AWS Systems Manager Incident Manager steht neuen Kunden nicht mehr offen. Bestandskunden können den Service weiterhin wie gewohnt nutzen. Weitere Informationen finden Sie unter Änderung der AWS Systems Manager Incident Manager Verfügbarkeit.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Lebenszyklus von Vorfällen in Incident Manager
AWS Systems Manager Incident Manager bietet ein step-by-step Framework, das auf bewährten Verfahren basiert, um Vorfälle wie Serviceausfälle oder Sicherheitsbedrohungen zu identifizieren und darauf zu reagieren. Das Hauptaugenmerk von Incident Manager liegt darauf, die betroffenen Dienste oder Anwendungen mithilfe einer vollständigen Lösung für das Incident Lifecycle Management so schnell wie möglich wieder in den Normalzustand zu versetzen.
Wie in der folgenden Abbildung dargestellt, bietet Incident Manager Tools und bewährte Methoden für jede Phase des Incident-Lebenszyklus:
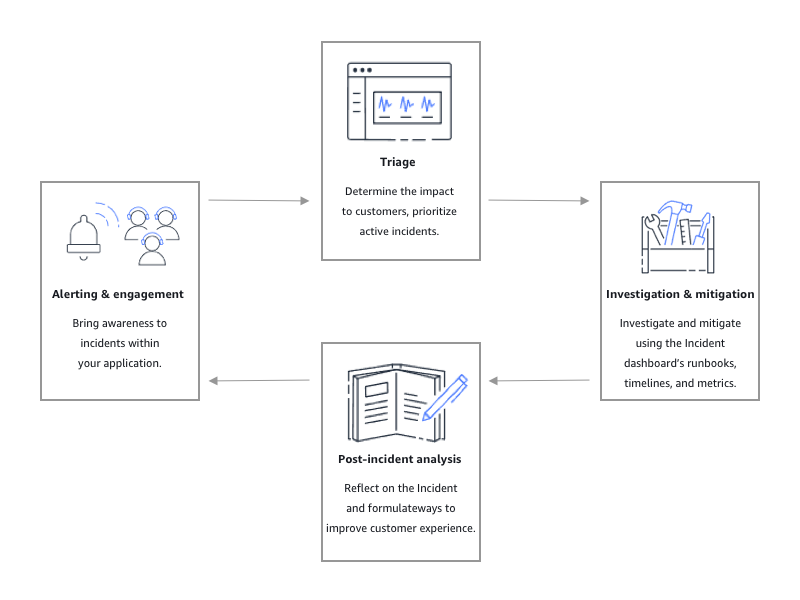
Alarmierung und Interaktion
In der Warn- und Interaktionsphase des Incident-Lebenszyklus liegt der Schwerpunkt darauf, das Bewusstsein für Vorfälle in Ihren Anwendungen und Diensten zu schärfen. Diese Phase beginnt, bevor ein Vorfall entdeckt wird, und erfordert ein tiefes Verständnis Ihrer Anwendungen. Sie können CloudWatchAmazon-Metriken verwenden, um Daten über die Leistung Ihrer Anwendungen zu überwachen, oder Amazon verwenden, EventBridge um Warnmeldungen aus verschiedenen Quellen, Anwendungen und Diensten zu aggregieren. Nachdem Sie die Überwachung für Ihre Anwendungen eingerichtet haben, können Sie damit beginnen, Benachrichtigungen über Kennzahlen zu senden, die von der historischen Norm abweichen. Weitere Informationen zu bewährten Methoden für die Überwachung finden Sie unter. Überwachen
Um die Diagnose von Vorfällen durch Einsatzkräfte zu unterstützen, können Sie die Funktion „Ergebnisse“ in Incident Manager aktivieren. Bei den Ergebnissen handelt es sich um Informationen über AWS CodeDeploy Bereitstellungen und AWS CloudFormation Stack-Aktualisierungen, die ungefähr zum Zeitpunkt eines Vorfalls aufgetreten sind. Mit diesen Informationen wird der Zeitaufwand für die Bewertung potenzieller Ursachen reduziert, wodurch sich die mittlere Wiederherstellungszeit (MTTR) nach einem Vorfall verringern kann.
Nachdem Sie Ihre Anwendungen auf Vorfälle überwacht haben, können Sie einen Plan zur Reaktion auf Vorfälle definieren, der während eines Vorfalls verwendet werden soll. Weitere Informationen zum Erstellen von Reaktionsplänen finden Sie unterErstellung und Konfiguration von Reaktionsplänen in Incident Manager. Amazon EventBridge Events oder CloudWatch Alarms können mithilfe von Reaktionsplänen als Vorlage automatisch einen Vorfall erstellen. Weitere Informationen zur Erstellung von Vorfällen finden Sie unterAutomatisches oder manuelles Erstellen von Vorfällen im Incident Manager.
Reaktionspläne beinhalten entsprechende Eskalations- und Einsatzpläne, um Ersthelfer in den Vorfall einzubeziehen. Weitere Informationen zur Einrichtung von Eskalationsplänen finden Sie unter. Erstellen Sie einen Eskalationsplan Gleichzeitig benachrichtigt Amazon Q Developer in Chat-Anwendungen die Antwortenden über einen Chat-Kanal und leitet sie zur Detailseite des Vorfalls weiter. Mithilfe des Chat-Kanals und der Vorfalldetails kann das Team einen Vorfall kommunizieren und prüfen. Weitere Informationen zur Einrichtung von Chat-Kanälen in Incident Manager finden Sie unterAufgabe 2: Einen Chat-Kanal in Amazon Q Developer in Chat-Anwendungen erstellen.
Triage
Bei der Triage versuchen Ersthelfer, die Auswirkungen auf die Kunden zu ermitteln. Die Ansicht mit den Vorfalldetails in der Incident Manager-Konsole bietet den Einsatzkräften Zeitpläne und Kennzahlen, anhand derer sie den Vorfall beurteilen können. Die Bewertung der Auswirkungen eines Vorfalls bildet auch die Grundlage für die Reaktionszeit, Lösung und Kommunikation im Zusammenhang mit dem Vorfall. Die Einsatzkräfte priorisieren Vorfälle anhand von Folgenabstufungen von 1 (kritisch) bis 5 (keine Auswirkungen).
Ihr Unternehmen kann den genauen Umfang jeder Folgenabschätzung nach Ihren Wünschen festlegen. Die folgende Tabelle enthält Beispiele dafür, wie die einzelnen Wirkungsstufen typischerweise definiert werden können.
| Auswirkungscode | Name der Auswirkung | In der Stichprobe definierter Umfang |
|---|---|---|
1 |
Critical |
Vollständiger Anwendungsausfall, von dem die meisten Kunden betroffen sind. |
2 |
High |
Vollständiger Anwendungsausfall, der sich auf eine Untergruppe von Kunden auswirkt. |
3 |
Medium |
Teilweiser Anwendungsausfall, der sich auf Kunden auswirkt. |
4 |
Low |
Zeitweise auftretende Ausfälle, die nur begrenzte Auswirkungen auf Kunden haben. |
5 |
No Impact |
Kunden sind derzeit nicht betroffen, aber es sind dringende Maßnahmen erforderlich, um Auswirkungen zu vermeiden. |
Untersuchung und Schadensbegrenzung
Die Ansicht mit den Vorfalldetails bietet Ihrem Team Runbooks, Zeitpläne und Kennzahlen. Informationen darüber, wie Sie mit einem Vorfall arbeiten können, finden Sie unter. Vorfalldetails in der Konsole anzeigen
Runbooks bieten häufig Ermittlungsschritte und können automatisch Daten abrufen oder häufig verwendete Lösungen ausprobieren. Runbooks enthalten außerdem klare, wiederholbare Schritte, die sich für Ihr Team als nützlich erwiesen haben, um Vorfälle einzudämmen. Die Runbook-Tab konzentriert sich auf den aktuellen Runbook-Schritt und zeigt vergangene und future Schritte.
Incident Manager lässt sich in Systems Manager Automation integrieren, um Runbooks zu erstellen. Verwenden Sie Runbooks für eine der folgenden Aufgaben:
-
Instanzen und AWS Ressourcen verwalten
-
Automatische Ausführung von Skripten
-
CloudFormation Ressourcen verwalten
Weitere Informationen zu den unterstützten Aktionstypen finden Sie in der Aktionsreferenz von Systems Manager Automation im AWS Systems Manager Benutzerhandbuch.
Auf der Registerkarte „Zeitleiste“ wird angezeigt, welche Aktionen ergriffen wurden. In der Zeitleiste werden jeweils ein Zeitstempel und automatisch erstellte Details aufgezeichnet. Informationen zum Hinzufügen benutzerdefinierter Ereignisse zur Zeitleiste finden Sie im Zeitplan Abschnitt auf der Seite mit den Incident-Details in diesem Benutzerhandbuch.
Auf der Registerkarte Diagnose werden automatisch aufgefüllte Messwerte und manuell hinzugefügte Metriken angezeigt. Diese Ansicht bietet wertvolle Informationen über die Aktivitäten Ihrer Anwendung während eines Vorfalls.
Auf der Registerkarte „Engagements“ können Sie dem Vorfall weitere Kontakte hinzufügen und dem betroffenen Kontakt die Ressourcen zur Verfügung stellen, damit er sich schnell auf den neuesten Stand bringen kann, sobald er in den Vorfall involviert ist. Die Kontakte werden im Rahmen definierter Eskalationspläne oder persönlicher Engagementpläne kontaktiert.
Über einen Chat-Kanal können Sie direkt mit Ihrem Vorfall und anderen Einsatzkräften in Ihrem Team interagieren. Wenn Sie Amazon Q Developer in Chat-Anwendungen verwenden, können Sie Chat-Kanäle in konfigurieren. Slack, Microsoft Teamsund Amazon Chime. In Slack and Microsoft Teams Kanäle, Responder können mithilfe einer Reihe von Befehlen direkt vom Chat-Kanal aus mit Vorfällen interagieren. ssm-incidents Weitere Informationen finden Sie unter Interaktion über den Chat-Kanal.
Analyse nach dem Vorfall
Incident Manager bietet einen Rahmen, um über einen Vorfall nachzudenken und Maßnahmen zu ergreifen, die erforderlich sind, um zu verhindern, dass sich der Vorfall in future wiederholt, und um die Aktivitäten zur Reaktion auf Vorfälle insgesamt zu verbessern. Zu den Verbesserungen können gehören:
-
Änderungen an den Anwendungen, die an einem Vorfall beteiligt waren. Ihr Team kann diese Zeit nutzen, um das System zu verbessern und es fehlertoleranter zu machen.
-
Änderungen an einem Plan zur Reaktion auf Vorfälle. Nehmen Sie sich Zeit, um die gewonnenen Erkenntnisse einfließen zu lassen.
-
Änderungen an Runbooks. Ihr Team kann sich eingehend mit den zur Problemlösung erforderlichen Schritten und den Schritten befassen, die Sie automatisieren können.
-
Änderungen an den Warnmeldungen. Nach einem Vorfall sind Ihrem Team möglicherweise kritische Punkte in den Kennzahlen aufgefallen, anhand derer Sie das Team früher über einen Vorfall informieren können.
Incident Manager unterstützt diese potenziellen Verbesserungen, indem er neben dem Zeitplan des Vorfalls eine Reihe von Fragen und Aktionspunkten zur Analyse des Vorfalls verwendet. Weitere Informationen zur Verbesserung durch Analyse finden Sie unterDurchführen einer Analyse nach einem Vorfall im Incident Manager.
