,然後從下拉式清單中選取 Data Wrangler,以查看您建立的所有 .flow 檔案。您可以使用此功能表來尋找資料流程,並在資料流程之間移動。
啟動 Data Wrangler 之後,您可以利用下列章節,逐步了解如何使用 Data Wrangler 建立機器學習 (ML) 資料準備流程。
更新 Data Wrangler
我們建議您定期更新 Data Wrangler Studio Classic 應用程式,以取得最新功能和更新。Data Wrangler 應用程式名稱以 sagemaker-data-wrang 開頭。若要了解如何更新 Studio Classic 應用程式,請參閱關閉並更新 Amazon SageMaker Studio Classic 應用程式。
示範:Data Wrangler Titanic 資料集演練
下列區段提供逐步解說,以協助您開始使用 Data Wrangler。本逐步解說假設您已按照存取 Data Wrangler中的步驟進行操作,並開啟要用於示範的新資料流程檔案。您可能想要將此 .flow 檔案重新命名為類似titanic-demo.flow的檔案。
本逐步解說使用 Titanic 資料集
您將在本教學課程中執行下列步驟。
-
執行以下任意一項:
-
開啟 Data Wrangler 流程,然後選擇使用範例資料集。
-
將 Titanic 資料集
上傳到 Amazon Simple Storage Service (Amazon S3),然後將此資料集匯入 Data Wrangler。
-
-
使用 Data Wrangler 分析來分析此資料集。
-
使用 Data Wrangler 資料轉換來定義資料流量。
-
將流程匯出至 Jupyter 筆記本,您可以用來建立 Data Wrangler 任務。
-
處理您的資料,並開始一項 SageMaker 訓練任務,以訓練 XGBoost 二進位分類器。
將資料集上傳至 S3 並匯入
若要開始使用,您可以使用下列其中一個方法,將 Titanic 資料集匯入 Data Wrangler:
-
直接從 Data Wrangler 流程匯入資料集
-
將資料集上傳到 Amazon S3,然後將其匯入 Data Wrangler
若要將資料集直接匯入 Data Wrangler,請開啟流程,然後選擇使用範例資料集。
將資料集上傳到 Amazon S3 並將其匯入 Data Wrangler,將與您匯入自己資料的經驗更接近。下列資訊說明如何上傳資料集並匯入資料集。
在開始將資料匯入 Data Wrangler 之前,請下載 Titanic 資料集
如果您是 Amazon S3 的新使用者,可以在 Amazon S3 主控台中使用拖放功能來執行此操作。要瞭解如何操作,請參閱使用拖放功能上傳文件和文件夾在亞馬遜簡單儲存服務用戶指南中。
重要
將資料集上傳至您要用來完成此示範的相同 AWS 區域中的 S3 儲存貯體。
資料集成功上傳到 Amazon S3 後,您可以將其匯入 Data Wrangler。
匯入 Titanic 資料集到 Data Wrangler
-
選擇資料流量索引標籤中的匯入資料按鈕,或選擇匯入索引標籤。
-
選取 Amazon S3。
-
使用從 S3 資料表匯入資料集,尋找您新增 Titanic 資料集的儲存貯體。選擇 Titanic 資料集 CSV 檔案以開啟詳細資訊面板。
-
在 詳細資訊下,檔案類型 應為 CSV。檢查第一行是標題,以指定資料集的第一行是標題。您也可以將資料集命名為更好記的名稱,例如
Titanic-train。 -
選擇匯入按鈕。
當您的資料集匯入資料 Data Wrangler 時,資料集就會出現在 資料流量索引標籤中。您可以在節點上按兩下以進入節點詳細資訊檢視,這裡可以讓您新增轉換或分析。您可以透過加號圖示快速存取導覽。在下一節中,您將使用此資料流程來新增分析和轉換步驟。
資料流程
在資料流程區段中,資料流程中唯一的步驟為近期匯入的資料集和資料類型步驟。套用轉換後,您可以回到此選項卡,查看資料流程的狀態。現在,在準備和分析索引標籤下增加一些基本轉換。
準備與視覺化
Data Wrangler 具有內建的轉換和視覺化,可用來分析、清理和轉換資料。
節點詳細資訊檢視的資料 索引標籤會列出右側面板中的所有內建轉換,其中也包含您可以在其中新增自訂項目的區域。下列使用案例展示如何使用這些轉換。
若要取得可協助您進行資料探勘和特徵工程的資訊,請建立資料品質和深入分析報告。報告中的資訊可協助您清理和處理資料。它為您提供諸如缺少值的數量和極端值數量等資訊。如果您的資料有問題,例如目標洩漏或不平衡,洞察報告可以引起您注意這些問題。如需建立報告的更多相關資訊,請參閱取得有關資料和資料品質的洞察。
資料探勘
首先,使用分析資料建立資料表摘要。請執行下列操作:
-
選擇資料流程中資料類型步驟旁的 +,然後選取新增分析。
-
在 分析 區域中,從下拉式清單中選取 表格摘要。
-
為表格摘要指定一個名稱。
-
選取預覽,以預覽將會建立的表格。
-
選擇 儲存,將其儲存至資料流程。會顯示於所有分析資料下。
使用您看到的統計資料,您可以建立類似下列與此資料集相關的觀察結果:
-
平均票價 (平均值) 約為 33 美元,而最高票價超過 500 美元。此欄可能具有極端值。
-
使用? 指示資料集所缺少的值。許多欄位中的缺少值:cabin、embarked和 home.dest
-
年齡類別遺失超過 250 個值。
接下來,使用從這些統計資料中獲得的洞察來清理資料。
捨棄未使用的欄位
使用上一節的分析,清除資料集以準備進行訓練。若要將新的轉換新增至資料流程,請選擇資料流程中資料類型步驟旁的 +,然後選擇 新增轉換。
首先,捨棄您不想要用於訓練的資料欄。您可以使用pandas
使用下列程序來捨棄未使用的資料欄。
捨棄未使用的資料欄。
-
開啟 Data Wrangler 流程。
-
此網域 Data Wrangler 流程中有兩個節點。選擇資料類型節點右側的 +。
-
選擇新增轉換。
-
在 所有步驟 欄中,選擇 新增步驟。
-
在 標準轉換清單中,選擇 管理欄位。標準轉換是現成的內建轉換。確定已選取 捨棄資料欄。
-
在要刪除的資料欄底下,檢查下列欄位名稱:
-
cabin
-
ticket
-
name
-
sibsp
-
parch
-
home.dest
-
boat
-
本文
-
-
選擇預覽。
-
確認已捨棄資料欄,然後選擇新增。
請遵循下列步驟,使用 pandas 執行此操作。
-
在 所有步驟 欄中,選擇 新增步驟。
-
在 自訂轉換清單中,選擇 自訂轉換。
-
為您的轉換提供名稱,然後從下拉式清單中選擇 Python (Pandas)。
-
請在程式碼框中輸入 Python 指令碼。
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
選擇預覽以預覽變更,然後選擇新增以新增轉換。
清除缺少值
現在,清除缺少值。您可以使用處理缺少值轉換群組來執行此操作。
一些欄數有缺少值。在剩餘資料欄中,年紀和票價包含缺少值。使用自訂轉換檢查此內容。
使用 Python (Pandas)選項,使用以下命令快速檢閱每個資料欄中的項目數:
df.info()
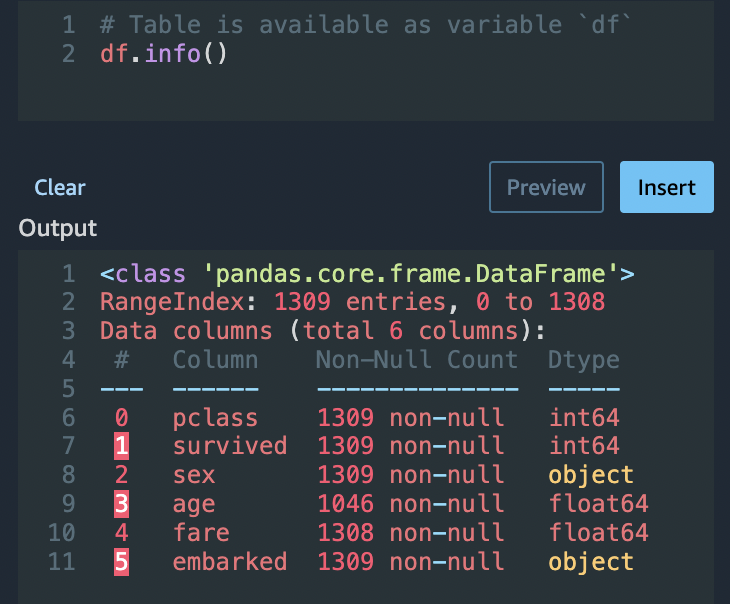
若要捨棄年齡類別中缺少值的資料列,請執行下列動作:
-
選擇處理缺少值。
-
為 轉換器 選擇 捨棄缺少值。
-
選擇輸入欄位的年齡。
-
選擇預覽以參閱新資料框,然後選擇新增以將轉換新增至流程。
-
對票價重複相同的過程。
您可以在 自訂轉換 區段df.info()中使用,以確認所有資料列現在都有 1,045 個值。
自訂 Pandas:編碼
試圖使用 Pandas 進行平面編碼。編碼分類資料是為類別建立數值表示的過程。例如,如果您的類別是 Dog 和 Cat,則可以將此資訊編碼為兩個向量:[1,0] 表示 Dog,而 [0,1] 表示 Cat。
-
在自訂轉換區段中,從下拉式清單中選擇 Python (Pandas)。
-
請在程式碼框中輸入以下內容。
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
選擇預覽以預覽變更。每個資料欄的編碼版本會新增到資料集。
-
選擇新增以新增轉換。
自訂 SQL:選取資料欄
現在,選擇要繼續使用 SQL 的資料欄。對於此示範,選取下列SELECT陳述式中列出的資料欄清單。因為是否倖存是您訓練的目標欄,所以將該欄放在第一位。
-
在 自訂轉換 區段中,從下拉式清單中選取 SQL (PySpark SQL)。
-
請在程式碼框中輸入以下內容。
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
選擇預覽以預覽變更。
SELECT陳述式中列出的資料欄清單是唯一的剩餘資料欄。 -
選擇新增以新增轉換。
匯出至 Data Wrangler 筆記本
完成建立資料流程後,您有許多匯出選項。下一節解釋如何匯出至 Data Wrangler 任務筆記本。Data Wrangler 任務是使用處理資料流程中,所定義的步驟來處理資料。若要進一步了解所有匯出選項,請參閱Export (匯出)。
匯出至 Data Wrangler 任務筆記本
當您使用 Data Wrangler 任務匯出資料流程時,程序會自動建立 Jupyter 筆記本。此筆記本會在您的 Studio Classic 執行個體中自動開啟,並設定為執行 SageMaker Processing 任務,以執行 Data Wrangler 資料流程 (稱為 Data Wrangler 任務)。
-
儲存資料流程。選取檔案,然後選取儲存 Data Wrangler 流程。
-
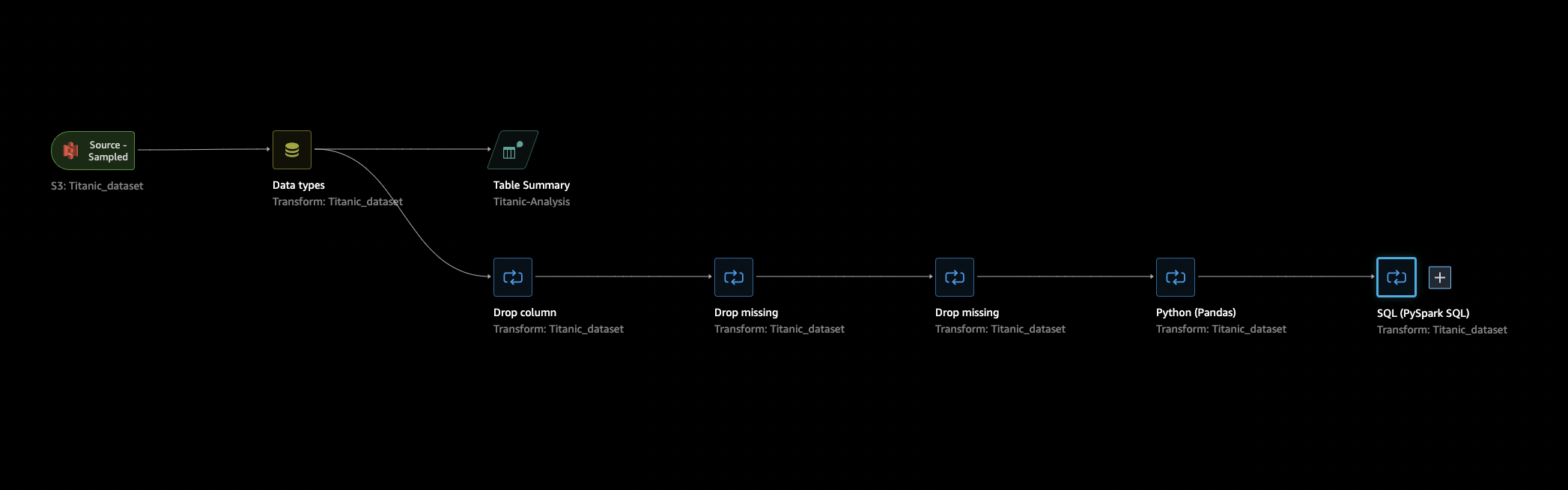
傳回資料流程索引標籤,選取資料流程 (SQL) 中的最後一個步驟,然後選擇 + 以開啟導覽。
-
選擇匯出和 Amazon S3 (透過 Jupyter 筆記本)。這會開啟 Jupyter 筆記本。
-
為核心選擇任何 Python 3 (資料科學) 核心。
-
核心啟動時,執行筆記本書中的儲存格,直到啟動 SageMaker 訓練任務 (選用)。
-
或者,如果您想要建立 SageMaker AI 訓練任務來訓練 XGBoost 分類器,您可以在啟動 SageMaker 訓練任務 (選用)中執行儲存格。您可以找到執行 SageMaker 訓練工作的成本,請參閱 Amazon SageMaker 定價
。 或者,您可以將在訓練 XGBoost 分類器中找到的程式碼區塊新增至筆記本,然後執行,以使用 XGBoost
開放原始碼程式庫來訓練 XGBoost 分類器。 -
取消註解並在清理下執行儲存格,然後執行該儲存格,以將 SageMaker Python SDK 還原為其原始版本。
您可以在 SageMaker AI 主控台的處理索引標籤中監控 Data Wrangler 任務狀態。此外,您也可以使用 Amazon CloudWatch 監控您的 Data Wrangler 任務。有關其他資訊,請參閱使用 CloudWatch Logs 和指標監控 Amazon SageMaker 處理作業。
如果您開始執行訓練任務,您可以使用 SageMaker AI 主控台在訓練區段的訓練任務下監視其狀態。
訓練 XGBoost 分類器
您可以使用 Jupyter 筆記本或 Amazon SageMaker Autopilot 訓練 XGBoost 二進位分類器。您可以使用 Autopilot 來自動訓練和微調模型,這些模型是根據您的 Data Wrangler 流程中轉換的資料而來。若要取得有關 Autopilot 的更多資訊,請參閱在資料流程上自動訓練模型。
在啟動 Data Wrangler 任務的同一筆記本中,您可以提取資料,並使用準備好的資料以最小化的資料準備方式,來訓練 XGBoost 二進位分類器。
-
首先,使用
pip升級必要的模組,並移除 _SUCCESS 文件 (當使用awswrangler時,這個檔案會造成問題)。! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
從 Amazon S3 讀取資料。您可以使用
awswrangler遞迴讀取 S3 字首中的所有 CSV 文件。然後將資料分割為功能和標籤。標籤是資料框的首欄。import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
最後,建立 DMatrices (XGBoost 的基本資料結構),並使用 XGBoost 二進制分類進行交叉驗證。
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
關閉 Data Wrangler
當您完成使用 Data Wrangler 後,我們建議您關閉其執行的執行個體,以避免產生額外費用。要瞭解如何關閉 Data Wrangler 應用程式和關聯的執行個體,請參閱關閉 Data Wrangler。
