本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
部署模型以進行即時推論
重要
允許 Amazon SageMaker Studio 或 Amazon 工作室經典版建立 Amazon SageMaker SageMaker 資源的自訂IAM政策還必須授予許可,才能將標籤新增到這些資源。需要向資源添加標籤的權限,因為 Studio 和 Studio 經典版會自動標記它們創建的任何資源。如果IAM原則允許 Studio 和 Studio 典型版建立資源,但不允許標記,則在嘗試建立資源時可能會發生 AccessDenied "" 錯誤。如需詳細資訊,請參閱提供標記 SageMaker資源的許可。
AWS Amazon 的受管政策 SageMaker授予建立 SageMaker 資源的權限,已包含在建立這些資源時新增標籤的權限。
有數個選項可以使用 SageMaker 託管服務部署模型。您可以使用 SageMaker Studio 以互動方式部署模型。或者,您可以透過程式設計方式部署模型 AWS SDK,例如 SageMaker Python SDK 或 Python (Boto3)。SDK您也可以使用 AWS CLI.
開始之前
在部署 SageMaker 模型之前,請找出並記下以下內容:
-
您 AWS 區域 的 Amazon S3 存儲桶所在的位置
-
儲存模型成品的 Amazon S3 URI 路徑
-
的IAM角色 SageMaker
-
包含推論程式碼的自訂映像檔的 Docker Amazon ECR URI 登錄路徑,或支援的內建 Docker 映像檔的架構和版本, AWS
如需每個項目中 AWS 服務 可用的清單 AWS 區域,請參閱區域對應和邊緣網路
重要
存放模型成品的 Amazon S3 儲存貯體必須與您建立的模型相同 AWS 區域 。
多個模型的共用資源使用率
您可以使用 Amazon 將一個或多個模型部署到端點 SageMaker。當多個模型共用一個端點時,它們會共同利用託管在該處的資源,例如 ML 運算執行個體和加速器。CPUs將多個模型部署到端點最靈活的方法是將每個模型定義為推論元件。
推論元件
推論元件是一種 SageMaker 託管物件,您可以用來將模型部署到端點。在推論元件設定中,您可以指定模型、端點,以及模型如何利用端點託管的資源。若要指定模型,您可以指定 SageMaker Model 物件,或直接指定模型人工因素和影像。
在設定中,您可以透過自訂必要CPU核心、加速器和記憶體配置給模型的方式來最佳化資源使用率。您可以將多個推論元件部署到端點,其中每個推論元件都包含一個模型,以及該模型的資源使用率需求。
部署推論元件之後,您可以在使用中的 InvokeEndpoint 動作時直接叫用相關模型。 SageMaker API
推論元件具有下列優點:
- 彈性
-
推論元件會將裝載模型與端點本身的詳細資訊分離出來。這提供了更大的靈活性和控制如何託管模型和與端點一起提供服務。您可以在相同的基礎結構上託管多個模型,並且可以視需要從端點新增或移除模型。您可以獨立更新每個模型。
- 可擴展性
-
您可以指定每個模型要做主體的複本數,並且可以設定最少複本數,以確保模型載入的數量符合您要求的數量。您可以將任何推論元件複本縮放到零,這樣可以有空間放大另一個複本。
SageMaker 當您使用下列項目部署模型時,將模型封裝為推論元件:
-
SageMaker 經典一室公寓.
-
SageMaker Python SDK 部署模型對象(在其中設置端點類型
EndpointType.INFERENCE_COMPONENT_BASED)。 -
AWS SDK for Python (Boto3) 定義您部署到端點的
InferenceComponent物件。
使用 SageMaker 工作室部署模型
完成下列步驟,透過 SageMaker Studio 以互動方式建立和部署模型。如需有關 Studio 的詳細資訊,請參閱 Studio 文件。有關各種部署案例的更多逐步解說,請參閱部落格 Package 和部署傳統機器學習模型,並使用 Amazon LLMs SageMaker 輕鬆
準備您的成品和權限
在 SageMaker Studio 中建立模型之前,請先完成本節。
您有兩個選項可讓您的工件和在 Studio 中建立模型:
-
您可以使用預先封裝的
tar.gz歸檔,其中應包含您的模型加工品、任何自訂推論程式碼,以及檔案中列出的任何相依性。requirements.txt -
SageMaker 可以為您打包您的工件。您只需要將原始模型加工品和任何相依性放在
requirements.txt檔案中,而且 SageMaker 可以為您提供預設的推論程式碼 (或者您可以使用您自己的自訂推論程式碼覆寫預設程式碼)。 SageMaker支援下列架構的此選項: PyTorch、XGBoost。
除了使用模型、 AWS Identity and Access Management (IAM) 角色和 Docker 容器 (或 SageMaker 具有預先建置容器的所需架構和版本) 之外,您還必須授予透過 SageMaker Studio 建立和部署模型的權限。
您應該將AmazonSageMakerFullAccess政策附加到您的IAM角色,以便您可以訪問 SageMaker 和其他相關服務。若要在 Studio 中查看執行個體類型的價格,您還必須附加AWS PriceListServiceFullAccess政策 (或者,如果您不想附加整個政策,更具體地說是pricing:GetProducts動作)。
如果您選擇在建立模型時上傳模型成品 (或上傳用於推論建議的範例承載檔案),則必須建立 Amazon S3 儲存貯體。值區名稱必須加上字SageMaker首。也可以接受的 SageMaker 替代資本化:Sagemaker或sagemaker。
建議您使用值區命名慣例sagemaker-{。此值區是用來儲存您上傳的成品。Region}-{accountID}
建立值區之後,請將下列 CORS (跨來源資源共用) 政策附加至值區:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
您可以使用下列任何一種方法將CORS政策附加到 Amazon S3 儲存貯體:
-
透過 Amazon S3 主控台中的編輯跨來源資源共用 (CORS)
頁面 -
使用 Amazon S3 API PutBucketCors
-
使用 put-bucket-cors AWS CLI 命令:
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
建立可部署模型
在此步驟中,您可以在中建立模型的可部署版本,方 SageMaker 法是提供成品以及其他規格,例如所需的容器和架構、任何自訂推論程式碼以及網路設定。
通過執行以下操 SageMaker 作在 Studio 中創建可部署的模型:
-
開啟 SageMaker 工作室應用程式。
-
在左側導覽窗格中選擇 Models (模型)。
-
選擇「可部署的模型」標籤。
-
在「可部署的模型」頁面上,選擇「建立」。
-
在「建立可部署模型」頁面的「模型名稱」欄位中,輸入模型的名稱。
您可以在「建立可建置的模型」頁面上填寫其他幾個段落。
容器定義部分看起來像下面的屏幕截圖:
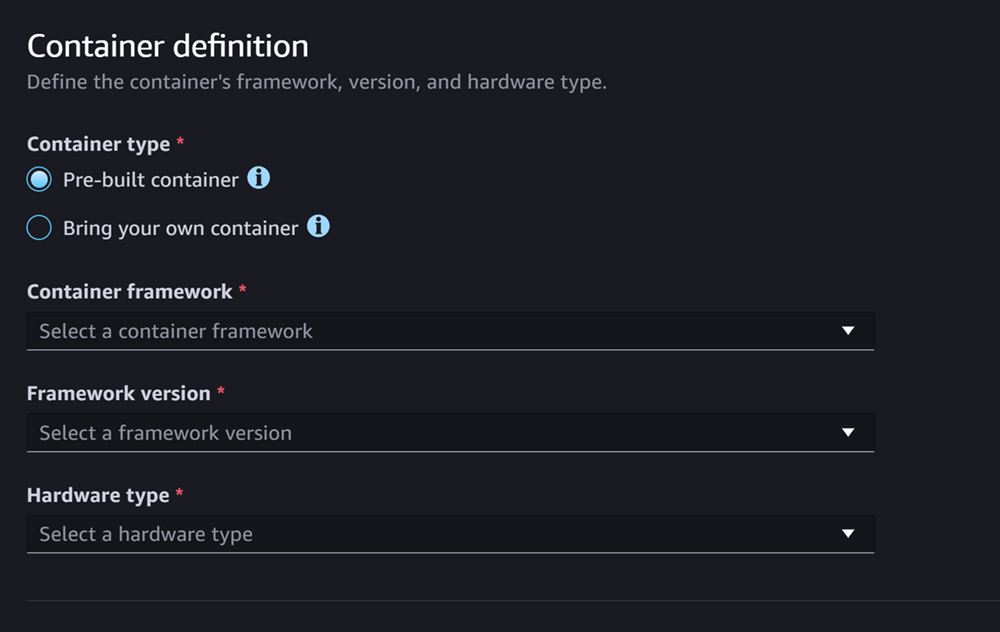
針對 [容器定義] 區段,執行下列動作:
-
如果您想要使用 SageMaker 受管理容器,請選取 [容器類型],請選取 [預先建立容器],或選取 [攜帶自己的容器] (如果您有自己的容器)。
-
如果您選取預先建置的容器,請選取您要使用的容器架構、架構版本和硬體類型。
-
如果您選取「攜帶自己的容器」,請輸入容器映像ECR路徑的 Amazon ECR 路徑。
然後,填寫「工件」部分,該部分看起來像以下屏幕截圖:

針對「人工因素」段落,執行下列動作:
-
如果您使用其中一個 SageMaker 支援封裝模型成品 (PyTorch 或XGBoost) 的架構,則您可以選擇「上載成品」選項。使用此選項,您可以簡單地指定原始模型加工品、您擁有的任何自訂推論程式碼以及 requirements.txt 檔案,並為您 SageMaker 處理封裝歸檔。請執行下列操作:
-
對於人工因素,選取上載人工因素以繼續提供檔案。否則,如果您已經擁有包含模型檔案、推論程式碼和
requirements.txt檔案的tar.gz存檔,請選取將 S3 輸入URI至預先封裝的成品。 -
如果您選擇上傳成品,則對於 S3 儲存貯體,請在為您封裝成品後,輸入 SageMaker 要存放成品的儲存貯體的 Amazon S3 路徑。然後,完成以下步驟。
-
對於「上載模型加工品」,請上載模型檔案。
-
對於推論程式碼,如果您想要使用 SageMaker 提供提供推論的預設程式碼,請選取 [使用預設推論程式碼]。否則,請選取 [上傳自訂的推論程式碼],以使用您自己的推論程式碼。
-
針對「上載 requirements.txt」,請上傳文字檔案,其中列出您要在執行階段安裝的任何相依性。
-
-
如果您不使用 SageMaker 支持打包模型工件的框架,則 Studio 會向您顯示預先打包的工件選項,並且您必須提供已打包為
tar.gz存檔的所有成品。請執行下列操作:-
對於預先封裝的成品,如果您的
tar.gz存檔已上傳到 Amazon S3,請URI針對預先封裝的模型成品選取輸入 S3。如果您要將存檔直接上傳至,請選取「上載預先封裝的模型人工因素」。 SageMaker -
如果您URI為預先封裝的模型成品選取輸入 S3,請輸入 S3 存檔的 Amazon S3 URI 路徑。否則,請從本機電腦選取並上傳歸檔。
-
下一部分是安全性,它看起來像下面的屏幕截圖:
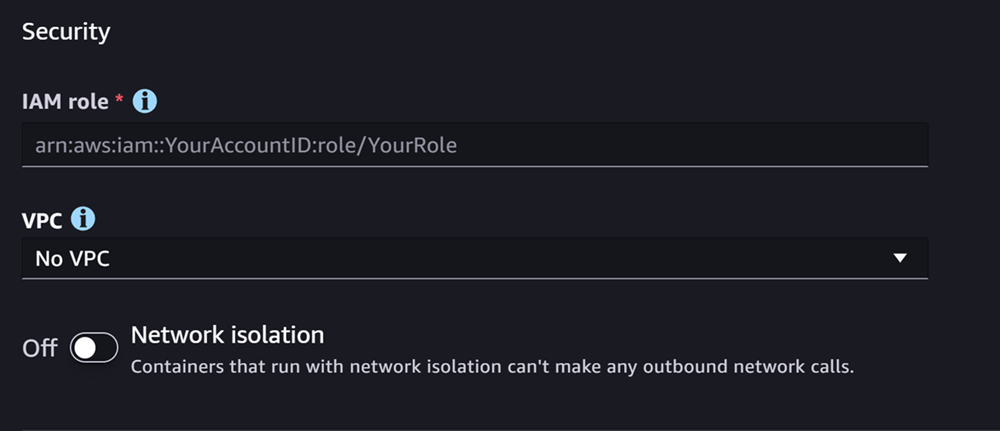
在「安全性」段落中,執行下列動作:
-
若為IAM角色,請輸ARN入IAM角色的。
-
(選用) 對於虛擬私有雲 (VPC),您可以選取 Amazon VPC 來存放模型組態和成品。
-
(選擇性) 如果您想要限制容器的網際網路存取,請開啟網路隔離切換。
最後,您可以選擇填寫高級選項部分,該部分看起來像以下屏幕截圖:
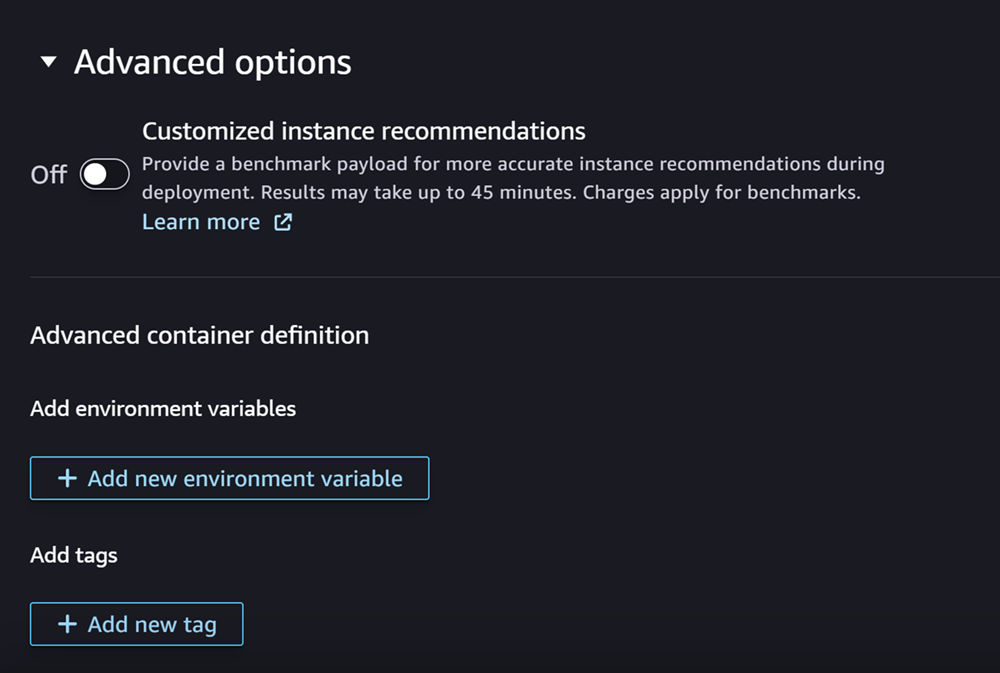
(選擇性) 對於「進階選項」區段,請執行下列動作:
-
如果您想在建立模型後在模型上執行 Amazon SageMaker 推論建議程式任務,請開啟自訂執行個體建議切換。推論建議程式是一項功能,可為您提供建議的執行個體類型,以最佳化推論效能和成本。您可以在準備部署模型時檢視這些執行個體建議。
-
在新增環境變數中,輸入容器的環境變數做為鍵值配對。
-
在「標籤」中,輸入任何標籤作為鍵值配對。
-
完成模型和容器設定後,選擇 [建立可部署模型]。
現在,您應該在 SageMaker Studio 中有一個已準備好部署的模型。
部署模型
最後,您將在上一個步驟中設定的模型部署到HTTPS端點。您可以將單一模型或多個模型部署到端點。
模型和端點相容性
在您可以將模型部署到端點之前,模型和端點必須具有相同的下列設定值來相容:
-
角IAM色
-
AmazonVPC,包括其子網絡和安全組
-
網路隔離 (啟用或停用)
Studio 可防止您以下列方式將模型部署到不相容的端點:
-
如果您嘗試將模型部署到新端點,請使用相容 SageMaker 的初始設定來設定端點。如果您透過變更這些設定中斷相容性,Studio 會顯示警示並防止您的部署。
-
如果您嘗試部署到現有端點,且該端點不相容,Studio 會顯示警示並阻止您的部署。
-
如果您嘗試將多個模型新增至部署,Studio 會阻止您部署彼此不相容的模型。
當 Studio 顯示有關模型和端點不兼容的警報時,您可以選擇警報中的「查看詳細信息」以查看哪些設置不兼容。
部署模型的一種方法是在 Studio 中執行以下操作:
-
開啟 SageMaker 工作室應用程式。
-
在左側導覽窗格中選擇 Models (模型)。
-
在「模型」頁面上,從模型清單中選取一或多個 SageMaker 模型。
-
選擇部署。
-
針對端點名稱,開啟下拉式功能表。您可以選取現有端點,也可以建立部署模型的新端點。
-
針對執行個體類型,選取要用於端點的執行個體類型。如果您之前已針對模型執行推論建議工作,建議的執行個體類型會顯示在「建議」標題下方的清單中。否則,您會看到一些可能適合您模型的潛在執行個體。
執行個體類型相容性 JumpStart
如果您要部署 JumpStart 模型,Studio 只會顯示模型支援的執行個體類型。
-
針對初始執行個體計數,輸入您要為端點佈建的初始執行個體數目。
-
針對執行個體計數上限,指定端點在擴展以適應流量增加時可佈建的執行個體數目上限。
-
如果您要部署的模型是模型中樞最常用 JumpStart LLMs的模型之一,則 [替代組態] 選項會出現在執行個體類型和執行個體計數欄位之後。
對於最受歡迎的執行個體類型 JumpStart LLMs, AWS 已預先標準化執行個體類型,以達到最佳化的成本或效能 此資料可協助您決定要使用哪種執行個體類型來部署您的LLM. 選擇替代組態以開啟包含預先基準測試資料的對話方塊。面板看起來像下面的屏幕截圖:
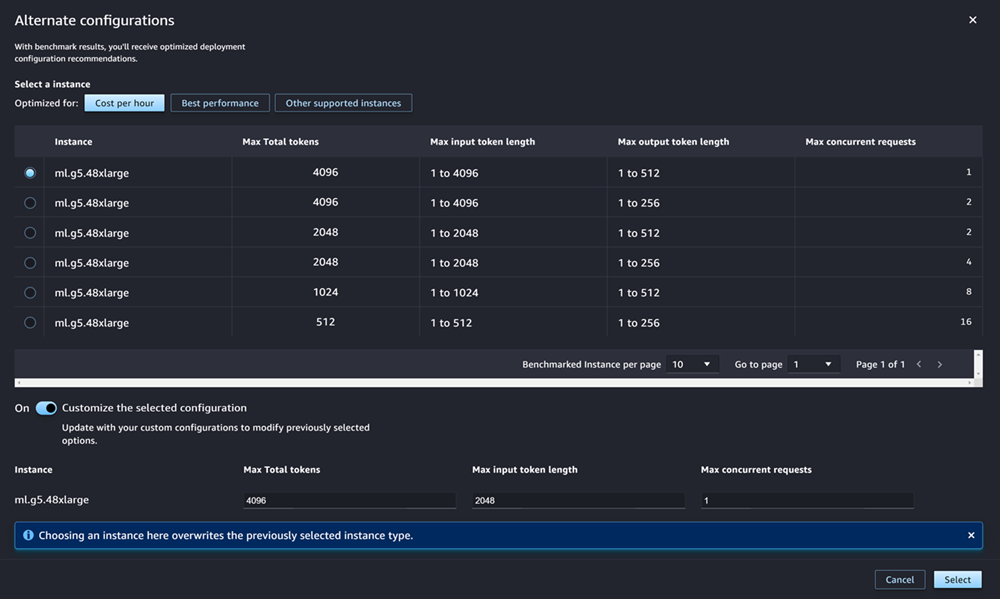
在替代組態方塊中,執行下列操作:
-
選取執行個體類型。您可以選擇 [每小時成本] 或 [最佳效能],查看針對指定模型最佳化成本或效能的執行個體類型。您也可以選擇「其他支援的執行個體」,查看與模型相容的其他執行個體類 JumpStart 型清單。請注意,在此選取例證類型會覆寫在步驟 6 中指定的任何先前執行個體選取。
-
(選擇性) 開啟自訂選取的組態切換以指定最大記號總數 (您要允許的最大記號數目,也就是輸入 Tok en 與模型產生的輸出總和)、輸入 Token 長度上限 (您要允許輸入每個要求的最大記號數) 和最大並行要求 (模型一次可以處理要求的最大處理數)。
-
選擇 [選取] 以確認您的執行個體類型和組態設定。
-
-
「模型」欄位應該已填入您要部署的模型名稱。您可以選擇 [新增模型],將更多模型加入至部署。針對您新增的每個模型,填寫下列欄位:
-
在「CPU核心數目」中,輸入您要專用於模型使用的CPU核心。
-
對於「最小複本數」,請輸入您希望在任何指定時間在端點上託管的模型複本的最小數目。
-
在最小CPU記憶體 (MB) 中,輸入模型所需的最小記憶體容量 (以 MB 為單位)。
-
在最大CPU記憶體 (MB) 中,輸入您要允許模型使用的最大記憶體容量 (以 MB 為單位)。
-
-
(選擇性) 對於「進階」選項,請執行下列操作:
-
對於 IAMrole,請使用預設 SageMakerIAM執行角色,或指定具有所需權限的自己角色。請注意,此IAM角色必須與您在建立可部署模型時指定的角色相同。
-
對於虛擬私有雲 (VPC),您可以指定要VPC在其中託管端點的端點。
-
對於加密KMS金鑰,請選取 AWS KMS 金鑰,以加密連接至託管端點之 ML 計算執行個體之儲存磁碟區上的資料。
-
開啟啟用網路隔離切換,以限制容器的網際網路存取。
-
在 [逾時] 組態中,輸入 [模型資料下載逾時 (秒)] 和 [容器啟動健全狀況檢查逾時 (秒)] 欄位的值。這些值分別決定了 SageMaker 允許將模型下載到容器和啟動容器的時間上限。
-
在「標籤」中,輸入任何標籤作為鍵值配對。
注意
SageMaker 使用與您正在部署的模型相容的初始值來設定IAM角色VPC、和網路隔離設定。如果您透過變更這些設定中斷相容性,Studio 會顯示警示並防止您的部署。
-
配置選項後,頁面應該看起來像下面的屏幕截圖。
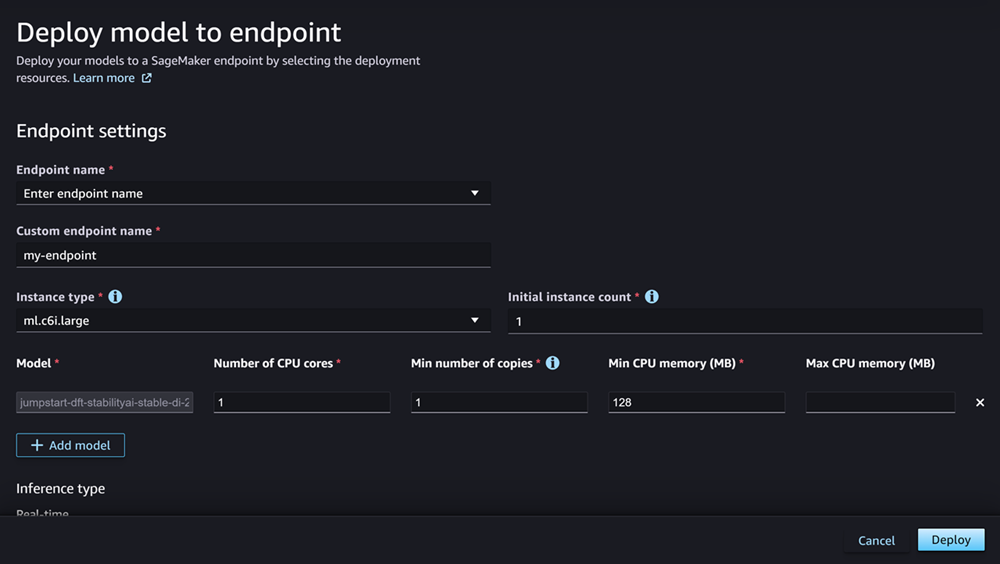
設定部署後,選擇「部署」以建立端點並部署模型。
使用 Python 部署模型 SDKs
使用 SageMaker PythonSDK,您可以通過兩種方式構建模型。首先是從Model或ModelBuilder類建立模型物件。如果您使用Model類別建立Model物件,則需要指定模型套件或推論程式碼 (視您的模型伺服器而定)、用來處理用戶端和伺服器之間資料序列化和還原序列化的指令碼,以及任何要上傳到 Amazon S3 以供使用的相依性。建置模型的第二種方法是使ModelBuilder用您提供模型加工品或推論程式碼。 ModelBuilder自動捕獲您的依賴關係,推斷所需的序列化和反序列化功能,並打包您的依賴關係以創建對象。Model如需有關 ModelBuilder 的詳細資訊,請參閱 在 Amazon SageMaker 中創建模型 ModelBuilder。
下一節說明建立模型和部署模型物件的兩種方法。
設定
下列範例會為模型部署程序做好準備。他們匯入必要的程式庫URL,並定義用於尋找模型人工因素的 S3。
範例 人工因素 URL
以下代碼構建了一個示例 Amazon S3 URL。URL會在 Amazon S3 儲存貯體中尋找預先訓練模型的模型成品。
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
完整的 Amazon S3 URL 存放在變數中model_url,該變數會用於以下範例中。
概觀
您可以使用 SageMaker Python SDK 或 Python (Boto3) 部署模型的SDK多種方式。以下幾節概述了您針對數種可能方法所完成的步驟。以下範例會示範這些步驟。
設定
下列範例會設定將模型部署到端點所需的資源。
部署
下列範例會將模型部署到端點。
使用部署模型 AWS CLI
您可以使用將模型部署到端點 AWS CLI。
概觀
使用部署模型時 AWS CLI,您可以使用或不使用推論元件來部署模型。下列各節摘要說明您針對這兩種方法執行的命令。以下範例會示範這些指令。
設定
下列範例會設定將模型部署到端點所需的資源。
部署
下列範例會將模型部署到端點。
