本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
模型平行處理簡介
模型平行處理原則是一種分散式訓練方法,深度學習模型會在多個裝置間分割,不論是在執行個體內部或執行個體間皆如此。此簡介頁面提供有關模型平行處理原則的高階概觀、說明它如何協助克服訓練通常非常大的 DL 模型時所產生的問題,以及 SageMaker 模型平行程式庫所提供之協助管理模型平行策略以及記憶體使用的範例。
什麼是模型平行處理?
增加深度學習模型 (圖層和參數) 的大小可以為複雜的任務 (例如電腦視覺和自然語言處理) 提供更佳的準確性。不過,單一 GPU 記憶體可容納的最大模型大小有限制。訓練 DL 模型時,GPU 記憶體限制可能是瓶頸,狀況如下:
-
它們會限制您可以訓練的模型大小,因為模型的記憶體佔用量會與參數數量成比例擴展。
-
它們會在訓練期間限制每個 GPU 批次大小,進而降低 GPU 使用率和訓練效率。
為了克服在單一 GPU 上訓練模型的相關限制,SageMaker 提供了模型平行程式庫,以協助在多個運算節點上有效地分散和訓練 DL 模型。此外,借助該程式庫,您可以使用支援 EFA 的裝置實現最佳化的分散式訓練,這可以透過低延遲、高輸送量和作業系統規避來增強節點間通訊的效能。
使用模型平行處理之前預估記憶體
在您使用 SageMaker 模型平行程式庫之前,請考慮下列事項,以了解訓練大型 DL 模型的記憶體需求。
對於使用 AMP (FP16) 和 Adam 最佳化工具的訓練任務,每個參數所需的 GPU 記憶體大約為 20 位元組,我們可以按下列方式細分:
-
一個 FP16 參數約 2 位元組
-
一個 FP16 漸層約 2 位元組
-
基於 Adam 最佳化工具的 FP32 最佳化工具狀態約 8 位元組
-
參數的 FP32 副本約 4 位元組 (
optimizer apply(OA) 操作需要) -
漸層的 FP32 副本約 4 位元組 (OA 操作需要)
即使對於具有 100 億個參數的相對較小之 DL 模型,它至少需要 200GB 的記憶體,這比單一 GPU 上的一般 GPU 記憶體大得多 (例如,具有 40GB/80GB 記憶體的 NVIDIA A100,以及具有 16/32 GB 的 V100)。請注意,除了模型和最佳化工具狀態的記憶體需求之外,還有其他記憶體取用者,例如在轉送傳遞中產生的啟動。所需的記憶體可能大於 200GB。
對於分散式訓練,建議您分別使用具有 NVIDIA V100 和 A100 張量核心 GPU 的 Amazon EC2 P3 和 P4 執行個體。如需 CPU 核心、RAM、已連接的儲存磁碟區和網路頻寬等規格的詳細資訊,請參閱 Amazon EC2 執行個體類型
即使使用加速運算執行個體,明顯將了解具有大約 100 億個參數 (例如 Megatron-LM 和 T5) 的模型,甚至是具有數千億個參數 (例如 GPT-3) 的大型模型,也無法在每個 GPU 裝置中使用模型複本。
程式庫如何運用模型平行處理與記憶體節省技術
該程式庫包含各種類型的模型平行處理功能和記憶體節省功能,例如最佳化工具狀態碎片、啟動檢查點、啟動卸載。所有這些技術都可以結合起來,以有效率地訓練包含數千億個參數的大型模型。
主題
碎片資料平行處理 (適用於 PyTorch)
碎片資料平行處理是一種節省記憶體的分散式訓練技術,可將模型狀態 (模型參數、漸層和最佳化工具狀態) 分割到資料平行群組中的 GPU。
SageMaker AI 透過實作 MiCS 來採用碎片資料平行化,MiCS 是一款程式庫,可讓您最小化通訊規模,並在關於 AWS巨型模型訓練的近線性擴展部落格文章中討論那樣進行處理
您可以將碎片資料平行處理套用至模型,以作為獨立的策略。此外,如果您使用的是配有 NVIDIA A100 張量核心 GPU 的最高效能 GPU 執行個體 (ml.p4d.24xlarge),您可以利用 SMDDP 系列產品提供的 AllGather 操作來提升訓練速度。
若要深入了解碎片資料平行處理,並學習如何設定資料,或結合使用碎片資料平行處理與其他技術 (例如張量平行處理和 FP16 訓練),請參閱碎片資料平行處理。
管道平行處理 (適用於 PyTorch 和 TensorFlow)
管道平行處理會跨裝置集合分割一組層或作業,讓每個作業完好無缺。當您指定模型分割區數量 (pipeline_parallel_degree) 的值時,GPU 的總數量 (processes_per_host) 必須可由模型分割區的數量整除。若要正確設定,您必須指定正確的 pipeline_parallel_degree 和 processes_per_host 參數值。簡單的數學原理如下:
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
在特定您提供的兩個輸入參數的情況下,該程式庫負責計算模型複本的數量 (亦稱為 data_parallel_degree)。
例如,如果您設定 "pipeline_parallel_degree": 2 和 "processes_per_host": 8 以使用具有八個 GPU 工作者的機器學習 (ML) 執行個體 (例如 ml.p3.16xlarge),則程式庫會自動跨 GPU 和四向資料平行處理設定分散式模型。下列影像說明模型如何在八個 GPU 上分散,以達到四向資料平行處理和雙向管道平行處理。每個模型複本,我們將其定義為管道平行群組並將其標籤為 PP_GROUP,且跨兩個 GPU 進行分割。模型的每個分割區都會指派給四個 GPU,其中四個分割區複本位於資料平行群組中並標示為 DP_GROUP。如果沒有張量平行處理,管道平行群組本質上就是模型平行群組。
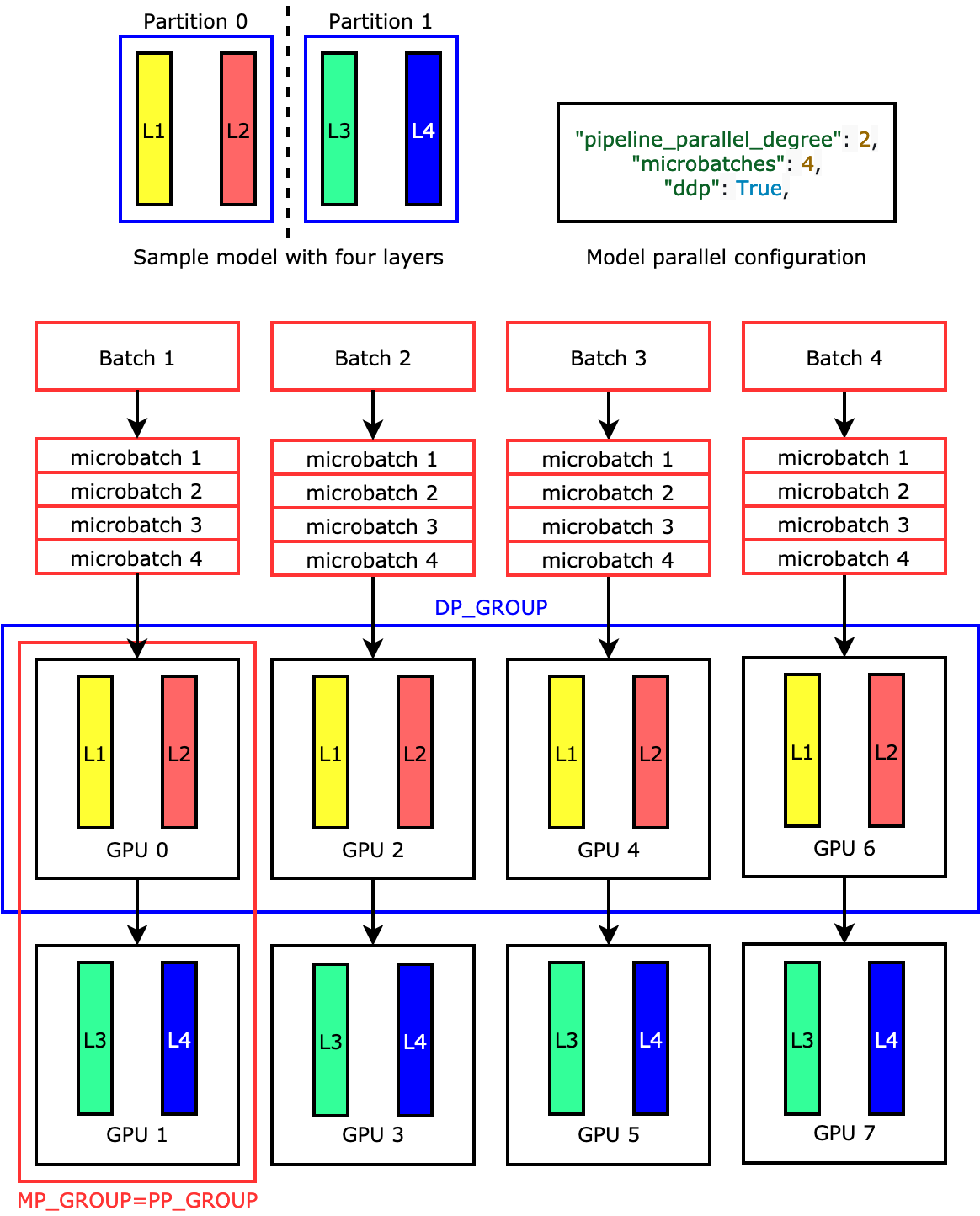
若要深入了解管道平行處理,請參閱SageMaker 模型平行化程式庫的核心功能。
若要開始使用管道平行處理來執行模型,請參閱使用 SageMaker 模型平行程式庫執行 SageMaker 分散式訓練任務。
張量平行處理 (適用於 PyTorch)
張量平行處理會跨裝置將各個層或 nn.Modules 分割,藉此平行執行。下圖顯示最簡單的範例,說明程式庫如何將模型分割成四層,以達到雙向張量平行處理 ("tensor_parallel_degree": 2)。每個模型複本的層會均分並分散為兩個 GPU。在這個範例中,模型平行設定也包含 "pipeline_parallel_degree": 1 和 "ddp": True (在背景中使用 PyTorch DistributedDataParallel 套件),因此資料平行處理的程度會變成 8。程式庫會管理張量分散式模型複本之間的通訊。
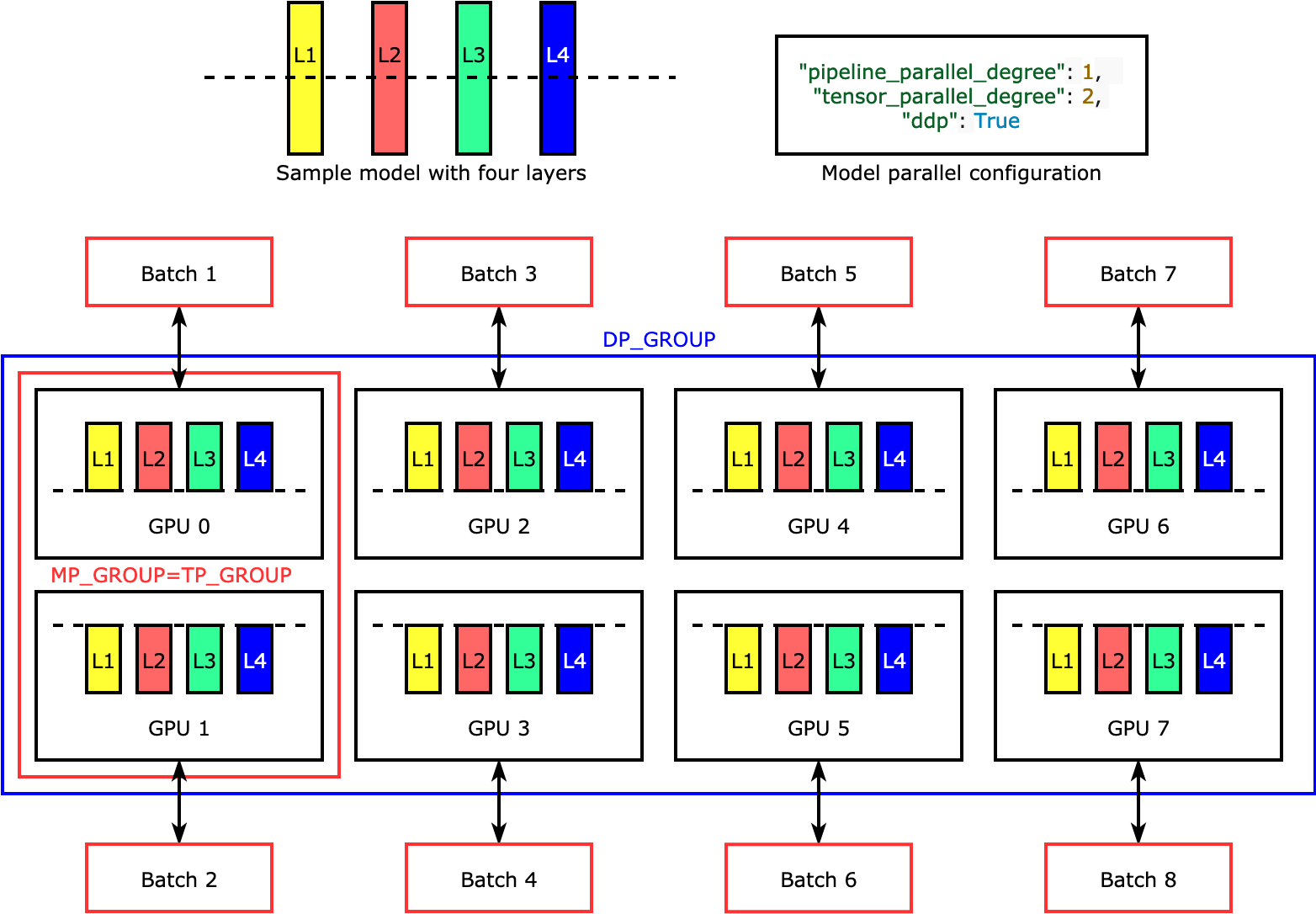
此功能的實用性在於您可以選取特定的層或層子集,藉此套用張量平行處理。若要深入了解 PyTorch 的張量平行處理和其他可節省記憶體的功能,並探究如何設定管道和張量平行處理的組合,請參閱張量平行處理。
最佳化工具狀態碎片 (適用於 PyTorch)
如要了解程式庫如何執行最佳化工具狀態碎片,不妨參考一個具有四層的簡單範例模型。最佳化狀態碎片的關鍵概念是,您不必在所有 GPU 中複製最佳化工具的狀態。相反地,最佳化工具狀態的單一複本會 data-parallel 等級進行資料分割,而不會跨裝置提供備援。例如,GPU 0 會保留第一層的最佳化工具狀態,下一個 GPU 1 會保留 L2 的最佳化工具狀態,依此類推。下列動畫圖顯示使用最佳化工具狀態碎片技術的向後傳播。在向後傳播結束時,optimizer apply (OA) 作業會更新最佳化工具狀態的運算和網路時間,而 all-gather (AG) 作業則會更新下一次反覆運算的模型參數。最重要的是,reduce 作業可能會與 GPU 0 上的運算重疊,因此可提高記憶體效率,並且加快向後傳播的速度。在目前的實作中,AG 和 OA 作業不會與 compute 重疊。這可能會導致在 AG 作業期間延伸運算,因此可能會有所取捨。
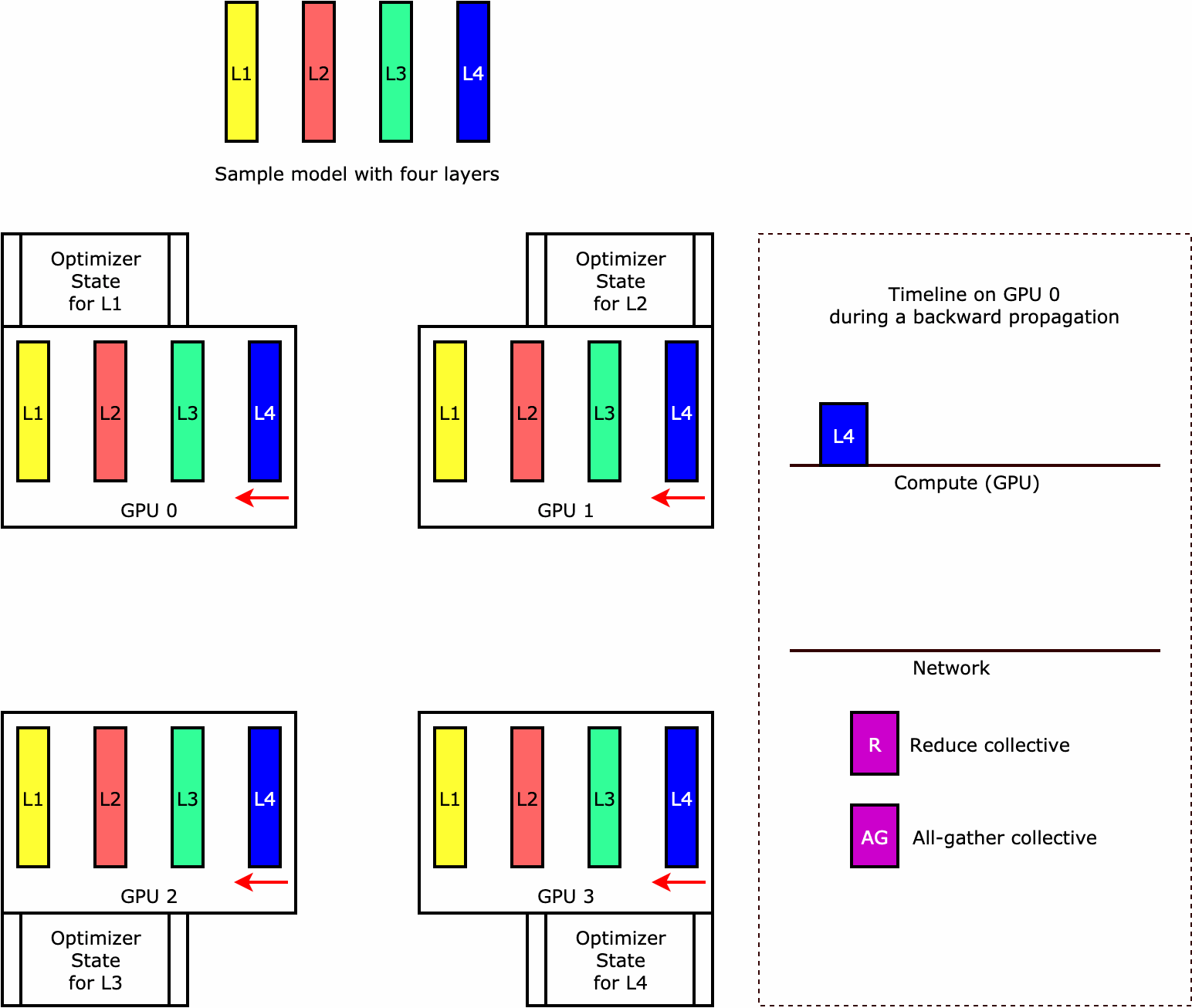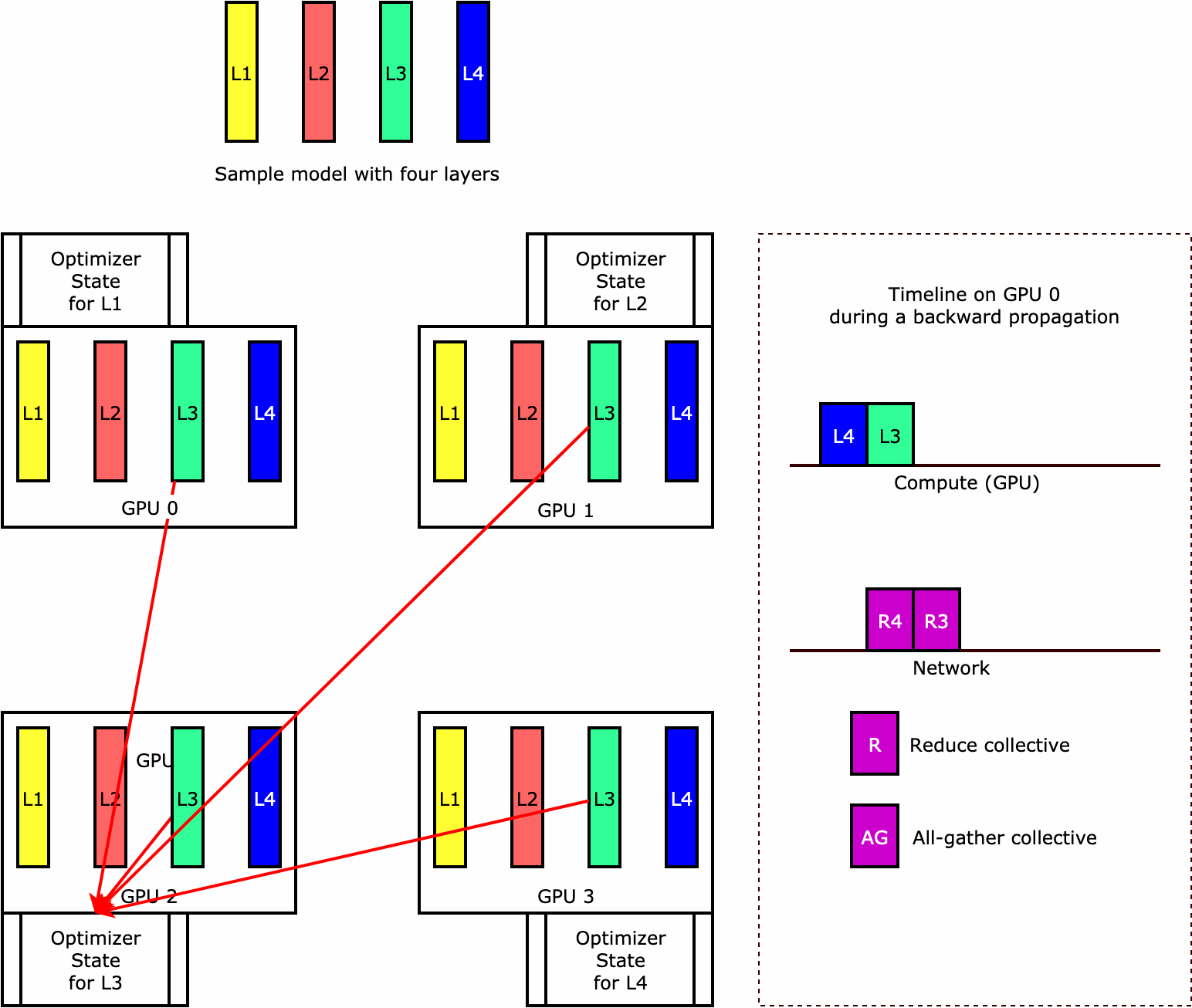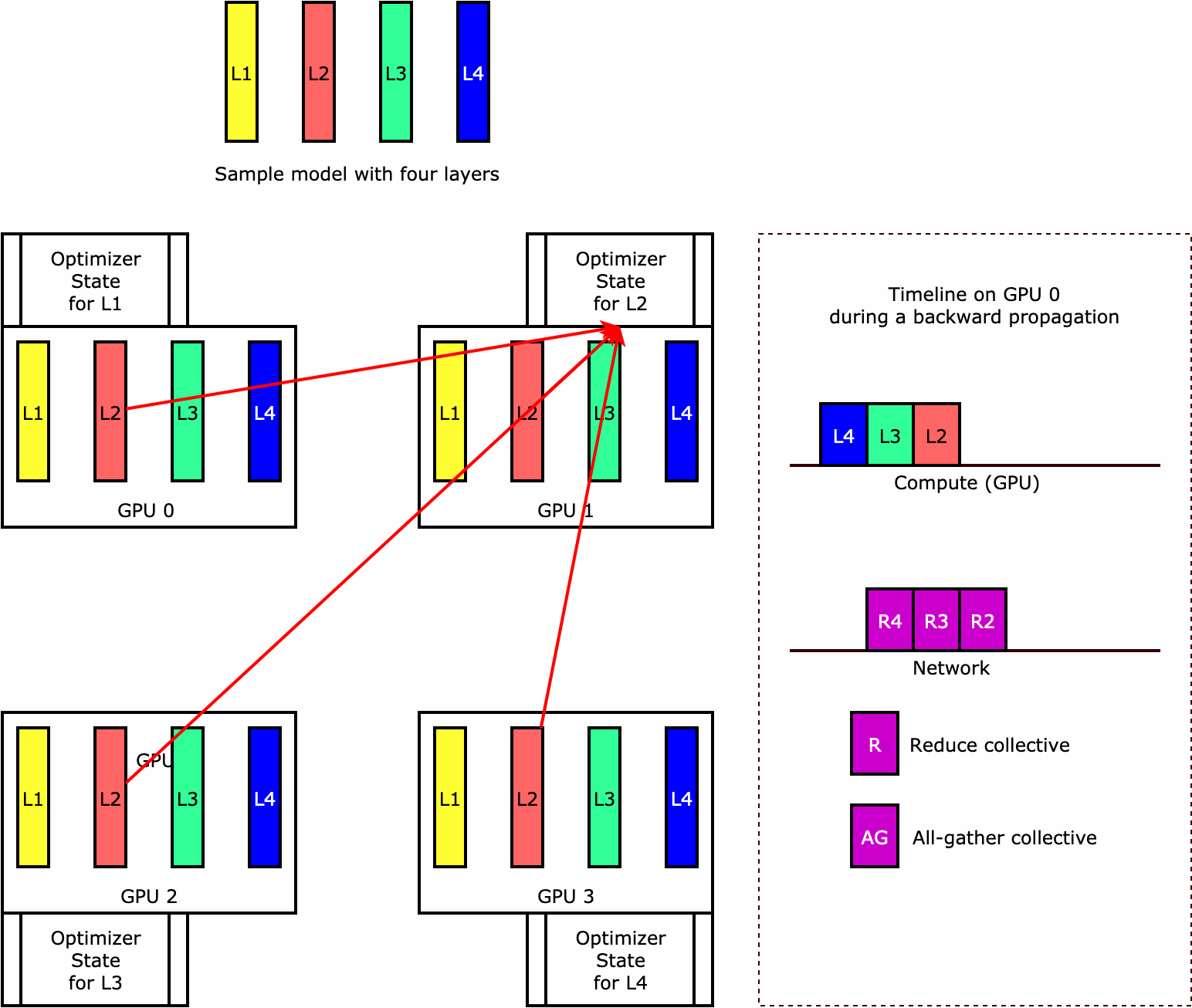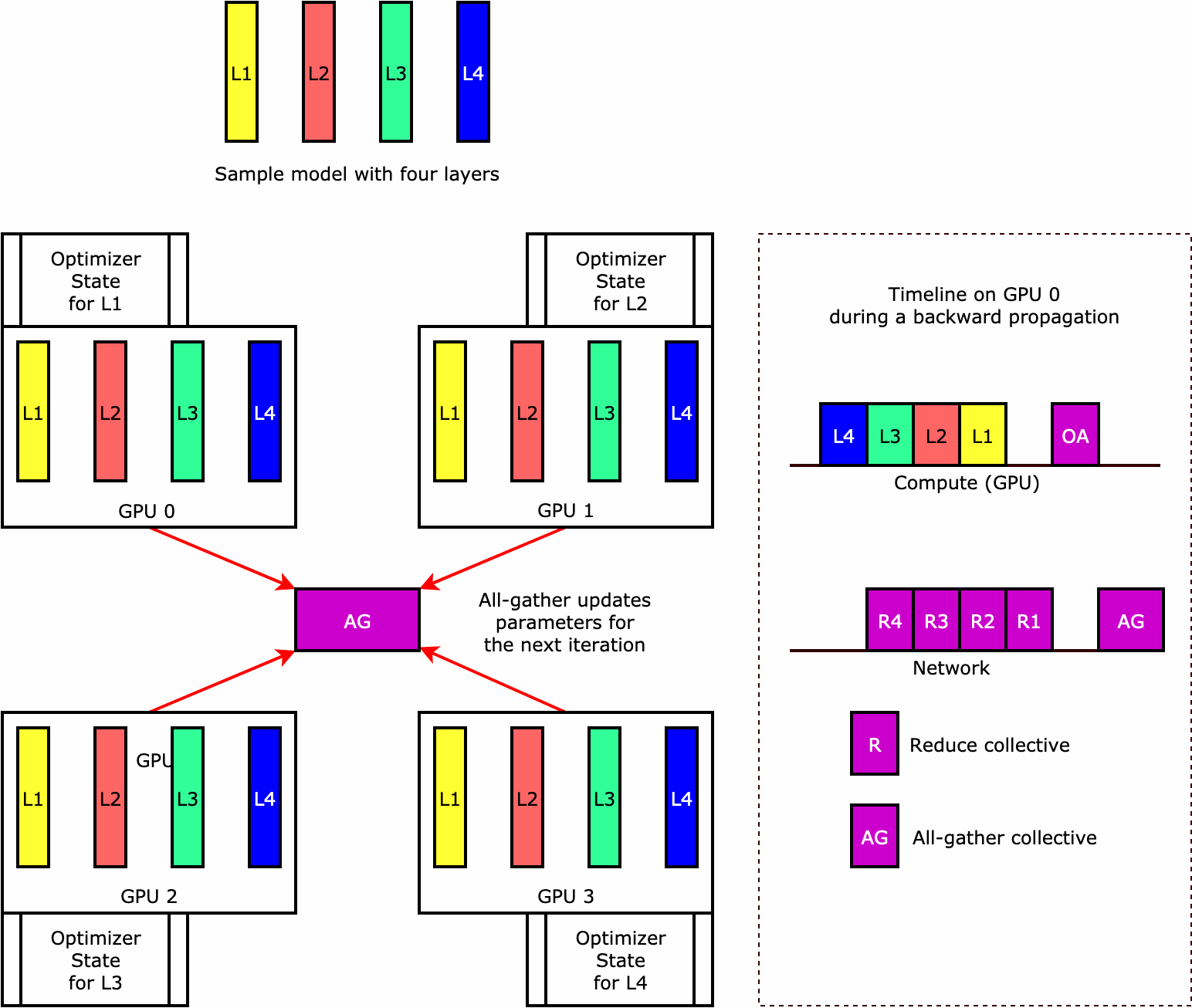
如需如何使用此功能的詳細資訊,請參閱最佳化工具狀態碎片。
啟動卸載和檢查點 (適用於 PyTorch)
為了節省 GPU 記憶體,程式庫支援啟動檢查點,以避免在轉送傳遞期間將內部啟動儲存在使用者指定的模組之 GPU 記憶體中。程式庫會在向後傳遞期間重新運算這些啟動項目。此外,啟動卸載功能會將儲存的啟動卸載至 CPU 記憶體,並在向後傳遞期間擷取回 GPU,進一步減少啟用記憶體佔用量。如需如何使用這些功能的詳細資訊,請參閱啟用檢查點和啟用卸載。
為您的模型選擇正確的技術
如需有關選擇正確技術和組態的詳細資訊,請參閱 SageMaker 分散式模型平行最佳實務和組態提示與陷阱。
