本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
開始通話後分析轉錄
在開始通話後分析轉錄之前,您必須建立 Amazon Transcribe 要在音訊中符合的所有類別。
注意
通話分析轉錄無法追溯配對至新類別。只有您開始通話分析轉錄前建立的類別,才能套用至該轉錄輸出。
如果您已建立一或多個類別,且音訊符合至少一個類別中的所有規則, Amazon Transcribe 將標記輸出為符合的類別。如果您選擇不使用類別,或您的音訊與類別中指定的規則不符,系統就不會標示您的文字記錄。
若要開始通話後分析轉錄,您可以使用 AWS 管理主控台、AWS CLI 或 AWS SDK;請參閱下列範例:
使用以下程序以開始啟動通話後分析工作。會以該類別標示符合某個類別定義之所有特徵的通話。
-
在導覽窗格中的 Amazon Transcribe 通話分析下,選擇通話分析任務。
-
選擇建立任務。
-
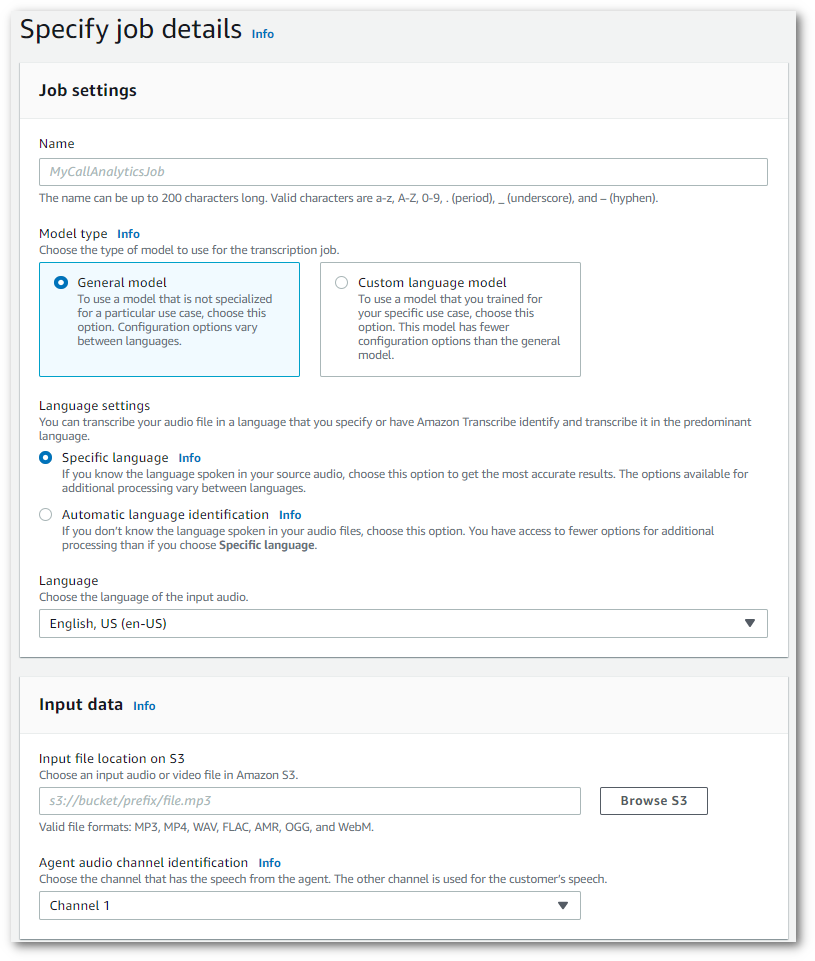
在指定作業詳細資訊頁面上,提供有關通話分析工作的資訊,包括輸入資料的位置。
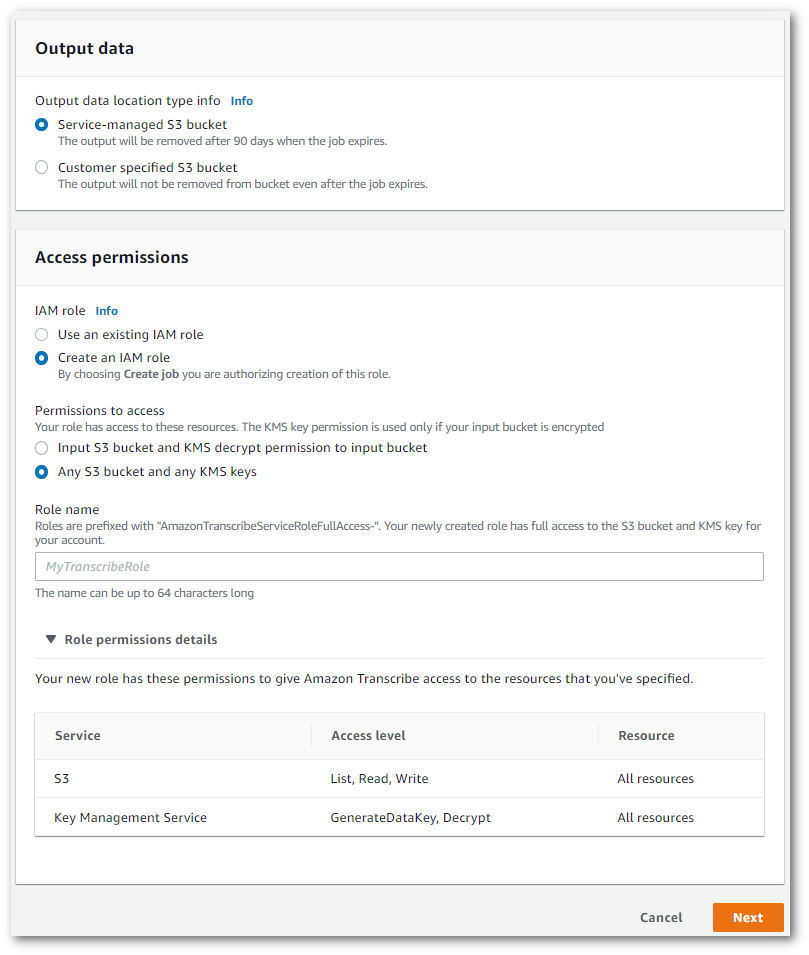
指定輸出資料的所需 Amazon S3 位置,以及要使用 IAM 的角色。
-
選擇下一步。
-
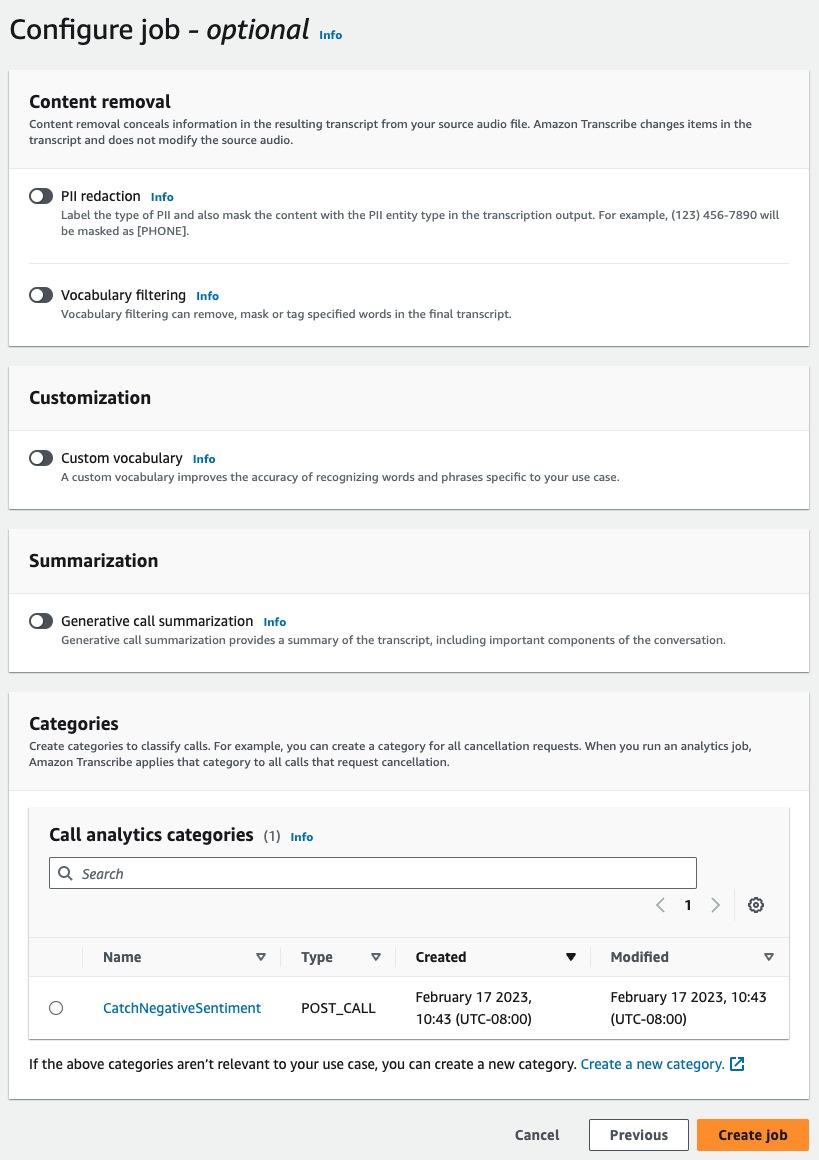
位於設定工作,開啟您要包含在通話分析工作中的任何選用功能。如果您先前已建立類別,這些類別會在類別面板顯示,並會自動套用至您的通話分析工作。
-
選擇建立作業。
此範例使用 start-call-analytics-jobchannel-definitions 參數。如需詳細資訊,請參閱StartCallAnalyticsJob及ChannelDefinition。
aws transcribe start-call-analytics-job \ --regionus-west-2\ --call-analytics-job-namemy-first-call-analytics-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-location s3://amzn-s3-demo-bucket/my-output-files/ \ --data-access-role-arn arn:aws:iam::111122223333:role/ExampleRole\ --channel-definitions ChannelId=0,ParticipantRole=AGENTChannelId=1,ParticipantRole=CUSTOMER
以下是使用start-call-analytics-job
aws transcribe start-call-analytics-job \ --regionus-west-2\ --cli-input-json file://filepath/my-call-analytics-job.json
檔案 my-call-analytics-job.json 包含以下請求主文。
{ "CallAnalyticsJobName": "my-first-call-analytics-job", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputLocation": "s3://amzn-s3-demo-bucket/my-output-files/", "ChannelDefinitions": [ { "ChannelId": 0, "ParticipantRole": "AGENT" }, { "ChannelId": 1, "ParticipantRole": "CUSTOMER" } ] }
此範例使用 適用於 Python (Boto3) 的 AWS SDK 來啟動使用 start_call_analytics_jobStartCallAnalyticsJob及ChannelDefinition。
如需使用 AWS SDKs 的其他範例,包括功能特定、案例和跨服務範例,請參閱 Amazon Transcribe AWS SDKs的程式碼範例章節。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-call-analytics-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" output_location = "s3://amzn-s3-demo-bucket/my-output-files/" data_access_role = "arn:aws:iam::111122223333:role/ExampleRole" transcribe.start_call_analytics_job( CallAnalyticsJobName = job_name, Media = { 'MediaFileUri': job_uri }, DataAccessRoleArn = data_access_role, OutputLocation = output_location, ChannelDefinitions = [ { 'ChannelId': 0, 'ParticipantRole': 'AGENT' }, { 'ChannelId': 1, 'ParticipantRole': 'CUSTOMER' } ] ) while True: status = transcribe.get_call_analytics_job(CallAnalyticsJobName = job_name) if status['CallAnalyticsJob']['CallAnalyticsJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
