本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 SageMaker Processing 的資料轉換工作負載
SageMaker Processing 是指 SageMaker AI 在 SageMaker AI 全受管基礎設施上執行資料預先處理和後期處理、特徵工程和模型評估任務的功能。這些任務會做為處理任務來執行。以下的資訊和資源可供了解 SageMaker Processing。
使用 SageMaker Processing API,資料科學家可以執行指令碼和筆記本來處理、轉換和分析資料集,為機器學習做好準備。結合 SageMaker AI 提供的其他重要機器學習任務時 (例如訓練和託管),Processing 擁有全管理式機器學習環境的優點,包括 SageMaker AI 內建的所有安全性和合規性支援。您可以靈活地將內建的資料處理容器或使用自有容器用於自訂處理邏輯,然後提交任務以於 SageMaker AI 受管基礎設施上執行。
注意
您能夠以程式設計方式建立處理任務,方法是以 SageMaker AI 支援的任何語言或使用 AWS CLI來呼叫 CreateProcessingJob API 動作。有關此 API 動作如何以您選擇的語言轉換為函式的詳細資訊,請參閱 CreateProcessingJob 的另請參閱一節,並選擇 SDK。例如,對於 Python 使用者,請參閱 SageMaker Python SDK 的 Amazon SageMaker Processing
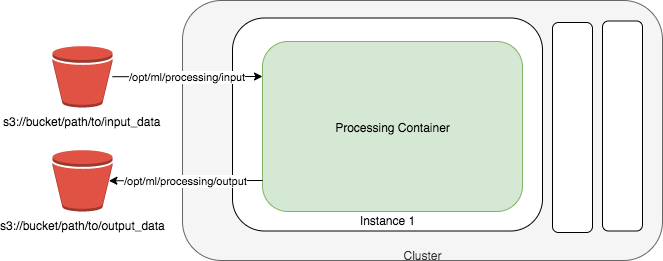
下圖顯示 Amazon SageMaker AI 如何加速處理任務。Amazon SageMaker AI 會從 Amazon Simple Storage Service (Amazon S3) 取得您的指令碼、複製資料,然後提取處理容器。處理任務的基礎設施由 Amazon SageMaker AI 完全管理。提交處理任務後,SageMaker AI 會啟動運算執行個體、處理和分析輸入資料,並在完成後釋放資源。處理任務的輸出會存放在您所指定的 Amazon S3 儲存貯體中。
注意
您的輸入資料必須存放在 Amazon S3 儲存貯體中。或者,您也可以使用 Amazon Athena 或 Amazon Redshift 作為輸入來源。
提示
若要了解適用於機器學習 (ML) 訓練和處理任務之分散式運算的最佳實務,請參閱SageMaker AI 分散式運算最佳實務。
使用 Amazon SageMaker Processing 範例筆記本
我們提供兩個範例 Jupyter 筆記本,說明如何執行資料預處理、模型評估或同時執行兩者。
如需了解示範如何使用適用於 Processing 之 SageMaker Python SDK 來執行 scikit-learn 指令碼,以執行預先處理資料、模型訓練與評估的範例筆記本,請參閱 scikit-learn Processing
如需了解示範如何使用 Amazon SageMaker Processing 搭配 Spark 執行分散式資料預先處理的範例筆記本,請參閱分散式處理 (Spark)
如需如何建立和存取 Jupyter 筆記本執行個體以用於 SageMaker AI 中執行範例的指示,請參閱 Amazon SageMaker 筆記本執行個體。建立並開啟筆記本執行個體後,請選擇 SageMaker AI 範例索引標籤,查看所有 SageMaker AI 範例清單。若要開啟筆記本,請選擇其使用標籤,然後選擇建立複本。
使用 CloudWatch 日誌和指標監控 Amazon SageMaker Processing 任務
Amazon SageMaker Processing 提供 Amazon CloudWatch 日誌和指標來監控處理任務。CloudWatch 提供 CPU、GPU、記憶體、GPU 記憶體和磁碟指標,以及事件記錄。如需詳細資訊,請參閱Amazon CloudWatch 中的 Amazon SageMaker AI 指標及Amazon SageMaker AI 的 CloudWatch Logs。
