本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
視覺化 TensorBoard 中的 Amazon SageMaker Debugger 輸出張量
重要
此頁面已棄用,以支持 Amazon SageMaker AI 搭配 TensoBoard,它提供與 SageMaker Training 整合的全面 TensorBoard 體驗,以及 SageMaker AI 網域的存取控制功能。如需進一步了解,請參閱 Amazon SageMaker AI 中的 TensorBoard 。
使用 SageMaker Debugger,建立與 TensorBoard 相容的輸出張量檔案。載入要在 TensorBoard 中視覺化的檔案,並分析您的 SageMaker 訓練任務。偵錯工具會自動產生與 TensorBoard 相容的輸出張量檔案。對於您為儲存輸出張量自訂的任何勾點組態,偵錯工具可以彈性建立純量摘要、分佈和長條圖,供您匯入至 TensorBoard。
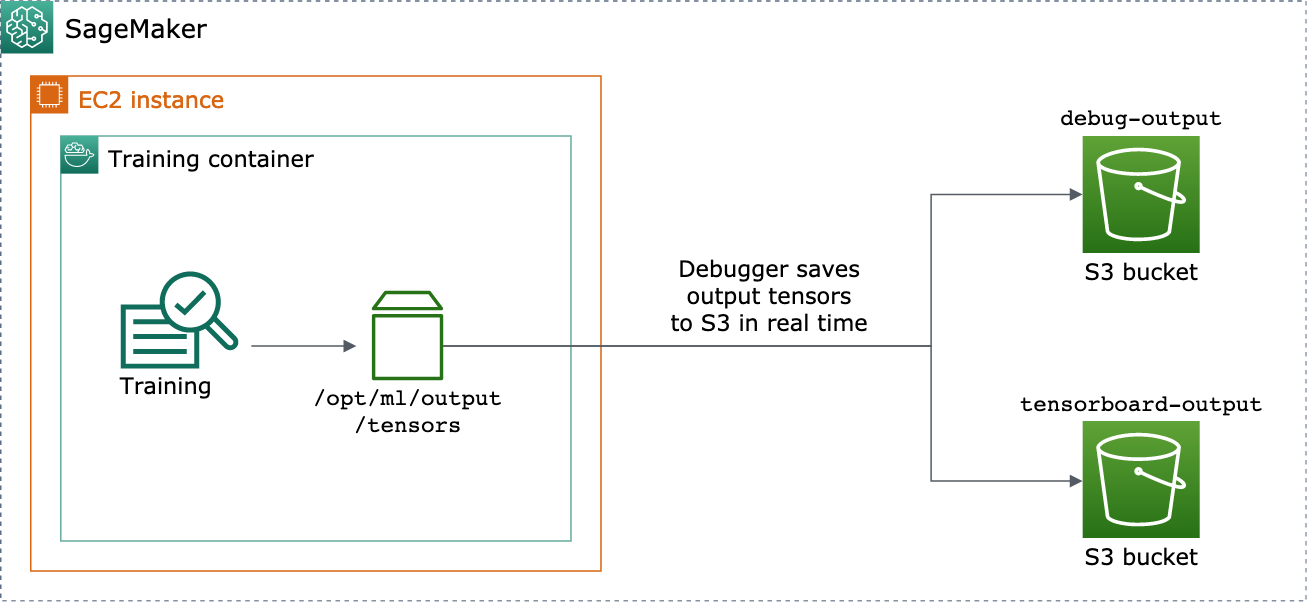
您可以透過傳遞 DebuggerHookConfig 和 TensorBoardOutputConfig 物件給 estimator 來啟用。
下列程序說明如何將純量、權重和偏差儲存為可透過 TensorBoard 視覺化的完整張量、長條圖和分佈。Debugger 會將它們儲存到訓練容器的本機路徑 (預設路徑為 /opt/ml/output/tensors),並同步至透過偵錯程式輸出組態物件傳遞的 Amazon S3 位置。
若要使用偵錯工具儲存 TensorBoard 相容的輸出張量檔案
-
使用偵錯工具
TensorBoardOutputConfig類別,設定tensorboard_output_config組態物件,以儲存 TensorBoard 輸出。針對s3_output_path參數,指定目前 S3 SageMaker AI 工作階段的預設 S3 儲存貯體或偏好的 S3 儲存貯體。此範例不會新增container_local_output_path參數,而是將其設定為預設本機路徑/opt/ml/output/tensors。import sagemaker from sagemaker.debugger import TensorBoardOutputConfig bucket = sagemaker.Session().default_bucket() tensorboard_output_config = TensorBoardOutputConfig( s3_output_path='s3://{}'.format(bucket) )有關其他資訊,請參閱 Debugger
TensorBoardOutputConfigAPI 中的 Amazon SageMaker Python SDK。 -
設定偵錯工具勾點,並自訂勾點參數值。例如,下列程式碼會設定偵錯工具勾點,以在訓練階段每 100 個步驟和驗證階段每 10 個步驟儲存所有純量輸出、每 500 個步驟
weights參數 (儲存張量集合的預設save_interval值為 500),以及每 10 個全域步驟bias參數,直到全域步驟達到 500 個。from sagemaker.debugger import CollectionConfig, DebuggerHookConfig hook_config = DebuggerHookConfig( hook_parameters={ "train.save_interval": "100", "eval.save_interval": "10" }, collection_configs=[ CollectionConfig("weights"), CollectionConfig( name="biases", parameters={ "save_interval": "10", "end_step": "500", "save_histogram": "True" } ), ] )有關 Debugger 組態 API 的詳細資訊,請參閱 Amazon SageMaker Python SDK
中的 Debugger CollectionConfig和DebuggerHookConfigAPI。 -
使用傳遞組態物件的 Debugger 參數來建構 SageMaker AI 估算器。下列範例範本示範如何建立一般 SageMaker AI 估算器。您可以使用其他 SageMaker AI 架構的估算器父類別和估算器類別
estimatorEstimator來取代 和 。此功能的可用 SageMaker AI 架構估算器為TensorFlow、PyTorch和MXNet。from sagemaker.estimatorimportEstimatorestimator =Estimator( ... # Debugger parameters debugger_hook_config=hook_config, tensorboard_output_config=tensorboard_output_config ) estimator.fit()此
estimator.fit()方法會啟動訓練任務,偵錯工具會即時將輸出張量檔案寫入偵錯工具 S3 輸出路徑和 TensorBoard S3 輸出路徑。若要擷取輸出路徑,請使用下列估算方法:-
對於偵錯工具 S3 輸出路徑,請使用
estimator.latest_job_debugger_artifacts_path()。 -
對於 TensorBoard S3 輸出路徑,請使用
estimator.latest_job_tensorboard_artifacts_path()。
-
-
訓練完成後,請檢查儲存的輸出張量名稱:
from smdebug.trials import create_trial trial = create_trial(estimator.latest_job_debugger_artifacts_path()) trial.tensor_names() -
檢視 Amazon S3 中的 TensorBoard 輸出資料:
tensorboard_output_path=estimator.latest_job_tensorboard_artifacts_path() print(tensorboard_output_path) !aws s3 ls {tensorboard_output_path}/ -
將 TensorBoard 輸出資料下載至您的筆記本執行個體。例如,下列 AWS CLI 命令會將 TensorBoard 檔案下載到筆記本執行個體的目前工作目錄
/logs/fit下。!aws s3 cp --recursive {tensorboard_output_path}./logs/fit -
將檔案目錄壓縮為 TAR 檔案,以下載至您的本機機器。
!tar -cf logs.tar logs -
將 Tensorboard TAR 檔案下載並解壓縮至裝置上的目錄、啟動 Jupyter Jupyter 筆記本伺服器、開啟新筆記本,然後執行 TensorBoard 應用程式。
!tar -xf logs.tar %load_ext tensorboard %tensorboard --logdir logs/fit
下列動畫螢幕擷取畫面示範步驟 5 到 8。將示範如何下載偵錯工具 TensorBoard TAR 檔案,並將檔案載入本機裝置上的 Jupyter 筆記本中。