本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
碎片資料平行處理
碎片資料平行處理是節省記憶體的分散式訓練技術,可將模型狀態 (模型參數、漸層與最佳化工具狀態) 分割到資料平行群組的 GPU。
注意
碎片資料平行處理適用 SageMaker 模型平行處理程式庫 v1.11.0 及更高版本的 PyTorch。
當縱向擴展訓練任務到大型 GPU 叢集時,您可以透過碎片化模型的訓練狀態至多個 GPU 來減少模型的每個 GPU 記憶體的使用量。這會帶來兩個優點:您可以容納較大模型 (否則會耗盡標準資料平行處理的記憶體),或者可以使用釋放的 GPU 記憶體來增加批次大小。
標準資料平行處理技術會複寫訓練狀態至資料平行群組的 GPU,並基於 AllReduce 作業執行漸層彙總。碎片資料平行處理會修改標準資料平行分散式訓練程序,以說明最佳化工具狀態的碎片性質。模型與最佳化工具狀態用以碎片化的一組等級稱為碎片群組。碎片資料平行處理技術會碎片化模型的可訓練參數、對應漸層以及最佳化工具狀態至碎片群組的 GPU。
SageMaker AI 透過實作 MiCS 來實現碎片資料平行處理,這在巨型模型訓練的 AWSAllGather 作業暫時重新組合所有 GPU 的模型參數。在每一層的向前或向後傳遞之後,MiCS 會再次碎片化參數以節省 GPU 記憶體。在向後傳遞期間,MiCS 會縮減漸層,並透過 ReduceScatter 作業同時將其碎片化到各 GPU。最後,MiCS 會使用最佳化工具狀態的本機碎片,套用本機的縮減及碎片漸層至其對應本機參數碎片。為降低通訊額外負荷,SageMaker 模型平行處理程式庫會在向前或向後傳遞階段預先擷取即將發生的圖層,並重疊網路通訊與運算。
模型的訓練狀態會跨碎片群組複寫。這表示在將漸層套用至參數之前,除在碎片群組進行的 AllReduce 作業之外,還必須在碎片群組進行 ReduceScatter 作業。
實際上,碎片資料平行處理必須在通訊額外負荷與 GPU 記憶體效率之間做取捨。使用碎片資料平行處理會增加通訊成本,然而每個 GPU 的記憶體使用量 (排除因啟用而導致的記憶體使用量) 會除以碎片資料平行處理程度,因此較大模型可納入 GPU 叢集。
選取碎片資料平行處理程度
當您針對碎片資料平行處理程度選取值時,該值必須能平均除碎片資料平行處理程度。例如,對於 8 向資料平行處理工作,請選擇 2、4 或 8 做為碎片資料平行處理程度。在選擇碎片資料平行處理程度時,建議您從小數字開始,然後逐漸增加,直到模型與所需的批次大小可一起放入記憶體。
選取批次大小
在設定碎片資料平行處理之後,請確定您找到可在 GPU 叢集成功執行的最佳訓練組態。若要訓練大型語言模型 (LLM),請從批次大小 1 開始,然後逐漸增加,直到您收到記憶體不足 (OOM) 錯誤為止。如果即使最小批次大小也遇到 OOM 錯誤,請套用較高程度的碎片資料平行處理,或是組合碎片資料平行處理與張量平行處理。
如何套用碎片資料平行處理至訓練任務
若要開始使用碎片資料平行處理,請套用必要修改至訓練指令碼,並使用碎片資料平行處理特定參數來設定 SageMaker PyTorch 估算器。同時請考慮以參考值與範例筆記本為起點。
調整 PyTorch 訓練指令碼
遵循步驟 1:修改 PyTorch 訓練指令碼的指示,使用 torch.nn.parallel 與 torch.distributed 模組的 smdistributed.modelparallel.torch 包裝函式來包裝模型與最佳化工具物件。
(選用) 註冊外部模型參數的其他修改
如果您的模型是以 torch.nn.Module 構建,且使用未在模組類別內定義的參數,則應手動將其註冊到模組,以便 SMP 可收集完整參數。若要將參數註冊到模組,請使用 smp.register_parameter(module,
parameter)。
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
設定 SageMaker PyTorch 估算器
在 步驟 2:使用 SageMaker Python SDK 啟動訓練任務 設定 SageMaker PyTorch 估算器時,請新增碎片資料平行處理的參數。
若要開啟碎片資料平行處理,請新增 sharded_data_parallel_degree 參數至 SageMaker PyTorch 估算器。此參數指定訓練狀態要碎片化的 GPU 數量。sharded_data_parallel_degree 的值必須為整數並介於 1 與資料平行處理程度之間,且必須能平均除資料平行處理程度。請注意,程式庫會自動偵測 GPU 數量,因而也會自動偵測資料平行程度。下列其他參數可用於設定碎片資料平行處理。
-
"sdp_reduce_bucket_size"(整數,預設值:5e8) — 以預設 dtype 的元素數量指定 PyTorch DDP 漸層儲存貯體的大小。 -
"sdp_param_persistence_threshold"(整數,預設值:1e6) — 針對可在每個 GPU 持續存在的元素數量指定參數張量大小。碎片資料平行處理會分割每個參數張量至資料平行群組的 GPU。如果參數張量的元素數量小於此閾值,則不會分割參數張量;這有助於減少通訊額外負荷,因為參數張量會跨資料平行 GPU 複寫。 -
"sdp_max_live_parameters"(整數,預設值:1e9) — 針對在向前與向後傳遞期間,可同時處於重新組合訓練狀態的參數指定其數量上限。當有效參數數量達到指定閾值時,使用AllGather作業擷取的參數會暫停。請注意,增加此參數會增加記憶體使用量。 -
"sdp_hierarchical_allgather"(boo l,預設值:True) — 如果設定為True,則AllGather作業會以階層方式執行:會先在每個節點內執行,然後跨節點執行。對於多節點分散式訓練任務,會自動啟用階層式AllGather作業。 -
"sdp_gradient_clipping"(浮動,預設值:1.0) — 針對剪輯 L2 標準的漸層指定閾值,然後再透過模型參數向後傳播漸層。當啟用碎片資料平行處理時,也會啟用漸層剪輯。預設閾值為1.0。如果您遇到漸層爆炸問題,請調整此參數。
下列程式碼範例顯示如何設定碎片資料平行處理。
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
參考組態
SageMaker分散式訓練團隊提供下列參考組態,您可以使用這些組態做為起點。您可以從下列組態推斷,以便針對模型組態進行實驗並估算 GPU 記憶體使用量。
搭配 SMDDP 集體的碎片資料平行處理
| 模型/參數量 | 執行個體數 | 執行個體類型 | 序列長度 | 全域批次大小 | 最小批次大小 | 碎片資料平行程度 |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
例如,如果增加 200 億個參數模型的序列長度,或增加模型大小到 650 億個參數,則需要先嘗試縮小批次大小。如果模型仍無法容納最小批次大小 (批次大小為 1),請嘗試增加模型平行處理程度。
搭配張量平行處理與 NCCL 集體的碎片資料平行處理
| 模型/參數量 | 執行個體數 | 執行個體類型 | 序列長度 | 全域批次大小 | 最小批次大小 | 碎片資料平行程度 | 張量平行程度 | 啟用卸載 |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | Y |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | Y |
當您希望將大型語言模型 (LLM) 納入大型擴展叢集,同時使用具較長序列長度的文字資料時,合併使用碎片資料平行處理與張量平行處理很有幫助,因為這會導致使用較小批次大小,因而處理 GPU 記憶體使用量來針對較長文字序列訓練 LLM。如需進一步了解,請參閱 搭配張量平行處理的碎片資料平行處理。
如需案例研究、基準測試和更多組態範例,請參閱部落格文章 Amazon SageMaker AI 模型平行程式庫中的新效能改善
搭配 SMDDP 集體的碎片資料平行處理
SageMaker 資料平行處理程式庫提供針對 AWS 基礎設施最佳化的集體通訊基本概念 (SMDDP 集合)。其透過使用 Elastic Fabric Adapter (EFA)
注意
搭配 SMDDP 集體的碎片資料平行處理可在 SageMaker 模型平行處理程式庫 v1.13.0 及更高版本取得,以及 SageMaker 資料平行處理程式庫 1.6.0 及更高版本。另請參閲 Supported configurations,以便搭配 SMDDP 集體使用碎片資料平行處理。
在碎片資料平行處理 (這是大規模分散式訓練常用的技術),AllGather 集體用於重組碎片層參數,以便與 GPU 運算平行進行向前與向後傳遞運算。對於大型模型而言,重要的是應以有效率的方式執行 AllGather 作業,以利避免 GPU 瓶頸問題並降低訓練速度。當啟用碎片資料平行處理時,SMDDP 集體會進入這些關鍵效能 AllGather 集體,進而改善訓練輸送量。
搭配 SMDDP 集體一起進行訓練
當訓練任務已啟用碎片資料平行處理並符合時 Supported configurations,SMDDP 集體就會自動啟用。在內部,SMDDP Collectives 會將AllGather集體最佳化,以便在 AWS 基礎設施上執行,並針對所有其他集體回復至 NCCL。此外,在不支援的組態,所有集體 (包括 AllGather) 都會自動使用 NCCL 後端。
自 SageMaker 模型平行處理程式庫版本 1.13.0 起,已新增 "ddp_dist_backend" 參數至 modelparallel 選項。此設定參數的預設值為 "auto",其會盡可能使用 SMDDP 集體,否則會回復為 NCCL。若要強制程式庫一律使用 NCCL,請指定"nccl" 至 "ddp_dist_backend" 設定參數。
下列程式碼範例示範如何使用碎片資料平行處理與 "ddp_dist_backend" 參數 (依預設設定為 "auto",因此為選用新增) 來設定 PyTorch 估算器。
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
支援的組態
當符合下列所有組態需求時,會在訓練任務啟用 SMDDP 集體的 AllGather 作業。
-
碎片資料平行處理程度大於 1
-
Instance_count大於 1 -
Instance_type等於ml.p4d.24xlarge -
適用於 PyTorch v1.12.1 或更高版本的 SageMaker 訓練容器
-
SageMaker 資料平行處理程式庫 v1.6.0 或更高版本
-
SageMaker 模型平行處理程式庫 v1.13.0 或更高版本
效能與記憶體調整
SMDDP 集體利用其他 GPU 記憶體。根據不同模型訓練使用案例,有兩個環境變數可設定 GPU 記憶體使用量。
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES– 在 SMDDPAllGather作業期間,會複製AllGather輸入緩衝至暫時緩衝,以便進行節點間通訊。SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES變數控制此暫時緩衝的大小 (位元組)。如果暫時緩衝大小小於AllGather輸入緩衝大小,則AllGather集體會回復使用 NCCL。-
預設值:16 * 1024 * 1024 (16 MB)
-
可接受值:8192 的任何倍數
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES–SMDDP_AG_SORT_BUFFER_SIZE_BYTES變數用以調整暫時緩衝大小 (位元組),以便保存從節點間通訊收集的資料。如果此暫時緩衝大小小於1/8 * sharded_data_parallel_degree * AllGather input size,則AllGather集體會回復使用 NCCL。-
預設值:128 * 1024 * 1024 (128 MB)
-
可接受值:8192 的任何倍數
-
緩衝大小變數的調整指引
環境變數的預設值應適用於多數使用案例。建議僅當訓練出現記憶體不足 (OOM) 錯誤時,才調整這些變數。
下列清單將討論部分調整提示,以減少 SMDDP 集體的 GPU 記憶體使用量,同時保留因此取得的效能提升。
-
調校
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
對於較小模型,
AllGather輸入緩衝大小較小。因此,對於具較少參數的模型,SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES的所需大小可更小。 -
AllGather輸入緩衝大小會隨著sharded_data_parallel_degree增加而減少,因為模型會碎片化至更多 GPU。因此,對於具較大sharded_data_parallel_degree值的訓練任務,SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES的所需大小可更小。
-
-
調校
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
對於參數較少的模型,從節點間通訊收集的資料量會較少。因此,對於具較少參數數量的此類模型,
SMDDP_AG_SORT_BUFFER_SIZE_BYTES的所需大小可更小。
-
部分集體可能會回復使用 NCCL; 因此,您可能無法從最佳化的 SMDDP 集體獲得效能提升。如果有其他 GPU 記憶體可用,您可以考慮增加 SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES 與 SMDDP_AG_SORT_BUFFER_SIZE_BYTES 的值,以便從效能提升獲益。
下列程式碼示範如何針對 PyTorch 估算器附加環境變數至發佈參數的 mpi_options,藉此設定環境變數。
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
搭配碎片資料平行處理的混合精確度訓練
若要利用半精確度浮點數與碎片資料平行處理來進一步節省 GPU 記憶體,您可以新增單一其他參數至分散式訓練組態來啟用 16 位元浮點格式 (FP16) 或 Brain 浮點格式
注意
SageMaker 模型平行處理程度程式庫 v1.11.0 及更高版本提供搭配碎片資料平行處理的混合精確度訓練。
對於搭配碎片資料平行處理的 FP16 訓練
若要搭配碎片資料平行處理來執行 FP16 訓練,請新增 "fp16": True" 至 smp_options 組態字典。在訓練指令碼,您可以透過 smp.DistributedOptimizer 模組選擇靜態或動態損失縮放選項。如需更多資訊,請參閱使用模型平行處理進行 FP16 訓練。
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
對於搭配碎片資料平行處理的 BF16 訓練
SageMaker AI 的碎片資料平行處理功能支援 BF16 資料類型的訓練。BF16 資料類型使用 8 位元來表示浮點數的指數,而 FP16 資料類型則使用 5 位元。保留指數的 8 位元可針對 32 位元單一精確度浮點 (FP32) 數的指數保持相同表示法。這可簡化 FP32 與 BF16 之間的轉換,且可大幅減少在 FP16 訓練過程經常出現的溢位及下溢問題,尤其是在訓練大型模型時。儘管這兩種資料類型總共使用 16 位元,但 BF16 格式的指數表示法範圍會增加,而精確度則會降低。對於訓練大型模型,這種降低的精確度通常被認為是為取得範圍與訓練穩定性的可接受折衷。
注意
目前,僅當啟用碎片資料平行處理時,BF16 訓練才有效。
若要搭配碎片資料平行處理執行 BF16 訓練,請新增 "bf16": True 至 smp_options 組態字典。
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
搭配張量平行處理的碎片資料平行處理
如果您使用碎片資料平行處理,同時還需要減少全域批次大小,請考慮搭配碎片資料平行處理使用張量平行處理。在非常大型的運算叢集 (通常為 128 個節點或以上) 使用碎片資料平行處理來訓練大型模型時,即使每個 GPU 批次大小很小仍會產生非常大的全域批次大小。這可能導致收斂問題或低運算效能問題。當單一批次已經很大且無法進一步縮減時,僅使用碎片資料平行處理,有時無法縮減每個 GPU 的批次大小。在這種情況,結合使用碎片資料平行處理與張量平行處理有助於減少全域批次大小。
選擇最佳碎片資料平行與張量平行程度取決於模型規模、執行個體類型,以及對於模型收斂合理的全域批次大小。建議您從較低張量平行程度開始,以便將全域批次大小納入運算叢集,解決 CUDA 記憶體不足錯誤並達到最佳效能。請參閱下列兩個範例案例,了解組合張量平行處理與碎片資料平行處理可如何協助您透過將 GPU 分組為模型平行處理來調整全域批次大小,進而產生較少的模型複本數量及較小全域批次大小。
注意
您可從 SageMaker 模型平行處理程式庫 1.15 取得此功能,並支援 PyTorch 第 1.13.1 版。
注意
此功能可透過程式庫的張量平行處理功能用於支援模型。若要尋找支援模型清單,請參閱對 Hugging Face 轉換器模型支援。另請注意,在修改訓練指令碼時,您需要傳遞 tensor_parallelism=True 至 smp.model_creation 引數。若要進一步了解,請參閱 SageMaker AI 範例 GitHub 儲存庫train_gpt_simple.py
範例 1
假設我們要在 1536 個 GPU 的叢集訓練模型 (192 個節點各有 8 個 GPU),設定碎片資料平行處理程度為 32 (sharded_data_parallel_degree=32),且每個 GPU 的批次大小為 1,其中每個批次的序列長度為 4096 個權杖。在這種情況,有 1536 個模型複本,全域批次大小變成 1536 個,每個全域批次包含約 600 萬個權杖。
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
新增張量平行處理至其中可降低全域批次大小。組態範例之一可以是設定張量平行程度為 8,而每個 GPU 的批次大小為 4。這會形成 192 個張量平行群組或 192 個模型複本,其中每個模型複本發佈至 8 個 GPU。批次大小 4 是每個反覆項目與每個張量平行群組的訓練資料量;也就是說,每個模型複本每次反覆會取用 4 個批次。在這種情況,全域批次大小變為 768,而每個全域批次包含約 300 萬個權杖。因此,相較於先前案例僅採用碎片資料平行處理,全域批次大小減少一半。
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
範例 2
當同時啟用碎片資料平行處理與張量平行處理時,程式庫會先套用張量平行處理並跨此維度來碎片化模型。對於每個張量平行等級,會按照每個 sharded_data_parallel_degree 來套用資料平行處理。
例如,假設我們想要設定 32 個 GPU,張量平行程度為 4 (形成 4 個 GPU 的群組),碎片資料平行程度為 4,最後複寫度為 2。此指派會基於張量平行程度建立八個 GPU 群組,如下所示:(0,1,2,3)、(4,5,6,7)、(8,9,10,11)、(12,13,14,15)、(16,17,18,19)、(20,21,22,23)、(24,25,26,27)、(28,29,30,31)。也就是說,四個 GPU 會形成單一張量平行群組。在這種情況,張量平行群組第 0 級 GPU 所縮減的資料平行群組將是 (0,4,8,12,16,20,24,28)。縮減資料平行群組會基於碎片資料平行程度 4 進行碎片化,進而產生兩個資料平行處理的複寫群組。GPU (0,4,8,12) 形成單一碎片群組,該群組針對第 0 級張量平行集體保存所有參數的完整副本,且 GPU (16,20,24,28) 會形成另一此類群組。其他張量平行等級也有類似的碎片與複寫群組。
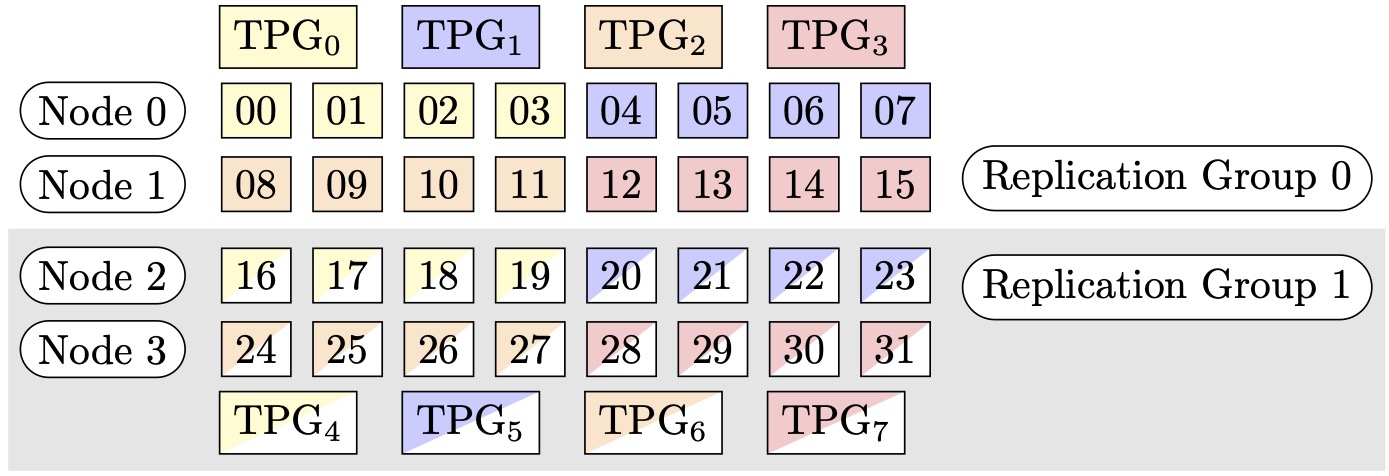
圖 1: (節點、碎片資料平行程度、張量平行程度) = (4、4、4) 的 Tensor 平行處理群組,其中每個矩形代表索引從 0 到 31 的 GPU。GPUs 會形成張量平行處理群組,從 TPG0 到 TPG7。複寫群組是 ({TPG0, TPG4}、{TPG1, TPG5}、{TPG2, TPG6} 和 {TPG3, TPG7});每個複寫群組對都共用相同的顏色,但填充不同。
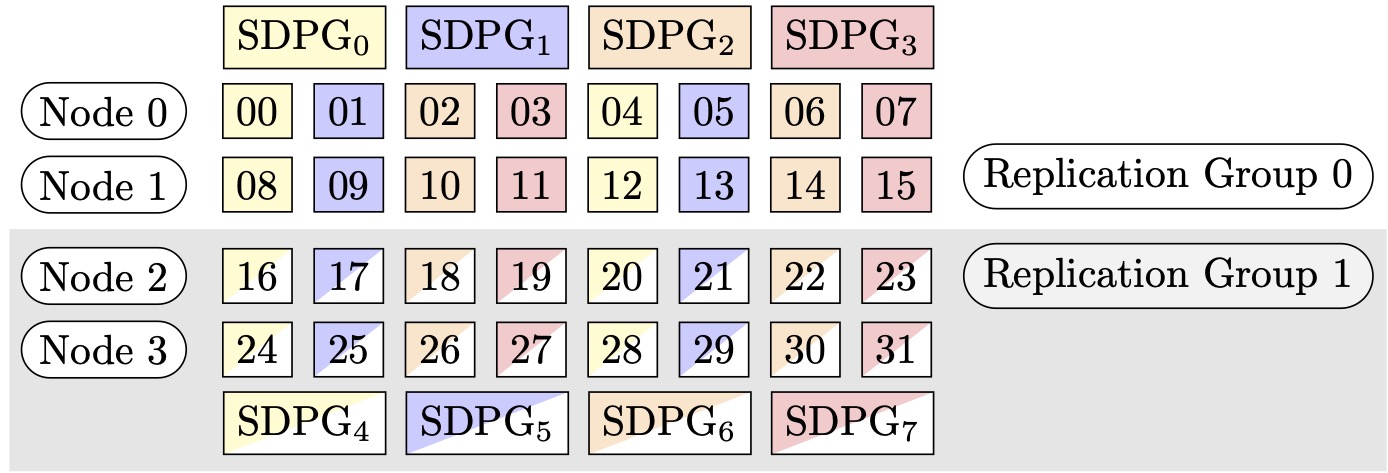
圖 2: 的陰影資料平行處理群組 (節點、碎片資料平行程度、張量平行程度) = (4、4、4),其中每個矩形代表索引從 0 到 31 的 GPU。GPUs 會形成從 SDPG0 到 SDPG 的碎片資料平行處理群組7。複寫群組是 ({SDPG0、SDPG4}、{SDPG1、SDPG5}、{SDPG2、SDPG6} 和 {SDPG3、SDPG7});每個複寫群組對都共用相同的顏色,但填充不同。
如何利用張量平行處理啟用碎片資料平行處理
若要利用張量平行處理使用碎片資料平行處理,則當建立 SageMaker PyTorch 估算器類別的物件時,您需要在設定 distribution 的同時設定 sharded_data_parallel_degree 與 tensor_parallel_degree。
您還需要啟用 prescaled_batch。這表示,每個張量平行群組都會集體讀取所選批次大小的合併批次,而非每個 GPU 各自讀取其批次資料。實際上,其不會將資料集分成等於 GPU 數量 (或資料平行大小 smp.dp_size()) 的部分,而是分成等於 GPU 數量除以 tensor_parallel_degree 的部分 (也稱為縮減資料平行大小 smp.rdp_size())。如需更多詳細資訊了解預先調整大小的批次,請參閱 SageMaker Python SDK 文件的預先調整大小的批次train_gpt_simple.py
下列程式碼片段為基於上述 範例 2 的案例,此範例顥示如何建立 PyTorch 估算器物件。
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
使用碎片資料平行處理的提示與考量事項
當使用 SageMaker 模型平行處理程式庫的碎片資料平行處理時,請考慮下列事項。
-
碎片資料平行處理相容 FP16 訓練。若要執行 FP16 訓練,請參閱使用模型平行處理進行 FP16 訓練區段。
-
碎片資料平行處理相容張量平行處理。以下是搭配張量平行處理使用碎片資料平行處理時,可能需要考慮的項目。
-
當搭配張量平行處理使用碎片資料平行處理時,內嵌層也會自動發佈至張量平行群組。換句話說,
distribute_embedding參數會自動設定為True。如需張量平行處理的更多相關資訊,請參閱張量平行處理。 -
請注意,搭配張量平行處理的碎片資料平行處理目前會使用 NCCL 集體做為分散式訓練策略的後端。
如需進一步了解,請參閱搭配張量平行處理的碎片資料平行處理區段。
-
-
碎片資料平行處理目前不相容管道平行處理或最佳化工具狀態碎片。若要啟用碎片資料平行處理,請關閉最佳化工具狀態碎片,並設定管道平行程度為 1。
-
若要搭配漸層累積使用碎片資料平行處理,請在使用
smdistributed.modelparallel.torch.DistributedModel模組包裝模型時,設定 backward_passes_per_step引數為累積步驟數。這可確保模型複寫群組 (碎片群組) 之間的漸層AllReduce作業發生在漸層累積的範圍。 -
您可以使用程式庫的檢查點 API
smp.save_checkpoint與smp.resume_from_checkpoint來檢查使用碎片資料平行處理訓練的模型。如需更多資訊,請參閱對分散式 PyTorch 模型執行檢查點 (適用於 SageMaker 模型平行處理程式庫 1.10.0 版及更新版本)。 -
delayed_parameter_initialization設定參數的行為會在碎片資料平行處理下發生變更。當同時開啟這兩項功能時,參數會在建立模型時立即以碎片方式初始化,而不會延遲參數初始化,以便每個等級初始化並儲存各自的參數碎片。 -
當啟用碎片資料平行處理時,在呼叫
optimizer.step()時,程式庫會在內部執行漸層剪輯。您不需要使用公用程式 API 進行漸層剪輯,例如torch.nn.utils.clip_grad_norm_()。若要調整漸層剪輯的閾值,您可以在建構 SageMaker PyTorch 估算器時透過發佈參數組態的 sdp_gradient_clipping參數來加以設定,如 如何套用碎片資料平行處理至訓練任務 區段所示。
