本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
針對 Step Functions 中的大規模平行工作負載,在分散式模式中使用映射狀態
管理狀態和轉換資料
使用 Step Functions,您可以協調大規模平行工作負載來執行任務,例如半結構化資料的隨需處理。這些平行工作負載可讓您同時處理存放在 Amazon S3 中的大規模資料來源。例如,您可以處理包含大量資料的單一 JSON 或 CSV 檔案。或者,您可以處理大量 Amazon S3 物件。
若要在工作流程中設定大規模平行工作負載,請在分散式模式中包含 Map 狀態。映射狀態會同時處理資料集中的項目。設定為分散式Map的狀態稱為分散式映射狀態。在分散式模式中, Map 狀態允許高並行處理。在分散式模式中, Map 狀態會在稱為子工作流程執行的反覆運算中處理資料集中的項目。您可以指定可平行執行的子工作流程執行數目。每個子工作流程執行都有自己的獨立執行歷史記錄,與父工作流程的執行歷史記錄不同。如果您未指定,Step Functions 會平行執行 10,000 個平行子工作流程執行。
下圖說明如何在工作流程中設定大規模平行工作負載。
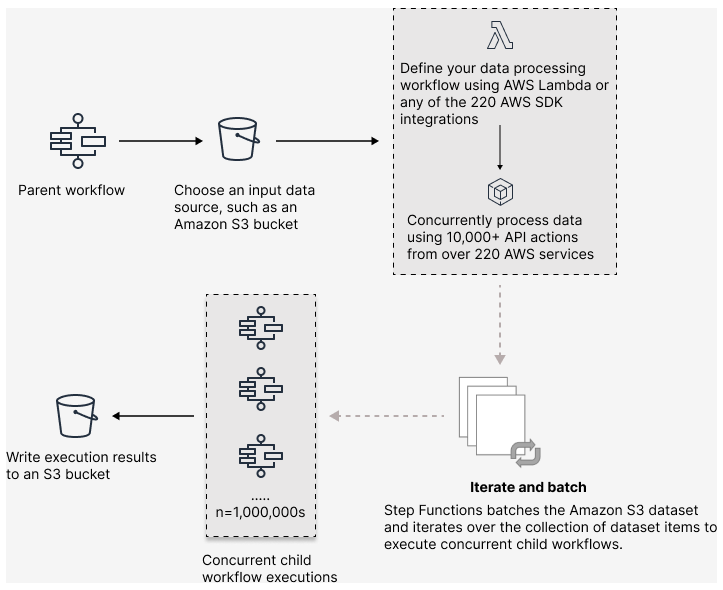
在研討會中學習
了解 Step Functions 和 Lambda 等無伺服器技術如何簡化管理和擴展、卸載未區分的任務,以及解決大規模分散式資料處理的挑戰。在此過程中,您將使用分散式映射進行高並行處理。研討會也提供最佳化工作流程的最佳實務,以及用於宣告處理、漏洞掃描和 Monte Carlo 模擬的實際使用案例。
重要用語
- 分散式模式
-
Map 狀態的處理模式。在此模式中,狀態的每個反覆運算
Map都會執行為啟用高並行的子工作流程執行。每個子工作流程執行都有自己的執行歷史記錄,與父工作流程的執行歷史記錄分開。此模式支援從大規模 Amazon S3 資料來源讀取輸入。 - 分散式映射狀態
-
映射狀態設定為分散式處理模式。
- 映射工作流程
Map狀態執行的一組步驟。- 父工作流程
-
包含一或多個分散式映射狀態的工作流程。
- 子工作流程執行
-
分散式地圖狀態的反覆運算。子工作流程執行有自己的執行歷史記錄,與父工作流程的執行歷史記錄分開。
- 映射執行
-
當您在分散式模式下執行
Map狀態時,Step Functions 會建立 Map Run 資源。Map Run 是指分散式映射狀態啟動的一組子工作流程執行,以及控制這些執行的執行時間設定。Step Functions 會將 Amazon Resource Name (ARN) 指派給您的 Map Run。您可以在 Step Functions 主控台中檢查 Map Run。您也可以叫用DescribeMapRunAPI 動作。Map Run 的子工作流程執行會向 發出指標 CloudWatch;。這些指標會有標記的狀態機器 ARN,格式如下:
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUID如需詳細資訊,請參閱檢視地圖執行。
分散式映射狀態定義範例 (JSONPath)
當您需要協調符合下列任一條件組合的大規模平行工作負載時,請在分散式模式中使用 Map 狀態:
資料集的大小超過 256 KiB。
工作流程的執行事件歷史記錄會超過 25,000 個項目。
您需要並行超過 40 個並行反覆運算。
下列分散式映射狀態定義範例會將資料集指定為存放在 Amazon S3 儲存貯體中的 CSV 檔案。它還指定了一個 Lambda 函數,用於處理 CSV 檔案的每一列中的資料。由於此範例使用 CSV 檔案,因此也會指定 CSV 資料欄標頭的位置。若要檢視此範例的完整狀態機器定義,請參閱教學課程 使用分散式地圖複製大規模 CSV 資料。
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}執行分散式映射的許可
當您在工作流程中包含分散式地圖狀態時,Step Functions 需要適當的許可,以允許狀態機器角色叫用分散式地圖狀態的 StartExecution API 動作。
下列 IAM 政策範例會將執行分散式映射狀態所需的最低權限授予狀態機器角色。
注意
請務必stateMachineNamearn:aws:states:。region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
此外,您必須確定您擁有存取分散式地圖狀態中使用的 AWS 資源所需的最低權限,例如 Amazon S3 儲存貯體。如需相關資訊,請參閱使用分散式地圖狀態的 IAM 政策。
分散式映射狀態欄位
若要在工作流程中使用分散式映射狀態,請指定一個或多個這些欄位。除了常見狀態欄位之外,您還可以指定這些欄位。
Type(必要)-
設定狀態類型,例如
Map。 ItemProcessor(必要)-
包含下列指定
Map狀態處理模式和定義的 JSON 物件。-
ProcessorConfig– JSON 物件,指定處理項目的模式,具有下列子欄位:-
Mode– 將DISTRIBUTED設定為在分散式模式中使用Map狀態。警告
標準工作流程支援分散式模式,但 Express 工作流程不支援。
-
ExecutionType– 指定映射工作流程的執行類型為 STANDARD 或 EXPRESS。如果您DISTRIBUTED為Mode子欄位指定 ,則必須提供此欄位。如需工作流程類型的詳細資訊,請參閱 在 Step Functions 中選擇工作流程類型。
-
StartAt– 指定字串,指出工作流程中的第一個狀態。此字串區分大小寫,且必須符合其中一個狀態物件的名稱。此狀態會先針對資料集中的每個項目執行。您提供給Map狀態的任何執行輸入會先傳遞至StartAt狀態。States– 包含逗號分隔狀態集的 JSON 物件探索要在 Step Functions 中使用的工作流程狀態。在此物件中,您可以定義 Map workflow。
-
ItemReader-
指定資料集及其位置。
Map狀態會從指定的資料集接收其輸入資料。在分散式模式中,您可以使用從先前狀態傳遞的 JSON 承載,或是使用大型 Amazon S3 資料來源做為資料集。如需詳細資訊,請參閱ItemReader (地圖)。
Items(選用,僅限 JSONata)-
JSON 陣列、JSON 物件或必須評估為陣列或物件的 JSONata 表達式。
ItemsPath(選用,僅限 JSONPath)-
使用 JsonPath
語法指定參考路徑,以選取包含項目陣列的 JSON 節點,或狀態輸入內具有鍵值對的物件。 在分散式模式中,只有當您使用上一個步驟的 JSON 陣列或物件做為狀態輸入時,才指定此欄位。如需詳細資訊,請參閱ItemsPath (地圖,僅限 JSONPath)。
ItemSelector(選用,僅限 JSONPath)-
覆寫個別資料集項目的值,然後再傳遞至每個
Map狀態反覆運算。在此欄位中,您可以指定有效的 JSON 輸入,其中包含鍵值對的集合。這些對可以是您在狀態機器定義中定義的靜態值、使用路徑從狀態輸入中選取的值,或從內容物件存取的值。如需詳細資訊,請參閱ItemSelector (地圖)。
ItemBatcher(選用)-
指定 批次處理資料集項目。然後,每個子工作流程執行都會收到這些項目的批次做為輸入。如需詳細資訊,請參閱ItemBatcher (地圖)。
MaxConcurrency(選用)-
指定可平行執行的子工作流程執行數目。解譯器最多只允許指定數量的平行子工作流程執行。如果您未指定並行值或將其設定為零,Step Functions 不會限制並行並執行 10,000 個平行子工作流程執行。在 JSONata 狀態下,您可以指定評估為整數的 JSONata 表達式。
注意
雖然您可以為平行子工作流程執行指定更高的並行限制,但我們建議您不要超過下游 AWS 服務的容量,例如 AWS Lambda。
MaxConcurrencyPath(選用,僅限 JSONPath)-
如果您想要使用參考路徑從狀態輸入動態提供最大並行值,請使用
MaxConcurrencyPath。解析後,參考路徑必須選取值為非負整數的欄位。注意
Map狀態不能同時包含MaxConcurrency和MaxConcurrencyPath。 ToleratedFailurePercentage(選用)-
定義映射執行中要容忍的失敗項目百分比。如果 Map Run 超過此百分比,則會自動失敗。Step Functions 計算失敗項目的百分比,是失敗或逾時項目總數除以項目總數的結果。您必須指定介於零到 100 之間的值。如需詳細資訊,請參閱在 Step Functions 中設定分散式映射狀態的失敗閾值。
在 JSONata 狀態下,您可以指定評估為整數的 JSONata 表達式。
ToleratedFailurePercentagePath(選用,僅限 JSONPath)-
如果您想要使用參考路徑從狀態輸入動態提供可容忍的失敗百分比值,請使用
ToleratedFailurePercentagePath。解析後,參考路徑必須選取值介於零和 100 之間的欄位。 ToleratedFailureCount(選用)-
定義映射執行中要容忍的失敗項目數量。如果 Map Run 超過此數字,則會自動失敗。如需詳細資訊,請參閱在 Step Functions 中設定分散式映射狀態的失敗閾值。
在 JSONata 狀態下,您可以指定評估為整數的 JSONata 表達式。
ToleratedFailureCountPath(選用,僅限 JSONPath)-
如果您想要使用參考路徑從狀態輸入動態提供容錯計數值,請使用
ToleratedFailureCountPath。解析後,參考路徑必須選取值為非負整數的欄位。 Label(選用)-
唯一識別
Map狀態的字串。對於每個 Map Run,Step Functions 會將標籤新增至 Map Run ARN。以下是具有名為 之自訂標籤的 Map Run ARN 範例demoLabel:arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0b如果您未指定標籤,Step Functions 會自動產生唯一的標籤。
注意
標籤長度不能超過 40 個字元,在狀態機器定義中必須是唯一的,且不能包含以下任何字元:
-
空格
-
萬用字元 (
? *) -
括號字元 (
< > { } [ ]) -
特殊字元 (
: ; , \ | ^ ~ $ # % & ` ") -
控制字元 (
\\u0000-\\u001f或\\u007f-\\u009f)。
Step Functions 接受包含非 ASCII 字元的狀態機器、執行、活動和標籤名稱。由於這類字元會阻止 Amazon CloudWatch 記錄資料,因此我們建議您僅使用 ASCII 字元,以便您可以追蹤 Step Functions 指標。
-
ResultWriter(選用)-
指定 Step Functions 寫入所有子工作流程執行結果的 Amazon S3 位置。
Step Functions 會合併所有子工作流程執行資料,例如執行輸入和輸出、ARN 和執行狀態。接著,它會將狀態相同的執行匯出至指定 Amazon S3 位置中的個別檔案。如需詳細資訊,請參閱ResultWriter (地圖)。
如果您不匯出
Map狀態結果,它會傳回所有子工作流程執行結果的陣列。例如:[1, 2, 3, 4, 5] ResultPath(選用,僅限 JSONPath)-
指定輸入中要放置反覆運算輸出的位置。輸入接著會依 OutputPath 欄位指定的存在進行篩選,再做為狀態的輸出傳遞。如需詳細資訊,請參閱輸入和輸出處理。
ResultSelector(選用)-
傳遞金鑰值對的集合,其中值為靜態或從結果中選取。如需詳細資訊,請參閱ResultSelector。
提示
如果您在狀態機器中使用的平行或映射狀態傳回陣列,您可以將它們轉換為具有 ResultSelector 欄位的平面陣列。如需詳細資訊,請參閱平面化陣列陣列。
Retry(選用)-
稱為 Retriers 的物件陣列,可定義重試政策。如果狀態遇到執行時間錯誤,則執行會使用重試政策。如需詳細資訊,請參閱使用重試和擷取的狀態機器範例。
注意
如果您為分散式映射狀態定義重試器,則重試政策會套用至所有啟動
Map狀態的子工作流程執行。例如,假設您的Map狀態開始三個子工作流程執行,其中一個工作流程執行失敗。當失敗發生時,如果已定義,則執行會使用Retry欄位做為Map狀態。重試政策適用於所有子工作流程執行,而不只是失敗的執行。如果一或多個子工作流程執行失敗,則 Map Run 失敗。當您重試
Map狀態時,它會建立新的 Map Run。 Catch(選用)-
稱為 Catcher 的物件陣列,可定義後援狀態。
Catch如果狀態遇到執行時間錯誤,Step Functions 會使用 中定義的 Catchers。發生錯誤時,執行會先使用 中定義的任何重試器Retry。如果未定義或耗盡重試政策,則如果已定義,則執行會使用其 Catchers。如需詳細資訊,請參閱備用狀態。 Output(選用,僅限 JSONata)-
用來指定和轉換 狀態的輸出。指定時,值會覆寫狀態輸出預設值。
輸出欄位接受任何 JSON 值 (物件、陣列、字串、數字、布林值、 null)。任何字串值,包括物件或陣列內的值,如果被 {% %} 字元包圍,將評估為 JSONata。
輸出也直接接受 JSONata 表達式,例如:「輸出」:「{% jsonata 表達式 %}」
如需詳細資訊,請參閱在 Step Functions 中使用 JSONata 轉換資料。
-
Assign(選用) -
用來存放變數。
Assign欄位接受 JSON 物件,其中包含定義變數名稱及其指派值的鍵/值對。任何字串值,包括物件或陣列內的值,在被{% %}字元包圍時都會評估為 JSONata如需詳細資訊,請參閱使用變數在狀態之間傳遞資料。
在 Step Functions 中設定分散式映射狀態的失敗閾值
當您協調大規模平行工作負載時,您也可以定義可容忍的失敗閾值。此值可讓您將失敗項目的數量上限或百分比指定為 Map Run 的失敗閾值。根據您指定的值,如果 Map Run 超過閾值,則會自動失敗。如果您同時指定這兩個值,當工作流程超出任一個值時,就會失敗。
指定閾值有助於您在整個 Map Run 失敗之前,使特定數量的項目失敗。Step Functions 會在 Map Run 失敗時傳回States.ExceedToleratedFailureThreshold錯誤,因為超過指定的閾值。
注意
Step Functions 可以在 Map Run 中繼續執行子工作流程,即使超過可容忍的失敗閾值,但在 Map Run 失敗之前。
若要在 Workflow Studio 中指定閾值,請在執行期設定欄位下的其他組態中選取設定容錯閾值。
- 容錯失敗百分比
-
定義要容忍的失敗項目百分比。如果超過此值,您的 Map Run 失敗。Step Functions 計算失敗項目的百分比,是失敗或逾時項目總數除以項目總數的結果。您必須指定介於零到 100 之間的值。預設百分比值為零,這表示如果其任何一個子工作流程執行失敗或逾時,工作流程就會失敗。如果您將百分比指定為 100,即使所有子工作流程執行都失敗,工作流程也不會失敗。
或者,您可以指定百分比做為分散式映射狀態輸入中現有鍵值對的參考路徑。此路徑必須在執行時間解析為介於 0 到 100 之間的正整數。您可以在
ToleratedFailurePercentagePath子欄位中指定參考路徑。例如,假設有下列輸入:
{"percentage":15}您可以使用該輸入的參考路徑指定百分比,如下所示:
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }重要
您可以在分散式映射狀態定義中指定
ToleratedFailurePercentage或ToleratedFailurePercentagePath,但不能同時指定兩者。 - 容錯失敗計數
-
定義要容忍的失敗項目數量。如果超過此值,您的 Map Run 失敗。
或者,您可以指定計數做為分散式映射狀態輸入中現有鍵值對的參考路徑。此路徑必須在執行時間解析為正整數。您可以在
ToleratedFailureCountPath子欄位中指定參考路徑。例如,假設有下列輸入:
{"count":10}您可以使用該輸入的參考路徑指定數字,如下所示:
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }重要
您可以在分散式映射狀態定義中指定
ToleratedFailureCount或ToleratedFailureCountPath,但不能同時指定兩者。
進一步了解分散式地圖
若要繼續進一步了解分散式地圖狀態,請參閱下列資源:
-
輸入和輸出處理
若要設定分散式映射狀態接收的輸入及其產生的輸出,Step Functions 會提供下列欄位:
除了這些欄位之外,Step Functions 也可讓您定義分散式映射的可容忍失敗閾值。此值可讓您將失敗項目的數量上限或百分比指定為 Map Run 的失敗閾值。如需設定容錯閾值的詳細資訊,請參閱 在 Step Functions 中設定分散式映射狀態的失敗閾值。
-
使用分散式映射狀態
請參閱下列教學課程和範例專案,以開始使用分散式地圖狀態。
-
檢查分散式映射狀態執行
Step Functions 主控台提供映射執行詳細資訊頁面,其中會顯示與分散式映射狀態執行相關的所有資訊。如需如何檢查此頁面上顯示的資訊,請參閱 檢視地圖執行。
